這是我的資料庫的簡化 ER 圖:
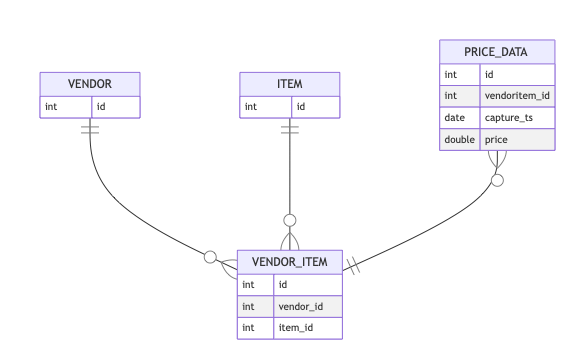
我想檢索的是,對于每個vendor_item:
- 最高價(不包括最后一次捕獲)
- 最低價(不包括最后一次捕獲)
- 當前價格(即最??后一次捕獲)
這是PRICE_DATA表格的一些示例資料,可以讓您有所了解:
| vendor_item_id | 捕獲_ts | 價錢 |
|---|---|---|
| 124 | 2022-03-02 09:00:12.851043 | 46.78 |
| 124 | 2022-03-02 14:07:49.423343 | 42.99 |
| 124 | 2022-03-04 08:20:07.636140 | 43.99 |
| 124 | 2022-03-05 08:29:20.421764 | 42.99 |
| 124 | 2022-03-08 08:33:59.043372 | 42.99 |
| 129 | 2022-03-02 08:55:14.401816 | 21.52 |
| 129 | 2022-03-02 14:11:20.544427 | 25.54 |
| 129 | 2022-03-04 08:24:06.976667 | 25.72 |
| 129 | 2022-03-08 08:22:46.734662 | 30.83 |
| 132 | 2022-03-02 09:04:18.144494 | 41.99 |
| 132 | 2022-03-03 08:29:15.981712 | 42.99 |
| 132 | 2022-03-04 08:27:39.327779 | 41.99 |
| 132 | 2022-03-07 08:29:41.236009 | 42.99 |
| 132 | 2022-03-08 08:27:44.318570 | 40.99 |
這是我到目前為止的 SQL 陳述句:
select distinct vendor_item_id
,last_value(price) over win as curr_price
,min(price) over win as low_price
,max(price) over win as high_price
from price_data
window win as (partition by vendor_item_id
order by capture_ts
rows between unbounded preceding
and unbounded following);
雖然這或多或少地給了我我想要的東西,但有幾個問題:
最高和最低價格考慮了所有記錄,而不是排除最近的捕獲。
如果我不添加
distinct到查詢中,我最終會得到重復的記錄(這可能是我的錯,因為未能正確掌握視窗功能)。
期望的結果:
| vendor_item_id | 當前價格 | 低價 | 高價 |
|---|---|---|---|
| 124 | 42.99 | 42.99 | 46.78 |
| 129 | 30.83 | 21.52 | 25.72 |
| 132 | 40.99 | 41.99 | 42.99 |
謝謝你的幫助!
uj5u.com熱心網友回復:
使用回傳最大值的 CTE,capture_ts然后vendor_item_id使用條件聚合獲取low_price和:high_price
WITH cte AS (
SELECT *, MAX(capture_ts) OVER (PARTITION BY vendor_item_id) max_capture_ts
FROM price_data
)
SELECT DISTINCT vendor_item_id,
FIRST_VALUE(price) OVER (PARTITION BY vendor_item_id ORDER BY capture_ts DESC) curr_price,
MIN(CASE WHEN capture_ts < max_capture_ts THEN price END) OVER (PARTITION BY vendor_item_id) low_price,
MAX(CASE WHEN capture_ts < max_capture_ts THEN price END) OVER (PARTITION BY vendor_item_id) high_price
FROM cte;
請參閱演示。
uj5u.com熱心網友回復:
您可以使用視窗過濾器洗掉“除了最新捕獲”要求的最后一行
select distinct
p.vendor_item_id
,last_value(p.price) over vendor_item as curr_price
,min(price) filter (where p.capture_ts < latest.capture_ts) over vendor_item as low_price
,max(price) filter (where p.capture_ts < latest.capture_ts) over vendor_item as high_price
from
price_data p
inner join (
select vendor_item_id, max(capture_ts) capture_ts from price_data group by vendor_item_id
) latest on latest.vendor_item_id = p.vendor_item_id
window
vendor_item as (
partition by p.vendor_item_id
order by p.capture_ts
rows between unbounded preceding and unbounded following
);
結果
124 42.99 42.99 46.78 129 30.83 21.52 25.72 132 40.99 41.99 42.99
我想這capture_ts是唯一的 per vendor_item_id,否則你必須創建一個更智能的過濾器。
price_data未定義索引的裸表上的查詢計劃:
查詢計劃 |--協同程式3 | |--材質化 1 | | |--掃描表price_data | | `--將 TEMP B-TREE 用于 GROUP BY | |--SCAN TABLE price_data AS p | |--SEARCH SUBQUERY 1 AS latest USING AUTOMATIC COVERING INDEX (vendor_item_id=?) | `--使用 TEMP B-TREE FOR ORDER BY |--掃描子查詢3 `--將 TEMP B-TREE 用于 DISTINCT
當定義了覆寫索引(create index ix_price_data on price_data (vendor_item_id, capture_ts, price))時,事情變得稍微簡單了一點:
查詢計劃 |--協同程式3 | |--材質化 1 | | `--使用覆寫索引 ix_price_data 掃描表 price_data | |--掃描子查詢 1 為最新 | |--搜索表 price_data AS p 使用覆寫索引 ix_price_data (vendor_item_id=?) | `--使用 TEMP B-TREE FOR ORDER BY |--掃描子查詢3 `--將 TEMP B-TREE 用于 DISTINCT
由于覆寫索引會增加資料庫大小(畢竟,所有資料都作為索引中的副本存在),您可以決定要重新創建price_data為聚集索引,即創建表WITHOUT ROWID并標記vendor_item_id, capture_ts為主鍵. 您也可以擺脫當時無用的id列。
這樣,您將獲得與顯式索引相同的性能,但不會增加資料庫的大小(事實上,由于 row_id 已經消失,表應該會變得更小)。查詢計劃保持不變。
uj5u.com熱心網友回復:
我最終使用 CTE 和常規聚合函式來解決這個問題:
with v_last_capture as (
select vendor_item_id
,max(capture_ts) last_capture_ts
from price_data pd
group by vendor_item_id
)
, v_curr_price as (
select pd.*
from price_data pd
inner join v_last_capture vc
on (pd.vendor_item_id = vc.vendor_item_id and
pd.capture_ts = vc.last_capture_ts)
)
, v_other_prices as (
select vendor_item_id
,min(pd.price) as min_price
,max(pd.price) as max_price
from price_data pd
where id not in (select id from v_curr_price)
group by vendor_item_id
)
select vc.id
,vc.vendor_item_id
,vc.price as curr_price
,vc.stock
,vo.min_price
,vo.max_price
from v_curr_price vc
left join v_other_prices vo on (vc.vendor_item_id = vo.vendor_item_id)
解釋計劃:
QUERY PLAN
|--MATERIALIZE 4
| |--SCAN TABLE price_data AS pd
| `--USE TEMP B-TREE FOR GROUP BY
|--MATERIALIZE 5
| |--SCAN TABLE price_data AS pd
| |--LIST SUBQUERY 6
| | |--MATERIALIZE 8
| | | |--SCAN TABLE price_data AS pd
| | | `--USE TEMP B-TREE FOR GROUP BY
| | |--SCAN SUBQUERY 8 AS vc
| | `--SEARCH TABLE price_data AS pd USING AUTOMATIC COVERING INDEX (vendor_item_id=? AND capture_ts=?)
| `--USE TEMP B-TREE FOR GROUP BY
|--SCAN TABLE price_data AS pd
|--SEARCH SUBQUERY 4 AS vc USING AUTOMATIC COVERING INDEX (vendor_item_id=?)
`--SEARCH SUBQUERY 5 AS vo USING AUTOMATIC COVERING INDEX (vendor_item_id=?)
@forpas的答案同樣有效(并且查詢更簡潔)。這是他的查詢的解釋計劃:
QUERY PLAN
|--CO-ROUTINE 3
| |--CO-ROUTINE 4
| | |--CO-ROUTINE 1
| | | |--CO-ROUTINE 5
| | | | |--SCAN TABLE price_data
| | | | `--USE TEMP B-TREE FOR ORDER BY
| | | `--SCAN SUBQUERY 5
| | |--SCAN SUBQUERY 1
| | `--USE TEMP B-TREE FOR ORDER BY
| |--SCAN SUBQUERY 4
| `--USE TEMP B-TREE FOR ORDER BY
|--SCAN SUBQUERY 3
`--USE TEMP B-TREE FOR DISTINCT
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/442099.html