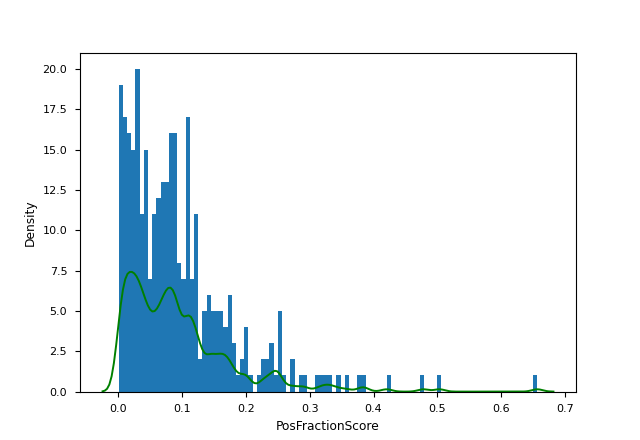
大家好,我正在嘗試從 0 到 1 之間采樣隨機值,權重由上述資料提供。scipy.stats.gaussian_kde我已經找到了使用及其.resample(n)方法的部分解決方案。我的主要問題是,因為我的大部分資料都非常接近于 0,所以重新采樣會回傳一堆負數,這些負數會打亂我以后的計算。
有沒有辦法限制我的重采樣都大于零,而不改變樣本空間?我考慮過只取一切的絕對值來消除負面影響,但我不知道這是否能反映分布權重。
為了澄清,我重新采樣的每個值 (n) 都將對應于我的代碼中的一個特定變數,所以我不能只洗掉小于零的數字。
# Here is a little sample dataset if you need something to work this out!
import numpy as np
data = np.array([0.147, 0.066, 0.017, 0.011, 0.040, 0.087, 0.024, 0.127, 0.071, 0.127,
0.027, 0.008, 0.067, 0.032, 0.247, 0.028, 0.122, 0.304, 0.074, 0.119])
# Thank you!
uj5u.com熱心網友回復:
您可以使用支持不包括負數的分布。例如,從指數分布采樣可能適用于您提供的示例陣列:
import numpy as np
from scipy.stats import expon
import matplotlib.pyplot as plt
data = np.array([0.147, 0.066, 0.017, 0.011, 0.040, 0.087, 0.024, 0.127, 0.071, 0.127, 0.027, 0.008, 0.067, 0.032, 0.247, 0.028, 0.122, 0.304, 0.074, 0.119])
# fit exponential model using data
loc, scale = expon.fit(data)
# plot histogram and model
fig, ax = plt.subplots()
ax.hist(data, density = True)
x = np.linspace(0.01, 1, 200)
ax.plot(x, expon.pdf(x, loc, scale), 'k-')
plt.show()
# sample from your modelled distribution using your fitted loc and scale parameters
sample = expon.rvs(loc, scale)
uj5u.com熱心網友回復:
要完成 Ben Devries 的回答,您有多種選擇來管理這種情況。您面臨一個截止值為零的分布(讓我們指出這可能不是這種情況,但是知道您的資料,您似乎確信這是不可能的,這沒關系!)。高斯 KDE 不能很好地處理這個問題,因為它們通常是在真實空間中定義的。
一個明智的選擇是從 KDE 切換到引數估計。這意味著您假設一種概率密度形式(基于資料的形式和您對其來源的了解)并嘗試調整概率密度引數(例如許多分布的 loc 和比例),以便密度適合資料. 在你的情況下,分布看起來像一個指數,很多。
如果您不知道,您可以嘗試堅持使用 KDE(順便說一下,一種非引數估計形式),并使用隨機變數轉換管理截止:您嘗試將函式應用于您的資料,以便它可以很容易地被 KDE 擬合,之后很容易恢復到原始分布。
在那里,對數變換似乎是應用的完美功能。詳細資訊鏈接: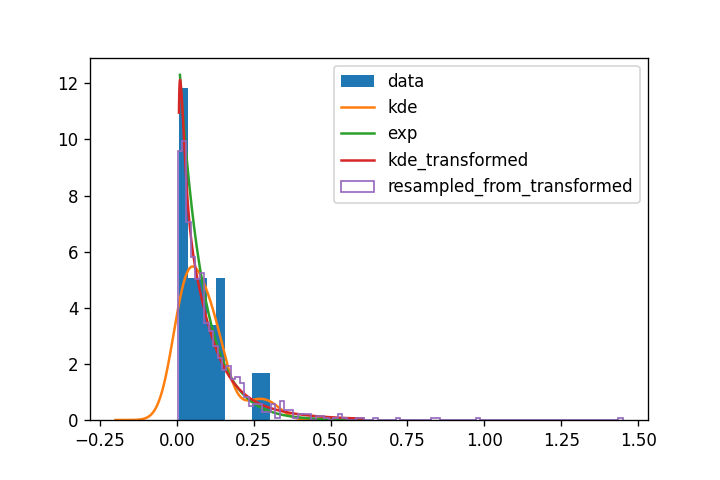
如你看到的:
- 指數匹配轉換后的 KDE 很多。這似乎是一個安全的選擇。
- 轉換后的 KDE 不會像 0 附近的指數擬合那樣表現出急劇的截止;這是我認為的典型技術(
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/448666.html下一篇:從向量自身的元素操作生成陣列