import requests
from fake_useragent import UserAgent
import csv
import re
import time
import random
class CFP2_spider(object):
def __init__(self):
self.first_url = 'https://www.springer.com/journal/11263/updates'
self.second_url = 'https://www.springer.com/journal'
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0) Gecko/20100101 Firefox/76.0'}
self.regex_first = '<a href="https://bbs.csdn.net/topics/(/journal/11263/updates/.*?)"'
self.regex_title = '<h1>(.*?)</h1>'
self.regex_submissiontime = '<p>.*?Submission deadline:</strong>(.*?)</p>|<p>.*?(Submission deadline:[^</strong>].*?)</p>|<li>(deadline.*?)</li>'
self.regex_decisiontime = '<[a-zA-Z]>(final.*decision:.*?)</[a-zA-Z]>|<li>(final decision by.*?)</li>'
self.regex_manuscript_submission = '<[a-zA-Z]>(final manuscript.*?:.*?)</[a-zA-Z]>'
self.regex_submission_email = '([a-zA-z]+://VISI[^\s]*?.com)'
#得到次級頁面URL函式
def getres(self,url):
res = requests.get(url=url,headers=self.headers).text
return res
def regex_f(self,regex,res):
pattern = re.compile(regex,re.I)
lists = re.findall(pattern,res)
return lists
def parse_first(self,first_url):
res_first = self.getres(first_url)
links = self.regex_f(self.regex_first,res_first)
for a in links:
url_second = self.second_url + a
self.parse_second(url_second)
#決議次級頁面函式
def parse_second(self,second_url):
res_second = self.getres(second_url)
title = self.regex_f(self.regex_title,res_second)
submissiontime = self.regex_f(self.regex_submissiontime,res_second)
final_decisiontime = self.regex_f(self.regex_decisiontime,res_second)
manuscript_submission = self.regex_f(self.regex_manuscript_submission,res_second)
submission_email = self.regex_f(self.regex_submission_email,res_second)
print(title)
print(submissiontime)
print(final_decisiontime)
print(manuscript_submission)
print(submission_email)
self.writecsv(title, submissiontime, final_decisiontime, manuscript_submission, submission_email)
def writecsv(self,title,submissiontime,final_decisiontime,manuscript_submission,submission_email):
with open('cfpmess3.csv', 'a', encoding='utf-8')as f:
writer = csv.writer(f)
writer.writerow([title, submissiontime, final_decisiontime,manuscript_submission, submission_email])
f.close()
#入口函式
def run(self):
url = self.first_url
self.parse_first(url)
#主函式
if __name__ == '__main__':
spider = CFP2_spider()
spider.run()

而我把一級爬蟲爬取下來的第一個子頁面直接賦值給requests庫的時候再來運行,則得到我想要結果:
import requests
from fake_useragent import UserAgent
import csv
import re
from multiprocessing.dummy import Pool
linklist=[]
title = []
submissiontime = []
manuscript_submission = []
submission_email = []
final_decisiontime = []
url_s ='https://www.springer.com/journal/11263/updates/17198708'
response = requests.get(url_s).text
pattern1 = re.compile("<h1>(.*?)</h1>")#匹配title的模板
pattern2 = re.compile("<p>.*?Submission deadline:</strong>(.*?)</p>|<p>.*?(Submission deadline:[^</strong>].*?)</p>|<li>(deadline.*?)</li>",re.I)
pattern3 = re.compile("<[a-zA-Z]>(final.*decision:.*?)</[a-zA-Z]>|<li>(final decision by.*?)</li>",re.I)
pattern4 = re.compile("<[a-zA-Z]>(final manuscript.*?:.*?)</[a-zA-Z]>",re.I)
pattern5 = re.compile('([a-zA-z]+://VISI[^\s]*?.com)')
title = re.findall(pattern1,response)
submissiontime = re.findall(pattern2,response)
final_decisiontime = re.findall(pattern3,response)
manuscript_submission= re.findall(pattern4,response)
submission_email = re.findall(pattern5,response)
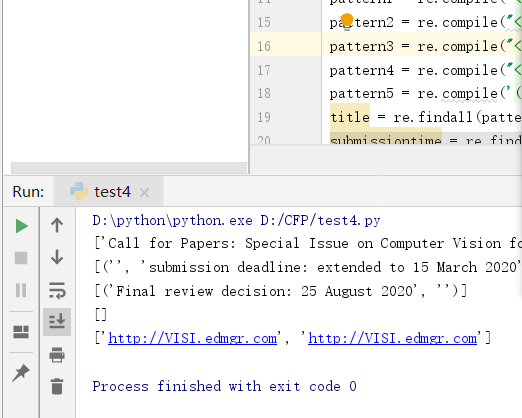
print(title)
print(submissiontime)
print(final_decisiontime)
print(manuscript_submission)
print(submission_email)
uj5u.com熱心網友回復:
做了很久的爬蟲,感覺就差這一點就成功了uj5u.com熱心網友回復:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/44927.html
上一篇:Get請求回傳的是html原始碼,原始碼里有js檔案如何給js檔案加斷點
下一篇:【小白】在使用了Go module之后,go build和go install 的區別是什么呢?怎么不加引數好像都不會生成.a檔案了