基于樹的分類模型是一種監督機器學習演算法,它使用一系列條件陳述句將訓練資料劃分為子集,每一次連續的分割都會給模型增加一些復雜性,這些復雜性可以用來進行預測,最終結果模型可以可視化為描述資料集的邏輯測驗的路線圖,決策樹對于中小型資料集很流行,因為它們容易實作,甚至更容易解釋,然而,他們也不是沒有挑戰,在本文中,我們將重點介紹基于樹的分類模型的優缺點以及克服它們所取得的進展,

決策樹的構造
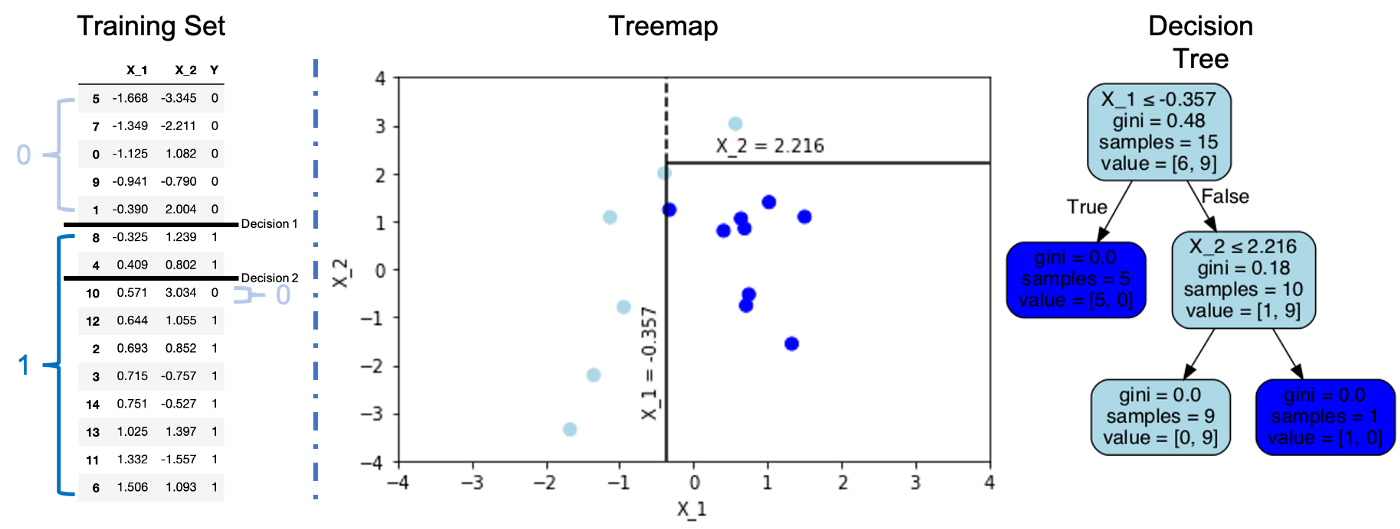
下面的示例描述了只有兩個特性和兩個類的樣例資料集(左),決策樹演算法從根節點中的所有15個資料點開始,該節點被稱為不純節點,因為它混合了多種異構資料,在每個決策節點上,演算法根據減少雜質最多的目標特征對資料集進行分割,最終產生具有同質資料的葉節點/終端節點(右),有一些常用的測量雜質的指標-基尼系數和熵,雖然不同的決策樹實作在使用雜質度量進行計算時可能會有所不同,但一般的概念是相同的,并且在實踐中結果很少有實質性的變化,磁區程序會繼續,直到沒有進一步的分離,例如,模型希望達到一個狀態,即每個葉節點都盡可能快地變成純的,在進行預測時,新的資料點遍歷決策節點序列,以達到確定的結果,
優勢
- 它們是直觀的,容易理解的,即使是非分析背景的人,
- 決策樹是一種不要求資料集服從正態分布的非引數方法,
- 它們能夠容忍資料質量問題和例外值,例如,它們需要較少的資料準備,比如在實作之前的縮放和標準化,此外,它對分類變數和連續變數都很有效,
- 它們可以在資料探索階段用于快速識別重要的變數,
問題
- 決策樹容易發生過擬合,當函式過于接近訓練資料時發生過擬合,當決策樹模型在訓練資料中學習到顆粒狀的細節和噪音時,就會影響到它對新資料做出預測的能力,創建一個過于復雜的模型,會冒著用從未見過的資料做出糟糕預測的風險,
- 決策樹的方差很大,如果資料集很小,結果可能會非常不同,這取決于如何分割訓練和測驗樣本,
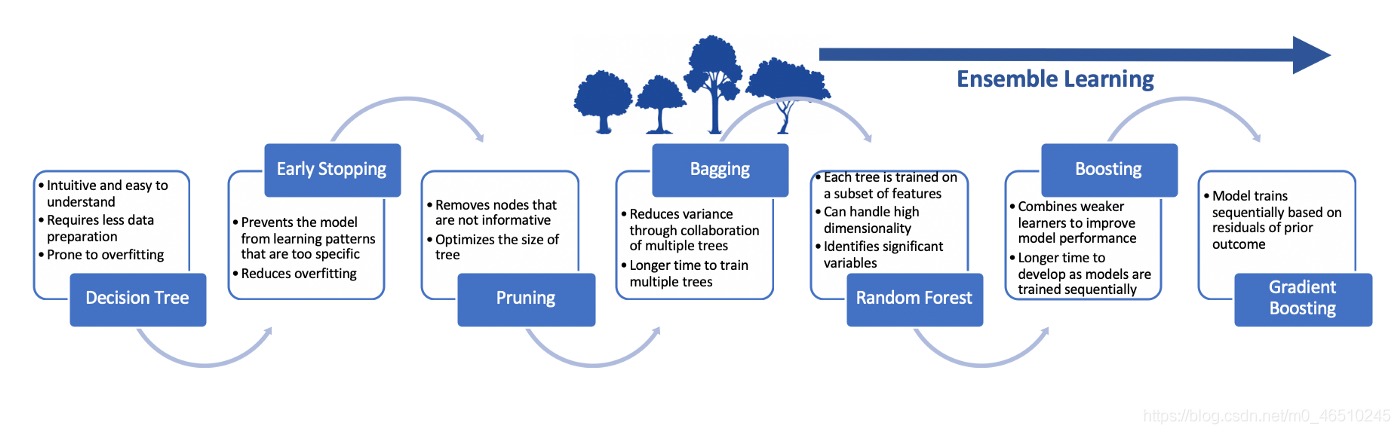
改進
在最近的一段時間里,為了進一步提高基于樹的模型的潛力,對樹類的模型進行了重大的改進和驗證,下面的流程記錄了這個程序:
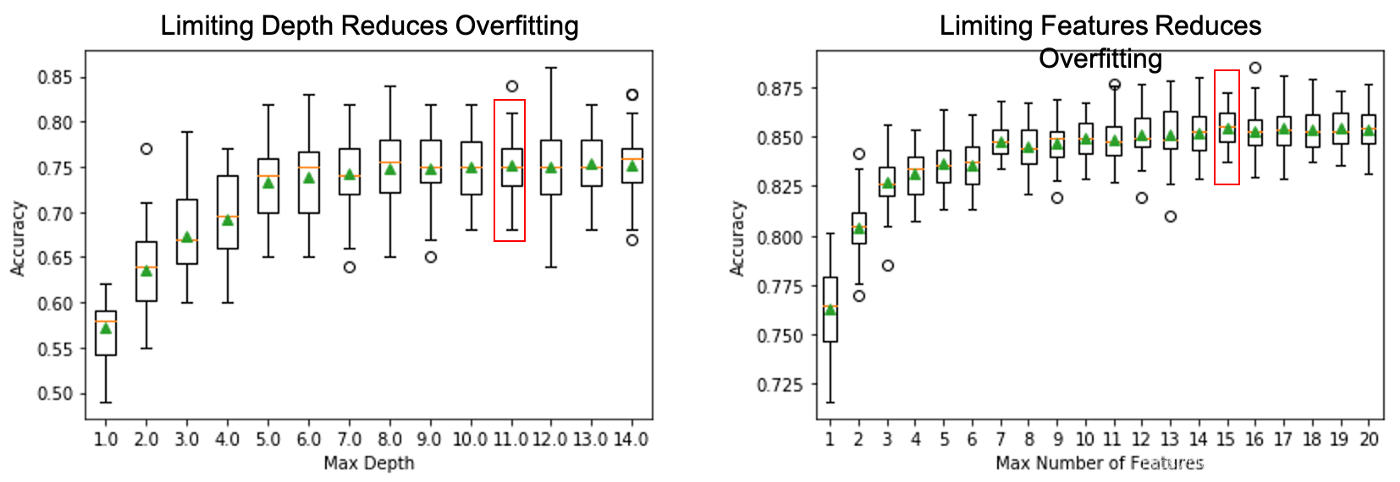
早期停止(Pre-Pruning)
通過防止模型學習過于具體和過于復雜的模式,有幾種方法可以減少過擬合,
- 限制節點分割的最小樣本
- 限制樹最大深度
- 分割需要考慮的最大特性數
因為很難提前知道什么時候停止生長,可能需要一些迭代來調整這些超引數,建議在對樹進行訓練時可視化,從較低的max_depth開始,然后迭代遞增,
修剪(Post-Pruning)
修剪是通過洗掉不利于模型預測能力的葉節點來實作的,這是簡化模型和防止過擬合的另一種方法,實際上,一個完全成熟的決策樹可能有太多冗余的分支,修剪通常是通過在模型構建之后,在驗證或測驗資料集上檢查模型的性能來完成的,通過洗掉對性能產生最小負面影響的節點(稱為成本復雜性剪枝),它降低了復雜性,并允許模型更好地泛化,
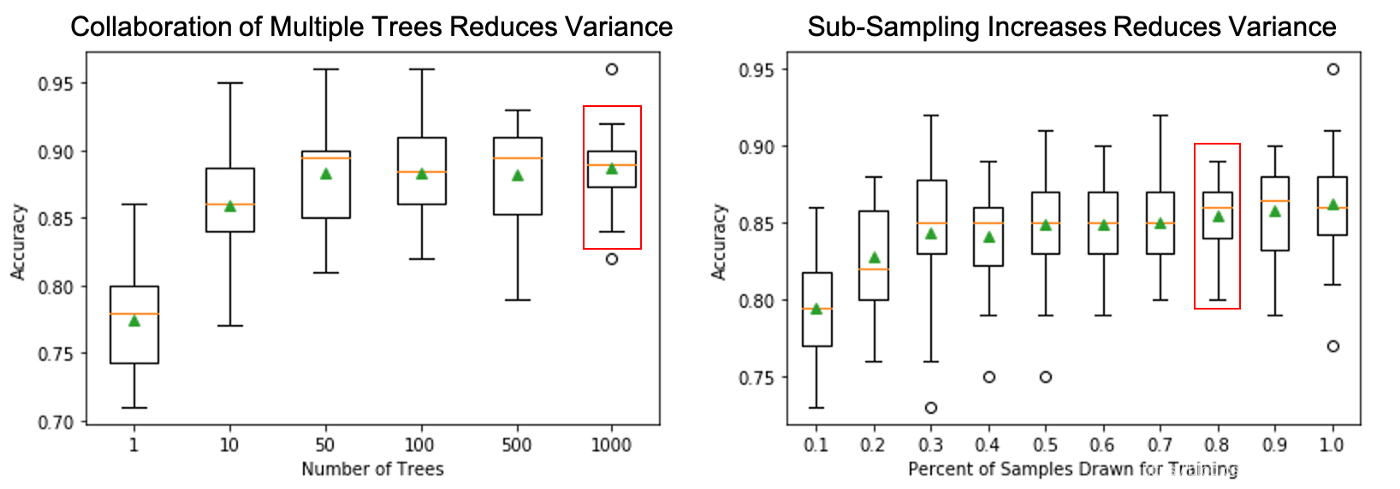
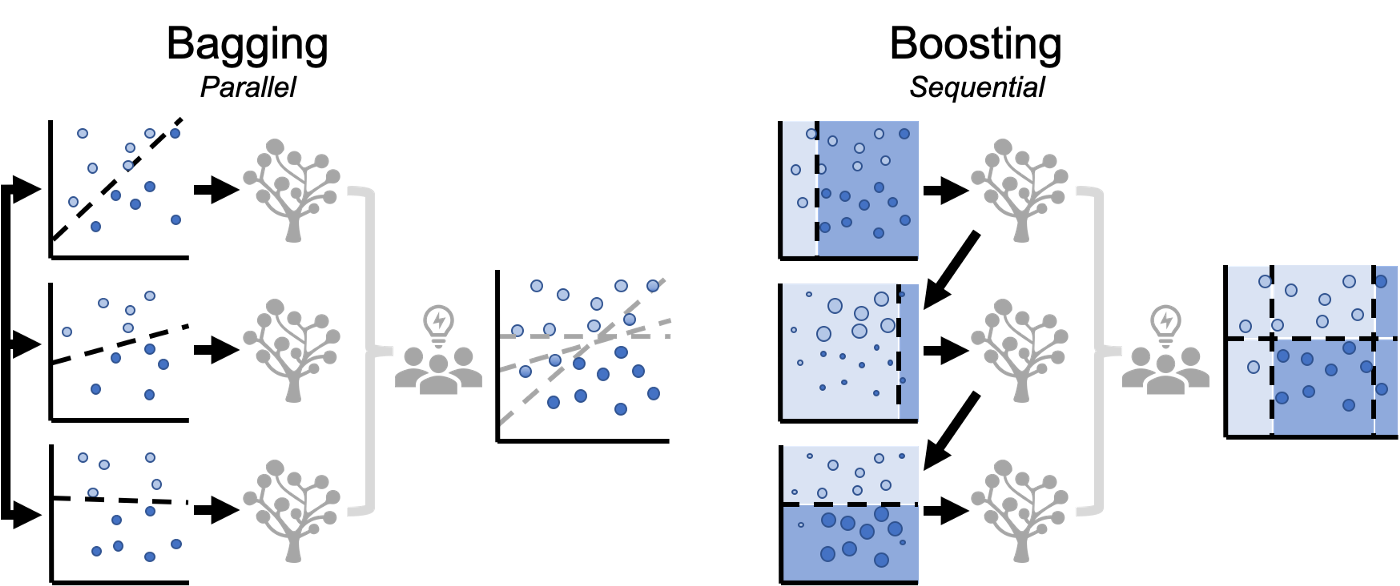
Bagging (Bootstrap Aggregation 采樣聚合)
Bagging是一種集成技術,通過考慮在同一資料集的不同子樣本上訓練的多個決策樹模型的結果,來減少預測的方差,當資料的大小受到限制時,這種方法特別有用,根據問題的不同,所有模型的預測使用平均值、中位數或眾數值進行組合,
隨機森林
隨機森林(Random Forest)是一種集成學習方法,使用不同的特征子集構建多個樹模型,無論是否采樣(即Bootstrap),它可以有效地處理具有許多變數的高維資料集,因為只使用其中的一個子集來構建單獨的樹,限制每個樹模型的特征數量的思路是為了消除它們之間的相關性,當決策節點一致使用強預測器時就會發生這種情況,高度相關模型的協作并不能有效地減少結果的差異,隨機森林演算法的特點是通用性強,訓練速度快,準確率高,
值得注意的是,這種方法通常用于理解資料集和確定變數的重要性,因為它與解決問題有關——排除有價值的特征會導致錯誤的增加,
Boosting
Boosting是另一種集成學習,它結合弱學習者來提高模型性能,弱學習者是預測相對較差的簡單模型,提升的概念是按順序訓練模型,每次都試圖比之前更好地適應,一種被稱為自適應增強(AdaBoost)的方法,根據先前的結果修改資料點的權重,對于后續的每個模型構建實體,正確分類的資料點權重更小,錯誤分類的資料點權重更高,較高的權值可以引導模型學習這些資料點的細節,最后,所有的模型都有助于做出預測,
梯度提升(和XGBoost)
梯度提升方法隨著復雜性的增加而增強,梯度提升不是在每次構建模型時調整權重,而是將后續模型與前一個模型的殘差進行匹配,這種方法可以幫助樹在性能不好的地方逐漸改進,換句話說,它迭代地提高了單個樹的精度,從而提高了模型的整體性能,梯度提升受制于許多必須仔細考慮的引數,當資料集中的關系高度復雜和非線性時,它是有效的,
極端梯度提升(Extreme Gradient boost,簡稱XGBoost)是對標準梯度增強方法進行了一些添加的實作,首先,它使正則化成為可能,這進一步有助于減少過擬合,開發XGBoost的目的是優化計算性能,由于梯度提升訓練的模型是按順序進行的,因此實作起來會很慢,XGBoost的一些顯著特性包括并行化、分布式計算、核外計算和快取優化,
總結
在本文中,我們回顧了一些用于改進基于樹的模型的粗線條術語和技術,基于樹的模型很受歡迎,因為它具有直觀的特性,理解機制將有助于創建基線模型,也就是說,沒有免費的午餐——即使有了這些技術,調整模型以完全優化模型性能仍然是一個迭代程序,
作者:Kevin C Lee
deephub翻譯組
說,沒有免費的午餐——即使有了這些技術,調整模型以完全優化模型性能仍然是一個迭代程序,
作者:Kevin C Lee
deephub翻譯組
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/44558.html
標籤:其他
上一篇:大學兩年經歷