使用PCA核方法對糖尿病資料集降維
主要步驟流程:
- 1. 匯入包
- 2. 匯入資料集
- 3. 資料預處理
- 3.1 檢測缺失值
- 3.2 生成自變數和因變數
- 3.3 拆分訓練集和測驗集
- 3.4 特征縮放
- 4. 使用 Kernel PCA 降維
- 5. 構建邏輯回歸模型
- 5.1 使用原始資料構建邏輯回歸模型
- 5.2 使用降維后資料構建邏輯回歸模型
- 6. 可視化Kernel PCA 降維效果
1. 匯入包
In [2]:# 匯入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2. 匯入資料集
In [3]:# 匯入資料集
dataset = pd.read_csv('pima-indians-diabetes.csv')
dataset
Out[3]:
| preg | plas | pres | skin | test | mass | pedi | age | class | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 763 | 10 | 101 | 76 | 48 | 180 | 32.9 | 0.171 | 63 | 0 |
| 764 | 2 | 122 | 70 | 27 | 0 | 36.8 | 0.340 | 27 | 0 |
| 765 | 5 | 121 | 72 | 23 | 112 | 26.2 | 0.245 | 30 | 0 |
| 766 | 1 | 126 | 60 | 0 | 0 | 30.1 | 0.349 | 47 | 1 |
| 767 | 1 | 93 | 70 | 31 | 0 | 30.4 | 0.315 | 23 | 0 |
768 rows × 9 columns
3. 資料預處理
3.1 檢測缺失值
In [4]:# 檢測缺失值
null_df = dataset.isnull().sum()
null_df
Out[4]:
preg 0
plas 0
pres 0
skin 0
test 0
mass 0
pedi 0
age 0
class 0
dtype: int64
3.2 生成自變數和因變數
In [5]:# 生成自變數和因變數
X = dataset.iloc[:,0:8].values
y = dataset.iloc[:,8].values
3.3 拆分訓練集和測驗集
In [6]:# 拆分訓練集和測驗集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.2, random_state = 1)
print(X_train.shape)
(614, 8)
3.4 特征縮放
In [7]:# 特征縮放
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
4. 使用 Kernel PCA 降維
In [128]:# 使用 Kernel PCA 生成新的自變數
from sklearn.decomposition import KernelPCA
kernel_pca = KernelPCA(n_components = 3, kernel='sigmoid')
X_train_kernel_pca = kernel_pca.fit_transform(X_train)
print(X_train_kernel_pca)
[[ 0.53677552 0.18237473 -0.06784237]
[ 0.2525542 0.21315067 -0.10500243]
[ 0.22619011 0.14259737 -0.28290242]
...
[ 0.22015692 0.56336814 -0.19225494]
[ 0.13823718 0.09177124 0.10862359]
[ 0.15799345 0.26629945 -0.14812701]]
In [129]:
X_test_kernel_pca = kernel_pca.transform(X_test)
n_components的值需要不斷嘗試
5. 構建邏輯回歸模型
5.1 使用原始資料構建邏輯回歸模型
In [130]:# 構建模型
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(penalty='l2', C=1,
class_weight='balanced', random_state = 0)
classifier.fit(X_train, y_train)
Out[130]:
LogisticRegression(C=1, class_weight='balanced', random_state=0)
In [131]:
# 預測測驗集
y_pred = classifier.predict(X_test)
In [132]:
# 評估模型性能
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test, y_pred))
0.7922077922077922
5.2 使用降維后資料構建邏輯回歸模型
In [133]:# 構建模型
classifier = LogisticRegression(penalty='l2', C=1,
class_weight='balanced', random_state = 0)
classifier.fit(X_train_kernel_pca, y_train)
Out[133]:
LogisticRegression(C=1, class_weight='balanced', random_state=0)
In [134]:
# 預測測驗集
y_pred = classifier.predict(X_test_kernel_pca)
In [135]:
# 評估模型性能
print(accuracy_score(y_test, y_pred))
0.7727272727272727
In [137]:
import seaborn as sns
ne=pd.concat([pd.DataFrame(X_train_kernel_pca),
pd.DataFrame(y_train)],axis=1).reset_index(drop=True)
ne.columns = ['a', 'b', 'c', 'd']#, 'e','f','g','h']
antV = ['#1890FF', '#2FC25B']
sns.pairplot(ne,palette=antV,hue='d')
Out[137]:
<seaborn.axisgrid.PairGrid at 0x1ff388dc250>
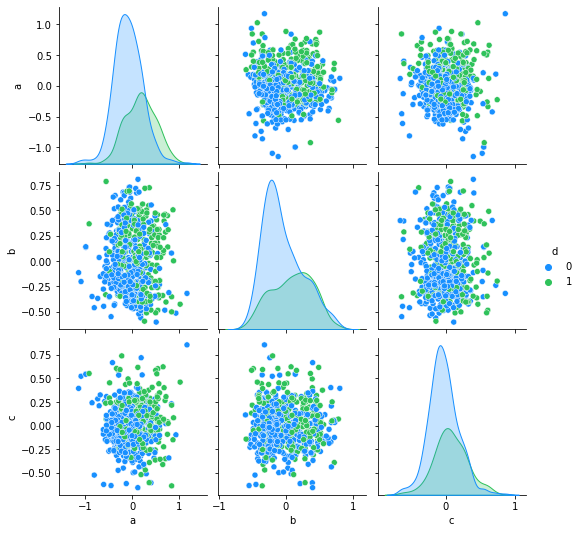
6. 可視化Kernel PCA 降維效果
In [138]:from matplotlib.colors import ListedColormap
X_set, y_set = X_train_kernel_pca, y_train
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
color = ListedColormap(('red', 'green'))(i), label = j)
plt.title('PCA Viz')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend()
plt.show()
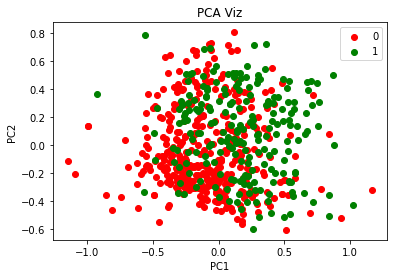
經過Kernel PCA降維,自變數由8個變為2個,
將降維后的2個主成分可視化,可以看到,如果以2個主成分訓練邏輯回歸模型,模型性能會較差,因為肉眼可見,2個類別之間沒有明顯的界限,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/445331.html
標籤:其他
下一篇:外包的選擇