一.資訊量
資訊論背后的原理是:從不太可能的事件中,能學到更多的資訊,發生概率越小的事件資訊量越大,獨立事件包含額外的資訊
資訊量又譯為資訊本體,由克勞德·香農提出,用來衡量單一事件發生時所包含的資訊量多寡,它的單位是bit,或是nats,
資訊量是指一個事件所能夠帶來的資訊的多少,這個事件發生的概率越小,其帶來的資訊量越大
自資訊的含義包括兩個方面:
1.自資訊表示事件發生前,事件發生的不確定性,
2.自資訊表示事件發生后,事件所包含的資訊量,是提供給信宿的資訊量,也是解除這種不確定性所需要的資訊量
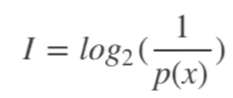
這仿佛和我們的直覺相反,假如有一個全知全能的上帝,他知道宇宙所有的資訊,任何事件對他來說都是確定無疑的,任何事情發生的概率都是1,那他腦中的資訊量一定是很大的
但是按照資訊量的概念,他的資訊量卻為0,這是怎么回事呢,正如定義所描述的資訊量是解除事件不確定性需要的資訊,下圖給出了一個直觀的解釋
任何事件的發生概率都介于0到1之間,確定的一極是有邊界的,這個邊界是1
但是不確定的一極是沒有邊界的,只能無限小趨于0卻不能等于0,因為0也是確定的,即這件事一定不會發生
我們總要選一個資訊量為0的標桿,就像重力勢能一樣,資訊也只有相互比較才有意義,資訊學家們選擇了概率為1作為這個標桿,至于為什么不選擇0作為標桿我自己有一點理解
比如說我要娶劉亦菲的概率是1/10,我中午吃胡辣湯的概率也1/10,但是這兩個事件包含的資訊量那肯定是不一樣的,吃胡辣湯的概率1/10說明了食堂有10種食物,娶劉亦菲的概率1/10那包含的資訊可太多了,要是真能這樣說明了我這個人還是挺厲害的,所以一個事件從不會發生到有概率發生需要的資訊不太好估量,但是從另一個角度講,假如有朝一日我娶劉亦菲的概率真的變成了1/10,和我真的娶到了劉亦菲這件事之間的差距看起來又不是很遙遠,就像搖骰子一樣,而這個骰子有10個面
所以資訊量的概念:解除事件不確定性需要的資訊(事件越不確定就意味著越混亂,我認為這個概念起名為資訊熵才很恰當,但是資訊熵另有其他含義)
那如何量化這個概念呢,再舉一個例子(圖源 王木頭學科學)
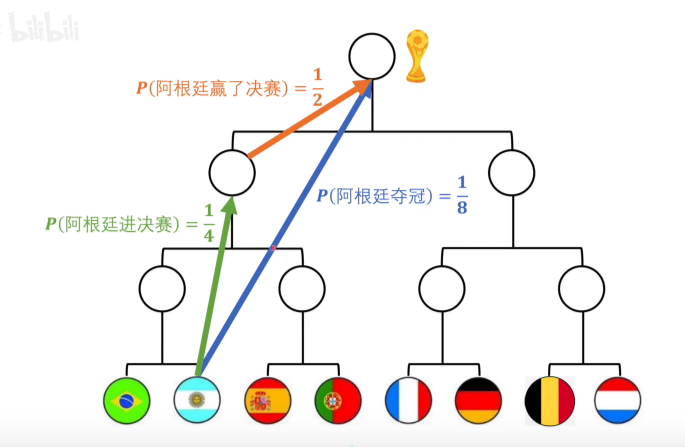
已知足球比賽中,阿根廷奪冠這件事 和 阿根廷進決賽并且贏了決賽,表達的是同一個意思,都是從奪冠概率1/8到奪冠這件事發生,那么這兩件事的資訊量應該是一致的,就有

所以 f 就被定義為(注意這里是人為規定的 一個符合上述兩條規律的函式)
![]()
這里的底數取2的原因是,如果底數取2,這個量就有了物理含義,它代表確定這個事件所需的位元位數,比如一個事件有A,B,C,D四種情況,每種情況發生概率為1/4,這樣f(1/4)=2,意思是2個bit可以確定這些情況,分別是00,01,10,11
二.資訊熵
資訊熵是每個事件的資訊量乘它發生的概率,熵既有熱力學概念,也有資訊論的概念還有這哲學概念,它反應系統的混亂程度(不確定程度)
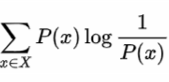
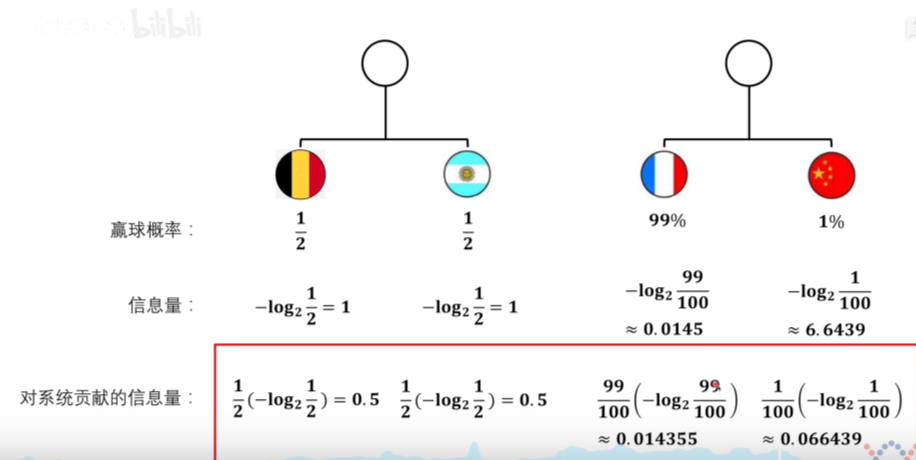
還以足球為例,中國對陣法國勝率為1%,法國有99%的概率會勝利,1%的概率會投降,所以中國隊的勝率是1%,雖然中國隊獲勝這個事件資訊量很大但是出現的概率低,所以對于總體的資訊熵貢獻不大
德國對陣比利時勝率各為1/2,雖然每個事件的資訊量不大,但是乘以概率后總體的資訊熵比較大,這個系統的資訊熵是1,這也符合我們的直覺,這個系統相對于中國對陣法國的系統不確定性更大,資訊熵也更大
用編碼位數的方式來解釋資訊熵,它也可以這樣被解釋,對于一個概率分布P,描述P中事件的平均編碼長度,當然,編碼的長度不能帶有小數,因為它代表了編碼的位數,但是我們所說的資訊熵是把這個情況從離散轉移到連續的情況,由此引出交叉熵和相對熵(KL散度)的概念
三.交叉熵和相對熵
交叉熵刻畫了使用錯誤分布Q來表示真實分布P中的樣本的平均編碼長度
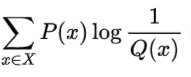
相對熵(KL散度)刻畫了錯誤分布Q來表示真實分布P中的樣本的平均編碼長度的增量
從定義也可以看出相對熵 = 交叉熵 - P的資訊熵
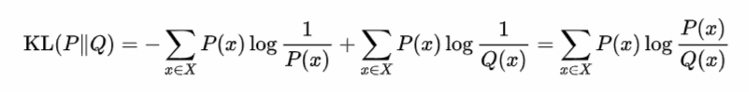
由吉布斯不等式可以證明,當使用錯誤的分布Q的編碼來表示P時,總會比用P來編碼P的長度更大,即相對熵總是個正值,它可以用來表示兩個概率分布的差異(PQ和QP的KL散度是不一樣的,不對稱性)
![]()
這樣我們就得到了兩個重要的工具:
資訊熵:描述概率分布的混亂程度,我們獲取的資訊越多,資訊熵就越低
相對熵:描述兩個概率分布的差異
由此引出它們在機器學習領域的應用:
四.簡介幾個熵在機器學習領域的應用
1.決策樹的屬性選擇基于資訊熵,通過某個屬性的劃分更能夠幫助對最終的結果進行預測,也就是更有助于降低資訊熵,就認為這個屬性對于最終的結果預測的幫助越大,這個屬性就蘊含更多的資訊
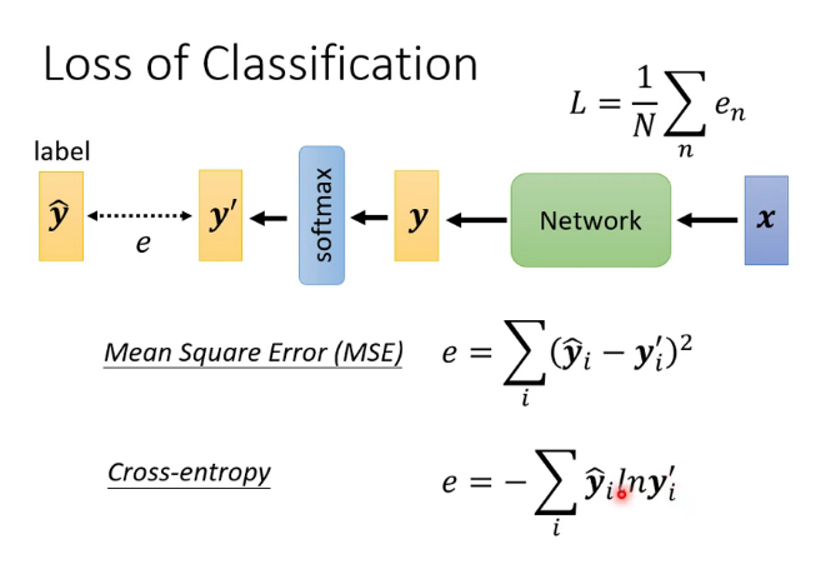
2.分類任務的損失函式可以使用交叉熵
分類器的輸出一般是樣本屬于各個類別的概率,這個整體就是一個概率分布,而真實樣本也可以理解成一個one-hot的概率分布,這兩個概率分布的差異就可以用相對熵來表述,所以loss函式就可以使用相對熵,又因為相對熵 = 交叉熵 - 真實分布的資訊熵,資訊熵是一個固定值,所以我們就使用交叉熵作為loss函式,
除此之外,交叉熵的損失函式更加平滑,相對于MSE更能夠幫助學習,它的等高線如圖所示,紅色代表loss大,藍色代表loss小,可以看出交叉熵更加平滑
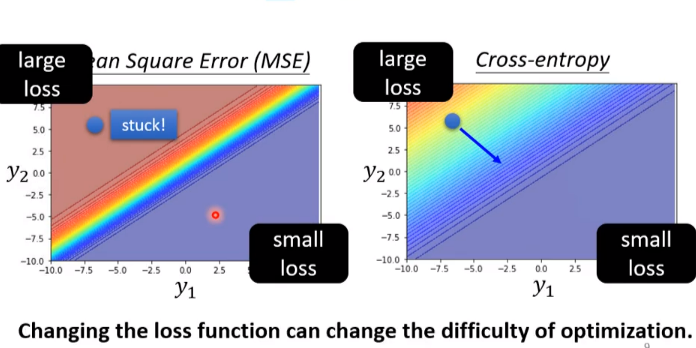
所以如果提問,為什么交叉熵適合做分類問題的損失函式?就可以這樣回答
理論上:softmax輸出的就是概率分布,KL散度恰好可以用來刻畫兩個概率分布之間的差異,而真實分布的資訊熵是固定的,所以可用交叉熵可以當作損失函式
實際上:最后一層是softmax時損失函式是這樣的,交叉熵里loss很大時梯度很大,MSEloss大時梯度很大,更大時反而梯度很小,是一個劇變,使用交叉熵更易收斂
五.其他關于熵的思考
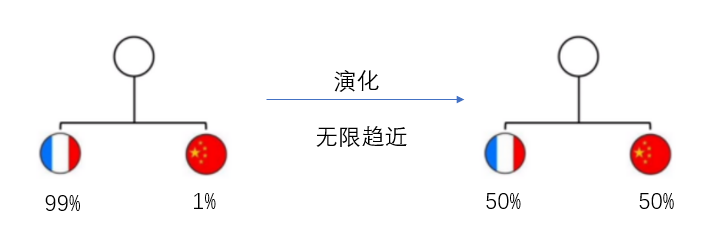
我聽說過一個說法,一個耗散系統的演化是從低熵向高熵進行,還拿足球舉例子,中國隊對陣法國隊目前勝率是1%,但是把這兩個隊天天放在一起訓練,最后兩者的勝率就會無限趨近于50%,就像溶液從高濃度流向低濃度一樣,最后不是中國隊把法國隊帶撈了,就是法國隊把中國隊帶強了
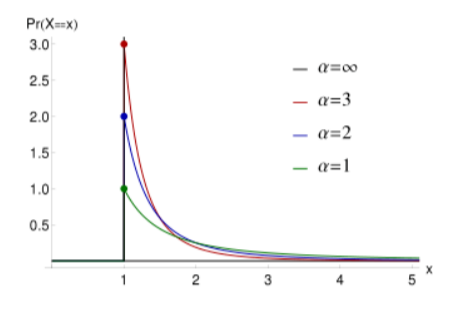
你可能還聽說過一個叫做二八定律的東西,20%的人掌握著社會80%的財富,把這種離散的模型遷移到連續的情況,這就是帕累托分布(這是一個厚尾模型,它的u均值在采樣無限時可以趨于無限大)從如下的影像可以看到,采樣時大部分樣本都聚集在前面,但采樣足夠多時,總有x非常大的樣本來影響采樣資料整體的分布,這個概率分布的熵值就很低
與帕累托分布相比,正態分布的熵值就非常大,這也對應了事物演化的開始和結局
有一種說法,宇宙誕生時是符合帕累托分布的,它的熵值很低,也具有很大的活力;宇宙熱寂時,它的熵值很大,符合正態分布,也就是說事物的發展程序就是從冪律分布到正態分布
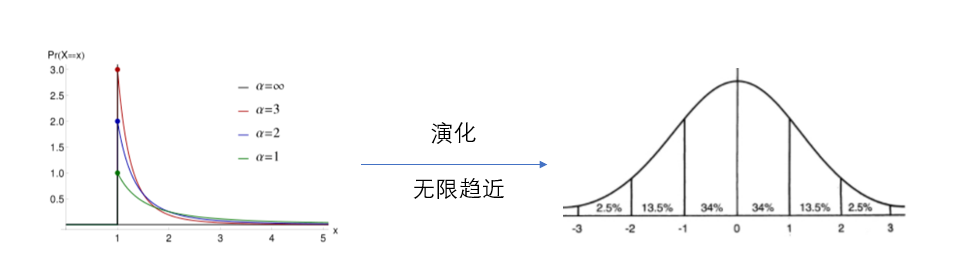
還拿二八定律舉例,我們目前社會的財富比例符合二八定律,大部分財富在少部分人手中,但它最終必將演化到正態分布,大部分財富掌握在大部分人手中,這時社會形態就從資本主義演化到共產主義,我們又從資訊論的理論證明了馬克思主義的正確性
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/449084.html
標籤:其他