目錄
- 1. WebGL
- 2. WebGPU
- 2.1. 配接器(Adapter)和設備(Device)
- 2.2. 著色器(Shaders)
- 2.3. 管線(Pipeline)
- 2.4. 并行(Parallelism)
- 2.5. 作業組(Workgroup)
- 2.6. 指令(Command)
- 3. 資料交換
- 3.1. 系結組的布局(GPUBindGroupLayout)
- 3.2. 暫存緩沖區(Staging Buffer)
- 3.3. 過度調度
- 3.4. 麻煩的結構體(記憶體地址對齊問題)
- 3.5. 輸入輸出
- 4. 性能
- 5. 穩定性與可用性
- 總結
原文譯名:WebGPU - 專注于處理核心(GPU Cores),而不是繪圖畫布(Canvas)
原文發布于 2022年3月8日,傳送門 https://surma.dev/things/webgpu
這篇東西非常長,不計代碼字符也有1w字,能比較好理解 WebGPU 的計算管線中的各個概念,并使用一個簡單的 2D 物理模擬程式來理解它,本篇重點是在計算管線和計算著色器,繪圖部分使用 Canvas2D 來完成,
WebGPU 是即將推出的 WebAPI,你可以用它訪問圖形處理器(GPU),它是一種底層介面,
原作者對圖形編程沒有多少經驗,他是通過研究 OpenGL 構建游戲引擎的教程來學習 WebGL 的,還在 ShaderToy 上學習 Inigo Quilez 的例子來研究著色器,因此,他能在 PROXX 中創建背景影片之類的效果,但是他表示對 WebGL 并不太滿意,別急,下文馬上會解釋,
當作者開始注意 WebGPU 后,大多數人告訴他 WebGPU 這東西比 WebGL 多很多條條框框,他沒考慮這些,已經預見了最壞的情況,他盡可能找了一些教程和規范檔案來看,雖然彼時并不是很多,因為他找的時候 WebGPU 還在早期制定階段,不過,他深入之后發現 WebGPU 并沒有比 WebGL 多所謂的“條條框框”,反而是像見到了一位老朋友一樣熟悉,
所以,這篇文章就是來分享學到的東西的,
作者明確指出,他 不會 在這里介紹如何使用 WebGPU 繪制圖形,而是要介紹 WebGPU 如何呼叫 GPU 進行它本身最原始的計算(譯者注:也就是通用計算),
他覺得已經有很多資料介紹如何用 WebGPU 進行繪圖了,例如 austin 的例子,或許他考慮之后也寫一些繪圖方面的文章,
他在這里會討論得比較深入,希望讀者能正確、有效地使用 WebGPU,但是他不保證你讀完就能成為 GPU 性能專家,
絮絮叨叨結束后,準備發車,
1. WebGL
WebGL 是 2011 年發布的,迄今為止,它是唯一能在 Web 訪問 GPU 的底層 API,實際上它是 OpenGL ES 2.0 的簡易封裝版以便能在 Web 中使用,WebGL 和 OpenGL 都是科納斯組標準化的,這個作業組是圖形界的 W3C,可以這么理解,
OpenGL 本身是一個頗具歷史的 API,按今天的標準看,它不算是一個很好的 API,它以內部全域狀態物件為中心,這種設計可以最大限度減少特定呼叫的 GPU 的 IO 資料量,但是,這種設計有很多額外的開銷成本,
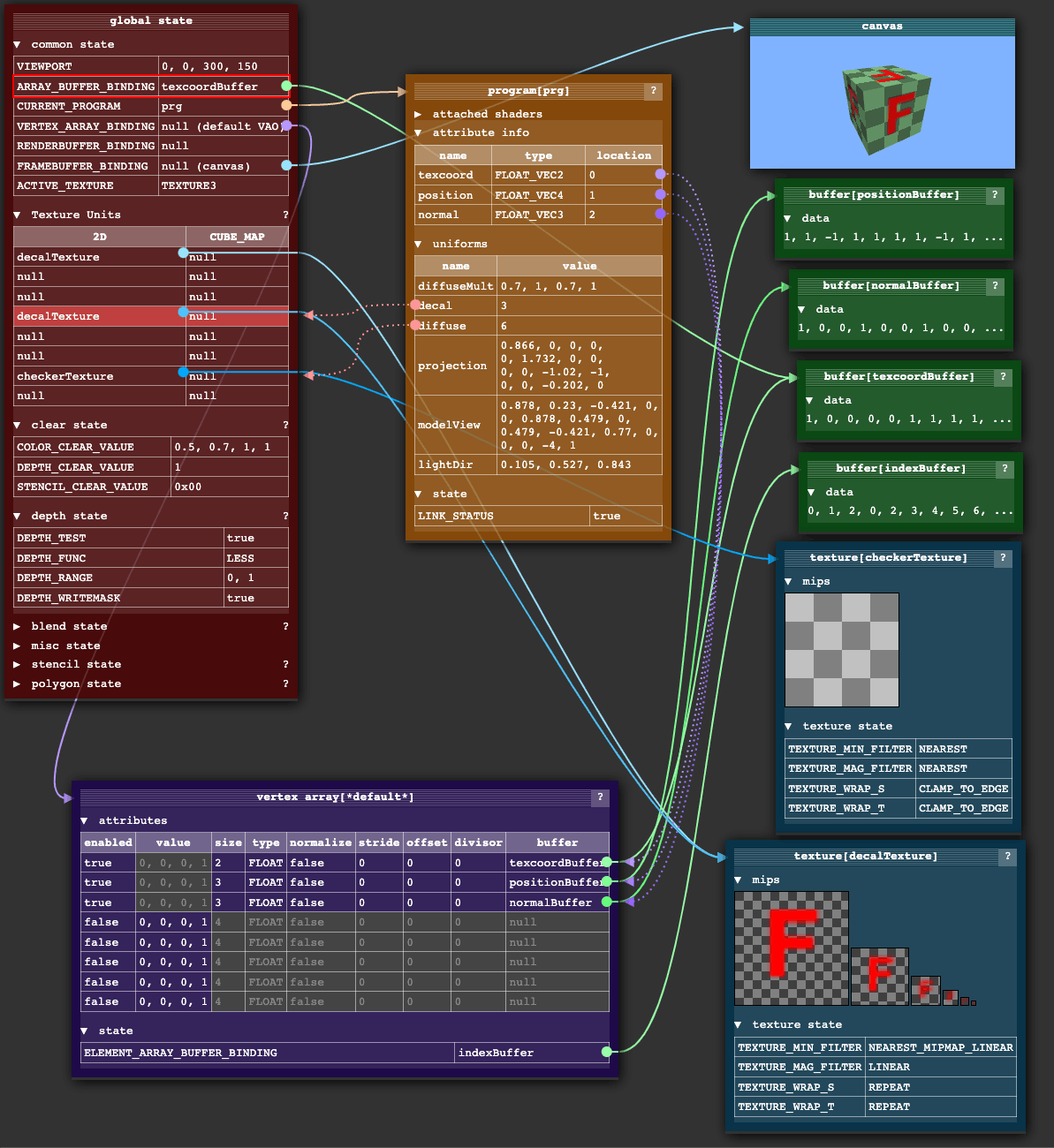
上圖:WebGL 內部全域狀態物件的可視化,源自 WebGL Fundamentals
內部狀態物件,說白了,大多數都是一些指標,呼叫 OpenGL API 會改變這些指標的指向,所以改變狀態的順序相當重要,這導致了抽象和寫庫的困難程度大大增加,你必須非常清楚地知道你現在馬上要進行的 API 呼叫需要準備什么狀態,呼叫完了還得恢復到之前的值,
他說,他經常會看到一個黑色的畫布(因為 WebGL 報錯大多數時候就這樣),然后得狂躁地找沒呼叫哪些 API 沒有正確設定全域狀態,
他承認,他不知道 ThreeJS 是如何做到狀態管理架構的,但是的確做的不錯,所以大多數人會使用 ThreeJS 而不是原生 WebGL,這是主要的原因了,
“不能很好認同 WebGL”這只是對原作者他自己說的,而不是讀者們,他表示,比他聰明的人用 WebGL 和 OpenGL 已經做了不少 nice 的東西,但是他一直不滿意罷了,
隨著機器學習、神經網路以及加密貨幣的出現,GPU 證明了它可以干除了畫三角形之外的事情,使用 GPU 進行任意資料的計算,這種被稱為 GPGPU,但是 WebGL 1.0 的目的并不在于此,如果你在 WebGL 1.0 想做這件事,你得把資料編碼成紋理,然后在著色器中對資料紋理進行解碼、計算,然后重新編碼成紋理,WebGL 2.0 通過 轉移反饋 讓這攤子事情更容易了一些,但是直到 2021 年 9 月,Safari 瀏覽器才支持 WebGL 2.0(大多數瀏覽器 2017 年 1 月就支持了),所以 WebGL 2.0 不算是好的選擇,
盡管如此,WebGL 2.0 仍然沒有改變 WebGL 的本質,就是全域狀態,
2. WebGPU
在 Web 領域外,新的圖形 API 已經逐漸成型,它們向外部暴露了一套訪問顯卡的更底層的介面,這些新的 API 改良了 OpenGL 的局促性,
主要就是指 DirectX 12、Vulkan、Metal
一方面來說,現在 GPU 哪里都有,甚至移動設備都有不錯的 GPU 了,所以,現代圖形編程(3D渲染、光追)和 GPGPU 會越來越普遍,
另一方面來看,大多數設備都有多核處理器,如何優化多執行緒與 GPU 進行互動,是一個重要的課題,
WebGPU 標準制定者注意到了這些現狀,在預加載 GPU 之前要做好驗證作業,這樣才能給 WebGPU 開發者以更多精力專注于壓榨 GPU 的性能,
下一代最受歡迎的 GPU API 是:
- 科納斯組的 Vulkan
- 蘋果的 Metal
- 微軟的 DirectX 12
為了把這些技術融合并帶到 Web,WebGPU 就誕生了,
WebGL 是 OpenGL 的一個淺層封裝,但是 WebGPU 并沒這么做,它引入了自己的抽象概念體系,汲取上述 GPU API 的優點,而不是繼承自這些更底層的 API.
原因很簡單,這三個 API 并不是全部都是全平臺通用的,而且有一些他們自己的非常底層的概念,對于 Web 這個領域來說顯得不那么合理,
相反,WebGPU 的設計讓人感覺“哇,這就是給 Web 設計的”,但是它的的確確又基于你當前機器的 GPU API,抽象出來的概念被 W3C 標準化,所有的瀏覽器都得實作,由于 WebGPU 相對來說比較底層,它的學習曲線會比較陡峭,但是作者表示會盡可能地分解,
2.1. 配接器(Adapter)和設備(Device)
最開始接觸到的 WebGPU 抽象概念是配接器(Adapter)和設備(Device),
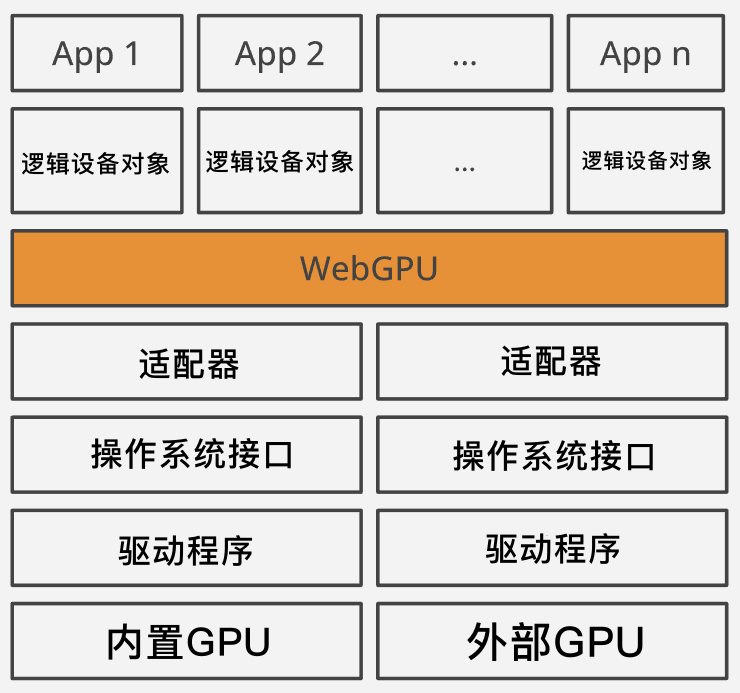
上圖:抽象層,從物理 GPU 到邏輯設備,
物理設備就是 GPU 本身,有內置的 GPU(核芯顯卡)和外部 GPU(獨立顯卡)兩種,通常,某個設備一般只有一個 GPU,但是也有兩個或者多個的情況,例如,微軟的 Surface 筆記本就具備雙顯卡,以便作業系統在不同的情況進行切換,
作業系統使用顯卡廠商提供的驅動程式來訪問 GPU;反過來,作業系統也可以用特定的 API(例如 Vulkan 或者 Metal)向外暴露 GPU 的功能,
GPU 是共享資源,它不僅要被各種程式呼叫,還要負責向顯示幕上輸出,這看起來需要一個東西來讓多個行程同時使用 GPU,以便每個行程把自己的東西畫在螢屏上,
對于每個行程來說,似乎看起里他們對 GPU 有唯一的控制權,但是那只是表象,實際上這些復雜邏輯是驅動程式和作業系統來完成調度的,
配接器(Adapter)是特定作業系統的 API 與 WebGPU 之間的中介,
但是,由于瀏覽器又是一個可以運行多個 Web 程式的“迷你作業系統”,因此,在瀏覽器層面仍需要共享配接器,以便每個 Web 程式感覺上就像唯一控制 GPU 一樣,所以,每個 Web 程式就獲得了再次抽象的概念:邏輯設備(Logical Device),
要訪問配接器物件,請呼叫 navigator.gpu.requestAdapter(),在寫本文時,這個方法的引數比較少,能讓你選請求的是高性能的配接器(通常是高性能獨顯)還是低功耗配接器(通常是核顯),
譯者注:本篇討論 WebGPU 的代碼,沒特殊指明,均為瀏覽器端的 WebGPU JavaScript API.
軟渲染:一些作業系統(諸如小眾 Linux)可能沒有 GPU 或者 GPU 的能力不足,會提供“后備配接器(Fallback Adapter)”,實際上這種配接器是純軟體模擬出來的,它可能不是很快,可能是 CPU 模擬出來的,但是能基本滿足系統運作,
若能請求到非空的配接器物件,那么你可以繼續異步呼叫 adapter.requestDevice() 來請求邏輯設備物件,下面是示例代碼:
if (!navigator.gpu) throw Error("WebGPU not supported.");
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) throw Error("Couldn’t request WebGPU adapter.");
const device = await adapter.requestDevice();
if (!device) throw Error("Couldn’t request WebGPU logical device.");
如果沒有任何請求設備的引數,那么 requestDevice() 會回傳一個不匹配任何設備功能要求的設備,即 WebGPU 團隊認為是合理且對于所有 GPU 都通用的設備物件,
請求設備物件程序中的“限制”見 規范,
舉個例子,即使我的 GPU 可以輕易處理 4GB 的資料,回傳的設備物件也只允許最大 1GB 的資料,你請求再多也只會回傳最大允許 1GB,這樣就算你切換到別的機器上跑代碼,就不會有太多問題,
你可以訪問 adapter.limits 查看物理 GPU 的實際限制情況,也可以在請求設備物件時,傳遞你所需要檢驗的更高限制引數,
2.2. 著色器(Shaders)
如果你用過 WebGL,那么你應該熟悉頂點著色器和片元(片段)著色器,其實也沒多復雜,常規技術路線就是上載三角形緩沖資料到 GPU,告訴 GPU 緩沖資料是如何構成三角形的,頂點緩沖的每個頂點資料描述了頂點的位置,當然還包括顏色、紋理坐標、法線等其它輔助內容,每個頂點都要經過頂點著色器處理,以完成平移、旋轉、透視變形等操作,
讓原作者感到困惑的是“著色器”這個詞,因為它除了著色之外還有別的作用,但是在很久以前(1980年代后期)來看,這個詞非常合適,它在 GPU 上的功能就是計算出像素的顏色值,而如今,它泛指在 GPU 上運行的任何程式,
GPU 會對三角形進行光柵化處理,計算出每個三角形在螢屏上占據的像素,每個像素,則交由片段著色器處理,它能獲取像素坐標,當然也可以加入一些輔助資料來決定該像素的最終著色,如果使用得當,就能繪制出令人驚嘆的 3D 效果,
將緩沖資料傳遞到頂點著色器,然后繼續傳送到片段著色器,最終輸出到螢屏上這一程序,可以簡單的稱之為管道(或管線,Pipeline),在 WebGPU 中,必須明確定義 Pipeline.
2.3. 管線(Pipeline)
目前,WebGPU 支持兩大管線:
- 渲染管線
- 計算管線
顧名思義,渲染管線繪制某些東西,它結果是 2D 影像,這個影像不一定要繪制到螢屏上,可以直接渲染到記憶體中(被稱作幀緩沖),計算管線則更加通用,它回傳的是一個緩沖資料物件,意味著可以輸出任意資料,
在本文的其它部分會專注于計算管線的介紹,因為作者認為渲染管線算是計算管線的一種特殊情況,
現在開始算開歷史倒車,計算管線原來其實是為了創建渲染管線而先做出來的“基礎”,這些所謂的管線在 GPU 中其實就是不同的物理電路罷了,
基于上述理解,倘若未來向 WebGPU 中添加更多型別的管線,例如“光追管線”,就顯得理所當然了,
使用 WebGPU API,管線由一個或多個可編程階段組成,每個階段由一個著色器模塊和一個入口函式定義,計算管線擁有一個計算著色階段,渲染管線有一個頂點著色階段和一個片段著色階段,如下所示是一個計算著色模塊與計算管線:
const module = device.createShaderModule({
code: `
@stage(compute) @workgroup_size(64)
fn main() {
// ...
}
`,
})
const pipeline = device.createComputePipeline({
compute: {
module,
entryPoint: "main",
},
})
這是 WebGPU 的著色語言(WGSL,發音 /wig-sal/)的首次登場,
WGSL 給作者的初印象是 Rust + GLSL,它有很多類似 Rust 的語法,也有類似 GLSL 一樣的全域函式(如 dot()、norm()、len() 等),以及型別(vec2、mat4x4 等),還有 swizzling 語法(例如 some_vec.xxy),
瀏覽器會把 WGSL 原始碼編譯成底層系統的著色器目標程式,可能是 D3D12 的 HLSL,也可能是 Metal 的 MSL,或者 Vulkan 的 SPIR-V.
SPIR-V:是科納斯組標準化出來的開源、二進制中間格式,你可以把它看作并行編程語言中的
LLVM,它支持多種語言編譯成它自己,也支持把自己翻譯到其它語言,
在上面的著色器代碼中,只創建了一個 main 函式,并使用 @stage(compute) 這個特性(Attribute,WGSL 術語)將其標記為計算著色階段的入口函式,
你可以在著色器代碼中標記多個 @stage(compute),這樣就可以在多個管線中復用一個著色器模塊物件了,只需傳遞不同的 entryPoint 選擇不同的入口函式即可,
但是,@workgroup_size(64) 特性是什么?
2.4. 并行(Parallelism)
GPU 以延遲為代價優化了資料吞吐量,想深入這點必須看一下 GPU 的架構,但是作者沒信心講好這塊,所以建議看一看 Fabian Giesen 的 文章,
眾所周知,GPU 有非常多個核心構成,可以進行大規模的并行運算,但是,這些核心不像 CPU 并行編程一樣相對獨立運作,首先,GPU 處理核心是分層分組的,不同廠商的 GPU 的設計架構、API 不盡一致,Intel 這里給了一個不錯的檔案,對他們的架構進行了高級的描述,
在 Intel 的技術中,最小單元被稱作“執行單元(Execution Unit,EU)”,每個 EU 擁有 7 個 SIMT 內核 —— 意思是,它有 7 個以“鎖步”(Lock-step)的方式運行同一個指令的并行計算核,每個內核都有自己的暫存器和調度快取的指標,盡管執行著相同的操作,但是資料可以是不同的,
所以有時候不推薦在 GPU 上執行 if/else 判斷分支,是因為 EU 的原因,因為 EU 遇到分支邏輯的時候,每個內核都要進行 if/else 判斷,這就失去了并行計算的優勢了,
對于回圈也是如此,如果某個核心提前完成了計算任務,那它不得不假裝還在運行,等待 EU 內其它核心完成計算,
盡管內核的計算頻率很高,但是從記憶體中加載資料或者從紋理中采樣像素的時間明顯要更長 —— Fabian 同志說,這起碼要耗費幾百個時鐘周期,這些時間顯然可以拿來算東西,為了充分利用這些時鐘周期,每個 EU 必須負重前行,
EU 空閑的時候,譬如在等記憶體的食物過來的時候,它可不會就一直閑下去,它會立馬投入到下一個計算中,只有這下一個計算再次進入等待時,才會切換回來,切換的程序非常非常短,
GPU 就是以這樣的技術為代價換來吞吐量的優化的,GPU 通過調度這些任務的切換機制,讓 EU 一直處于忙碌狀態,

上圖:Intel 銳炬 Xe 顯卡芯片架構,它被分成 8 個子塊,每個子塊有 8 個 EU;每個 EU 擁有 7 個 SIMT 內核,
不過,根據上圖來看,EU 只是 Intel 顯卡設計架構層級最低的一個,多個 EU 被 Intel 分為所謂的“子塊(SubSlice)”,子塊中所有的 EU 都可以訪問共有的區域快取(Shared Local Memory,SLM),大概是 64KB,如果所運行的程式有同步指令,那么就必須在同一個子塊中運行,因為這樣才能共享記憶體,
再往上,子塊就構成了塊(Slice),構成 GPU;對于集成在 CPU 中的 GPU,大約有 170 ~ 700 個內核,對于獨立顯卡,則會有 1500 或以上個內核,
其它廠商也許會用其它的術語,但是架構基本上可以這么類比理解,
為了充分利用 GPU 的架構優勢,需要專門寫程式呼叫,這樣就可以最大限度地壓榨 GPU 的性能,所以,圖形 API 得向外暴露類似的執行緒模型來呼叫計算任務,
在 WebGPU API 中,這種執行緒模型就叫做“作業組(Workgroup)”,
2.5. 作業組(Workgroup)
每個頂點都會被頂點著色器處理一次,每個片元則會被片元著色器處理一次(當然,這是簡單說法,忽略了很多細節),
而在 GPGPU 中,與頂點、片元類似的概念是需要開發者自己定義的,這個概念叫做 計算項,計算項會被計算著色器處理,
一組計算項就構成了“作業組”,作者稱之為“作業負載”,作業組中的每個計算項會被同時運行的計算著色器作用,在 WebGPU 中,作業組可以想象成一個三維網格,最小層級的是計算項,計算項構成稍大級別的是作業組,再往上就構成規模更大的作業負載,

上圖:這是一個作業負載,其中紅色小立方體由 43 個白色小立方體構成,白色小立方是計算項,而紅色小立方體則由這 64 個白色小立方構成,即作業組,
基于上述概念,就可以討論 WGSL 中的 @workgroup_size(x, y, z) 特性了,它的作用很簡單,就是告訴 GPU 這個計算著色器作用的作業組有多大,用上面的圖來說,其實就是紅色小立方的大小,x*y*z 是每個作業組的計算項個數,如果不設某個維度的值,那默認是 1,因此,@workgroup_size(64) 等同于 @workgroup_size(64, 1, 1).
當然,實際 EU 的架構當然不會是這個 3D 網格里面的某個單元,使用這個圖來描述計算項的目的是凸顯出一種區域性質,即假設相鄰的作業組大概率會訪問快取中相似的區域,所以順次運行相鄰的作業組(紅色小立方)時,命中快取中已有的資料的幾率會更高一些,而無需在再跑去顯存要資料,節省了非常多時間周期,
然而,大多數硬體依舊是順序執行作業組的,所以設定 @workgroup_size(64) 和 @workgroup_size(8, 8) 的兩個不同的著色器實際上差異并不是很大,所以,這個設計上略顯冗余,
作業組并不是無限維度的,它受設備物件的限制條件約束,列印 device.limits 可以獲取相關的資訊:
console.log(device.limits)
/*
{
// ...
maxComputeInvocationsPerWorkgroup: 256,
maxComputeWorkgroupSizeX: 256,
maxComputeWorkgroupSizeY: 256,
maxComputeWorkgroupSizeZ: 64,
maxComputeWorkgroupsPerDimension: 65535,
// ...
}
*/
可以看到,每個維度上都有最大限制,而且累乘的積也有最大限制,
提示:避免申請每個維度最大限制數量的執行緒,雖然 GPU 由作業系統底層調度,但如果你的 WebGPU 程式霸占了 GPU 太久的話,系統有可能會卡死,
那么,合適的作業組大小建議是多少呢?這需要具體問題具體分析,取決于作業組各個維度有什么指代含義,作者認為這答案很含糊,所以他參考了 Corentin 的話:“用 64 作為作業組的大小(各個維度累乘后),除非你十分清楚你需要呼叫 GPU 干什么事情,”
64 像是個比較穩妥的執行緒數,在大多數 GPU 上跑得還可以,而且能讓 EU 盡可能跑滿,
2.6. 指令(Command)
到目前為止,已經寫好了著色器并設定好了管線,剩下的就是要呼叫 GPU 來執行,由于 GPU 可以是有自己記憶體的獨立顯卡,所以可以通過所謂的“指令緩沖”或者“指令佇列”來控制它,
指令佇列,是一塊記憶體(顯示記憶體),編碼了 GPU 待執行的指令,編碼與 GPU 本身緊密相關,由顯卡驅動負責創建,WebGPU 暴露了一個“CommandEncoder”API 來對接這個術語,
const commandEncoder = device.createCommandEncoder()
const passEncoder = commandEncoder.beginComputePass()
passEncoder.setPipeline(pipeline)
passEncoder.dispatch(1)
passEncoder.end()
const commands = commandEncoder.finish()
device.queue.submit([commands])
commandEncoder 物件有很多方法,可以讓你把某一塊顯存復制到另一塊,或者操作紋理對應的顯存,它還可以創建 PassEncoder(通道編碼器),它可以配置管線并調度編碼指令,
在上述例子中,展示的是計算管線,所以創建的是計算通道編碼器,呼叫 setPipeline() 設定管線,然后呼叫 dispatch() 方法告訴 GPU 在每個維度要創建多少個作業組,以備進行計算,
換句話說,計算著色器的呼叫次數等于每個維度的大小與該維度呼叫次數的累積,
例如,一個作業組的三個維度大小是 2, 4, 1,在三個維度上要運行 4, 2, 2 次,那么計算著色器一共要運行 2×4 + 4×2 + 1×2 = 18 次,
順便說一下,通道編碼器是 WebGPU 的抽象概念,它就是文章最開始時作者抱怨 WebGL 全域狀態機的良好替代品,運行 GPU 管線所需的所有資料、狀態都要經過通道編碼器來傳遞,
抽象:指令緩沖也只不過是顯卡驅動或者作業系統的鉤子,它能讓程式呼叫 GPU 時不會相互干擾,確保相互獨立,指令推入指令佇列的程序,其實就是把程式的狀態保存下來以便待會要用的時候再取出,因為硬體執行的速度非常快,看起來就是各做各的,沒有受到其它程式的干擾,
跑起代碼,因為 workgroup_size 特性顯式指定了 64 個作業組,且在這個維度上呼叫了 1 次,所以最終生成了 64 個執行緒,雖然這個管線啥事兒都沒做(因為沒寫代碼),但是至少起作用了,是不是很酷炫?
隨后,我們搞點資料來讓它起作用,
3. 資料交換
如文章開頭所言,作者沒打算直接用 WebGPU 做圖形繪制,而是打算拿它來做物理模擬,并用 Canvas2D 來簡單的可視化,雖然叫是叫物理模擬,實際上就是生成一堆圓幾何,讓它們在平面范圍內隨機運動并模擬他們之間相互碰撞的程序,
為此,要把一些模擬引數和初始狀態傳遞到 GPU 中,然后跑計算管線,最后讀取結果,
這可以說是 WebGPU 最頭皮發麻的的一部分,因為有一堆的資料術語和操作要學,不過作者認為恰好是這些資料概念和資料的行為模式造就了 WebGPU,使它成為了高性能的且與設備無關的 API.
3.1. 系結組的布局(GPUBindGroupLayout)
為了與 GPU 進行資料交換,需要一個叫系結組的布局物件(型別是 GPUBindGroupLayout)來擴充管線的定義,
首先要說說系結組(型別是 GPUBindGroup),它是某種管線在 GPU 執行時各個資源的幾何,資源即 Buffer、Texture、Sampler 三種,
而先于系結組定義的系結組布局物件,則記錄了這些資源的資料型別、用途等元資料,使得 GPU 可以提前知道“噢,這么回事,提前告訴我我可以跑得更快”,
下列創建一個系結組布局,簡單起見,只設定一個存盤型(type: "storage")的緩沖資源:
const bindGroupLayout = device.createBindGroupLayout({
entries: [{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage",
}
}]
})
// 緊接著,傳遞給管線
const pipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module,
entryPoint: 'main'
}
})
binding 這里設為了 1,可以自由設定(當然得按順序),它的作用是在 WGSL 代碼中與相同 binding 值的 buffer 變數系結在一起,
@group(0) @binding(1)
var<storage, write> output: array<f32>;
type 欄位是 "storage",即說明這個 Buffer 的型別是存盤型,它還可以設定為其它的選項,其中 "read-only-storage" 即“只讀存盤型”,即著色器只能讀,但是不能寫這個 Buffer,只讀型緩沖可以優化一些讀寫同步的問題;而 "uniform" 則說明 Buffer 型別是統一資料(Uniform),作用和存盤型差不多(在著色器中值都一樣),
至此,系結組布局物件創建完畢,然后就可以創建系結組了,這里就不寫出來了;一旦創建好了對應的系結組和存盤型 Buffer,那么 GPU 就可以開始讀取資料了,
但是,在此之前,還有一個問題要討論:暫存緩沖區,
3.2. 暫存緩沖區(Staging Buffer)
這個小節的內容略長,請耐心閱讀,
作者再次強調:GPU 以延遲為代價,高度優化了資料 IO 性能,GPU 需要相當快的速度向內核提供資料,在 Fabian 他 2011 年的博客中做了一些計算,得出的結論是 GPU 需要維持 3.3 GB/s 的速度才能運行 1280×720 解析度的紋理的采樣計算,
為了滿足現在的圖形需求,GPU 還要再快,只有 GPU 的內核與緩沖存盤器高度集成才能實作,這意味著也就難以把這些存盤區交由 CPU 來讀寫,
我們都知道 GPU 有自己的記憶體,叫顯存,CPU 和 GPU 都可以訪問它,它與 GPU 的集成度不高,一般在電路板的旁邊,它的速度就沒那么快了,
暫存緩沖區(Staging buffers),是介于顯存和 GPU 之間的快取,它可以映射到 CPU 端進行讀寫,為了讀取 GPU 中的資料,要先把資料從 GPU 內的高速快取先復制到暫存緩沖區,然后把暫存緩沖區映射到 CPU,這樣才能讀取回主記憶體,對于資料傳遞至 GPU 的程序則類似,
回到代碼中,創建一個可寫的 Buffer,并添加到系結組,以便計算著色器可以寫入它;同時還創建一個大小一樣的 Buffer 以作為暫存,創建這些 Buffer 的時候,要用位掩碼來告知其用途(usage),GPU 會根據引數申請、創建這些緩沖區,如果不符合 WebGPU 規則,則拋出錯誤:
const BUFFER_SIZE = 1000
const output = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
})
const stagingBuffer = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST
})
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [{
binding: 1,
resource: {
buffer: output
}
}]
})
注意,createBuffer() 回傳的是 GPUBuffer 物件,不是 ArrayBuffer,創建完 Buffer 后還不能馬上寫入或者讀取,為了實作讀寫 Buffer,需要有單獨的 API 呼叫,而且 Buffer 必須有 GPUBufferUsage.MAP_READ 或 GPUBufferUsage.MAP_WRITE 的用途才能讀或寫,
TypeScript 提示:在各開發環境還未加入 WebGPU API 時,想要獲得 TypeScript 型別提示,還需要安裝 Chrome WebGPU 團隊維護的
@webgpu/types包到你的專案中,
到目前為止,不僅有系結組的布局物件,還有系結組本身,現在需要修改通道編碼器部分的代碼以使用這個系結組,隨后還要把 Buffer 中計算好的資料再讀取回 JavaScript:
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(pipeline)
passEncoder.setBindGroup(0, bindGroup)
passEncoder.dispatch(1)
passEncoder.dispatch(Math.ceil(BUFFER_SIZE / 64))
passEncoder.end()
commandEncoder.copyBufferToBuffer(
output,
0, // 從哪里開始讀取
stagingBuffer,
0, // 從哪里開始寫
BUFFER_SIZE
)
const commands = commandEncoder.finish()
device.queue.submit([commands])
await stagingBuffer.mapAsync(
GPUMapMode.READ,
0, // 從哪里開始讀,偏移量
BUFFER_SIZE // 讀多長
)
const copyArrayBuffer = stagingBuffer.getMappedRange(0, BUFFER_SIZE)
const data = https://www.cnblogs.com/onsummer/archive/2022/03/23/copyArrayBuffer.slice()
stagingBuffer.unmap()
console.log(new Float32Array(data))
稍前的代碼中,管線物件借助管線布局添加了系結組的局物件,所以如果在通道編碼的時候不設定系結組就會引起呼叫(dispatch)失敗,
在計算通道 end() 后,指令編碼器緊接著觸發一個緩沖拷貝方法呼叫,將資料從 output 緩沖復制到 stagingBuffer 緩沖,最河駁交指令編碼的指令緩沖到佇列上,
GPU 會沿著佇列來執行,沒法推測什么時候會完成計算,但是,可以異步地提交 stagingBuffer 緩沖的映射請求;當 mapAsync 被 resolve 時,stagingBuffer 映射成功,但是 JavaScript 仍未讀取,此時再呼叫 stagingBuffer.getMappedRange() 方法,就能獲取對應所需的資料塊了,回傳一個 ArrayBuffer 給 JavaScript,這個回傳的緩沖陣列物件就是顯存的映射,這意味著如果 stagingBuffer 的狀態是未映射時,回傳的 ArrayBuffer 也隨之沒有了,所以用 slice() 方法來拷貝一份,
顯然,可以在控制臺看到輸出效果:
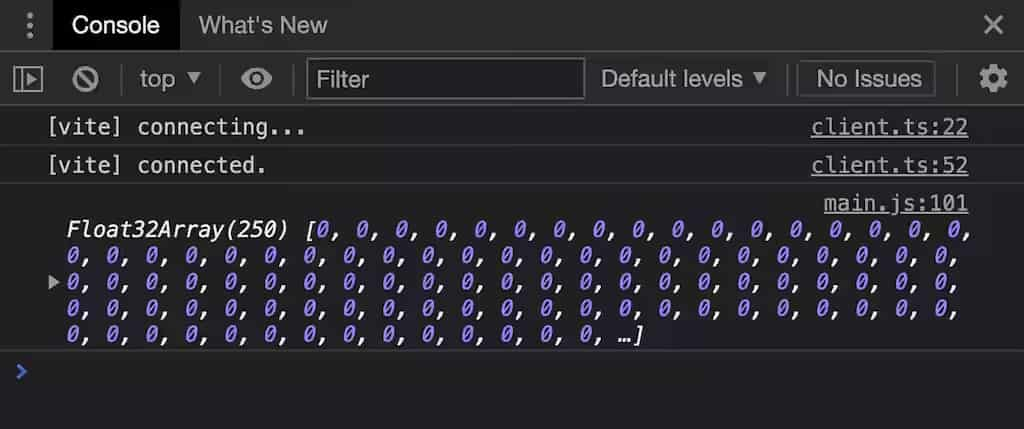
上圖:湊合,但是說明了一個問題,那就是從 GPU 顯存中把這堆 0 給拿下來了
或許,制造點 0 之外的資料會更有說服力,在進行高級計算之前,先搞點人工資料到 Buffer 中,以證明計算管線確實按預期在運行:
@group(0) @binding(1)
var<storage, write> output: array<f32>;
@stage(compute) @workgroup_size(64)
fn main(
@builtin(global_invocation_id)
global_id : vec3<u32>,
@builtin(local_invocation_id)
local_id : vec3<u32>,
) {
output[global_id.x] =
f32(global_id.x) * 1000. + f32(local_id.x);
}
前兩行宣告了一個名為 output 的模塊范圍的變數,它是一個 f32 元素型別的陣列,它的兩個特性宣告了來源,@group(0) 表示從第一個(索引為 0)系結組中獲取第 1 個系結資源,output 陣列是動態長度的,會自動反射對應 Buffer 的長度,
WGSL 變數:與 Rust 不同,let 宣告的變數是不可變的,如果希望變數可變,使用 var 宣告
接下來看 main 函式,它的函式簽名有兩個引數 global_id 和 local_id,當然這兩個變數的名稱隨你設定,它們的值取決于對應的內置變數 global_invocation_id、local_invocation_id,分別指的是 作業負載 中此著色器呼叫時的全域 x/y/z 坐標,以及 作業組 中此著色器呼叫時的區域 x/y/z 坐標,
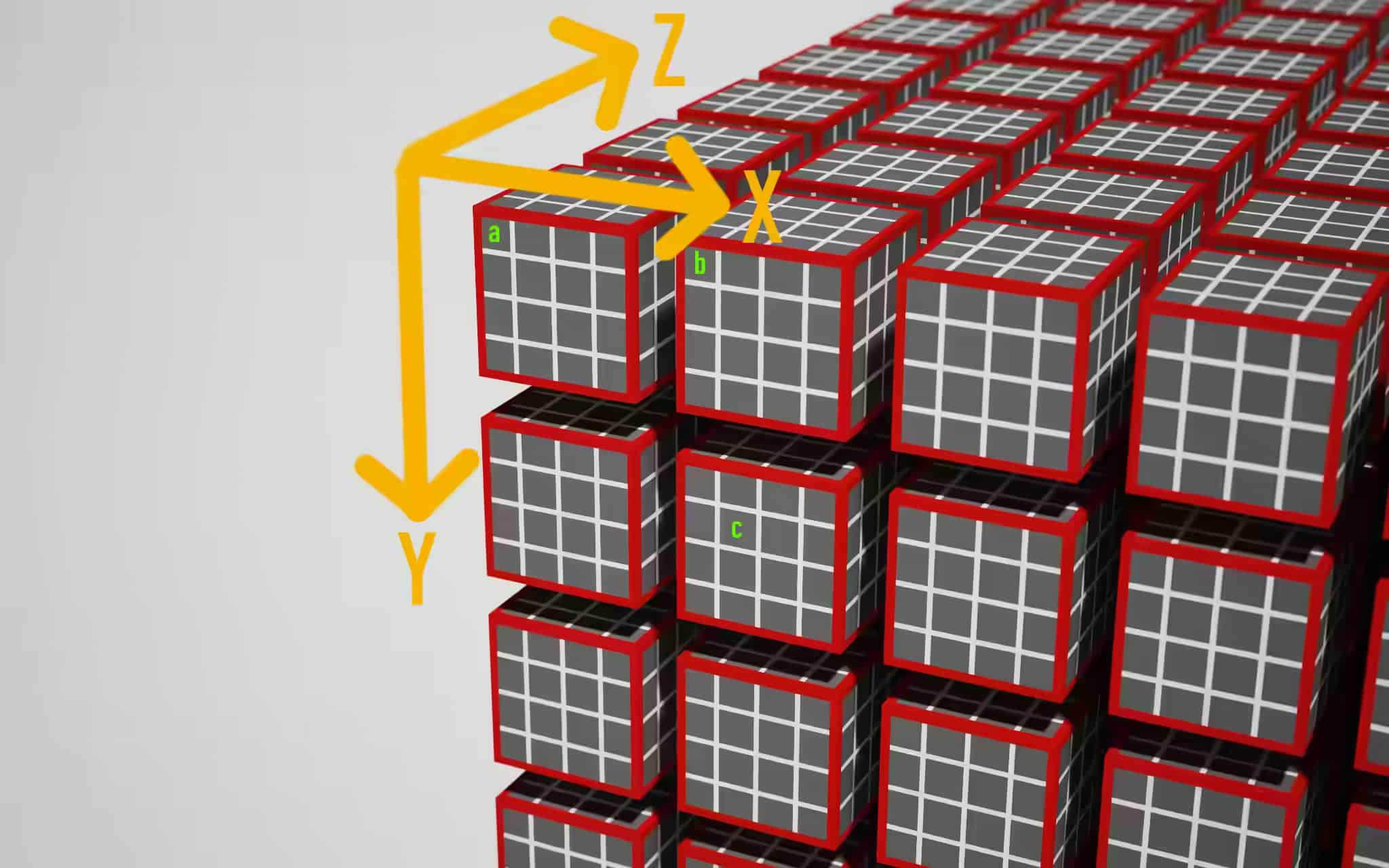
上圖:三個計算項,a、b、c,用綠色字母標注,
這張圖中使用的作業組大小是 @workgroup_size(4, 4, 4),使用圖中的坐標軸順序,那么對于圖中的 a、b、c 計算項:
- a:
local_id = (x=0, y=0, z=0),global_id = (x=0, y=0, z=0) - b:
local_id = (x=0, y=0, z=0),global_id = (x=4, y=0, z=0) - c:
local_id = (x=1, y=1, z=0),global_id = (x=5, y=5, z=0)
而對于我們的例子來說,作業組的大小被設為 @workgroup_size(64, 1, 1),所以 local_id.x 的取值范圍是 0 ~ 63. 為了能檢查 local_id 和 global_id,作者把這兩個值進行編碼,合成一個數字;注意,WGSL 型別是嚴格的,local_id 和 global_id 都是 vec3<u32>,因此要顯式地轉換為 f32 型別才能寫入 output 緩沖區,
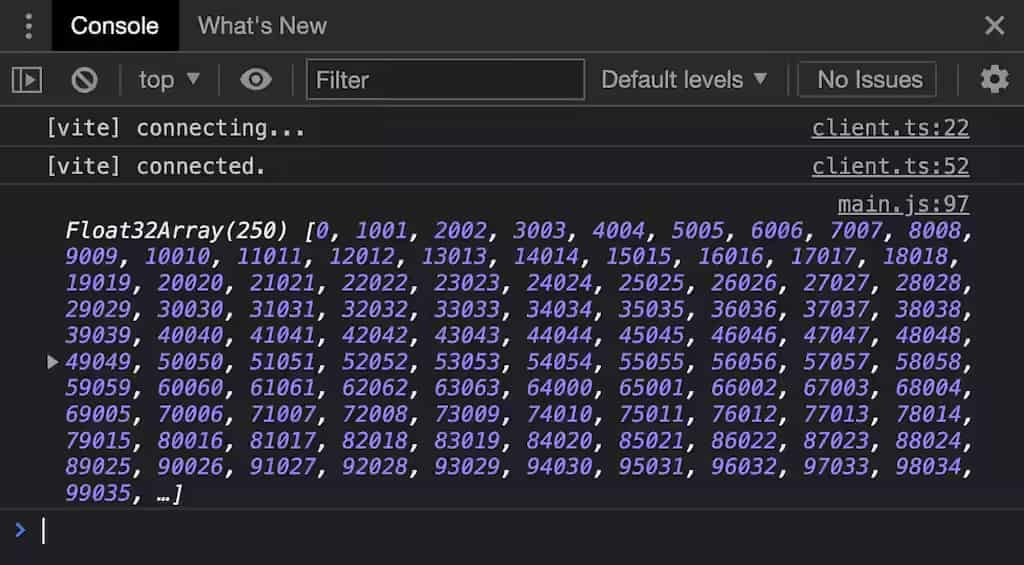
上圖:GPU 寫入的實際值,注意 local_id 是 63 為回圈的終點,而 global_id 則仍舊在繼續編碼
上圖證明了計算著色器確實向緩沖區輸出了值,但是很容易發現這些數字看似是沒什么順序的,因為這是故意留給 GPU 去做的,
3.3. 過度調度
你可能會注意到,計算通道編碼器的調度方法調度次數 Math.ceil(BUFFER_SIZE / 64) * 64 這個值,算出來就是 1024:
passEncoder.dispatch(Math.ceil(BUFFER_SIZE / 64))
這直接導致著色器代碼中 global_id.x 的取值能取到 1024,大于 Buffer 的長度 1000.
不過還好,WGSL 是有保護超出陣列索引范圍的機制的,即一旦發生對陣列索引越界的寫入,那么總是會寫入最后一個元素,這樣雖然可以避免記憶體訪問錯誤,但是仍有可能會生成一些無效資料,譬如,你把 JavaScript 端回傳的 Float32Array 的最后 3 個元素列印出來,它們是 247055、248056、608032;如何避免因陣列索引越界而可能發生的無效資料問題呢?可以用衛陳述句提前回傳:
fn main( /* ... */ ) {
if (global_id.x >= arrayLength(&output)) {
return;
}
output[global_id.x] = f32(global_id.x) * 100. + f32(local_id.x)
}
若讀者感興趣,可以運行這個例子看效果,
3.4. 麻煩的結構體(記憶體地址對齊問題)
還記得目標嗎?是在 2D 的 Canvas 中移動一些圓,并讓他們激情地碰撞,
所以,每個圓都要有一個半徑引數和一個坐標引數,以及一個速度矢量,可以繼續用 array<f32> 來表示上述資料,例如第一個數字是 x 坐標,第二個數字是 y 坐標,以此類推,
然而,這看起來有點蠢,WGSL 是允許自定義結構體的,把多條資料關聯在一個結構內,
注意:如果你知道什么是記憶體對齊,你可以跳過本小節;如果你不知道,作者也沒打算仔細解釋,他打算直接展示為什么要這么做,
因此,定義一個結構體 Ball,表示 2D 中的圓,并使用 array<Ball> 表示一系列的 2D 圓球,
使用結構體,就不得不討論記憶體對齊問題,
struct Ball {
radius: f32;
position: vec2<f32>;
velocity: vec2<f32>;
}
@group(0) @binding(1)
var<storage, write> output: array<Ball>;
@stage(compute) @workgroup_size(64)
fn main(
@builtin(global_invocation_id) global_id: vec3<u32>,
@builtin(local_invocation_id) local_id: vec3<u32>,
) {
let num_balls = arrayLength(&output);
if (global_id.x >= num_balls) {
return;
}
output[global_id.x].radius = 999.;
output[global_id.x].position = vec2<f32>(global_id.xy);
output[global_id.x].velocity = vec2<f32>(local_id.xy);
}
你可以運行這個代碼,打開控制臺可以看到:
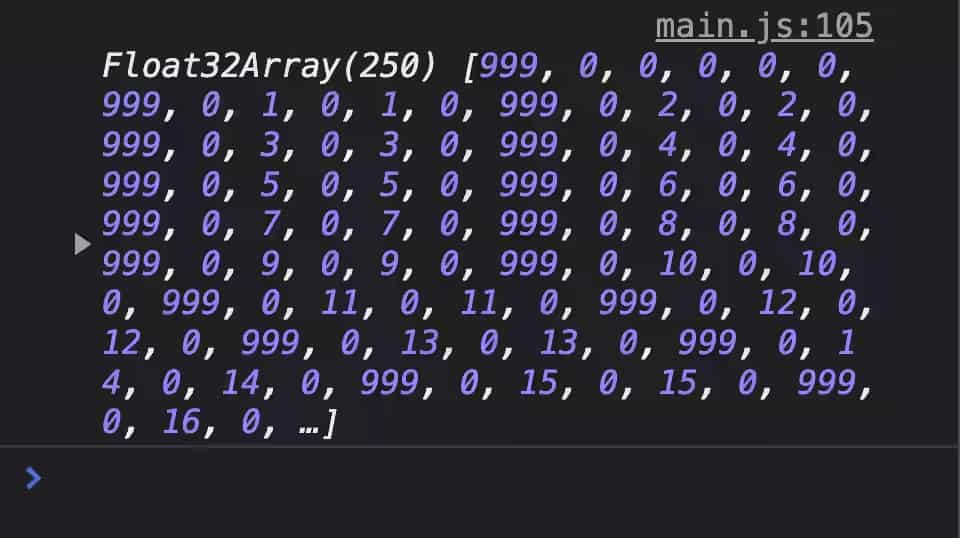
上圖:因為記憶體對齊的原因,這個 TypedArray 有明顯的資料填充現象
著色器代碼首先把資料 999.0 寫入到結構體的第一個欄位 radius 中,以便于觀察兩個結構的分隔界限;但是,這個列印的 Float32Array 中,兩個 999 數字之間,實際上跨越了 6 個數字,譬如上圖中 0~5 位數字是 999, 0, 0, 0, 0, 0,緊隨其后的 6~11 位數字是 999, 0, 1, 0, 1, 0,這就意味著每個結構體都占據了 6 個數字,但是 Ball 結構體明明只需要 5 個數字即可存盤:radius、position.x、position.y、velocity.x 和 velocity.y. 很明顯,每個 radius 后面都塞多了一個 0,這是為什么呢?
原因就是記憶體對齊,每一種 WGSL 中的資料型別都要嚴格執行對齊要求,
若一個資料資料型別的對齊尺度是 N(位元組),則意味著這個型別的資料值只能存盤在 N 的倍數的記憶體地址上,舉個例子,f32 的對齊尺度是 4(即 N = 4),vec2<f32> 的對齊尺度是 8(即 N = 8).
假設 Ball 結構的記憶體地址是從 0 開始的,那么 radius 的存盤地址可以是 0,因為 0 是 4 的倍數;緊接著,下個欄位 position 是 vec2<f32> 型別的,對齊尺度是 8,問題就出現了 —— 它的前一個欄位 radius 空閑地址是第 4 個位元組,并非 position 對齊尺度 8 的倍數,為了對齊,編譯器在 radius 后面添加了 4 個位元組,也就是從第 8 個位元組開始才記錄 position 欄位的值,這也就說明了控制臺中看到 999 之后的數字為什么總是 0 的原因了,
現在,知道結構體在記憶體中是如何分布位元組資料的了,可以在 JavaScript 中進行下一步操作了,
3.5. 輸入輸出
我們已經從 GPU 中讀取到資料了,現在要在 JavaScript 中解碼它,也就是生成所有 2D 圓的初始狀態,然后再次提交給 GPU 運行計算著色器,讓它“動起來”,初始化很簡單:
let inputBalls = new Float32Array(new ArrayBuffer(BUFFER_SIZE))
for (let i = 0; i < NUM_BALLS; i++) {
inputBalls[i * 6 + 0] = randomBetween(2, 10) // 半徑
inputBalls[i * 6 + 1] = 0 // 填充用
inputBalls[i * 6 + 2] = randomBetween(0, ctx.canvas.width) // x坐標
inputBalls[i * 6 + 3] = randomBetween(0, ctx.canvas.height) // y坐標
inputBalls[i * 6 + 4] = randomBetween(-100, 100) // x 方向速度分量
inputBalls[i * 6 + 5] = randomBetween(-100, 100) // y 方向速度分量
}
小技巧:如果你以后的程式用到了更復雜的資料結構,使用 JavaScript 拼湊這些位元組碼會非常麻煩,你可以用 Google 的 buffer-backed-object 庫去創建復雜的二進制資料(類似序列化),
還記得如何把 Buffer 傳遞給著色器嗎?不記得的回去看看上文,只需要調整一下計算管線的系結組布局即可接收新的 Buffer:
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: 'read-only-storage'
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: 'storage'
}
}
]
})
然后創建一個新的系結組來傳遞初始化后的 2D 圓球資料:
const input = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST
})
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: {
buffer: input // 輸入初始化資料
}
},
{
binding: 1,
resource: {
buffer: output
}
}
]
})
就像讀取資料一樣,從技術角度來看,為了輸入初始化的 2D 圓球資料,要創建一個可映射的暫存緩沖區 input,作為著色器讀取資料的容器,
WebGPU 提供了一個簡單的 API 便于我們把資料寫進 input 緩沖區:
device.queue.writeBuffer(input, 0, inputBalls)
就是這么簡單,并不需要指令編碼器 —— 也就是說不需要借助指令緩沖,writeBuffer() 是作用在佇列上的,
device.queue 物件還提供了一些方便操作紋理的 API.
現在,在著色器代碼中要用新的變數來與這個新的 input 緩沖資源系結:
// ... Ball 結構體定義 ...
@group(0) @binding(0)
var<storage, read> input: array<Ball>;
// ... output Buffer 的定義
let TIME_STEP: f32 = 0.016;
@stage(compute) @workgroup_size(64)
fn main(
@builtin(global_invocation_id)
global_id: vec3<u32>
) {
let num_balls = arrayLength(&output);
if (global_id.x >= num_balls) {
return;
}
// 更新位置
output[global_id.x].position =
input[global_id.x].position +
input[global_id.x].velocity * TIME_STEP;
}
希望大部分著色器代碼你能看得懂,
最后要做的,只是把 output 緩沖再次讀取回 JavaScript,寫一些 Canvas2D 的可視化代碼把 Ball 的運動效果展示出來(需要用到 requestAnimationFrame),你可以看示例效果:demo
4. 性能
3.5 小節最后演示的代碼只是能讓 Ball 運動起來,還沒有特別復雜的計算,在進行性能觀測之前,要在著色器中加一些適當的物理計算,
作者就不打算解釋物理計算了,寫到這里,博客已經很長了,但是他簡單的說明了物理效果的核心原理:每個 Ball 都與其它的 Ball 進行碰撞檢測計算,
如果你十分想知道,可以看看最終的演示代碼:final-demo,在 WGSL 代碼中你還可以找到物理計算的資料連接,
作者并未優化物理碰撞演算法,也沒有優化 WebGPU 代碼,即使是這樣,在他的 MacBook Air(M1處理器)上表現得也很不錯,
當超過 2500 個 Ball 時,幀數才掉到 60 幀以下,然而使用 Chrome 開發者工具去觀測性能資訊時,掉幀并不是 WebGPU 的問題,而是 Canvas2D 的繪制性能不足 —— 使用 WebGL 或 WebGPU 繪圖就不會出現這個問題了,
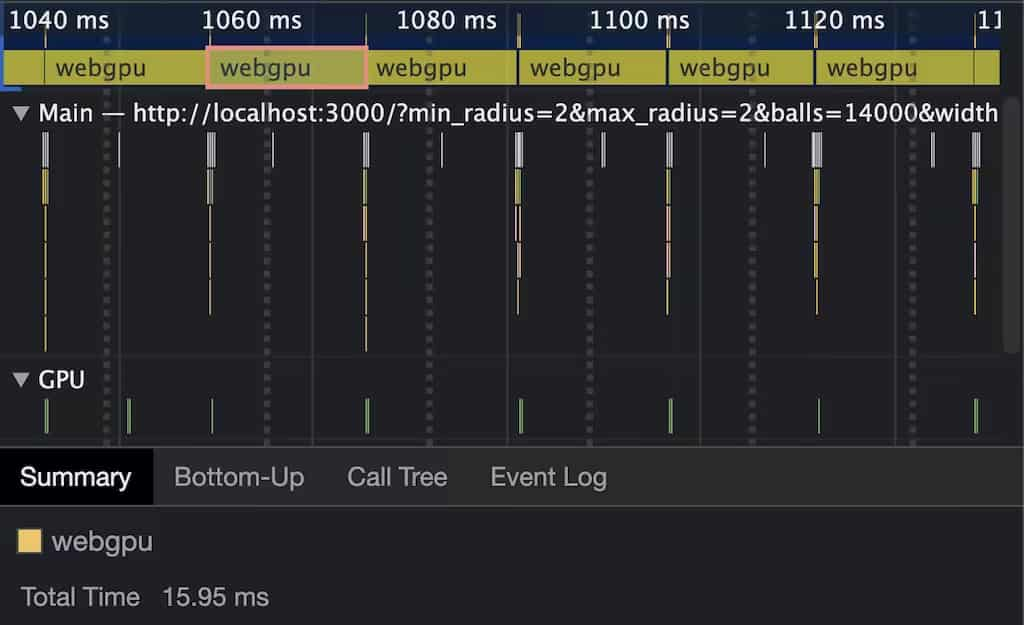
上圖:即使是 14000 個 Ball,WebGPU 在 M1 處理器的 MBA 筆記本上也才用了 16 毫秒的單幀計算時間
作者關閉了 Canvas2D 繪圖,加入 performance.measure() 方法來查看 16毫秒之內究竟可以模擬多少個 Ball 的物理計算,
這性能表現還是沒有優化過的,已經讓作者為之陶醉,
5. 穩定性與可用性
WebGPU 已經開發了蠻久了,作者認為制定規范的人希望 API 是穩定的,
話是這么說沒錯,但是 WebGPU API 目前只能跑在 Chrome 類瀏覽器和 FireFox 瀏覽器上,對 Safari 保持樂觀態度 —— 雖然寫本文時,Safari TP(技術預覽)還沒什么東西能看,
在穩定性表現上,即使是寫文章的這段時間里,也是有變化的,
例如,WGSL 著色器代碼的特性語法,從雙方括號改為 @ 符號:
[[stage(compute), workgroup_size(64)]]
↓
@stage(compute) @workgroup_size(64)
對通道編碼器結束的方法,Firefox 瀏覽器仍然是 endPass(),而 Chrome 類瀏覽器已經改為最新的 end().
規范中還有一些內容也并不是完全實作在所有瀏覽器上的,用于移動設備的 API 以及部分著色器常量就是如此,
基本上,WebGPU 進入 stable 階段后,不排除會發生很多重大變化,
總結
“在 Web 上能直接使用 GPU”這種現代的 API 看起來很好玩,在經歷過最初的陡峭學習曲線后,作者認為真的可以使用 JavaScript 呼叫 GPU 進行大規模并行運算了,
wgpu 是使用 Rust 實作的 WebGPU,你可以在瀏覽器之外使用 Rust 語言呼叫 WebGPU 規范的 API;wgpu 還支持編譯到 WebAssembly,你甚至可以使用 Rust 的 wgpu 撰寫 wasm,然后再放到瀏覽器運行高性能的代碼,
還有個有趣的東西:Deno 借助 wgpu,內置了 WebGPU 的支持,
如果你有啥問題,你可以去 WebGPU Matrix 頻道(國內可能訪問不太通暢)提問,那里有一些 WebGPU 的用戶、瀏覽器工程師和制定規范的人,
感謝 Brandon Jones 校對本文,感謝 WebGPU Matrix 頻道解惑,
也感謝原作者分享這篇長文,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/448140.html
標籤:其他