1 前言
MRS CDL是華為云FusionInsight MRS推出的一種資料實時同步服務,旨在將傳統OLTP資料庫中的事件資訊捕捉并實時推送到大資料產品中去,本檔案會詳細為大家介紹CDL的整體架構以及關鍵技術,
2 CDL的概念
MRS CDL(Change Data Loader)是一款基于Kafka Connect的CDC資料同步服務,可以從多種OLTP資料源捕獲資料,如Oracle、MySQL、PostgreSQL等,然后傳輸給目標存盤,該目標存盤可以大資料存盤如HDFS,OBS,也可以是實時資料湖Hudi等,
2.1 什么是CDC?
CDC(Change Data Capture)是一種通過監測資料變更(新增、修改、洗掉等)而對變更的資料進行進一步處理的一種設計模式,通常應用在資料倉庫以及和資料庫密切相關的一些應用上,比如資料同步、備份、審計、ETL等,
CDC技術的誕生已經有些年頭了,二十多年前,CDC技術就已經用來捕獲應用資料的變更,CDC技術能夠及時有效的將訊息同步到對應的數倉中,并且幾乎對當前的生產應用不產生影響,如今,大資料應用越來越普遍,CDC這項古老的技術重新煥發了生機,對接大資料場景已經是CDC技術的新使命,
當前業界已經有許多成熟的CDC to大資料的產品,如:Oracle GoldenGate(for Kafka)、 Ali/Canal、Linkedin/Databus、Debezium/Debezium等等,
2.2 CDL支持的場景
MRS CDL吸收了以上成熟產品的成功經驗,采用Oracle LogMinner和開源的Debezium來進行CDC事件的捕捉,借助Kafka和Kafka Connect的高并發,高吞吐量,高可靠框架進行任務的部署,
現有的CDC產品在對接大資料場景時,基本都會選擇將資料同步到訊息佇列Kafka中,MRS CDL在此基礎上進一步提供了資料直接入湖的能力,可以直接對接MRS HDFS和Huawei OBS以及MRS Hudi、ClickHouse等,解決資料的最后一公里問題,
| 場景 | 資料源 | 目標存盤 |
|---|---|---|
| 實時資料湖分析 | Oracle | Huawei OBS, MRS HDFS, MRS Hudi, MRS ClickHouse, MRS Hive |
| 實時資料湖分析 | MySQL | Huawei OBS, MRS HDFS, MRS Hudi, MRS ClickHouse, MRS Hive |
| 實時資料湖分析 | PostgreSQL | Huawei OBS, MRS HDFS, MRS Hudi, MRS ClickHouse, MRS Hive |
表1 MRS CDL支持的場景
3 CDL的架構
作為一個CDC系統,能夠從源目標抽取資料并且傳輸到目標存盤中去是基本能力,在此基礎上,靈活、高性能、高可靠、可擴展、可重入、安全是MRS CDL著重考慮的方向,因此,CDL的核心設計原則如下:
- 系統結構必須滿足可擴展性原則,支持在不損害現有系統功能的前提下添加新的源和目標資料存盤,
- 架構設計應當滿足不同角色間的業務側重點分離
- 在合理的情況下減少復雜性和依賴性,最大限度的降低架構、安全性、韌性方面的風險,
- 需要滿足插件式的客戶需求,提供通用的插件能力,使得系統靈活、易用、可配置,
- 業務安全,避免橫向越權和資訊泄露,
3.1 架構圖/角色介紹
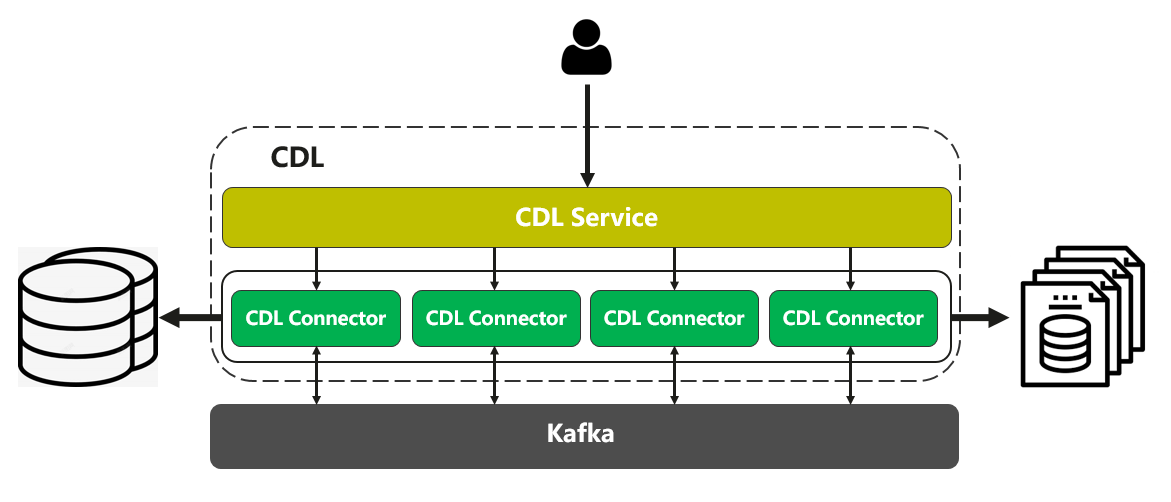
圖1 CDL架構
MRS CDL包含CDL Service和CDL Connector兩個角色,他們各自的職能如下:
- CDL Service:負責任務的管理和調度,提供統一的API介面,同時監測整個CDL服務的健康狀態,
- CDL Connector:本質上是Kafka Connect的Worker行程,負責真實Task的運行,在Kafka Connect高可靠、高可用、可擴展的特性基礎上增加了心跳機制來協助CDL Service完成集群的健康監測,
3.2 為什么選擇Kafka?
我們將Apache Kafka與Flume和Nifi等各種其他選項進行了比較,如下表所示:
|Flume|Nifi|Kafka
:--??:--??:--??:--:
優點|基于配置的Agent架構;攔截器;Source、Channel、Sink模型| 有許多開箱即用的處理器;背壓機制;處理任意大小的訊息;支持MiNifi Agent來收集資料;支持邊緣層資料流|可擴展、分布式、高容錯、高吞吐量的訊息傳遞系統;背壓機制;無資料丟失;Kafka Connect支持Source、Sink模型;超過50種可用的Connector;訊息保序;低耦合
缺點|存在資料丟失的場景;沒有資料備份;資料大小限制;沒有背壓機制|沒有資料復制;脆弱的容錯機制;不支持訊息保序;可擴展性較差|訊息大小限制
表1 框架比較
對于CDC系統,Kafka有足夠的優勢來支撐我們做出選擇,同時,Kafka Connect的架構完美契合CDC系統:
- 并行 - 對于一個資料復制任務,可以通過拆解成多個子任務并且并行運行來提高吞吐率,
- 保序 - Kafka的partition機制可以保證在一個partition內資料嚴格有序,這樣有助于我們實作資料完整性,
- 可擴展 - Kafka Connect在集群中分布式的運行Connector,
- 易用 - 對Kafka的介面進行了抽象,提升了易用性,
- 均衡 - Kafka Connect自動檢測故障,并在剩余行程上根據各自負載重新進行均衡調度,
- 生命周期管理 – 提供完善的Connector的生命周期管理能力,
4 MRS CDL關鍵技術
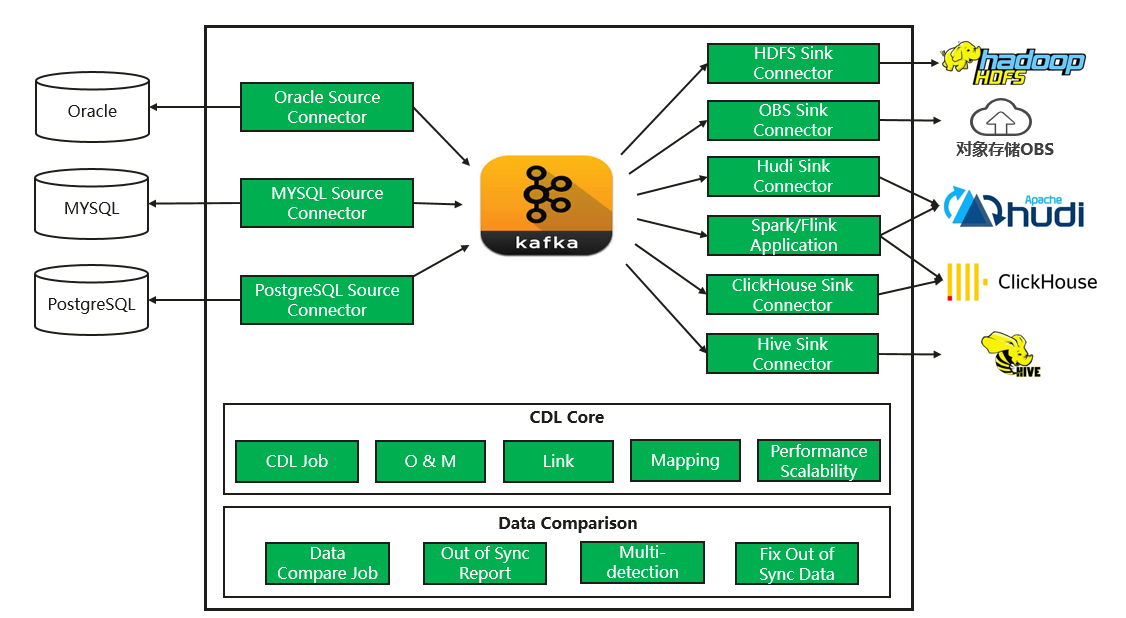
圖2 CDL關鍵技術
4.1 CDL Job
MRS CDL對業務進行了上層的抽象,通過引入CDL Job的概念來定義一個完整的業務流程,在一個Job中,用戶可以選擇資料源和目標存盤型別,并且可以篩選要復制的資料表,
在Job結構的基礎上,MRS CDL提供執行CDL Job的機制,在運行時,使用Kafka Connect Source Connector結合日志復制技術將CDC事件從源資料存盤捕獲到Kafka,然后使用Kafka Connect Sink Connector從Kafka提取資料,在應用各種轉換規則后將最終結果推送到目標存盤,
提供定義表級和列級映射轉換的機制,在定義CDL Job的程序中可以指定轉換規則,
4.2 Data Comparison
MRS CDL提供一種特殊的Job,用于進行資料一致性對比,用戶可以選擇源和目標資料存盤架構,從源和目標架構中選擇各種比較對進行資料比較,以確保資料在源和目標資料存盤中一致,
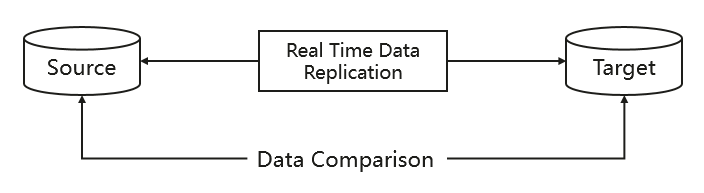
圖3 Data Comparison抽象視圖
MRS CDL提供了專用的Rest API來運行Data Compare Job,并且提供如下能力:
- 提供多樣的資料比較演算法,如行哈希演算法,非主鍵列比較等,
- 提供專門的查詢介面,可以查詢同步報表,展示當前Compare任務的執行明細,
- 提供實時的基于源和目標存盤的修復腳本,一鍵修復不同步資料,
如下是Data Compare Job執行流程:
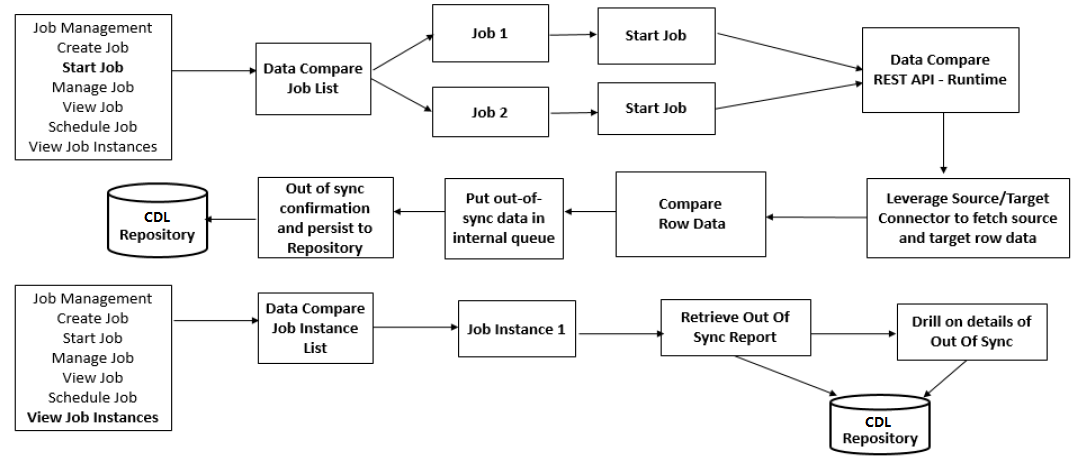
圖4 Data Compare Job執行和查看流程
4.3 Source Connectors
MRS CDL通過Kafka Connect SDK創建各種源連接器,這些連接器從各種資料源捕獲CDC事件并推送到Kafka,CDL提供專門的Rest API來管理這些資料源連接器的生命周期,
4.3.1 Oracle Source Connector
Oracle Source Connector使用Oracle RDBMS提供的Log Miner介面從Oracle資料庫捕獲DDL和DML事件,
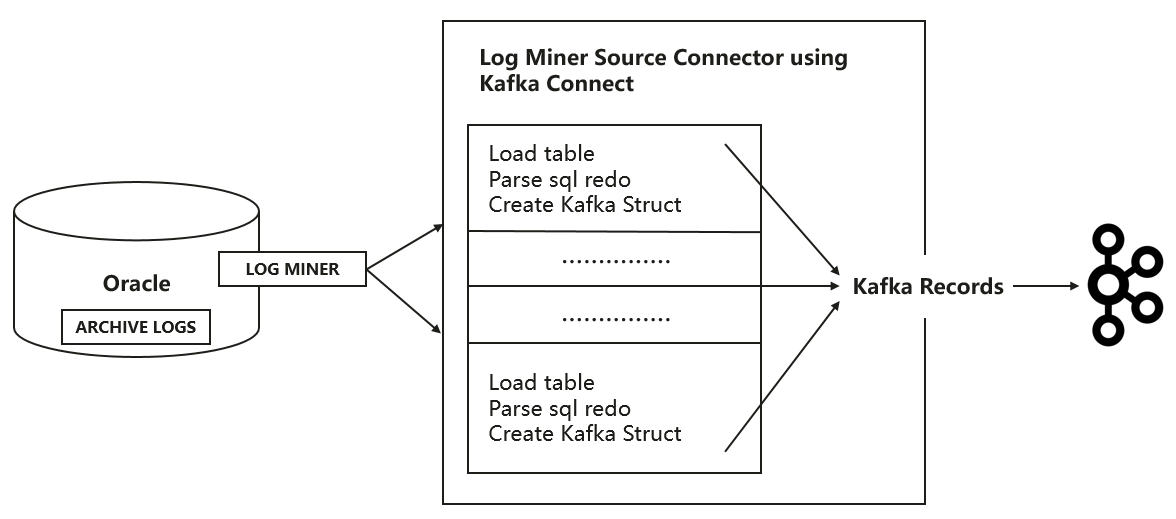
圖5 Log Miner抓取資料示意圖
在處理DML事件時,如果表中存在BOLB/CLOB列,CDL同樣可以提供支持,對于BOLB列的處理,關鍵點處理如下:
- 當insert/update操作發生時,會觸發一系列的LOB_WRITE操作,
- LOB_WRITE用于將檔案加載到BLOB欄位中,
- 每個LOB_WRITE只能寫入1KB資料,
- 對于一個1GB的圖片檔案,我們會整理全部的100萬個LOB_WRITE操作中的二進制資料,然后合并成一個物件,我們會把這個物件存盤到Huawei OBS中,最終在寫入Kafka的message中給出該物件在OBS中的位置,
對于DDL事件的捕獲,我們創建單獨的會話來持續跟蹤,當前支持的DDL陳述句如下:
| No | DDL陳述句 | 示例 |
|---|---|---|
| 1 | CREATE TABLE | CREATE TABLE TEST ( EMPID INT PRIMARY KEY, ENAME VARCHAR2(10)) |
| 2 | ALTER TABLE ... ADD ( |
ALTER TABLE TEST ADD ( SALARY NUMBER) |
| 3 | ALTER TABLE ... DROP COLUMN ... | ALTER TABLE TEST DROP (SALARY) |
| 4 | ALTER TABLE ... MODIFY ( |
ALTER TABLE TEST MODIFY SALARY INT |
| 5 | ALTER ... RENAME... | ALTER TABLE TEST RENAME TO CUSTOMER |
| 6 | DROP ... | DROP TABLE TEST |
| 7 | CREATE UNIQUE INDEX ... | CREATE UNIQUE INDEX TESTINDEX ON TEST (EMPID, ENAME) |
| 8 | DELETE INDEX … | Delete existing index |
表2 支持的DDL陳述句
4.3.2 MYSQL Source Connector
MYSQL的Binary Log(Bin Log)檔案順序記錄了所有提交到資料庫的操作,包括了對表結構的變更和對表資料的變更,MYSQL Source Connector通過讀取Bin Log檔案,生產CDC事件并提交到Kafka的Topic中,
MYSQL Source Connector主要支持的功能場景有:
- 捕獲DML事件,并且支持并行處理所捕獲的DML事件,提升整體性能
- 支持表過濾
- 支持配置表和Topic的映射關系
- 為了保證CDC事件的絕對順序,我們一般要求一張表只對應一個Partition,但是,MYSQL Source Connector仍然提供了寫入多Partition的能力,來滿足某些需要犧牲訊息保序性來提升性能的場景
- 提供基于指定Bin Log檔案、指定位置或GTID來重啟任務的能力,保證例外場景下資料不丟失
- 支持多種復雜資料型別
- 支持捕獲DDL事件
4.3.3 PostgreSQL Source Connector
PostgreSQL的邏輯解碼特性允許我們決議提交到事務日志的變更事件,這需要通過輸出插件來處理這些變更,PostgreSQL Source Connector使用pgoutput插件來完成這項作業,pgoutput插件是PostgreSQL 10+提供的標準邏輯解碼插件,無需安裝額外的依賴包,
PostgreSQL Source Connector和MYSQL Source Connector除了部分資料型別的區別外其他功能基本一致,
4.4 Sink Connectors
MRS提供多種Sink Connector,可以從Kafka中拉取資料并推送到不同的目標存盤中,現在支持的Sink Connector有:
- HDFS Sink Connector
- OBS Sink Connector
- Hudi Sink Connector
- ClickHouse Sink Connector
- Hive Sink Connector
其中Hudi Sink Connector和ClickHouse Sink Connector也支持通過Flink/Spark應用來調度運行,
4.5 表過濾
當我們想在一個CDL Job中同時捕獲多張表的變更時,我們可以使用通配符(正則運算式)來代替表名,即允許同時捕獲名稱滿足規則的表的CDC事件,當通配符(正則運算式)不能嚴格匹配目標時,就會出現多余的表被捕獲,為此,CDL提供表過濾功能,來輔助通配符模糊匹配的場景,當前CDL同時支持白名單和黑名單兩種過濾方式,
4.6 統一資料格式
MRS CDL對于不同的資料源型別如Oracle、MYSQL、PostgreSQL采用了統一的訊息格式存盤在Kafka中,后端消費者只需決議一種資料格式來進行后續的資料處理和傳輸,避免了資料格式多樣導致后端開發成本增加的問題,
4.7 任務級的日志瀏覽
通常境況下,一個CDL Connector會運行多個Task執行緒來進行CDC事件的抓取,當其中一個Task失敗時,很難從海量的日志中抽取出強相關的日志資訊,來進行進一步的分析,
為了解決如上問題,CDL規范了CDL Connector的日志列印,并且提供了專用的REST API,用戶可以通過該API一鍵獲取指定Connector或者Task的日志檔案,甚至可以指定起止時間來進一步縮小日志查詢的范圍,
4.8 監控
MRS CDL提供REST API來查詢CDL服務所有核心部件的Metric資訊,包括服務級、角色級、實體級以及任務級,
4.9 應用程式錯誤處理
在業務運行程序中,常常會出現某些訊息無法發送到目標資料源的情況,我們把這種訊息叫做錯誤記錄,在CDL中,出現錯誤記錄的場景有很多種,比如:
- Topic中的訊息體與特定的序列化方式不匹配,導致無法正常讀取
- 目標存盤中并不存在訊息中所存盤的表名稱,導致訊息無法發送到目標端
為了處理這種問題,CDL定義了一種“dead letter queue”,專門用于存盤運行程序中出現的錯誤記錄,本質上“dead letter queue”是由Sink Connector創建的特定的Topic,當出現錯誤記錄時,由Sink Connector將其發往“dead letter queue”進行存盤,
同時,CDL提供了REST API來供用戶隨時查詢這些錯誤記錄進行進一步分析,并且提供Rest API可以允許用戶對這些錯誤記錄進行編輯和重發,
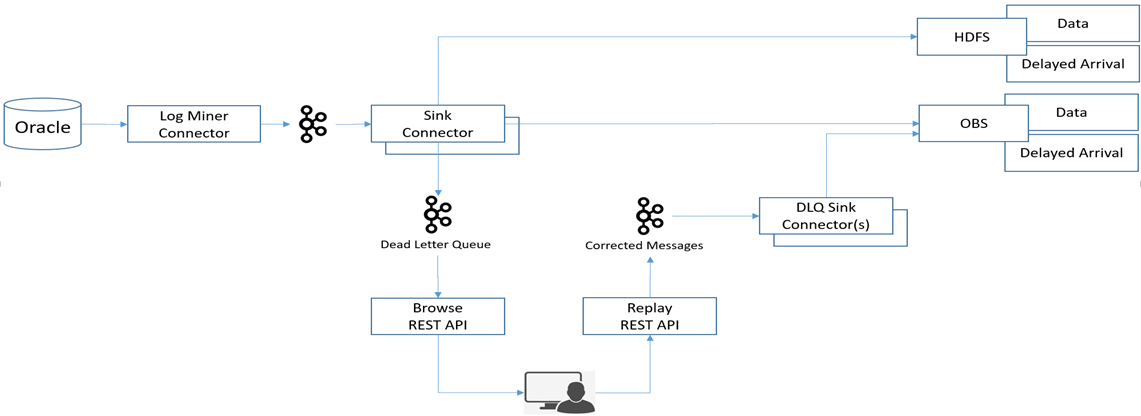
圖6 CDL Application Error Handling
5 性能
CDL使用了多種性能優化方案來提高吞吐量:
- Task并發
我們利用Kafka Connect提供的任務并行化功能,其中Connect可以將作業拆分為多個任務來并行復制資料,如下所示:
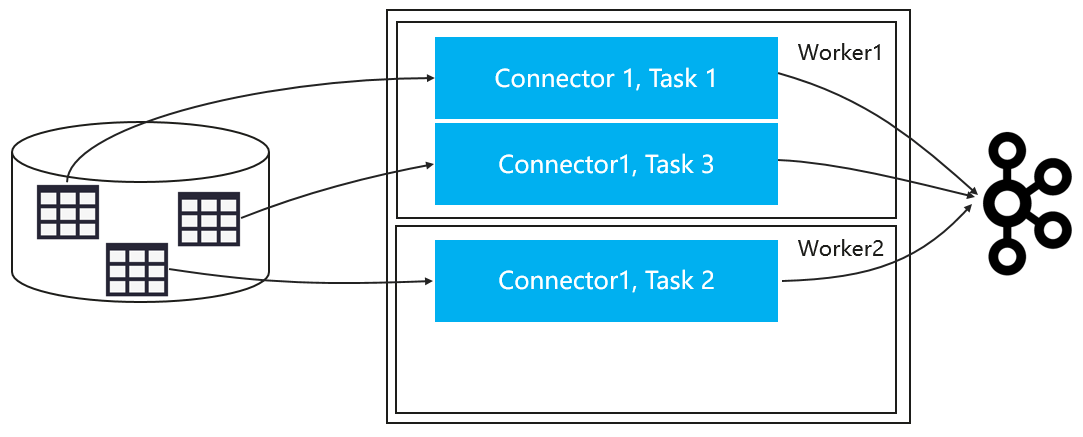
圖7 Task并發
- 使用Executor執行緒并行化執行任務
由于Log Miner,Bin Log等資料復制技術的限制,我們的Source Connector只能順序的捕獲CDC事件,因此,為了提高性能,我們將這些CDC事件先快取到記憶體佇列中,然后使用Executor執行緒并行的處理它們,這些執行緒會先從內部佇列中讀取資料,然后處理并且推送到Kafka中,
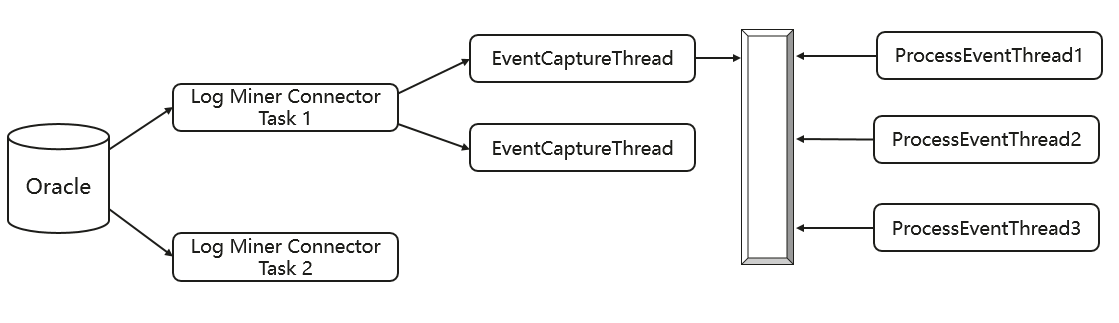
圖8 Executor執行緒并發
6 總結
MRS CDL是資料實時入湖場景下重要的一塊拼圖,我們仍然需要在資料一致性、易用性、多組件對接以及性能提升等場景需要進一步擴展和完善,在未來能夠更好的為客戶創造價值,
本文由華為云發布,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/445907.html
標籤:其他
上一篇:如何在Spark Scala/Java應用中呼叫Python腳本
下一篇:docker安裝