通過使用資料快取加速程式
譯者注:本文原始鏈接為<Make your programs run faster by better using the data cache>,翻譯獲得作者同意,本文中的一些策略只對大量資料處理有優化的可能,小量資料很可能帶來性能下降,
通過使用資料快取加速程式
開發者時刻面臨著如何加速程式,其中最明顯的是通過花哨的演算法來降低復雜度,比如說將\(O(n^2)\) 復雜度的演算法,使用 \(O(nlogn)\) 替換等等,這是很好的方法,但是并不是所有的程式都有更好的演算法來優化,那么應該怎么辦?是否存在一種方法來優化我們已存在的演算法,事實上是存在的,它叫:底層優化(low-level optimizations),
首先,先來了解一下底層優化的情況,底層優化關注于如何最好地利用底層架構的特殊性來獲得更好的性能,這是這個系列的第一篇,將會涉及到底層優化,我們將在如何更好地利用記憶體快取子系統上探索一系列的方法,對于熟悉現代多行程系統記憶體快取原理的讀者,可以調過 資料快取 章節,
資料快取
計算機系統通常包含處理器和記憶體,在現代計算機系是中記憶體是比處理器慢百倍的,因此處理器通常都要等待記憶體傳輸資料,聰明的硬體工程師想出了一個解決方案來抵消速度上差異:他們添加了一個很小的快速記憶體被稱為快取的東西,用以彌補不同的速度,當程式需要訪問主存中的資料,它首先會檢查資料是否已經在快取中,如果在,它可以很快的獲取資料,否則,計算機會犧牲一些處理器周期,等待主記憶體提供資料,
通常情況下,快取存盤器分為指令快取存盤器和資料快取存盤器,指令快取器的目的是加速對指令的訪問,資料緩沖器的目的是加快對指令所使用的資料的訪問,這篇文章主要關注如何使用資料快取器來加速程式,
為什么記憶體快取可以使程式運行的更快?
那么,為什么增加快取記憶體能起作用呢? 畢竟,程式可以在任何時候都可以訪問任何記憶體位置,因此,這些資料不應該在快取中,理論上是這樣的,但在實踐中,真正的程式幾乎不會以隨機方式訪問記憶體,
有兩個原則制約著現實世界的程式行為,第一條被稱為時間區域性,即如果處理器目前正在訪問某個記憶體地址,就很有可能在不久的將來訪問這個記憶體地址(例如:回圈中的計數器),第二種被稱為空間區域性,其含義是如果處理器目前正在訪問某個記憶體地址,那么它很有可能會在不久的將來訪問鄰近的記憶體地址(例如:處理陣列中的資料),
資料快取內部組織形式
現在讓我們來看看快取的內部情況,在現代計算機處理器中被分解為 Cache line,每個 Cache line 通常情況下是 64bytes 的大小,一個 Cache line 對應主存中 64byte 的記憶體塊,獲取 64byte 中的任意 1byte 資料,意味著需要加載整個 64byte 記憶體塊到快取中來,當 cache line 長時間沒有使用或需要使用新的資料去替換,快取將回傳修改后的塊到主存中去,這整個程序程式并不知道,
讓程式運行更快的一些技巧
對資料快取有了一定的了解后,讓我們來看看如何將資料快取相關的原理應用到你的程式中,從而使你的程式擁有更好的性能,
注意:下面每小節,我使用 C 寫法的陣列和 C++ 寫法的陣列(vector、array),以及 C 寫法(struct)和 C++ 寫法(class)的類,
當獲取線性資料時,盡量使用vector和array
鏈表,hash maps,字典等,都是十分有用的資料結構,但是,它們都不是快取優化的,在這些資料結構中遍歷,將會帶來很大的快取丟失,如果,當前程式性能是最重要的因素,那么將這些資料結構轉為陣列, 如果這是不可能的,嘗試將陣列的快取效率和其他資料的靈活性結合起來,Gap_buffer 是這種結合的很好例子,它將鏈表結構和陣列結構結合,這使得其具有卓越的快取效率和較低代價的元素添加和洗掉,另一個例子是 Judy_array ,稀疏陣列的樹形實作,同樣的擁有很低代價的元素插入和洗掉并且快取友好,
經常訪問的資料,在記憶體中應當是相鄰的
如果有幾個變數被一起訪問,它們應該被逐一宣告,這就增加了另一個變數在處理器訪問后已經在快取中的可能性,因為在處理器訪問了第一個變數之后,另一個變數已經在快取中了,從而避免了緩沖區的缺失,
考慮下面的類:
class free_memory_list {
void* head; /// Pointer to the beginning of the list
Statistics statistics; /// Statistics about list usage
int count; /// Number of elements in the list
Allocator* base_allocator; /// Pointer to the class used for memory
/// allocation and deallocation
};
這個類實作了一個鏈接指標串列,如果我們的程式以這樣的方式使用該類,即把變數 head 和 count 作為一個包來訪問,那么它們應該一個接一個地放在類定義中,在這種情況下我們增加了它們實際在同一快取行中的概率,
使用資料陣列替換指標陣列
當談到類或結構的陣列時,人們想到的第一個想法是使用指標而不是值,這種解決方案與陣列相比有很多優點,包括運行時的多型性和在陣列中未分配元素的情況下,對記憶體的使用更少,但會有一個性能缺陷, 使用指標訪問該變數時,必然會涉及到高速快取的缺失, 因此,為了快速訪問陣列,可以不使用指標而使用值,
因此,現在當把類的陣列作為值時,我們將獲得一些好處,每當我們訪問陣列中的一個元素時,快取預取器就會獲取更多與我們當前訪問的元素接近的元素, 如果,我們訪問的是陣列中彼此相鄰的元素,資料快取被最大限度地利用了,
優化對類或結構陣列的訪問
如果我們以隨機的方式訪問陣列中的元素,就會出現一些快取丟失的情況,但是我們會有更多或者更少的丟失取決于我們在類中如何組織資料,例如:
假設我們有一個類my_class 并且該類的大小為 48btyes,陣列的第一個元素從偏移量 0 開始,第二個元素從偏移量 48 開始,第三個元素從偏移量 96 開始,第四個元素從偏移量 96 開始,如果我們的cache line是64bytes,那么意味著第一個類元素在第一個 cache line 中,第二個元素將被分別存在第一個和第二個cache line中,第三個元素也將被分別存在兩個 cache line 中...
在對類的元素進行隨機訪問的情況下,將一個元素分割在兩個高速快取線之間,從資料快取利用率的角度來說是不好的,快取存盤器需要兩次訪問主存盤器才能讀取一個元素,那么如何避免呢?如何使每個元素適合最小數量的cache line?下面是一些規則:
- 類的大小需要是cache line大小的倍數,
- 陣列的起始地址需要是cache line大小的倍數,
要使類的大小是快取行大小的倍數,我們可以手動的填充使其滿足cache line 或者告訴編譯器自動幫我們填充,在C++11中允許使用alignas(64) 來指定,當然 GCC/CLANG 編譯器提供了 __attribute__((aligned (64))) 實作相同功能,更好的解決方案是讓編譯器和庫來幫助我們;我們可以用 posix_memalign 去分配對齊的記憶體在堆中,或者使用alignas(64) 和 __attribute__((aligned (64))) 在堆疊或者全域記憶體中分配記憶體,下面是一個使用posix_memalign分配類陣列的例子:
my_class* array_of_my_class;
posix_memalign((void**)array_of_my_class, 64, SIZE * sizeof(my_class));
for (size_t i = 0; i < SIZE; i++) {
::new (&array_of_my_class[i]) my_class(i);
}
語法看起來非常的復雜,其實很簡單,我們宣告了my_class 型別的指標,該指標用來保存類陣列,接下來我們使用posix_memalign 去為陣列分配記憶體,同時指定了對其引數為64,最后,在回圈中,我們為陣列中的每個元素呼叫建構式,注意,我們使用的是::new運算子,這個運算子不做記憶體分配,而是它在作為引數提供的記憶體上執行建構式(簡單的說,就是執行 array_of_my_class[i] 建構式,而不進行記憶體分配),
有效地訪問你的矩陣中的資料
如果你的程式需要處理矩陣,你需要了解矩陣是如何存盤在記憶體中的,矩陣被定義為二維的,但是記憶體是一維的,C 和 C+ 編譯器將矩陣逐行排列,這就意味著如果我們獲取矩陣中的某個元素,和這個元素在相同行的一些元素也已經被加載到資料快取中,
這看起來微不足道,但它會對性能產生深遠的影響,考慮一下簡單的矩陣乘法演算法:
void multiply_matrices(int in_matrix1[][N], int in_matrix[][N], int result[][N])
{
int i, j, k;
for (i = 0; i < N; i++) {
for (j = 0; j < N; j++) {
result[i][j] = 0;
for (k = 0; k < N; k++) {
result[i][j] += in_matrix1[i][k] * in_matrix[k][j];
}
}
}
}
矩陣相乘就是對in_matrix1 的行,和對in_matrix2 的列做運算,按照這個計算規律結合上文的內容,我們可知in_matrix1 是符合快取規律的,但是,in_matrix2 將會是緩沖的災難,在in_matrix2 中每訪問下一個元素都會導致 cache 丟失,因此上面的代碼具有很大的性能缺陷,
那么如何解決上述問題?其實很簡單,進行一種叫做回圈互換的轉換, 將j上的回圈移到最里面的位置,這個解決方案的具體實作如下:
void multiply_matrices(int in_matrix1[][N], int in_matrix[][N], int result[][N])
{
int i, j, k;
for (i = 0; i < N; i++) {
for (j = 0; j < N; j++) {
result[i][j] = 0;
}
for (k = 0; k < N; k++) {
for (j = 0; j < N; j++) {
result[i][j] += in_matrix1[i][k] * in_matrix[k][j];
}
}
}
通過這種轉換,逐行運行in_matrix,也要逐行運行result,這對性能有很大的影響,
在你的類和結構體中避免填充
關于資料對齊的一個小說明, 適用于所有原始資料型別,如果資料型別為4位元組大小,其起始地址需要能被 4 整除,如果資料型別為8位元組大小,其起始地址需要能被 8 整除,以此類推對于N位元組大小的資料型別,它的起始地址應當能被 N 整除,我們說變數是正確對齊的,或是對齊的,此外都是未對齊,對齊要求通常是由硬體提出的,并由編譯器盡可能地強制執行,
為了確保你的類和結構中的資料能正確對齊,C 和 C++ 編譯器可以添加填充:這些是在類的成員之間添加的未使用的位元組,以確保所有成員都正確對齊,請看下面的例子:
class my_class {
int my_int;
double my_double;
int my_second_int;
};
人們期望這個結構體的大小是sizeof(int) + sizeof(double) + sizeof(int) = 16 ,然而,double需要8位元組對其,因此在my_int 之后,編譯器添加了 4bytes 的填充,此時my_double 記憶體對齊了,因此,當前的結構體需要20bytes,
此外,為了使類的資料在陣列中正確對齊,類采取了根據其最大成員大小來對齊,而且類的大小是其最大成員大小的整數倍,在上面的例子中,整型是 4 位元組對齊,雙精度浮點型是 8 位元組對齊,因此我們的類應當 8 位元組對齊,由于類的大小需要是其對齊方式的倍數,編譯器在類的末尾增加了 4 位元組的填充,因此,類的大小從原來的 20 位元組增加到 24 位元組,填充物是如何影響快取效率的?比方說,我們的高速快取存盤器有一個 64 位元組的 cache line,在我們的例子中,只有2.7個my_class 類可以填充到 cache line 中,而不是我們所期望的四個類實體,另外,填充位元組被加載到高速快取中,但是你的程式是不會用這些填充位元組的,這保證了編譯器不會插入任何填充物,程式將更好地使用資料快取,下面對上面類進行了修改的類,其類成員的順序略有修改,從而避免編譯器填充,
class my_class {
double my_double;
int my_int;
int my_second_int;
};
這個類的大小現在是 16 位元組,四個類實體符合一個 cache line 大小,
在linux中有個叫做 pahole工具可以查找你類的填充,它需要從原始碼構建,并且不支持 C++11,
盡可能的使用最小的型別
盡可能的使用位元組數少的型別也是避免編譯器填充的一種方法,有時short 可以滿足需求的,我們卻習慣性的用int ,或者說在你的類的定義中有幾個bool變數,你用它來保持各種flag,你可以用chars或bool位域來代替使用bool,
class my_class {
public:
bool my_bool1:1;
bool my_bool2:1;
bool my_bool3:1;
bool my_bool4:1;
int my_int:1;
};
在上面的例子中,每個 bool 占了 1 bit,但是,編譯器為了和 my_int 對齊會在 my_bool4 后面自動填充,這可以通過重新安排my_class成員的順序來避免,
另外的例子:一個64位元組的cache line可以存盤8個整型或者4個長整型, 如果你有一個 1M 元素的陣列,若該陣列元素是整型那么將占 4MB,若為長整型就是 8MB,顯而易見的是,加載 8MB 到緩沖中,比加載 4MB 慢,
但要注意!處理器在內部以原生位元組數(例如:8位元組對于現代64位計算機,或者在嵌入式系統的結構中,可能適用更小的位元組數)為最佳作業方式, 使用較小的資料型別甚至可能降低速度,因此,你將需要測量以獲得確定的性能差異,
盡可能避免堆分配
由于下面幾個原因,堆的效率很低:
- 呼叫
malloc和free是很慢的, - 對這些位置的訪問是間接(通過指標)的,這種方式將導致更多的高速快取不命中的情況,
另一方面,堆疊頂幾乎總是在快取中,分配和洗掉的速度超快,你可以用下面幾個技巧來加速,如果,你的程式需要分配可變大小的陣列,可以考慮在堆疊而不是堆上分配陣列( GCC 支持但是有些編譯器不支持),如果,你的程式需要使用malloc分配大量的小記憶體塊,可以考慮分配一個大的記憶體塊,然后根據你的需要把它分成小的,如果,你的程式需要頻繁的分配和釋放同一型別的物件,那么我們可以考慮快取記憶體塊,而不是直接釋放,如果我們重新需要時,可以很快的重新分配,
盡可能的重復使用緩沖中的資料
理想情況下,我們希望從記憶體中加載資料到快取中,對其進行一些修改,然后再把它們回傳到操作記憶體中,如果你需要兩次獲取相同的資料,你就沒有最佳地使用快取,
以查找一個陣列中的最大元素和最小元素為例,
int * a = initialize_array(size);
int min = find_min(a, size);
int max = find_max(a, size);
我們在這里呼叫了兩個函式,一個是找到最大值,一個是找到陣列中的最小值,每個函式都有自己的回圈,并在回圈中遍歷陣列中的元素,
假設陣列足夠大,陣列中的元素將被加載到快取中兩次,
解決辦法很簡單:在一個回圈中完成對陣列的所有作業,下面是更正后的版本,
int * a = initialize_array(size);
int min = a[0];
int max = a[0];
for (int i = 0; i < size; i++) {
min = std::min(a[i], min);
max = std::max(a[i], max);
}
這里我們只對陣列進行一次迭代,陣列資料只被加載到資料快取中一次,這樣可以更好地利用資料快取,
盡量避免寫記憶體
所有對記憶體的寫入都要經過資料高速快取,當進行寫操作時,快取將該 cache line 標記為 "dirty",若一個 cache line 是 dirty 的,這就意味著他和記憶體中的資料不同,它的內容遲早會被寫回記憶體中,這導致了速度的減慢,請看這兩個演算法:
void sort_fast(int* a, int len) {
for (int i = 0; i < len; i++) {
int min = a[i];
int min_index = i;
for (int j = i+1; j < len; j++) {
if (a[j] < min) {
min = a[j];
min_index = j;
}
}
std::swap(a[i], a[min_index]);
}
}
void sort_slow(int* a, int len) {
for (int i = 0; i < len; i++) {
for (int j = i+1; j < len; j++) {
if (a[j] < a[i]) {
std::swap(a[j], a[i]);
}
}
}
}
上面的代碼顯示了兩個類似的數字排序的函式,兩者的作業方式相同,找到最小的元素并把它放在 0 的位置,然后找到下一個最小的元素并把它放在 1 的位置,以此類推,
方法 sort_slow 尋找比 a[i] 小的陣列元素,如果找到就立即交換, 每當發現一個比 a[i] 小的元素時,它就會繼續交換元素,方法sort_fast 尋找陣列中比a[i]小的元素,但它不做交換,而是將新的最小元素保存在臨時變數min和min_index中(編譯器為這些臨時變數使用一個暫存器), 當函式完成對陣列的運行并找到最終最小的元素時,才會替換a[i]和a[min_index]的內容, 在我的系統上,函式sort_fast比sort_slow快 2 倍,
正確對齊你的資料
你的變數需要正確對齊,這樣可以確保整個變數位于一個快取行中,而不是被分割在兩個快取行中,如果你的系統不支持對錯位變數的訪問,獲取資料會變得非常慢,因為你的作業系統可能會模擬對錯位記憶體地址的訪問,大多數時候,編譯器會確保資料正確對齊,但不細心開發者可能會創造出記憶體訪問錯位的地方,這種情況經常發生在將指標從一種型別轉換為另一種型別指標的時侯,錯誤示范:
unsigned char serialized_data[1024];
read_data(serialized_data);
int* header_pointer = (int*) (serialized_data + 3);
int header = *header_pointer;
在這個例子中,我們將 char 指標轉換為 int 指標,從而使 header_pointer 錯位,解除對header_pointer的參考會產生錯位的記憶體訪問,在某些架構上,程式會崩潰,在其他架構上,程式會變慢,正確示例:
unsigned char serialized_data[1024];
read_data(serialized_data);
int* header_pointer = (int*) (serialized_data + 3);
int header;
memcpy(&header, header_pointer, sizeof(int));
在這里,我們使用memcpy將輸入陣列中的值復制到 header 變數中,函式memcpy不需要適當的對齊,這段代碼更好地利用了資料快取,而且它是可移植的,
使用軟體預取
如果你的演算法不是一個一個地訪問資料,而是以隨機的方式在記憶體中跳躍,你可以使用軟體預取來告訴處理器你將訪問哪些資料,這樣它就有時間在需要它們之前將它們加載到快取中,例如,GCC 和 CLANG 編譯器提供了__builtin_prefetch內置,允許軟體預取,這里我們舉一個二分搜索演算法的例子:
int binarySearch(int *array, int number_of_elements, int key) {
int low = 0, high = number_of_elements-1, mid;
while(low <= high) {
mid = (low + high)/2;
#ifdef DO_PREFETCH
// low path
__builtin_prefetch (&array[(mid + 1 + high)/2], 0, 1);
// high path
__builtin_prefetch (&array[(low + mid - 1)/2], 0, 1);
#endif
if(array[mid] < key)
low = mid + 1;
else if(array[mid] == key)
return mid;
else if(array[mid] > key)
high = mid-1;
}
}
二分搜索演算法不按順序運行陣列,硬體快取預置器面臨大量的快取缺失,在上面的二分搜索演算法中,我們在進行資料查找之前就預取了記憶體中 high 的新值和 low 的新值,而當我們真正需要這些資料時,它已經存在于快取中了,
這個特定演算法的缺點是,我們獲取兩個值,而其中一個值我們將永遠不會被使用,這可能會對性能產生影響,因為一些 cache line 現在需要離開快取,以便為未使用的值騰出位置,如果另一個程式在另一個使用相同快取的核心上運行,可能會導致兩個程式的性能下降,
實驗
讓我們看看這些技巧對我們的實際問題有何幫助,在測驗中,我們使用一個普通的通用系統AMD A8-4500M CPU,有四個核心,每個核心有16KB的L1資料快取,每個核心有2MB的L2資料快取(兩個核心共享2MB的L2資料快取),這個系統有12GB的記憶體,
矩陣乘法
這里有一篇由 Ulrich Drepper 寫的關于快取優化的文章,非常好,但也很冗長,他從簡單的矩陣乘法演算法開始,不斷完善,直到得到一個優化的版本,速度幾乎快了十倍,在他的實驗中,他使用了一個1000×1000的雙精度浮點矩陣, 他做的第一個優化是在乘法前對矩陣進行轉置,僅此一項就帶來了76.6%的性能提升!
帶軟體預取的二分搜索演算法
我們實作了一個使用前一章中的軟體預取的二進制搜索演算法,我們用它來測驗當程式員明確使用預取時,記憶體快取子系統是如何作業的,我們使用的程式原始碼放在了 github 中,只需要輸入make binary_search_runtimes 和 make binary_search_cache_misses 就可分別生成帶預取和不帶預取的程式,
我們生成了一個排序的隨機整數陣列,長度為 10K, 100K, 1M, 10M 和 100M,我們用這些陣列來進行二分搜索,我們稱其為 input_array ,我們使用幾種不同的方法來生成 index_array 的索引,并使用隨機的方法來生成 index_array 的元素, 但我們也使用了一種基于非隨機步長的方法, 如果步長是 N,index_array 的第一個元素是 0,第二是 N,第三是 2N 等等,直到我們到達陣列的末端,然后繞過,
因此,代碼實作如下:
for (int i = 0; i < len; i++) {
binarySearch(inputArray, len, inputArray[indexArray[i]]);
}
我們對隨機 index_array 和步長為 1、100 和 10K 的 index_array 都進行了測驗, 我們將 index_array 的大小固定為 10M ,這意味著我們正在進行 10M 的搜索, 對于隨機訪問的 index_array,下面是結果,
| 作業集 | 關閉Prefetching | 開啟Prefetching | 速度差異 |
|---|---|---|---|
| 10K | 1673ms | 1777ms | -6.2% |
| 100K | 2478ms | 2426ms | +2.1% |
| 1M | 4519ms | 3996ms | +11.6% |
| 10M | 8804ms | 7096ms | +19.4% |
| 100M | 14970ms | 11685ms | +21.9% |
上表表示了在隨機訪問的情況下二分搜索的運行時間和作業集大小的關系,
對于隨機訪問,軟體預取對最小的10K資料集來說是負優化,隨著作業集的增加,帶軟預取的演算法也會變得比普通演算法快,對于大的作業集來說,速度上的差異大約是20%,而且即使作業集的大小進一步增加,它也會保持這種狀態,如果我們不是在訪問隨機元素,而是在以恒定的步長訪問元素,會發生什么?由于這是一個合成測驗,我們正在尋找一個我們事先知道位置的元素,例如:如果步長是 100,我們知道第一個元素的位置是 0,我們正在尋找 input_array[0] 這個值,在下一次迭代中,我們要尋找一個元素 input_array[100] 等等, 在這種情況下,快取是如何表現的?下面是結果,
| 作業集 | 關閉Prefetching | 開啟Prefetching | 速度差異 |
|---|---|---|---|
| 10K | 977ms | 1168ms | -19.5% |
| 100K | 1122ms | 1380ms | -23.0% |
| 1M | 1367ms | 1623ms | -18.7% |
| 10M | 1610ms | 1892ms | -17.5% |
| 100M | 1813ms | 2171ms | -19.7% |
上表是 步長=1 的情況下二分搜索的運行時間和作業集大小的關系,
| 作業集 | 關閉Prefetching | 開啟Prefetching | 速度差異 |
|---|---|---|---|
| 10K | 1112ms | 1418ms | -27.5% |
| 100K | 1766ms | 1942ms | -9.7% |
| 1M | 3018ms | 2792ms | +7.5% |
| 10M | 3236ms | 3019ms | +6.7% |
| 100M | 3356ms | 3182ms | +5.2% |
上表是 步長=100 的情況下二分搜索的運行時間和作業集大小的關系,
| 作業集 | 關閉Prefetching | 開啟Prefetching | 速度差異 |
|---|---|---|---|
| 10K | 760ms | 984ms | -29.5% |
| 100K | 1049ms | 1508ms | -43.8% |
| 1M | 2739ms | 2640ms | +3.6% |
| 10M | 4402ms | 7490ms | -70.1% |
| 100M | 10395ms | 8251ms | -20.6% |
上表是 步長=10K 的情況下二分搜索的運行時間和作業集大小的關系,
對于stride=1,普通演算法每次都能擊敗軟體預取演算法,不過這并不奇怪,因為前一次迭代的所有資料都已經在快取中了,
對于stride=100,正如預期的那樣,對于小的作業集,一般的演算法勝過軟體預取演算法,但是隨著作業集的增加,軟體預取演算法平均快6%,為什么在這種情況下,與完全隨機的情況下的20%相比,平均快6%?如果我們的作業集是10M,平均來說,該演算法在20步左右完成,在這20步中,有14步的資料已經在之前搜索的快取中了,因此,只有在最后的6步中,軟體預取才有意義,
對于stride = 10K,我們看到一個非常奇怪的行為,即一般演算法比軟體預取演算法快,為什么呢?答案是,在步長為10K時對于輸入的10M的作業集,這相當于將其減少到只有10K的作業集,因此,即使是最大的作業集大小(10M),通用演算法也更快,與隨機索引和作業集10K的通用演算法的百分比幾乎相同,
快取性能如何?預取對快取性能有什么樣的影響,讓我們比較一下有預取和無預取的pref指令的結果,
| Parameter | 關閉Prefetching | 開啟Prefetching | 差異 |
|---|---|---|---|
| 快取參考 | 409M | 649M | +58.7% |
| 快取丟失 | 155M | 254M | +63.9% |
| Cycles | 31481M | 25648M | -18.5% |
| 指令數 | 6659M | 10647M | +59.9% |
兩個版本的二分搜索的快取性能、周期和指令資料,結果是有趣的,與普通版本相比,軟體預取版本有更多的快取參考,更多的快取丟失和更多的指令執行,這意味著,軟體預取版本實際上做了更多的作業,但它還是更快,因為它在較少的周期內做了更多的作業,現代處理器每個周期可以執行一條以上的指令,但如果處理器需要等待從主存盤器中獲取資料,這個數字就會下降,如果我們計算每個周期的指令數,軟體預取版本為0.42,普通版本為0.21,這是一個巨大的差異,
快取友好的鏈表
第二個實驗是一個有利于快取的鏈表(這些串列也被稱為 unrolled 鏈表),普通的鏈表對快取非常不友好,在這樣的結構中迭代會導致很多快取丟失,我們怎樣才能做得更好呢?
常規的鏈接串列通常由鏈接串列節點組成,每個節點持有一個值和指向下一個節點的指標,在我們的實作中,鏈表節點可以持有一個以上的值,值的數量被指定為 linked_list 類的一個模板引數,我們測驗了可以容納 1、2、4和 8 個值的鏈接串列節點,節點中值的數量越大,快取失誤就越少,我們用來測驗的程式的源代碼可以在 github 上找到,要運行它,只需執行 make linked_list_runtimes 和 make linked_list_cache_misses 即可,
我們唯一感興趣的是測驗在鏈表中的進行插入、洗掉等,我們的實作也比簡單的鏈表快,但大部分的性能改進來自于更少的記憶體分配,而不是更好地使用資料快取,下面是一個單一串列節點的源代碼,
class linked_list_node {
public:
char used_elems[count];
linked_list_node* next;
char values[count * sizeof(Type)];
...
};
常量 count 保存單個串列節點中的值的數量,模板常量 Type 是我們在節點中保存的型別,由于一個節點有不止一個值,我們在陣列 used_elems 中標記哪些值是實際使用的,注意,我們使用字符來保存使用的值,而不是bool,在我的機器上,bool需要四個位元組,而char需要一個位元組,這個選擇確實提高了串列的性能,因為更多來自節點的其他資料將被預取到快取中,
現在讓我們開始測量,下面的圖表測量了迭代鏈表所需的時間,這取決于節點中的值的數量(1、2、4和8)和鏈表的值的型別大小,
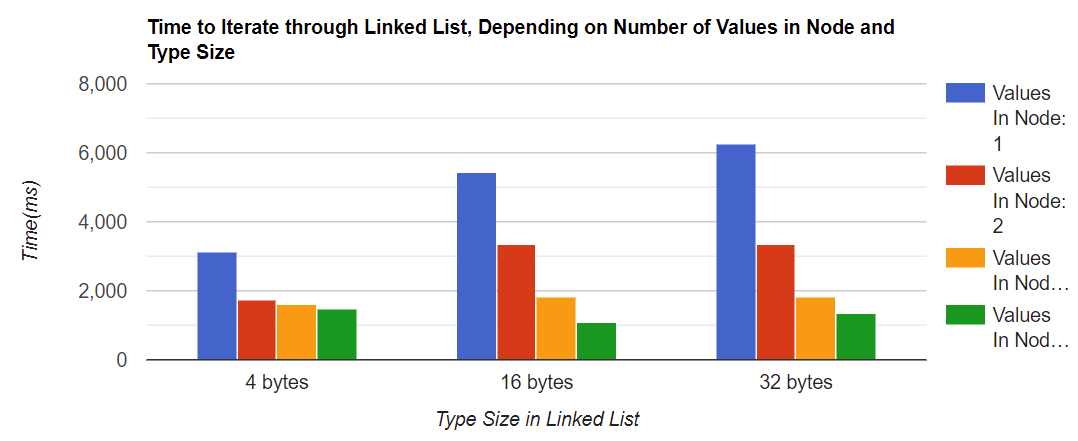
結果看起來非常好! 對于最小的型別大小,遍歷一個節點中有兩個值的鏈表比遍歷一個值的鏈表要少花43%的時間,而且這個數字對于所有型別大小都大致相同,還要注意的是,串列中的型別大小越大,在單個鏈表節點中擁有更多的值就越有意義,對于4位元組的型別大小,有兩個值的節點和有四個值的節點之間的差異很小,但對于32位元組的型別大小,這種差異是明顯的,
快取性能如何?在我們的測驗中,記憶體讀取次數和資料快取失誤率是多少?首先讓我們測量一下我們的程式有多少次記憶體讀取,
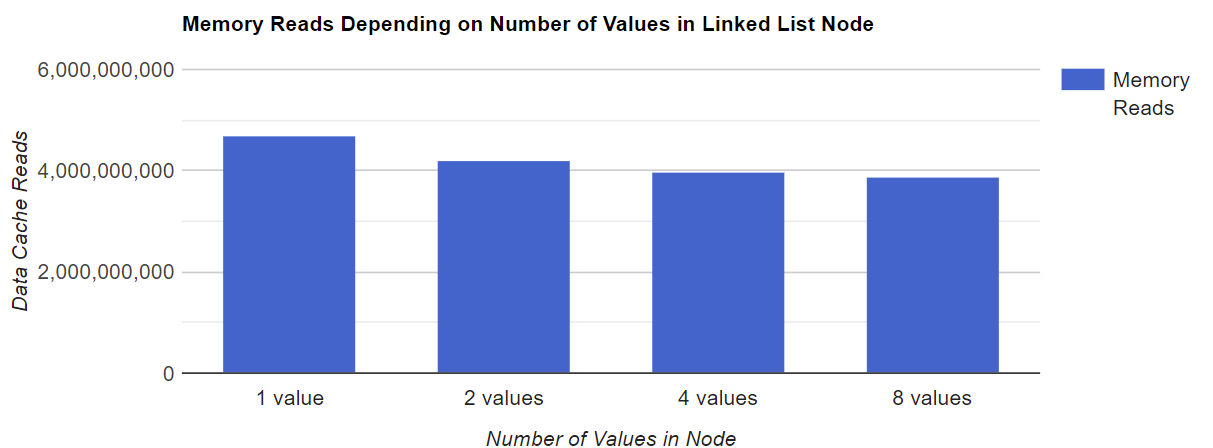
正如你所看到的,單個節點中存盤的數值越多,讀取的記憶體總量就越少,這是可以預期的,因為涉及的指標算術較少,請注意,在我們的例子中,記憶體讀取的數量并不取決于型別大小,
快取缺失情況如何?我們使用了 cachegrind 工具來測量高速快取失誤率,它可以提供關于每個函式或每行的快取缺失的資訊,下面是結果,
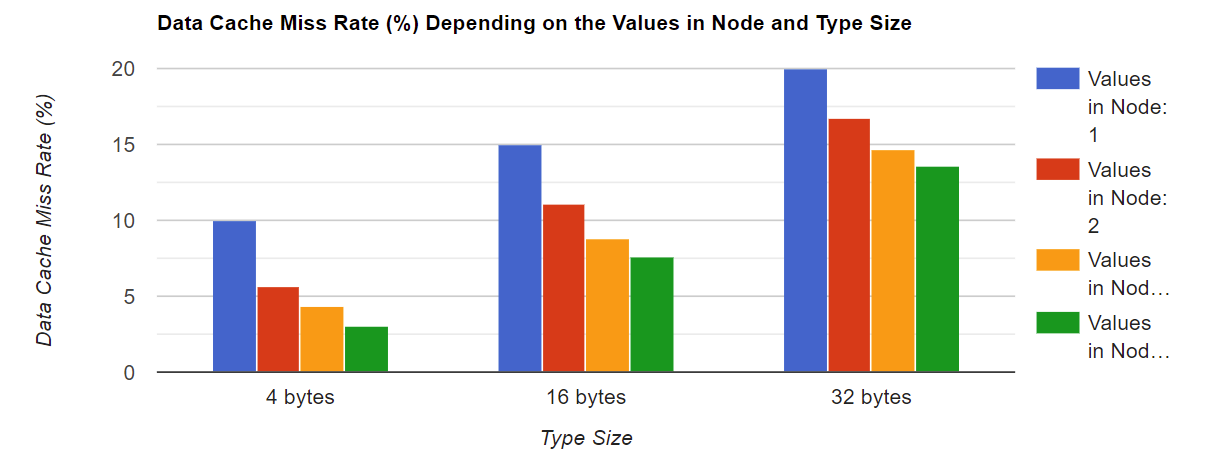
一般的趨勢是:如果一個鏈接串列中的值越多,快取缺失的次數就越少,對于最小的型別,節點中8個值的快取丟失率為3%,而節點中1個值的快取丟失率為10%,對于較大的型別也觀察到類似的比率,另一個趨勢是:在一個鏈接串列節點中,型別大小越大,快取缺失率就越大,對于4位元組的型別大小,最壞的情況下快取丟失率為10%,最好的情況下為3%,對于32位元組的型別大小,最壞的情況下快取缺失率為20%,最好的情況下為13.6%,沒有什么意外,當我們訪問節點中的第一個值時,快取預置器會在周圍的記憶體地址中加載值,所以當我們以后需要它們時,它們已經在快取中了,如果型別越大,預置器加載有用資料的機會就越少,所以這也是造成額外的緩沖區失誤的原因,
總結
那么結論是什么呢?無論是在我們的實驗中還是在一般情況下,關于資料快取的優化肯定有一些有趣的說法,
關于實驗的總結
那么結論是什么呢?我們先談談我們的實驗:這三個實驗都表明,更好地利用資料快取,會取得性能上的提升,與非優化版本相比,優化后的矩陣乘法有很好的性能提升,但是除了矩陣之外,我們很少能在資料結構上做一個簡單的操作來使我們的結構更適合快取,而在我的專業經驗中,我也很少看到矩陣作為資料結構使用,
第二個實驗是關于軟體預取的,我們確實看到了軟體預取在二分搜索上的性能提升,但性能提升只與不合適資料快取的作業集有關,需要注意,軟體預取是有代價的:我們的系統執行了更多的指令,并將更多的資料加載到快取中,這在某些情況下可能會導致其他方面的性能下降,軟體預取的好處是,它很容易實作,可以用來加快各種結構的迭代速度:鏈表、樹、堆等,然而,需要仔細測量以確保性能的提高是值得的,
我們的第三個實驗是關于快取友好的鏈表,我們再次看到速度有了很大的提高,改進來自幾個方面:更少的記憶體分配,更小的資料緩沖區失誤率和更少的指標運算指令,唯一的缺點是實作更復雜,而且記憶體消耗增加,因為可能會出現單個節點沒有被最佳填充的情況,但一般來說,我認為這些缺點是值得努力的,
對于資料快取優化的總結
正如我們的實驗所顯示的,以及我之前的經驗,優化確實帶來了性能的提升,而且有許多應用都需要這樣做,性能的提高取決于許多因素,范圍可以從百分之幾到百分之百甚至更多,
然而,這里提出的一些建議會使你的程式更難理解,更難除錯,而開發人員一直認為要避免的正是這一點,原因很充分,為了最大限度地從這些優化中獲益,你需要仔細地對你的程式進行剖析,找到瓶頸,并專注于加速這些瓶頸,而不是在你的代碼中到處應用這些技巧,首先,應當保持你的介面干凈,避免模塊間的依賴,然后用更快的代碼替換你的慢代碼就很簡單了,你可以在不犧牲可維護性的情況下享受性能的提升,
參考
Ulrich Drepper “What every programmer should know about memory”
What is cache memory – Gary explains
Agner.org – Software Optimization Resources
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/445578.html
標籤:其他
上一篇:鏈表和陣列的區別
下一篇:【面經】Java崗位常見面試題