Hash Join是在進行多表連接時常用的方式之一,那如何在openLooKeng上構建并實作Hash Join?openLooKeng支持的Join型別有哪些?本期,社區小伙伴將分享[openLooKeng Hash Join 實作原理],從構建到使用,內容十分詳細,希望對大家有幫助,
1 openLooKeng Join概述
為了更好的介紹join,我們創建兩個非常簡單的表t1和t2,執行的SQL陳述句如下:
create table t1(id bigint, value bigint);insert into t1 values(1, 11);insert into t1 values(2, 22);insert into t1 values(3, 33);insert into t1 values(4, 44);
create table t2(id bigint, value bigint);insert into t2 values(1, 111);insert into t2 values(2, 11);insert into t2 values(3, 333);insert into t2 values(4, 33);
openLooKeng的join有四類:
1) Lookup Join 大部分型別的Join都由Lookup Join完成,例如我們執行SQL陳述句如下: select * from t1 inner join t2 on t1.value=https://www.cnblogs.com/huaweicloud/archive/2022/03/17/t2.value;
其中,執行join所在stage涉及算子如下圖所示:
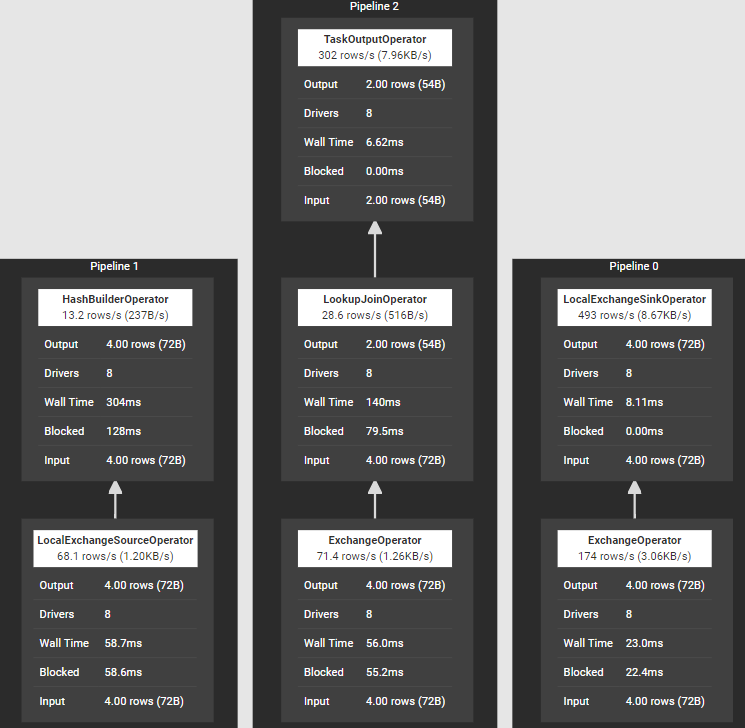
完成Join的算子是HashBuilderOperator和LookupJoinOperator,而本文即將介紹Hash Join的原理,也就是這兩個算子的實作原理,
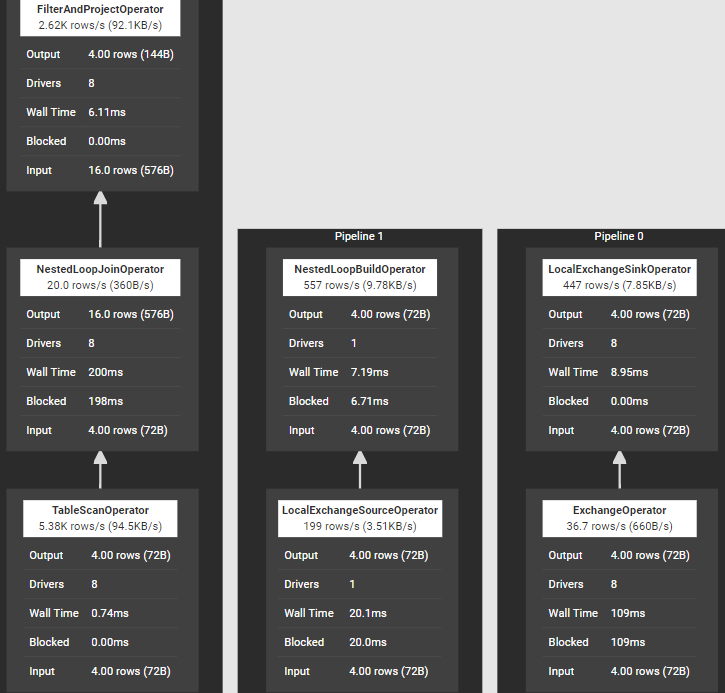
2) Nested Loop Join 執行SQL陳述句“select * from t1 join t2 on t1.value > t2.value;”,join所在stage涉及算子如下圖所示,其中完成Join的算子是NestedLoopBuilderOperator和NestedLoopJoinOperator,
3) Hash Semi Join 執行SQL陳述句“select * from t1 where value in (select value from t2);”,join所在stage涉及算子如下圖所示,其中完成join的算子是SetBuilderOperator和HashSemiJoinOperator,
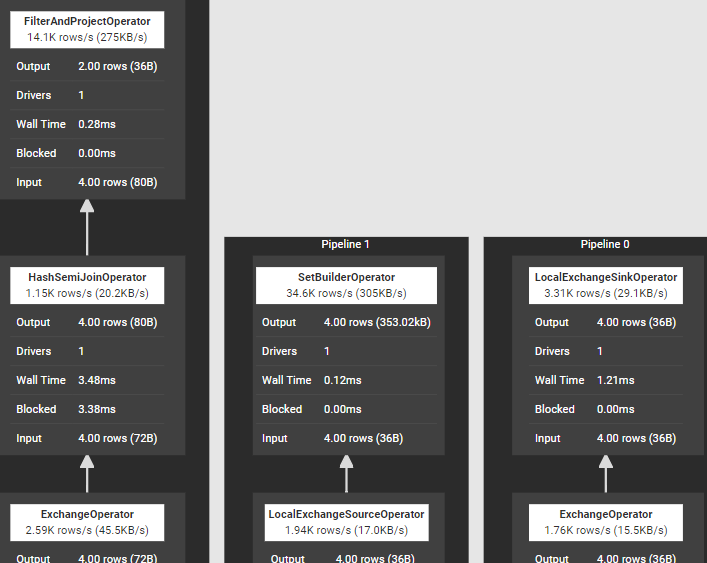
4) Spatial Join 執行SQL陳述句“select * from t1, t2 where ST_distance(ST_Point(t1.id, t1.value), ST_Point(t2.id, t2.value)) <= 10;”,join所在stage涉及算子如下圖所示,其中完成join的算子是SpatialIndexBuilderOperator和SpatialJoinOperator,
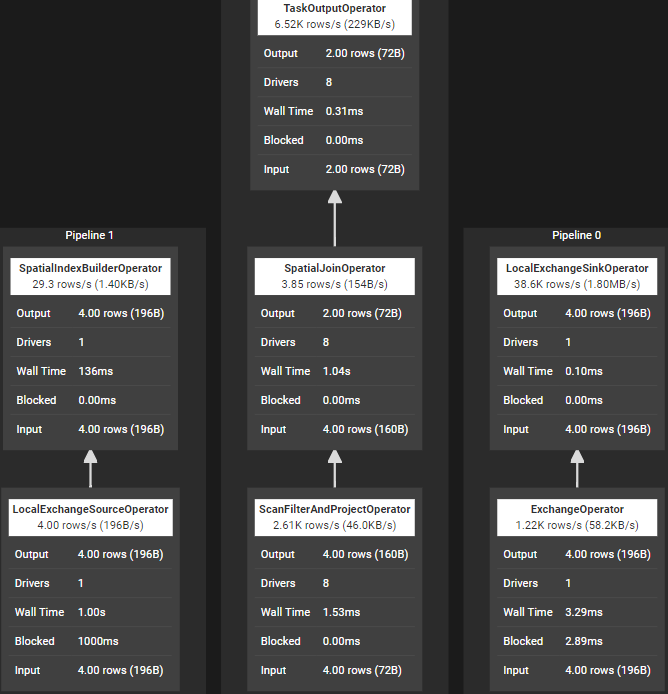
本博客關注的是Hash Join的實作原理分析,其他型別的Join后續展開介紹,
2 openLooKeng Hash Join實作原理
通常,我們稱Join操作的右表為build表,左表為probe表, Hash Join對應的邏輯執行計劃為JoinNode,物理執行計劃則由兩個算子完成作業,其中HashBuilderOperator根據build表來構建Hash Table,LookupJoinOperator完成對probe表逐行去Hash Table探測,找到匹配行,
2.1 build側資料partition
資料進入HashBuilderOperator之前已經由LocalExchangeSinkOperator和LocalExchangeSourceOperator完成資料partition,即join key的哈希值相同的資料進入同一個HashBuilderOperator,LocalExchangeSinkOperator和LocalExchangeSourceOperator對應的邏輯執行計劃的ExchangeNode,在openLooKeng中,ExchangeNode和JoinNode的模型關系如圖2-1所示,
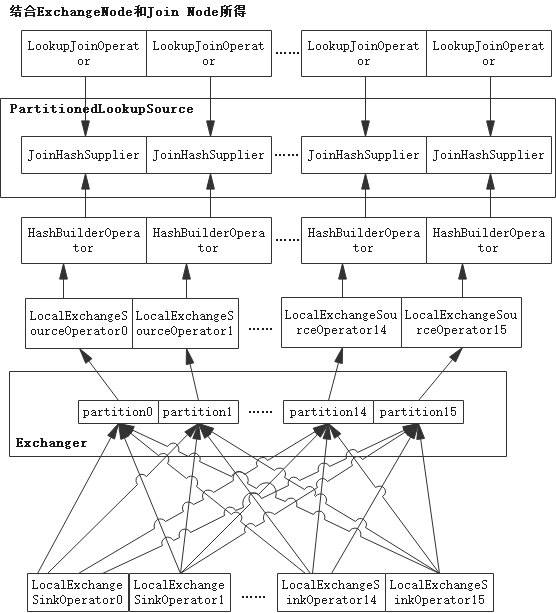
圖2-1中,有16個partition,LocalExchangeSinkOperator接收page后,根據Join key計算hash值,將hash值相同的資料組成新page,再根據hash值計算partition index,選擇相應的LocalExchangeSourceOperator,而LocalExchangeSourceOperator是HashBuilderOperator的上游算子,因此進入HashBuilderOperator的資料是已經partition過后的資料,
2.2 Hash Join類圖
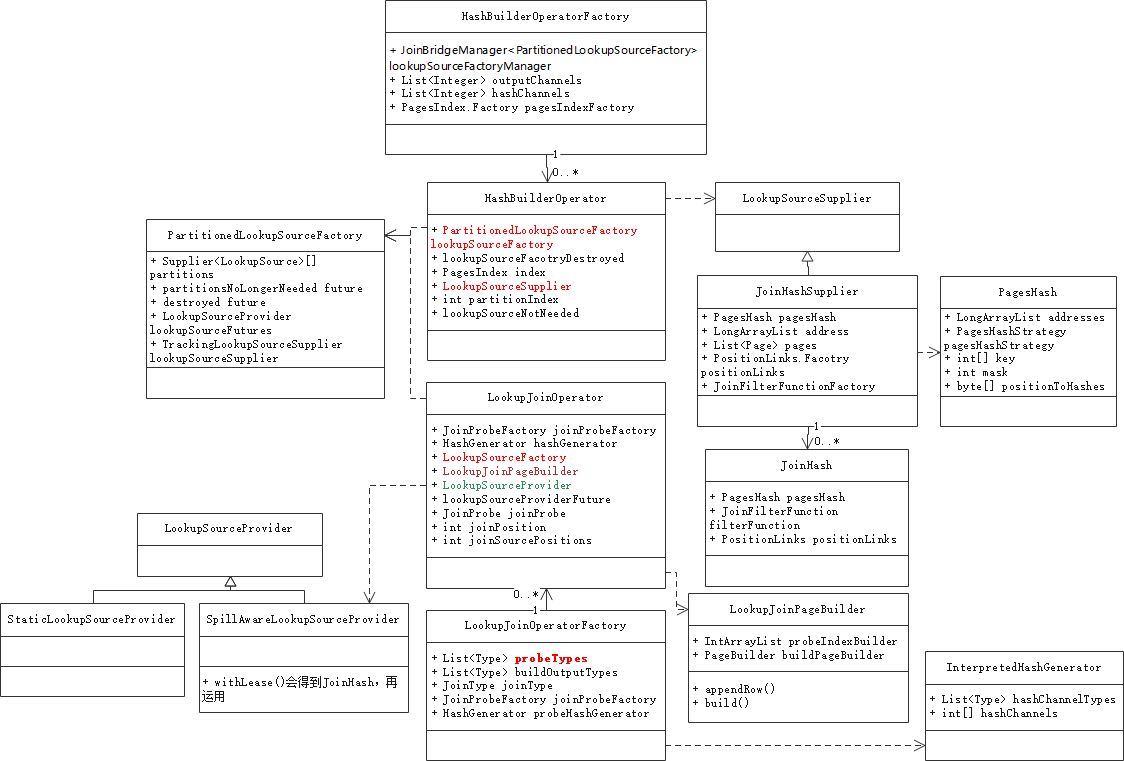
圖2-2展示了Hash Join所涉及的類圖,其中比較重要的類有以下幾個:
1) HashBuilderOperatorFactory/HashBuilderOperator,針對build表構建Hash Table;
2) JoinHash,Hash Table承載類;
3) LookupJoinOperatorFactory/LookupJoinOperator,負責probe表逐行探測;
4) LookupJoinPageBuilder,負責構建輸出page,
2.3 Hash Table構建
HashBuilderOperator負責對build表構建Hash Table,它的基本流程是: 1) addInput()時將Page累積在記憶體中;
2) finish()時,則創建Hash Table;
3) 不再阻塞LookupJoinOperator,即LookupJoinOperator可以開始處理, 我們重點講一下Hash Table的構建,
JoinHash中有兩個非常重要的類:PagesHash和PositionLinks,
我們先來看PagesHash,PagesHash的field有:
1) addresses,對page內每一行資料進行地址編碼,編碼公示為“pageIndex ? 32 | rowIndex”,如有2個page,每個page有2行,則addresses記憶體放的是0,1,4294967296,4294967297;
2) PageHashStrategy,會將原始的資料保存下來;
3) key陣列,可以理解為hash表,根據某行join key計算得到hash值,再將hash值進行hash計算得到一個hash表的offset,如果這個offset上沒有值則存放該行的address,例如addresses中1這個地址對應的行計算出offset為6,而這個位置沒有被占用,則key[6] = 1;
4) mask,掩碼,用于對陣列key求offset;
5) positionToHashes,byte陣列,根據join key計算hash值,但是只保存低位的byte,PositionLinks處理的是,當hash值沖突且原始值也相同時,將滿足這些情況的資料address使用陣列鏈起來,核心代碼片段如下:
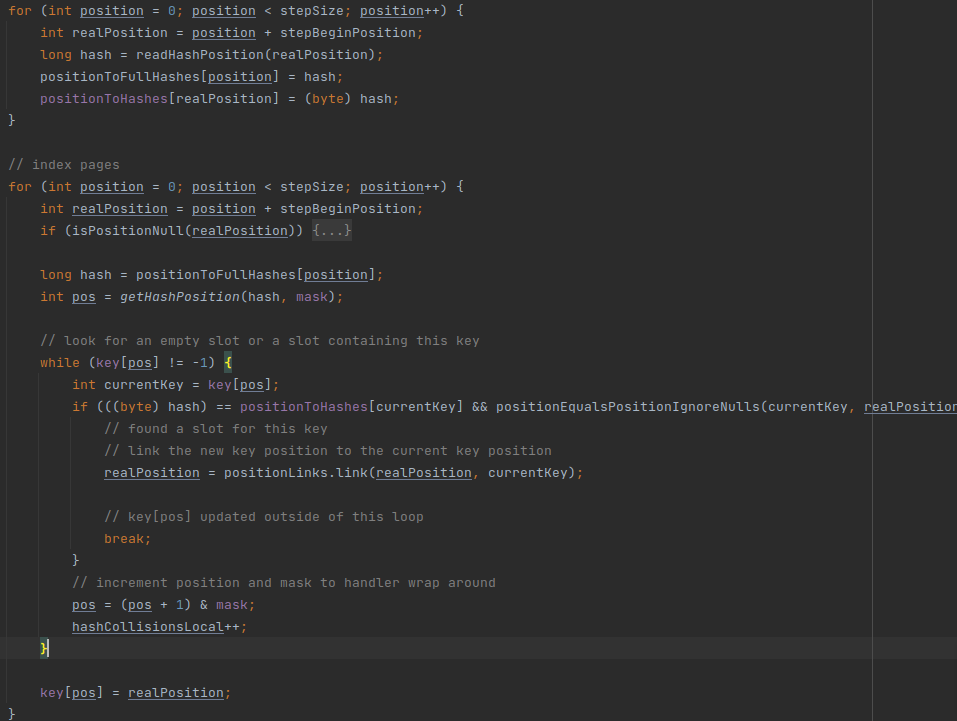
下面我們舉例來說明,

如圖所示,join key只有1個,page只有1個,其值如①所示,對這些行進行地址編碼,則編碼后地址如②所示,Hash table構建步驟: 1) 對原始資料進行hash計算,結果如③所示; 2) 逐行處理addresses:

最終得到的key陣列如④所示,得到的positionLinks如⑤所示,
2.4 Hash Table使用
HashBuilderOperator構建完hash table后,LookupJoinOperator才能開始處理資料進行探測,而LookupJoinOperator使用hash table的核心代碼片段如下:
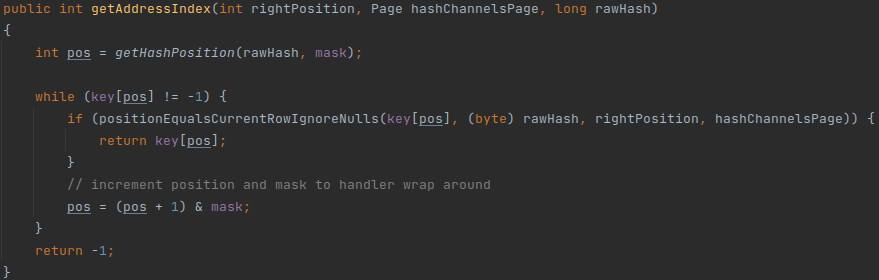
Hash table使用步驟:
1) 對原始資料進行hash計算得到rawHash;
2) 對rawHash再進行hash計算得到其在hash table的offset,即pos;
3) 若key[pos]為-1,則沒有匹配;
4) 若key[pos]不是-1,則hash值匹配,若原始資料是否相等,相等則完全匹配上,回傳key[pos],即原始資料的地址address;若原始資料不相等則pos加1再回圈判斷,
3 總結
本文介紹了openLooKeng支持的join型別,并展開介紹了Lookup join的partition,然后重點介紹了hash table的構建和使用程序,但其實Lookup Join的內容不止這些,比如HashBuilderOperator和LookupJoinOperator如何實作同步,LookupJoinOperator的probe后的輸出資料如何構造,非等值的join又是如何實作的,請期待后續的文章!
本文由華為云發布,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/445523.html
標籤:其他