1.導引
計算機科學一大定律:許多看似過時的東西可能過一段時間又會以新的形式再次回歸,
在聯邦學習領域,許多傳統機器學習已經討論過的問題(甚至一些90年代和00年代的論文)都可以被再次被發明一次,比如我們會發現聚類聯邦學習和多任務學習之間就有千絲萬縷的聯系,
2. 多任務學習回顧
我們在博客《基于正則化的多任務學習》中介紹了標準多任務學習的核心是多任務個性化權重+知識共享[1],如多任務學習最開始提出的模型即為一個共享表示的神經網路:
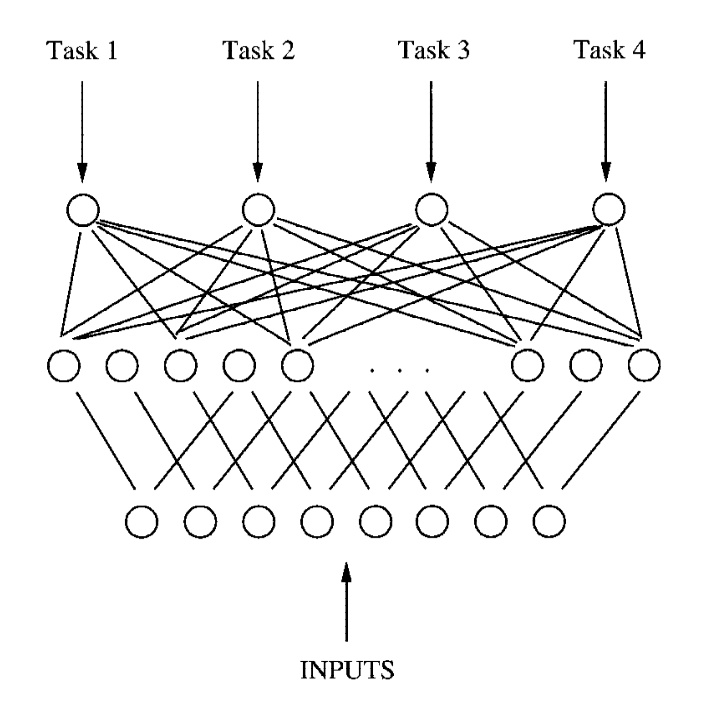
而多任務學習中有一種方法叫聚類多任務學習,聚類多任務學習基本思想為:將任務分為若個個簇,每個簇內部的任務在模型引數上更相似, 最早的聚類多任務學習的論文[2]為一種一次性聚類(one-shot clustering),即將任務聚類和引數學習分為了兩個階段:第一階段,根據在各任務單獨學習得到的模型來聚類,確定不同的任務簇,第二階段,聚合同一個任務簇中的所有訓練資料,以學習這些任務的模型,這種方法把任務聚類和模型引數學習分為了兩個階段,可能得不到最優解,因此后續作業都采用了迭代式聚類(iterative clustering),即在訓練迭代中同時學習任務聚類和模型引數的方法,
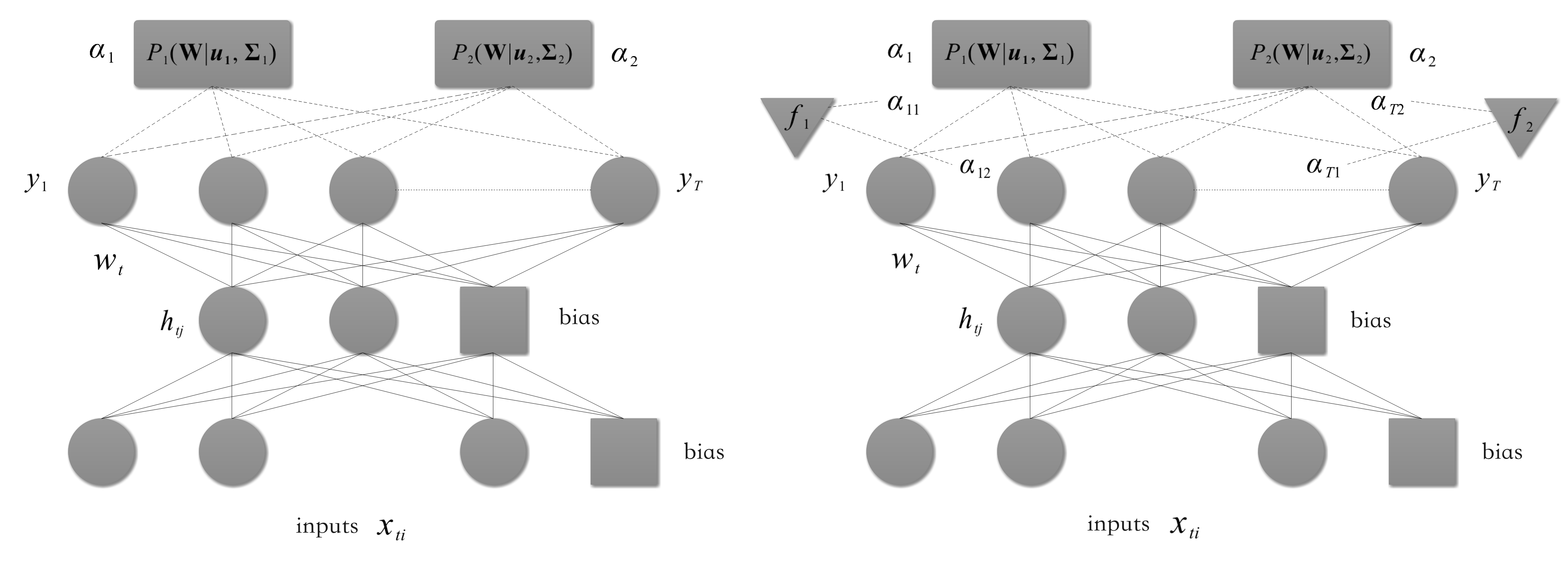
我們著重介紹Bakker等人(2003)[3]提出了一個多任務貝葉斯神經網路(multi-task Bayesian neural network),其結構與我們前面所展現的共享表示的神經網路相同,其亮點在于基于連接隱藏層和輸出層的權重采用高斯混合模型(Gaussian mixture model)對任務進行分組,若給定資料集\(\mathcal{D} = \{D_t\}, t=1,...,T\),設隱藏層維度為\(h\),輸出層維度為\(T\),\(\mathbf{W}\in \mathbb{R}^{T\times (h + 1)}\)代表隱藏層到輸出層的權重矩陣(結合了偏置),我們假定每個任務對應的權重向量\(\mathbf{w}_t\)(\(\mathbf{W}\)的第\(t\)列)關于給定超引數獨立同分布,我們假定第\(t\)個任務先驗分布如下:
\[\bm{w}_t \sim \mathcal{N}(\bm{w}_t | \bm{u}, \mathbf{\Sigma}) \tag{8} \]這是一個高斯分布,均值為\(\bm{u} \in \mathbb{R}^{h + 1}\),協方差矩陣\(\mathbf{\Sigma} \in \mathbb{R}^{ (h+1) \times (h+1)}\),
我們上面的定義其實假定了所有任務屬于一個簇,接下來我們假定我們有不同的簇(每個簇由相似的任務組成),我們設有\(C\)個簇(cluster),則任務\(t\)的權重\(w_t\)為\(C\)個高斯分布的混合分布:
其中,每個高斯分布可以被認為是描述一個任務簇,式\((9)\)中的\(\alpha_c\)代表了任務\(t\)被分為簇\(c\)的先驗概率,其中task clustering(如下面左圖所示)模型中所有任務對簇\(c\)的加權\(\alpha_c\)都相同;而task-depenent模型(如下面右圖所示)中各任務對簇\(c\)的加權\(\alpha_{tc}\)不同,且依賴于各任務特定的向量\(\bm{f}_t\),
好,大家再細細品味一下這種一個任務簇對應一個概率分布的思想,下面我們介紹的很多聚類聯邦學習演算法都體現有這種思想的思想,
3. 潛在聚類結構的的前置假設
上面我們提到的這種來自于上個世紀90年代的多任務學習思想并未過時,近年來在個性化聯邦學習中又重新煥發了生機,這篇文章我們就來歸納一下與多任務學習思想關系密切的聯邦學習個性化方法之一——聚類聯邦學習,
聚類聯邦學習基本上都基于這樣一個假設:雖然聯邦學習中各節點的資料是Non-IID的,但是我們可以假定某些節點的資料可以歸為一個聚類簇(簇內節點的分布近似IID),實際上,這個思想讓我們聯想到高斯混合分布,高斯混合分布就假設每個節點的資料采樣自高斯混合分布中的一個成分(對應一個簇),而經典的高斯混合聚類就是要確定每個節點和簇的對應關系,如果采用這種假設,那么在做實驗時就可以考慮基于混合分布的劃分方法,參見我的博客《基于混合分布的多任務學習》,
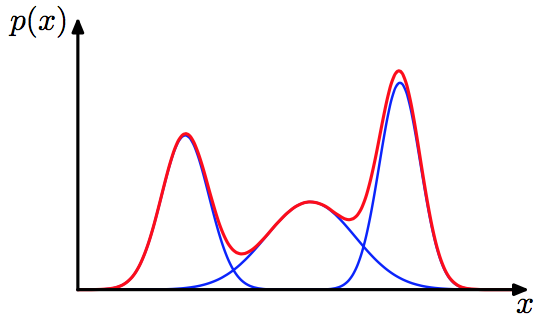
注意,雖然這里假定每個聚類簇對應一個成分分布,但現實情況的資料分布是模糊的,不同簇之間的資料仍然可能會有關聯,而這就為我們進行簇間的多任務知識共享提供了動機,
按照其聚類的時間,我們按照上文聚類多任務學習的分發,可將聚類聯邦學習的方法也分為一次性聚類和迭代式聚類,
一次性聚類即在模型訓練開始之前就先對client資料進行聚類,因為client資料不出庫,常常將\(T\)個client初步訓練后的引數\(\{\widetilde{\theta}_t\}^T_{t=1}\)發往server,然后由server將\(T\)個client聚為\(S_1,...,S_k\),然后對每一個類\(k(k\in [K])\),運行傳統聯邦學習方法(如FedAvg[5]或二階方法[6][7])求解出最終的\(\hat{\theta}_k\),注意, 此種方式默認每個聚類簇得到一個引數\(\hat{\theta}_k\),同樣,類似我們上面對一次性聚類多任務學習的分析,如果一旦開局的聚類演算法產生了錯誤的估計,那么接下來的時間里演算法將無法對其進行更正,此外,這種方法常常使用類似于K-means的距離聚類方法,而從理論上講對于神經網路兩個模型擁有相近的引數距離,但其輸出可能大不相同(由于模型對于隱藏層單元的置換不變性),
動態式的聚類為則為在訓練的程序中一邊訓練,一邊根據模型引數\(\widetilde{\theta}_t\)的情況來動態調整聚類結果,這種方式既可以簇內任務直接廣播引數\(\theta_k\),也可以僅僅共享引數的變化量\(\Delta \theta_k\),
按照其任務劃分粒度的方式,我們可將方法分為節點間多任務和簇間多任務,節點間多任務類似聚類多任務學習,它為將每個節點視為一個任務(訓練一個個性化模型),然后將節點劃分為多個簇,簇內和簇間都會進行知識共享,簇間多任務為將節點劃分為多個簇,假定簇內資料IID,然后簇內節點直接廣播引數,此時將每個簇視為一個任務,然后再在簇間進行知識共享,
4. 聚類聯邦學習經典論文閱讀
4.1 TNNLS 2020:《Clustered Federated Learning: Model-Agnostic Distributed Multitask Optimization Under Privacy Constraints》[8]
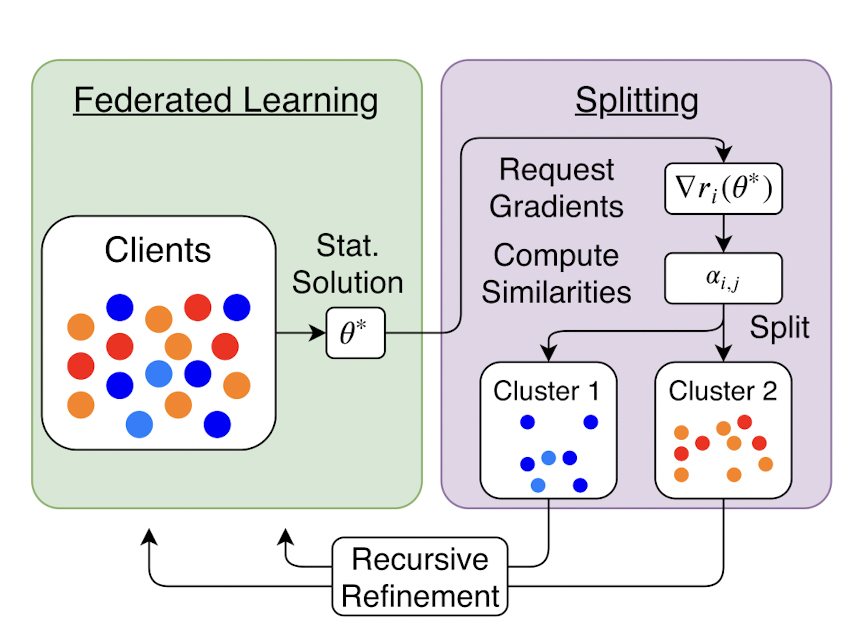
本文采用的是迭代式聚類和節點間多任務,它在每輪迭代時,都會根據節點的引數相似度進行一次任務簇劃分,同一個任務簇共享引數的變化量 \(g\),以此既能達到每個節點訓練一個個性化模型,又能完成知識共享和相似的節點相互促進的目的,本論文的亮點是聚類簇的個數可以隨著迭代變化,無需實作指定任務簇個數\(K\)做為先驗,
本篇論文演算法的每輪通信描述如下:
(1) 第\(t\)個client節點執行
- 從server接收對應的簇引數\(g_k\),
- 令\(\theta_{old}=\theta_t=\theta_t + g_k\),
- 執行\(E\)個區域epoch的SGD:\[\theta_t = \theta_t - \eta \nabla \mathcal{l}(\theta_t; b) \](此處將區域資料\(D_t\)劃分為多個\(b\))
- 將\(\widetilde{g}_t = \theta_t-\theta_{old}\)發往server,
(2) server節點執行
-
從\(T\)個client接收\(\widetilde{g}_1、\widetilde{g}_2,...\widetilde{g}_T\),
-
對每一個簇\(k\),計算簇內平均引數變化:
-
將每個簇的簇內變化\(\hat{g}_k\)發往對應的client,
-
根據不同節點引數變化量的余弦距離\(\alpha_{i,j}=\frac{\langle \widetilde{g}_i, \widetilde{g}_j\rangle}{||\widetilde{g}_i||||\widetilde{g}_j||}\)重新劃分聚類簇,
4.2 NIPS 2020:《An Efficient Framework for Clustered Federated Learning》[8]
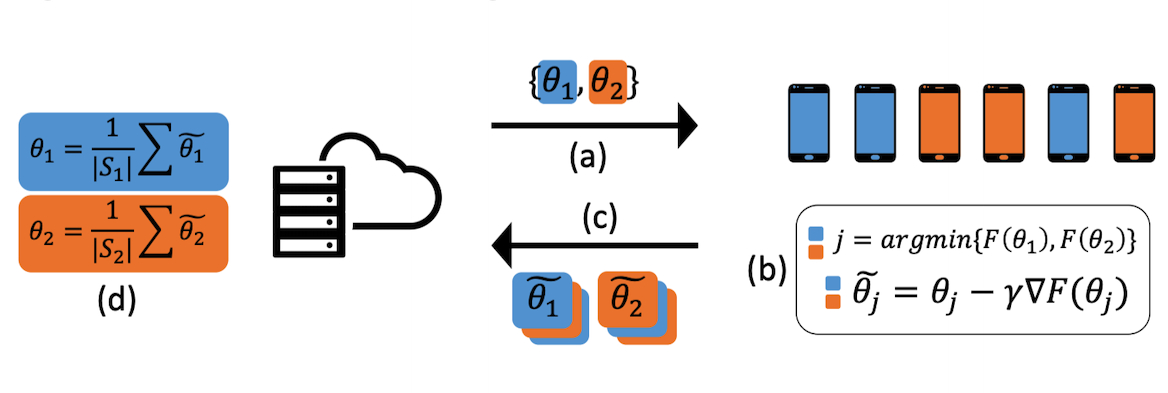
本文采用的是迭代式聚類和簇間多任務,本論文需要事先指定聚類簇的個數\(K\),它在每輪迭代時,都會根據節點的引數相似度重新進行一次任務簇劃分,第\(k\)個任務簇對其所有節點廣播引數\(\theta_k\),也就是說每個聚類簇構成一個學習任務(負責學習屬于該任務簇的個性化模型),
本篇論文演算法的每輪通信描述如下:
(1) 第\(t\)個client節點執行
-
從server接收簇引數\(\theta_1,\theta_2,...\theta_{K}\)
-
估計其所屬的簇:\(\hat{k}=\underset{k\in[K]}{\text{argmin }}\mathcal{l}(\theta_k;D_t)\)
-
對簇引數執行\(E\)個區域epoch的SGD:
\[\theta_k = \theta_k - \eta \nabla \mathcal{l}(\theta_k; b) \](此處將區域資料\(D_t\)劃分為多個\(b\))
-
將最終得到的簇引數做為\(\widetilde{\theta}_t\),并和該client對應的簇劃分一起發往server,
(2) server節點執行
-
從\(T\)個client接收\(\widetilde{\theta}_1、\widetilde{\theta}_2,..., \widetilde{\theta}_T\)和各client的簇劃分情況
-
根據節點引數的平均值來更新簇引數:
由于現實的聚類關系很模糊,該演算法在具體實作時效仿多任務學習中的權值共享[1]機制,允許不同簇(任務)之間共享部分引數,具體地,即在訓練神經網路模型時,先使用所有client的訓練資料學習一個共享表示,然后再運行聚類演算法為每個簇學習神經網路的最后一層(即多任務層),
4.3 WWW 2021:《PFA: Privacy-preserving Federated Adaptation for Effective Model Personalization》[9]
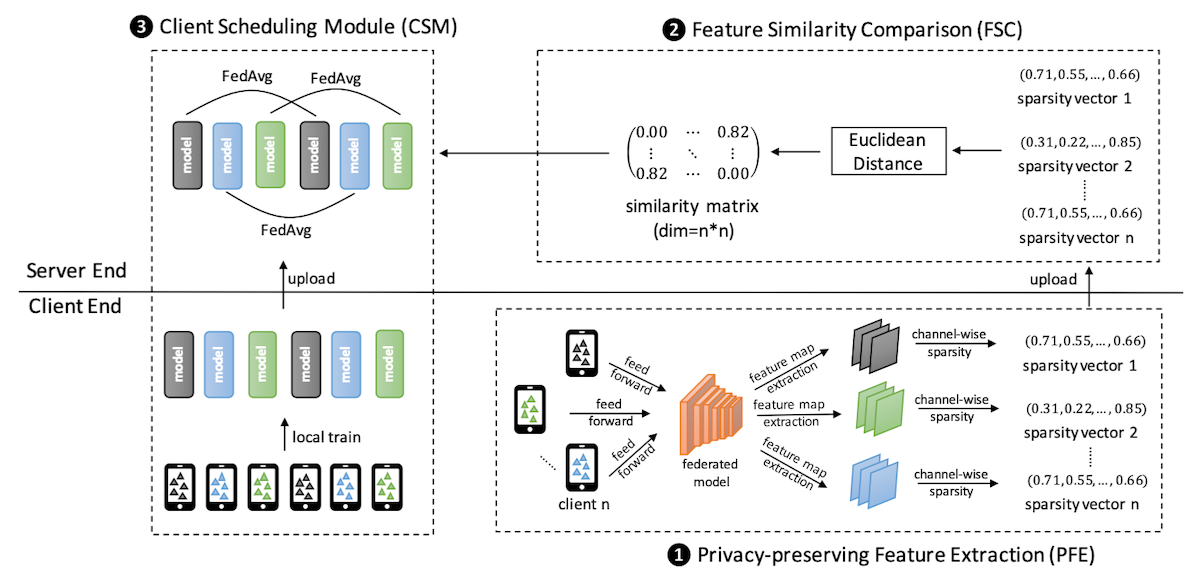
本文采用的是一次性聚類,本論文需要事先指定聚類簇的個數\(K\),然后在訓練迭代開始前,每個節點先訓練一個稀疏表征模型模型,然后將稀疏表征模型得到的稀疏向量傳到server,server再根據各client稀疏向量之間的相似度進行任務簇劃分,之后,各任務簇分別運行傳統FedAvg演算法學習每個簇對應的個性化模型,值得一提的是,雖然該演算法屬于聚類聯邦學習,但我個人認為嚴格來說它與標準的多任務學習還有一定距離,因為它的每個簇之間缺少知識共享, 不過它確物體現了“多任務”的思想,而且與我們前面講的聚類演算法關聯十分密切,最終我還是將其加入本專題,
4.4 INFOCOM 2021:《Resource-Efficient Federated Learning with Hierarchical Aggregation in Edge Computing》
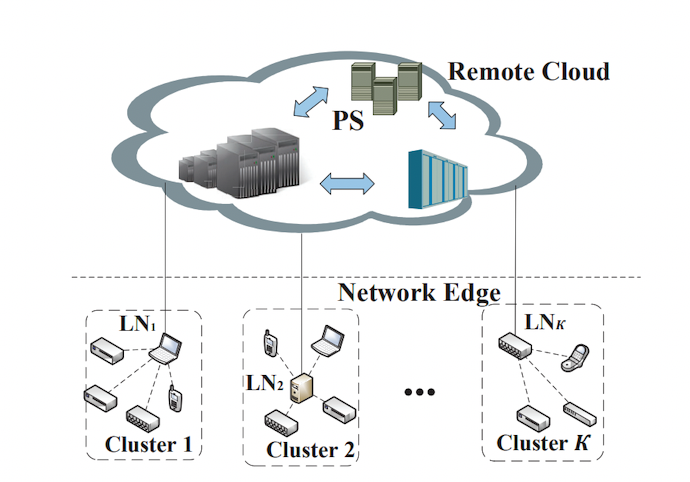 這篇文章嚴格來說不屬于上面所說的聚類聯邦學習,也不是多任務學習/個性化聯邦學習的范疇,其文中提到的clustered應該翻譯成"(局域網構成的)集群的",但我覺得這篇文章算是從另一個工程的角度來應用了分組聚合的思想,我在這里還是覺得將其介紹一下,
這篇文章嚴格來說不屬于上面所說的聚類聯邦學習,也不是多任務學習/個性化聯邦學習的范疇,其文中提到的clustered應該翻譯成"(局域網構成的)集群的",但我覺得這篇文章算是從另一個工程的角度來應用了分組聚合的思想,我在這里還是覺得將其介紹一下,
在現實工業環境下,聯邦學習常常是基于引數服務器(parameter server)的,但引數服務器位于遠程云平臺上,邊緣節點與它之間的通信經常不可用,而邊緣節點的數量龐大,這就導致通信代價可能會很高,本文的基本思想即是減少邊緣節點和PS之間的通信,加強邊緣節點之間的協作,論文將不同的client劃分為了多個局域網/集群,每個集群都有一個leader node(LN)做為集群頭,每個集群先分別運行FedAvg演算法將引數聚合到LN(集群內是同步的),然后再由PS異步地搜集各LN的引數并進行聚合,最后再將新的引數廣播到各個邊遠client,
本篇論文還考慮了每個client的資源消耗等復雜資訊,此處為了簡單起見,我們將簡化后演算法的每輪通信描述如下:
(1) 第\(t\)個client節點執行
- 從\(LN_k\)接收引數\(\theta\)做為本地的\(\theta_t\)
- 執行\(E\)個區域epoch的SGD:\[\theta_t = \theta_t - \eta \nabla \mathcal{l}(\theta_t; b) \](此處將區域資料\(D_t\)劃分為多個\(b\))
- 將新的引數\(\widetilde{\theta}_t\)發往所在簇的\(LN_k\),
(2) \(LN_k\)節點執行
-
從集群內的\(|S_k|\)個client接收引數\(\{\widetilde{\theta}_j\}(j\in S_k)\)
-
根據簇內節點引數的加權平均值來更新簇引數:
- 將簇引數\(\theta_k\)發往PS,
- 從PS接收引數\(\theta\)并將其發往client節點,
(2) PS節點執行
-
從\(k\)個\(LN_k\)節點接收\({\theta}_k\)(異步地),
-
根據一階指數平滑來更新引數:
\(\quad\quad\)(在實際論文中\(\alpha\)是一個在迭代中變化的量,此處為了簡化省略)
- 將新的引數\(\hat{\theta}\)發往\(LN_k\)
參考
-
[1] Caruana R. Multitask learning[J]. Machine learning, 1997, 28(1): 41-75
-
[2] Thrun S, O'Sullivan J. Discovering structure in multiple learning tasks: The TC algorithm[C]//ICML. 1996, 96: 489-497.
-
[3] Bakker B J, Heskes T M. Task clustering and gating for bayesian multitask learning[J]. 2003.
-
[4] Sattler F, Müller K R, Samek W. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints[J]. IEEE transactions on neural networks and learning systems, 2020, 32(8): 3710-3722.
-
[5] McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Artificial intelligence and statistics. PMLR, 2017: 1273-1282.
-
[6] Wang S, Roosta F, Xu P, et al. Giant: Globally improved approximate newton method for distributed optimization[J]. Advances in Neural Information Processing Systems, 2018, 31.
-
[7] Ghosh A, Maity R K, Mazumdar A. Distributed newton can communicate less and resist byzantine workers[J]. Advances in Neural Information Processing Systems, 2020, 33: 18028-18038.
-
[8] Ghosh A, Chung J, Yin D, et al. An efficient framework for clustered federated learning[J]. Advances in Neural Information Processing Systems, 2020, 33: 19586-19597.
-
[9] Liu B, Guo Y, Chen X. PFA: Privacy-preserving Federated Adaptation for Effective Model Personalization[C]//Proceedings of the Web Conference 2021. 2021: 923-934.
-
[10] Wang Z, Xu H, Liu J, et al. Resource-Efficient Federated Learning with Hierarchical Aggregation in Edge Computing[C]//IEEE INFOCOM 2021-IEEE Conference on Computer Communications. IEEE, 2021: 1-10.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/444405.html
標籤:其他
上一篇:【使用分享】Hive磁區表那些事
下一篇:【面經】面試基本流程