MRS IoTDB時序資料庫的總體架構設計與實作
MRS IoTDB是華為FusionInsight MRS大資料套件最新推出的時序資料庫產品,其領先的設計理念在時序資料庫領域展現出越來越強大的競爭力,得到了越來越多的用戶認可,為了大家更好地了解MRS IoTDB,本文將會系統地為大家介紹MRS IoTDB的來龍去脈和功能特性,重點為大家介紹MRS IoTDB時序資料庫的整體架構設計與實作,
- 什么是時序資料庫
時序資料庫是時間序列資料庫的簡稱,指的是專門對帶時間標簽(按照時間的順序變化,即時間序列化)的資料進行存盤、查詢、分析等處理操作的專用資料庫系統,通俗來說,時序資料庫就是專門用來記錄例如物聯網設備的溫度、濕度、速度、壓力、電壓、電流以及證券買入賣出價等隨著時間演進不斷變化的各類數值(測點、事件)的資料庫,
當前,隨著大資料技術發展和應用的不斷深入,以物聯網IoT(Internet Of Things)、金融分析為代表的兩類資料,表現出隨著時間的演進連續不斷地產生大量傳感器數值或事件資料,時間序列資料(time series data)就是以資料(事件)發生的時刻(時間戳)為時間軸形成的連續不斷的數值序列,例如某物聯網設備不同時刻的的溫度資料構成一個時間序列資料:
| 時間戳 | 設備ID | 溫度 |
|---|---|---|
| T1 | D1 | 28 |
| T2 | D2 | 31 |
| T3 | D3 | 12 |
| T4 | D4 | 89 |
無論是機器產生的傳感器資料,還是人類活動產生的社會事件資料,都有一些共同的特征:
(1)采集頻率高:每秒采集幾十次、上百次、十萬次乃至百萬次;
(2)采集精度高:最少支持毫秒級采集,有些需要支持微秒級和納秒級采集;
(3)采集跨度大:7*24小時持續不斷地連續采集幾年、乃至數十年資料;
(4)存盤周期長:需要支持時序資料的持久存盤,甚至對有些資料需要進行長達上百年的永久存盤(例如地震資料);
(5)查詢視窗長:需要支持從毫秒、秒、分鐘、小時到日、月、年等不同粒度的時間視窗查詢;也需要支持萬、十萬、百萬、千萬等不同粒度的數量視窗查詢;
(6)資料清洗難:時間序列資料存在亂序、缺失、例外等復雜情況,需要專用演算法進行高效實時處理;
(7)實時要求高:無論是傳感器資料還是事件資料,都需要毫秒級、秒級的實時處理能力,以確保實時回應和應急處理能力;
(8)演算法專業強:時間序列資料在地震、金融、電力、交通等不同領域,都有很多垂直領域的專業時序分析需求,需要利用時序趨勢預測、相似子序列分析、周期性預測、時間移動平均、指數平滑、時間自回歸分析以及基于LSTM的時序神經網路等演算法進行專業分析,
從時序資料的共同特征可以看出,時間序列特殊的場景需求給傳統的關系資料庫存盤和大資料存盤都帶來了挑戰,無法是采用關系資料庫進行結構化存盤,還是采用NoSQL資料庫進行存盤,都無法滿足海量時序資料高并發實時寫入和查詢的需求,因此,迫切需要一種專門用于存盤時間序列資料的專用資料庫,時序資料庫的概念和產品就這樣誕生了,
需要注意的是:時序資料庫不同于時態資料庫和實時資料庫,時態資料庫(Temporal Database)是一種能夠記錄物件變化歷史,即能夠維護資料的變化經歷的資料庫,比如TimeDB,時態資料庫是對傳統關系資料庫中時間記錄的時間狀態進行細粒度維護的系統,而時序資料庫完全不同于關系資料庫,只存盤不同時間戳對應的測點值,有關時序資料庫與時態資料庫的更詳細對比,后續將會發文專門介紹,在此不再詳述,
時序資料庫也不同于實時資料庫,實時資料庫誕生于傳統工業,主要是因為現代工業制造流程及大規模工業自動化的發展,傳統關系資料庫難以滿足工業資料的存盤和查詢需求,因此,在80年代中期,誕生了適用于工業監控領域的實時資料庫,由于實時資料庫誕生早,在擴展性、大資料生態對接、分布式架構、資料型別等方面存在局限,但是也有產品配套齊全、工業協議對接完整的優勢,時序資料庫誕生于物聯網時代,在大資料生態對接、云原生支持等方面更有優勢,
時序資料庫與時態資料庫、實時資料庫的基本對比資訊如下:
|時序資料庫|時態資料庫|實時資料庫
:---??:--??:---??:---:
誕生時代|誕生于物聯網時代|誕生于20世紀80年代|誕生于傳統工業時代
與關系資料庫關系|對關系資料庫無直接關系|對關系資料庫的時態擴展|對關系資料庫的擴展增強
時間序列處理能力|適合處理時間序列|不適合處理時間序列|適合處理時間序列
架構|分布式架構|非分布式架構|非分布式架構
生態對接|大資料生態對接|缺乏大資料生態對接|缺乏大資料生態對接|缺乏大資料生態對接
2.什么是MRS IoTDB時序資料庫
MRS IoTDB是華為FusionInsight MRS大資料套件中的時序資料庫產品,在深度參與Apache IoTDB社區開源版的基礎上推出的高性能企業級時序資料庫產品,IoTDB顧名思義,是針對IoT物聯網領域推出的專用時序資料庫軟體,是由清華大學發起的國產Apache開源軟體,自IoTDB誕生之初,華為就深度參與IoTDB的架構設計和核心代碼貢獻,對IoTDB集群版的穩定性、高可用和性能優化投入了大量人力并提出了大量的改進建議和貢獻了大量的代碼,
IoTDB在設計之初,全面分析了市面上的時序資料庫相關產品,包括基于傳統關系資料庫的Timescale、基于HBase的OpenTSDB、基于Cassandra的KariosDB、基于時序專屬結構的InfluxDB等主流時序資料庫,借鑒了不同時序資料在實作機制方面的優勢,形成了自己獨特的技術優勢:
(1)支持高速資料寫入
獨有的基于兩階段LSM合并的tLSM演算法有效保障了IoTDB即使在亂序資料存在的情況下也能輕松實作單機每秒千萬測點資料的并發寫入能力,
(2)支持高速查詢
支持TB級資料毫秒級查詢
(3)功能完備
支持CRUD等完整的資料操作(更新通過對同一設備同一時間戳的測點資料覆寫寫入來實作,洗掉通過設定TTL過期時間來實作),支持頻域查詢,具備豐富的聚合函式,支持相似性匹配、頻域分析等專業時序處理,
(4)介面豐富,簡單易用
支持JDBC介面、Thrift API介面和SDK等多種介面,采用類SQL陳述句,在標準SQL的陳述句上增加了對于時間滑動視窗的統計等時序處理常用的功能,提供了系統使用效率,Thrift API介面支持Java、C\C++、Python、C#等多語言介面呼叫,
(5)低存盤成本
IoTDB獨立研發的TsFile時序檔案存盤格式,專門針對時序處理處理做了優化,基于列式存盤,支持顯式的資料型別宣告,不同資料型別自動匹配SNAPPY、LZ4、GZIP、SDT等不同的壓縮演算法,可實作1:150甚至更高的壓縮比(資料精度進一步降低的情況下),極大地降低了用戶的存盤成本,例如某用戶原來用9臺KariosDB服務器存盤的時序資料,IoTDB用1臺同等配置的服務器即可輕松實作,
(6)云邊端多形態部署
IoTDB獨有的輕量級架構設計保障了IoTDB可以輕松實作“一套引擎打通云邊端,一份資料兼容全場景”,在云服務中心,IoTDB可以采用集群部署,充分發揮云的集群處理優勢;在邊緣計算位置,IoTDB可以在邊緣服務器上部署單機IoTDB,也可以部署少量節點的集群版,具體視邊緣服務器配置而定;在設備終端,IoTDB可以TsFile檔案的形態直接嵌入到終端設備的本地存盤中,并直接被設備終端的直接讀寫TsFile檔案,不需要IoTDB資料庫服務器的啟動運行,極大地減少了對終端設備處理能力的要求,由于TsFile檔案格式開放,終端任意語言和開發平臺可以直接讀寫TsFile的二進制位元組流,也可以利用TsFile自帶的SDK進行讀寫,對外甚至可以通過FTP將TsFile檔案發送到邊緣或云服務中心,
(7)查詢分析一體化
IoTDB一份資料同時支持實時讀寫與分布式計算引擎分析,TsFile與IoTDB引擎的松耦合設計保障了一方面IoTDB可以利用專有的時序資料處理引擎對時序資料進行高效寫入和查詢,同時TsFile也可以被Flink、Kafka、Hive、Pulsar、RabbitMQ、RocketMQ、Hadoop、Matlab、Grafana、Zeepelin等大資料相關組件進行讀寫分析,極大地提升了IoTDB的查詢分析一體化能力和生態擴展能力,

3. MRS IoTDB的整體架構
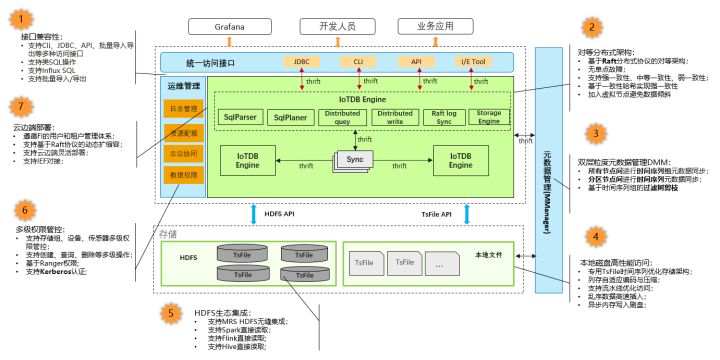
MRS IoTDB在Apache IoTDB已有架構的基礎上,融合MRS Manager強大的日志管理、運維監控、滾動升級、安全加固、高可用保障、災備恢復、細粒度權限管控、大資料生態集成、資源池優化調度等企業級核心能力,對Apache IoTDB內核架構尤其是分布式集群架構做了大量的重構優化,在穩定性、可靠性、可用性和性能方面做了大量的系統級增強,
(1)介面兼容性:
進一步完善北向介面和南向介面,支持JDBC、Cli、API、SDK、MQTT、CoAP、Https等多種訪問介面,進一步完善類SQL陳述句,兼容大部分Influx SQL,支持批量匯入匯出
(2)分布式對等架構:
MRS IoTDB在基于Raft協議的基礎上,采用了改進的Multi-Raft協議,并對Muti-Raft協議的底層實作進行了優化,采用了Cache Leader等優化策略在保障無單節故障的基礎上,進一步提升MRS IoTDB資料查詢路由的性能;同時,對強一致性、中等一致性和弱一致性策略進行了細粒度優化;對一致性哈希演算法加入虛擬節點策略避免資料傾斜,同時融合了查表與哈希磁區的演算法策略,在提升集群高可用的基礎上進一步保障集群調度的性能,
(3)雙層粒度元資料管理:
由于采用了對等架構,元資料資訊自然分布在集群所有節點上進行存盤,但是由于元資料的存盤量較大會帶來記憶體的較大消耗,為了平衡記憶體消耗與性能,MRS IoTDB采用了雙層粒度元資料管理架構,首先在所有節點間進行時間序列組元資料的同步,其次在磁區節點間進行時間序列元資料的同步,這樣在查詢元資料的時候,首先會基于時間序列組進行過濾樹剪枝,大大減少搜尋空間,然后在進一步在過濾后的磁區節點進行時間序列元資料的查詢,
(4)本地磁盤高性能訪問:
MRS IoTDB采用專用的TsFile檔案格式進行時間序列優化存盤,采用列存格式進行自適應編碼與壓縮,支持流水線優化訪問和亂序資料高速插入
(5)HDFS生態集成:
MRS IoTDB支持HDFS檔案讀寫,并對HDFS進行了本地快取、短路讀、HDFS I/O執行緒池等多種優化手段,全面提升MRS IoTDB對HDFS的讀寫性能,同時,MRS IoTDB支持華為OBS物件存盤并進行了更加高性能的深度優化,
在HDFS集成的基礎上,MRS IoTDB支持Spark、Flink、Hive等MRS組件對TsFile的高效讀寫,
(6)多級權限管控:
支持存盤組、設備、傳感器等多級權限管控
支持創建、洗掉、查詢等多級操作
支持Kerberos認證
支持Ranger權限架構
(7)云邊端部署:
支持云邊端靈活部署,邊緣部分可以基于華為的IEF產品進行對接,也可以直接部署在華為的IES中,
MRS IoTDB集群版支持動態擴縮容,可以為云邊端提供更加靈活的部署支持,
4. MRS IoTDB的單機架構
4.1 MRS IoTDB的基礎概念
MRS IoTDB主要聚焦在IoT物聯網領域的設備傳感器測點值的實時處理,因此,MRS IoTDB的基礎架構設計以設備、傳感器為核心概念,同時為了便于用戶使用和IoTDB管理時間序列資料,增加了存盤組的概念,下面為大家分別解釋一下:
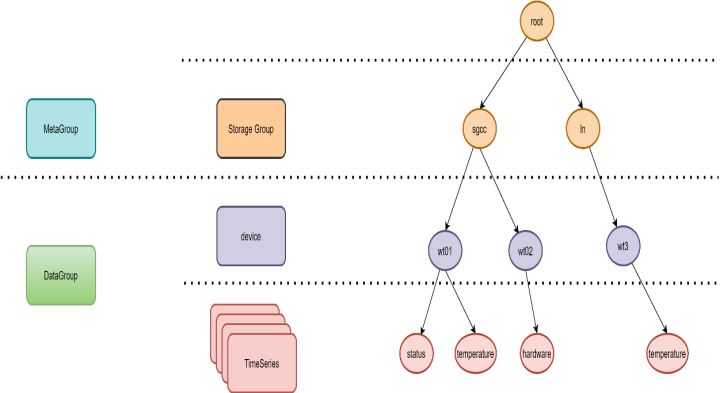
存盤組(Storage Group): IoTDB為了管理時序資料提出的一個概念,類似于關系資料庫中的資料庫的概念,從用戶角度,主要用于對設備資料進行分組管理;從IoTDB資料庫角度,存盤組又是一個并發控制和磁盤隔離的單位,不同存盤組之間可以并行讀寫,
設備 (Device):對應現實世界中的具體物理設備,例如:電廠某制造單元、風力發電機、汽車、飛機發動機、地震波采集儀器等,在IoTDB中, device是時序資料一次寫入的單位,一次寫入請求局限在一個設備中,
傳感器(Sensor): 對應現實世界中的具體物理設備自身攜帶的傳感器,例如:風力發電機設備上的風速、轉向角、發電量等資訊采集的傳感器,在IoTDB中,Sensor也稱為測點(Measurement),具體指傳感器采集的某時刻的傳感器值,在IoTDB內部采用的形式進行列式存盤,
存盤組、設備、傳感器的關系如下面的例子:
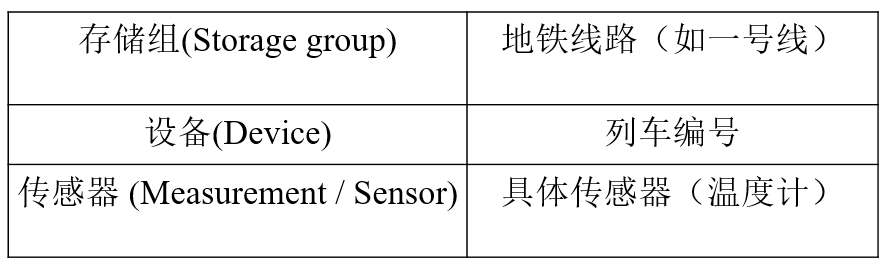
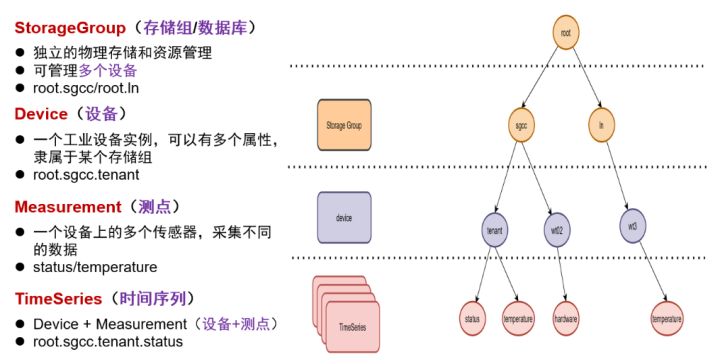
時間序列(Time Series): 類似于關系資料庫中的一張表,不過這張表主要有時間戳(Timestamp)、設備ID(Device ID)、測點值(Measurement)三個主要欄位,為了便于對時間序列的設備資訊進行更多描述,IoTDB還增加了Tag和Field等擴展欄位,其中Tag支持索引,Field不支持索引,在有的時序資料庫中,又稱為時間線,表示記錄某設備某傳感器值隨著時間不斷變化的值,形成一條沿著時間軸不斷追加測點值的時間線,
路徑(Path):IoTDB構造了一個以root為根節點、把存盤組、設備、傳感器串聯在一起的樹形結構,從root根節點經過存盤組、設備到傳感器葉子節點,構成了一條路徑,如下圖所示:
虛擬存盤組:由于存盤組的概念具有用戶對設備分組和系統進行并發控制的雙重作用,二者的過度耦合會造成用戶的不同使用方式對系統并發控制的影響,例如:用戶把不相關的所有設備資料都放到一個存盤組中,IoTDB對這個存盤組加鎖進行并發控制,限制了資料的并發讀寫能力,為了是實作存盤組與并發控制的相對松耦合,IoTDB設計了虛擬存盤組這個概念,把對存盤組的并發控制細粒度拆分到虛擬存盤組這個粒度,從而減少了并發控制的粒度,
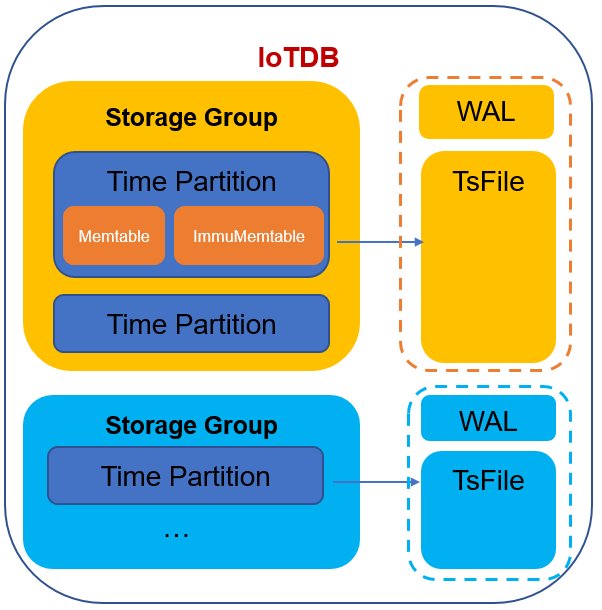
4.2 MRS IoTDB的基本架構
單機MRS IoTDB主要不同的存盤組構成,每個存盤組是一個并發控制和資源隔離單位,每個存盤組里面包括了多個Time Partition,其中,每個存盤組對應一個WAL預寫日志檔案和TsFile時序資料存盤檔案,每個Time Partition中的時序資料先寫入Memtable,同時記入WAL,定時異步刷盤到TsFile,具體實作機制后續會給大家詳細介紹,MRS IoTDB單機的基本架構如下:
5. MRS IoTDB的集群架構
5.1 基于Multi-Raft的分布式對等架構
MRS IoTDB集群是完全對等的分布式架構,既基于Raft協議避免了單點故障問題,又通過Multi-Raft協議避免了單一Raft共識組帶來的單點性能問題,同時對分布式協議的底層通訊、并發控制和高可用機制做了進一步優化,
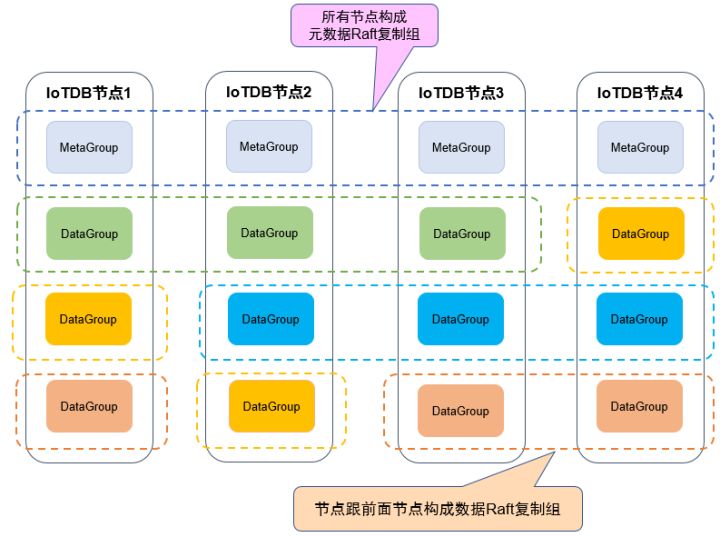
首先,整個集群的所有節點構成一個元資料組(MetaGroup),只用于維護存盤組的元資料資訊,例如下圖藍灰色框所示的一個4節點的IoTDB集群,全部4個節點構成一個元資料組(MetaGroup);
其次,根據資料副本數構造資料組,例如副本數為3,則構造一個包括3個節點的資料組(DataGroup),存盤組用于存盤時間序列資料及對應的元資料,
分布式系統中通常以多副本的方式實作資料的可靠存盤,同一份資料的多個副本存盤在不同的節點中且必須保證一致,因此需要使用Raft共識協議來保證資料的一致性,它將一致性的問題拆分成了幾個相對獨立的子問題,即領導者選舉、日志復制、一致性保證等,Raft協議中有以下重要的概念:
(1)Raft組,Raft組中有一個通過選舉產生的leader節點,其他節點是follower,當一個寫入請求到來時,首先要提交給leader節點處理,leader節點先在自己的日志里面記錄下這個寫入請求,然后將這條日志分發到follower節點,
(2)Raft日志,Raft通過日志的方式保證操作不會丟失,日志中維護了一個 Commit編號和Apply編號,如果一條日志被Commit,就代表目前集群中超過半數的節點都收到并持久化了這條日志,如果一條日志被Apply,就表示當前節點執行了這條日志,當某些節點出現故障并重新恢復時,該節點的日志就會落后于leader的日志,則在這個節點追上leader的日志之前,它不能向外界正常提供服務,
5.2 元資料分層管理
元資料管理策略是MRS IoTDB分布式設計中的要點,在進行元資料管理策略設計時首先要考慮元資料在讀寫流程中的用途:
寫入資料時需要元資料進行資料型別、權限等合法性檢查;
查詢資料時需要元資料進行查詢路由,同時,由于時序資料場景中元資料龐大,還需要考慮元資料對記憶體資源的消耗,
現有的元資料管理策略要么采用將元資料交由元資料節點專門管理的方式,這種方法會降低讀寫性能; 要么采用在集群所有節點全量保存元資料的方式,這種方式會消耗大量的記憶體資源,
為了解決上述問題,MRS IoTDB設計了雙層粒度元資料管理策略,其核心思想是通過將元資料拆分為存盤組和時間序列兩層分別管理:
(1)存盤組元資料:元資料組(MetaGroup)包含了查詢資料時的路由資訊,存盤組(Storage Group)的元資料資訊在集群所有節點上全量保存,存盤組的粒度較大,一個集群內部的存盤組數量級遠遠小于時間序列的數量級,因此在集群所有節點上對這些存盤組元資料的保存,大大減少了記憶體的占用,
元資料組中的每個節點稱為元資料持有者,采用Raft協議來保證每個持有者與同組的其他持有者的資料一致性,
(2)時間序列元資料:資料組(DataGroup)中的時間序列元資料中包含了資料寫入時需要的資料型別、權限等資訊,這些資訊保存在資料組所在節點(集群部分節點)上,由于時間序列元資料的粒度較小,數量遠遠多于存盤組元資料,因此這些時間序列元資料保存在資料組所在的節點上,避免了不必要的記憶體占用,同時也能通過存盤組元資料的一級過濾快速定位,同時資料組的Raft一致性也避免了時間序列元資料存盤的單點故障,
資料組中的每個節點稱為資料磁區持有者,采用Raft協議來保證每個持有者與同組的其他持有者的資料一致性,
該方法將元資料按存盤組和時間序列兩層粒度分別在元資料持有者和資料磁區持有者中管理,由于時間序列資料和元資料在資料組內同步,因此每次資料寫入不需要進行元資料的檢查與同步操作,僅需要在修改時間序列元資料時進行存盤組元資料的檢查與同步操作,從而提高系統性能,例如創建一個時間序列并進行50萬次資料寫入的操作中,元資料檢查與同步操作從50萬次降至1次,
5.3 元資料分布
根據元資料分層管理可知,元資料分為存盤組元資料和時間序列元資料,
存盤組元資料在全集群所有的節點上都有副本,屬于MetaGroup組,
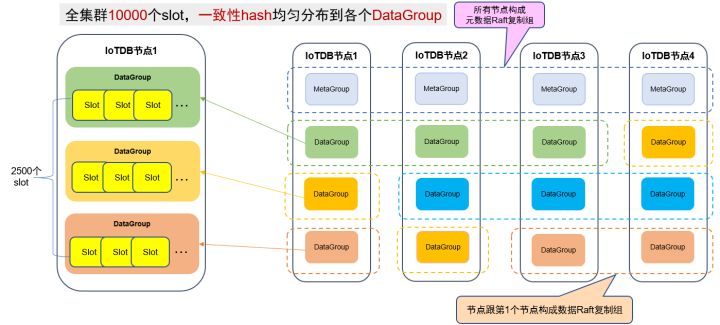
時間序列元資料只在對應的DataGroup上存盤,存盤一些時間序列的屬性,欄位型別,欄位描述等資訊,時間序列元資料的分布方式和資料分布方式一樣,都是通過slot hash產生,
5.4 時間序列資料分布
分布式系統實作中基于哈希環和環上查找演算法將時序資料按照存盤組進行磁區,將集群各個節點按哈希值放到哈希環上,對于到來的一個時間序列資料點,計算這個時間序列名稱所對應的存盤組的哈希值并放置到哈希環上,在環上按順時針方向進行搜索,找到的第1個節點就是要插入的節點,
使用哈希環進行資料磁區時,容易出現兩個節點的哈希值的差較小的情況,因此在使用一致性哈希環的基礎上引入虛擬節點,具體做法是將每個物理節點虛擬成若干個,并將這些虛擬節點按照哈希值放置到哈希環上,在很大程度上避免了資料傾斜的情況,使資料分布得更加均勻,
首先,整個集群預設10000個slot,均勻將此10000個slot分布在各個DataGroup上,如下圖所示,IoTDB集群有4個DataGroup,整個集群有10000個slot,則平均每個DataGroup有10000/4=2500個slot.由于DataGroup的數量等于集群節點數4,也就相當于平均每個節點2500個slot.
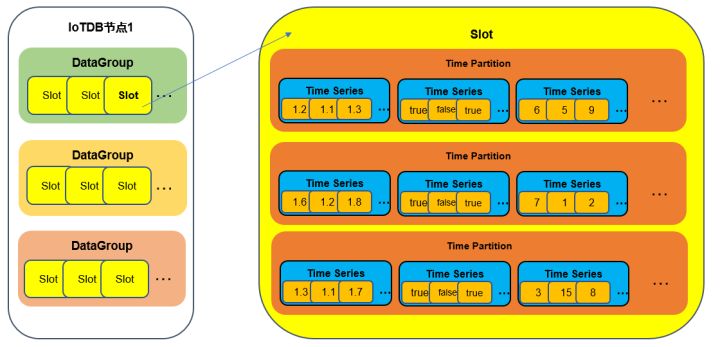
其次, 完成slot到DataGroup、Time Partition和time series的映射,
IoTDB集群根據raft協議劃分成多個DataGroup組,每一個DataGroup組中包含多個slot,而每一個slot中包含多個time partition,同時每一個time partition中包含多個time series,構成關系如下圖所示:
最后,通過Hash計算slot的值,完成輸入存盤組和時間戳到slot的映射:
1)先按時間范圍磁區,利于時間范圍查詢:
TimePartitionNum = TimeStamp % PartitionInterval
其中TimePartitionNum是時間磁區的ID,TimeStamp是待插入測點資料的時間戳,PartitionInterval是時間磁區間隔,默認是7天,
2)再按存盤組磁區,通過Hash計算出slot的值:
Slot = Hash(StorageGroupName + TimePartitionNum) % maxSlotNum
其中StorageGroupName是存盤組的名字,TimePartitionNum是第1步計算出的時間磁區ID,maxSlotNum是最大slot數,默認10000,
Data Group和Storage Group的關系如下圖所示,其中節點3和節點1上的Data Group 1展示的是同一個Data Group分布在兩個節點上的情形:
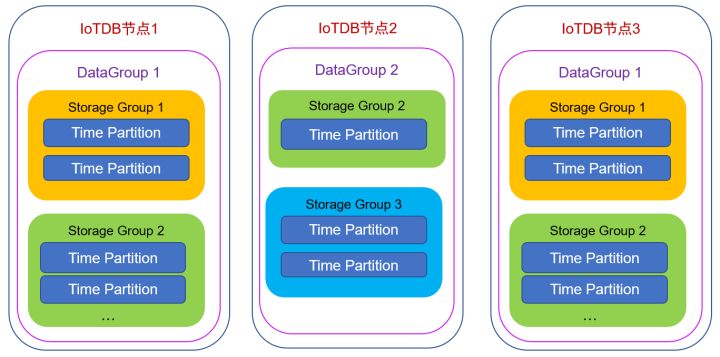
以上給大家介紹了MRS IoTDB的總體架構,下一篇文章將為大家進一步介紹集群架構的資料寫入、資料查詢、一致性協議的實作等技術細節,敬請期待,
本文由華為云發布,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/444379.html
標籤:其他
下一篇:軟體自動化測驗工具的選擇