LSM-Tree簡介
LSM Tree(Log Structure Merge Tree)是一種資料結構
從字面意思理解,是一種基于日志追加寫、有一定結構、并且會merge合并的樹(資料結構)
特點是:
①利用磁盤批量的順序寫要遠比隨機寫性能高出很多來支持隨機讀寫操作 ②更適用于寫多讀少型別的場景 ③廣泛應用在各大 NoSQL 中,比如基于 LSM 樹實作底層索引結構的 RocksDB,就是 Facebook 用 Golang 對 LevelDB 的實作,Hbase也是用LSM-Tree的資料結構實作的LSM-Tree一種比較完善的原理圖
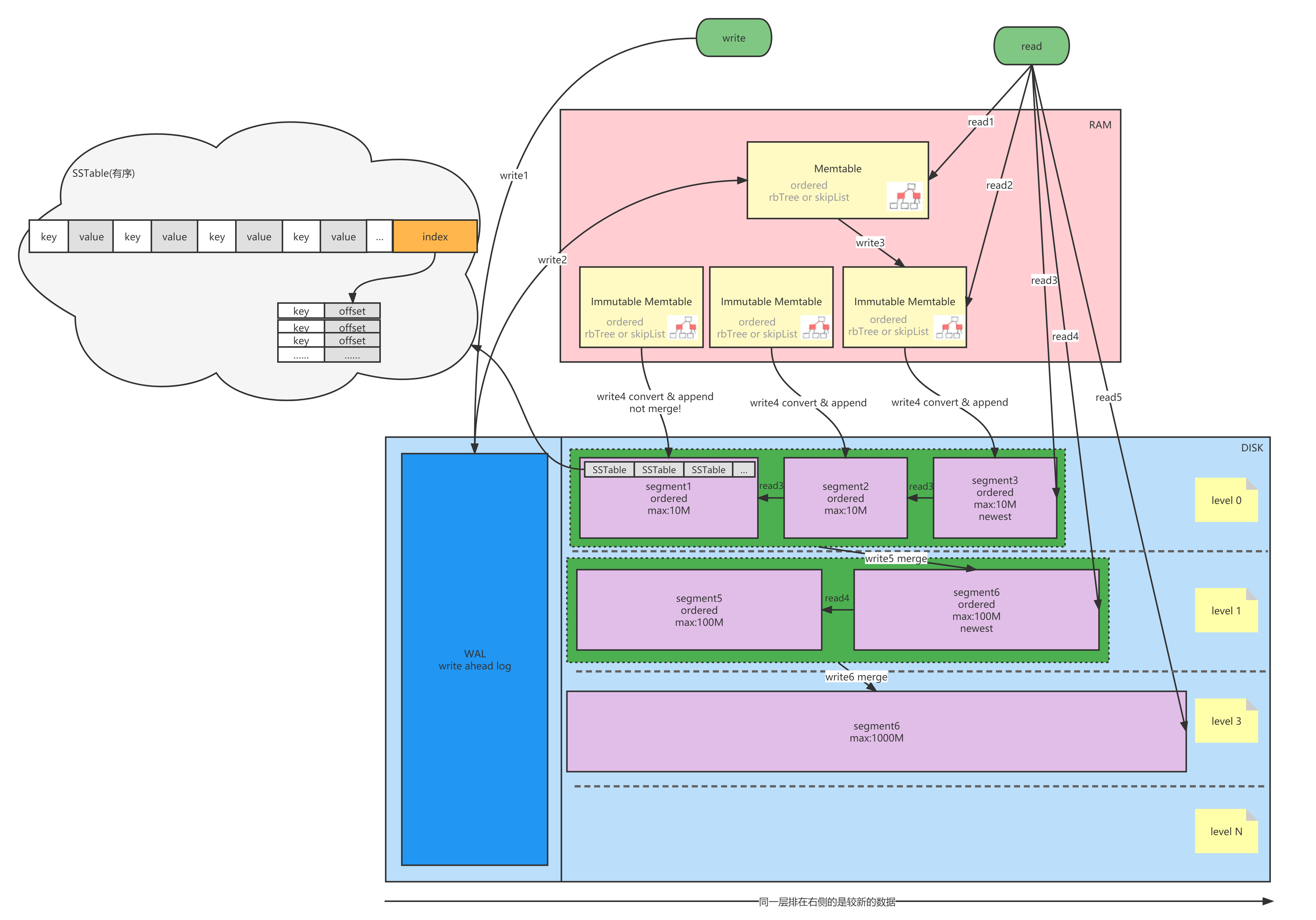
寫操作
write1:WAL
把操作同步到磁盤中WAL做備份(追加寫、性能極高)write2:Memtable
完成WAL后將(k,v)資料寫入記憶體中的Memtable,Memtable的資料結構一般是跳表或者紅黑樹 記憶體內采用這種資料結構一方面支持記憶體內高速增刪改查(時間復雜度O(logM)),另一方面可以保持有序,為寫入磁盤中的SSTable打基礎write3:Immutable Memtable
Memtable存盤的元素達到一定數量后,就會把它拷貝一份出來成為Immutable Memtable (不可變的Memtable)并且不能對其修改了,新增的資料都寫入新的Memtable,這么做的好處是當需要將Memtable轉化為Immutable Memtable時無需暫停作業,至于為什么要拷貝一個Immutable Memtable ,這主要是為了后續落盤時做準備write4:Minor Compaction
記憶體中的資料不可能無線的擴張下去,需要把記憶體里面Immutable Memtable 定期dump到到硬碟上的SSTable level 0層中,此步驟也稱為Minor Compaction SSTable的資料結構是LSM-Tree設計的精髓,他一方面可以保持有序,一方面又能利用磁盤追加寫的高性能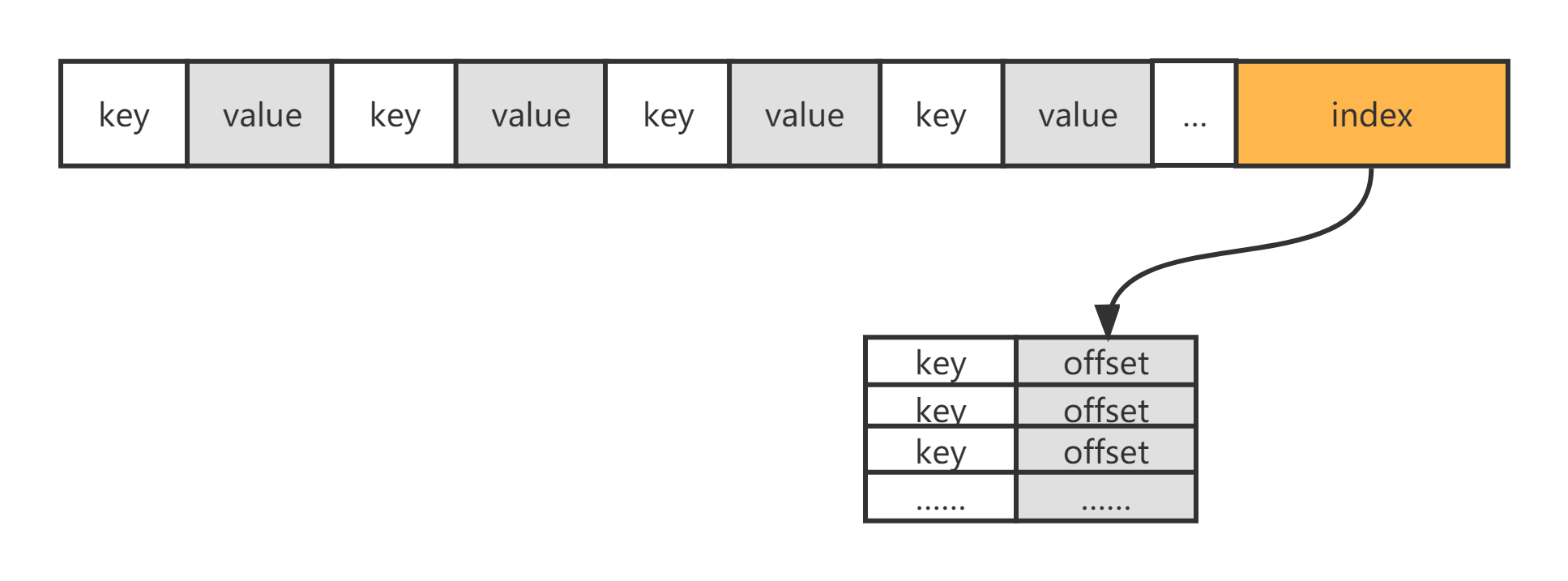
SSTable的資料結構為兩部分,前半部分是key與value成對的資料連續存盤,這部分資料的key是有序的,后半部分是前半部分的索引,值存盤的是key所對應的offset,也是有序的,每次打開這個SSTable需要把索引加載到記憶體并利用二分搜索可以很快查找出要訪問的key的值
dump的程序中每個Immutable Memtable會對應一個SSTable的segment且不會對多個Immutable Memtable進行合并,而是直接將Immutable Memtable中有序的跳表或者紅黑樹遍歷并追加寫入到segment,這個程序速度很快,由于不會合并level 0層中的SSTable可能會出現相同的key,write5、write6:Major Compaction merge
當level 0中的segment越來越多,查詢需要遍歷的segment也就會越來越多,并且隨著時間的推移,重復的key也會越來越多,在后面的步驟就需要對level 0層的segment進行合并merge 合并的程序中是吧多個有序的segment進行歸并合并,所以性能不會很差,多個老的segment會合并成一個更長的同樣有序的segment并設定到下一層 每一層的segment的數量和大小都會有限制,每當超出限制后,就會做合并操作雖然定期合并可以有效的清除無效資料,縮短讀取路徑提升查詢效率,提高磁盤利用空間,但Compaction操作是非常消耗CPU和磁盤IO的,尤其是在業務高峰期,如果發生了Major Compaction,則會降低整個系統的吞吐量,這也是一些NoSQL資料庫,比如Hbase里面常常會禁用Major Compaction,并在凌晨業務低峰期進行合并的原因,
修改流程
write1:WAL write2:找到key直接修改或新增key write3:Immutable Memtable write4:Minor Compaction write5、write6…:較新的key(有序可以識別)會替代較老的key洗掉流程
write1:WAL write2:找到key設定狀態為tombstone或新增key設定狀態為tombstone write3:Immutable Memtable write4:Minor Compaction write5、write6…:因為不確定下層是否有被洗掉的key,到最后一層merge時才真正洗掉讀操作
一、按照Memtable(記憶體)、Immutable Memtable(記憶體)、level 0 segments(磁盤)、level 1 segments(磁盤)、level 1 segments(磁盤)的順序查詢 二、每層先查新生成的segment 三、每個segment從后向前查為什么LSM不直接順序寫入磁盤,而是需要在記憶體中緩沖一下?
單條寫的性能沒有批量寫快,很多中間件比如elasticsearch、kafka、mysql都有類似的記憶體緩沖設計 在磁盤緩沖的另一個好處是,針對新增的資料,可以直接查詢回傳,能夠避免一定的IO操作LSM-Tree和B+Tree的比較
LSM-Tree的優點是支持高吞吐的寫O1,這個特點在分布式系統上更為看重 針對讀取普通的LSM-Tree結構,讀取是On的復雜度 在使用索引或者快取優化后的也可以達到O(logN)的復雜度, 適用于寫多讀少 B+tree的優點是支持高效的讀(穩定的O(logN)) 但是在大規模的寫請求下(O(LogN)),效率會變得比較低,因為隨著insert的操作,為了維護B+樹結構,節點會不斷的分裂和合并,操作磁盤的隨機讀寫概率會變大,故導致性能降低, 適用于寫少讀多或寫讀平衡
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/445903.html
標籤:其他
上一篇:【面經】Spring常見問題