HDFS由namenode以及datanode兩個角色組成
NameNode
作用
1、NameNode 負責整個分布式檔案系統的元資料(MetaData)管理,也就是檔案路徑名、資料塊的 ID 以及存盤位置等資訊
2、接受DD上報的資訊
3、給DD分配任務(維護副本數)
元資料的存盤檔案方式:edits與fsimages
元資料保存于記憶體+硬碟(fsimage檔案、edits檔案中),記憶體中的全量資料用于加速NameNode讀取處理元資料的速度,而持久化的fsimage以及edits用于配合保存元資料,在能保證元資料安全的前提下加快保存恢復的速度,edits提升增量寫元資料的速度,fsimages(執行checkpoint策略:1h or 100萬次操作)用于整合或者合并操作,加速恢復記憶體元資料所用
存放于${hadoop_home}/data/tmp/dfs/name/current
其實分布式檔案系統玩的就是元資料,由NameNode管理分布式機器中的檔案,就是管理分布式機器中檔案的元資料而已
fsimage
第一次格式化后生成一個fsimages檔案(fsimage_000000000)
NN啟動時會將所有的edits和fsimage檔案全部加載到記憶體合并得到最新的元資料,并將合并后的元資料持久化到一個新的fsimage中
edits
NN啟動后每次的寫命令都會記錄到edits檔案中
edits檔案每隔一段時間或大小就會滾動生成一個新的edits檔案
edits_inprogress表示正在寫入的檔案
上傳后操作動作會寫入edits_inprogress_000000000001檔案,讀操作不記錄
inodes: 記錄檔案的屬性和檔案由哪些塊組成,記錄在fsimages、edits檔案中 blocklist: 塊分布在哪個DataNode中,每次DataNode啟動后自動上報
<inode> <id>16386</id> <type>FILE</type> <name>hello</name> <replication>3</replication> <mtime>1629810520020</mtime> <atime>1629810519641</atime> <perferredBlockSize>134217728</perferredBlockSize> <permission>hadoop:supergroup:rw-r--r--</permission> <blocks> <block> <id>1073741825</id> <genstamp>1001</genstamp> <numBytes>27</numBytes> </block> </blocks> </inode> <inode> <id>16387</id> <type>DIRECTORY</type> <name>wc</name> <mtime>1629810620719</mtime> <permission>hadoop:supergroup:rwxr-xr-x</permission> <nsquota>-1</nsquota> <dsquota>-1</dsquota> </inode>
NameNode元資料管理流程
當各種上傳操作用了一段時間后會變成下面這個樣子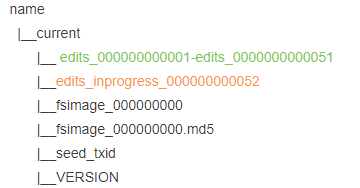
當寫入一段時間后,edits檔案會把之前的51次操作生成一個edits_000000000001-edits_0000000000051檔案,關閉
之后edits_inprogress改為edits_inprogress_000000000052并繼續寫入 這時我關閉NN,再啟動,啟動時會把fsimage_000000000+edits_000000000001-edits_0000000000051+edits_inprogress_000000000052合并生成一個fsimage_000000052(策略:1小時或100萬次操作)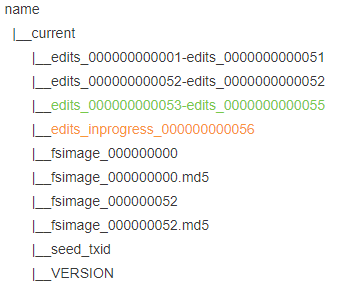 這時繼續上傳檔案變成上面那樣,這時再關閉重啟,重啟后只會加載比52大的檔案(找最新的元資料檔案加載):fsimage_000000052+edits_000000000053-edits_0000000000055
這時繼續上傳檔案變成上面那樣,這時再關閉重啟,重啟后只會加載比52大的檔案(找最新的元資料檔案加載):fsimage_000000052+edits_000000000053-edits_0000000000055
DataNode
一個資料塊在DataNode上以檔案形式存盤在磁盤上,包括兩個檔案,一個是資料本身,一個是元資料包括資料塊的長度,塊資料的校驗(crc校驗演算法,用戶資料完整性校驗)和,以及時間戳(mate)
${hadoop_home}/data/tmp/dfs/data/current/BP-1077754861-192.168.126.128-1629810385198/current/finalized/subdir0/subdir0
DataNode啟動后向NameNode注冊,通過后,周期性(1小時)的向NameNode上報所有的塊資訊
心跳是每3秒一次,心跳回傳結果帶有NameNode給該DataNode的命令如復制塊資料到另一臺機器,或洗掉某個資料塊,如果超過10分鐘(可以配置)沒有收到某個DataNode的心跳,則認為該節點不可用
NameNode啟動時,將所有的元資料加載完后,等待DataNode上報資料,如果上報的資料不全就會進入安全模式
當安全模式時,無法寫,只能部分讀
上報了的塊數(不考慮副本)/總塊數<99.99 就會進入安全模式,舉個例子,比如有13個塊,你只上報了10個塊,那么就會進入安全模式
當安全模式時,只能部分讀指的是單個檔案對應的所有的塊都已經上報了則可以讀,否則不可以讀
HDFS特點
HDFS不支持對檔案的隨機寫,只能追加不能修改
檔案在HDFS上存盤時,以block為基本單位存盤
沒有提供對檔案的在線尋址(打開)功能
檔案以塊形式存盤,修改了一個塊中的內容,就會影響當前塊之后所有的塊,效率低
HDFS不適合存盤小檔案
在線歸檔的功能實際是一個MR程式,這個程式將HDFS已經存在的多個小檔案歸檔為一個歸檔檔案
HDFS存盤了大量的小檔案,會降低NN的服務能力
NameNode負責檔案元資料(屬性,塊的映射)的管理,NN在運行時,必須將當前集群中存盤所有檔案的元資料全部加載到記憶體
存過多小檔案會導致NN占用大量記憶體
默認塊大小為128M,128M指的是塊的最大大小,每個塊最多存盤128M的資料,如果當前塊存盤的資料不滿128M,存了多少資料,就占用多少的磁盤空間
一個塊只能屬于一個檔案
HDFS寫資料原理
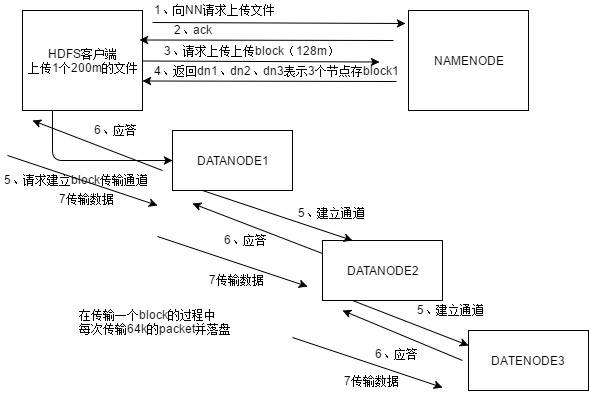
①服務端啟動HDFS中的NameNode和DataNode行程 ②客戶端創建一個分布式檔案系統客戶端,由客戶端向NameNode發送請求,請求上傳檔案 ③NameNode處理請求,檢查客戶端是否有權限上傳,路徑是否合法等 ④檢查通過,NameNode回應客戶端可以上傳 ⑤客戶端根據自己設定的塊大小,開始上傳第一個塊,默認0-128M(客戶端把檔案切好) NameNode根據客戶端上傳檔案的副本數(默認為3),根據機架感知策略選取指定數量的DataNode節點回傳 ⑥客戶端根據回傳的DataNode節點,請求建立傳輸通道 客戶端向最近(網路舉例最近)的DataNode節點發起通道建立請求,由這個DataNode節點依次向通道中的(距離當前DN距離最近) 下一個節點發送建立通道請求,各個節點發送回應 ,通道建立成功(每個DataNode都是要存相同資料的,冗余備份) ⑦客戶端每讀取64K的資料,封裝為一個packet(資料包,傳輸的基本單位),將packet發送到通道的下一個節點 通道中的節點收到packet之后,落盤(檢驗)存盤,將packet發送到通道的下一個節點 每個節點在收到packet后,向客戶端發送ack確認訊息
HDFS讀資料流程
先從NameNode獲取元資料,然后挑選DataNode,請求下載,以packet為單位接收,本地快取后寫入目標檔案
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/447055.html
標籤:其他