直接上圖

如上圖,下面個藍框里的代碼比上面的藍框多了個cache函式,輸出如下圖
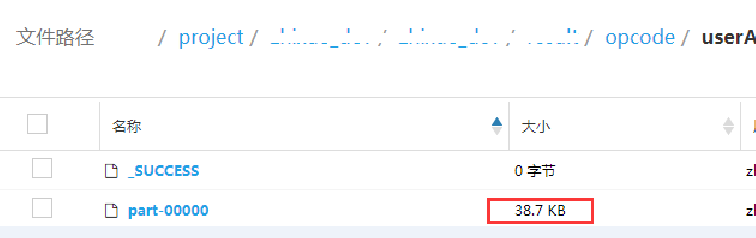

然后我下面個藍框代碼中的cache去掉,輸出如下

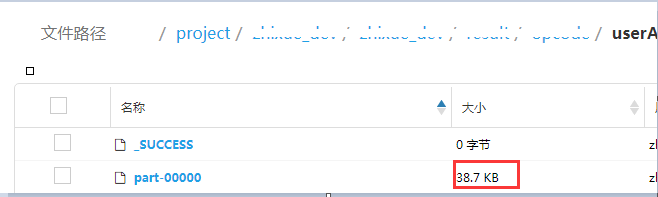
自己封裝的writeDataFrame

uj5u.com熱心網友回復:
集群用的spark是1.5的版本uj5u.com熱心網友回復:
集群用的spark是1.5的版本uj5u.com熱心網友回復:
cache 回傳的是 Dataset.this.type宣告變數后,單獨呼叫cache
uj5u.com熱心網友回復:
https://blog.csdn.net/qq_32023541/article/details/79282179不設定記憶體不夠可落盤到磁盤,記憶體不夠時會丟棄舊的快取資料,照成資料缺失
uj5u.com熱心網友回復:
https://blog.csdn.net/qq_32023541/article/details/79282179不設定記憶體不夠可落盤到磁盤,記憶體不夠時會丟棄舊的快取資料,造成資料缺失
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/44151.html
標籤:Spark
上一篇:【參與調研送好禮】全民上云的時代,聽見您真實的聲音,參與就送好禮!
下一篇:【求救········】centos下,為了docker的安裝,升級了內核,從2.6升級到3.11,但卻出現iptables丟失nat表問題。【求救······