背景
傳統大資料平臺的組織架構是針對離線資料處理需求設計的,常用的資料匯入方式為采用sqoop定時作業批量匯入,隨著資料分析對實時性要求不斷提高,按小時、甚至分鐘級的資料同步越來越普遍,由此展開了基于spark/flink流處理機制的(準)實時同步系統的開發,
然而實時同步從一開始就面臨如下幾個挑戰:
- 小檔案問題,不論是spark的microbatch模式,還是flink的逐條處理模式,每次寫入HDFS時都是幾MB甚至幾十KB的檔案,長時間下來產生的大量小檔案,會對HDFS namenode產生巨大的壓力,
- 對update操作的支持,HDFS系統本身不支持資料的修改,無法實作同步程序中對記錄進行修改,
- 事務性,不論是追加資料還是修改資料,如何保證事務性,即資料只在流處理程式commit操作時一次性寫入HDFS,當程式rollback時,已寫入或部分寫入的資料能隨之洗掉,
Hudi就是針對以上問題的解決方案之一,使用Hudi自帶的DeltaStreamer工具寫資料到Hudi,開啟–enable-hive-sync 即可同步資料到hive表,
Hudi DeltaStreamer寫入工具介紹
HoodieDeltaStreamer實用工具 (hudi-utilities-bundle中的一部分) 提供了從DFS或Kafka等不同來源進行攝取的方式,并具有以下功能,
- 從Kafka單次攝取新事件,從Sqoop、HiveIncrementalPuller輸出或DFS檔案夾中的多個檔案
- 支持json、avro或自定義記錄型別的傳入資料
- 管理檢查點,回滾和恢復
- 利用DFS或Confluent schema注冊表的Avro模式,
- 支持自定義轉換操作
場景說明
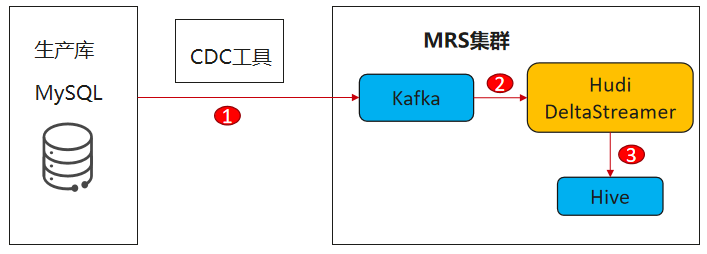
- 生產庫資料通過CDC工具(debezium)實時錄入到MRS集群中Kafka的指定topic里,
- 通過Hudi提供的DeltaStreamer工具,讀取Kafka指定topic里的資料并決議處理,
- 同時使用DeltaStreamer工具將處理后的資料寫入到MRS集群的hive里,
樣例資料簡介
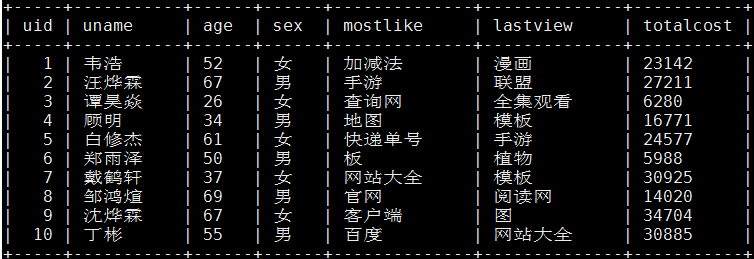
生產庫MySQL原始資料:
CDC工具debezium簡介
對接步驟具體參考:https://fusioninsight.github.io/ecosystem/zh-hans/Data_Integration/DEBEZIUM/
完成對接后,針對MySQL生產庫分別做增、改、洗掉操作對應的kafka訊息
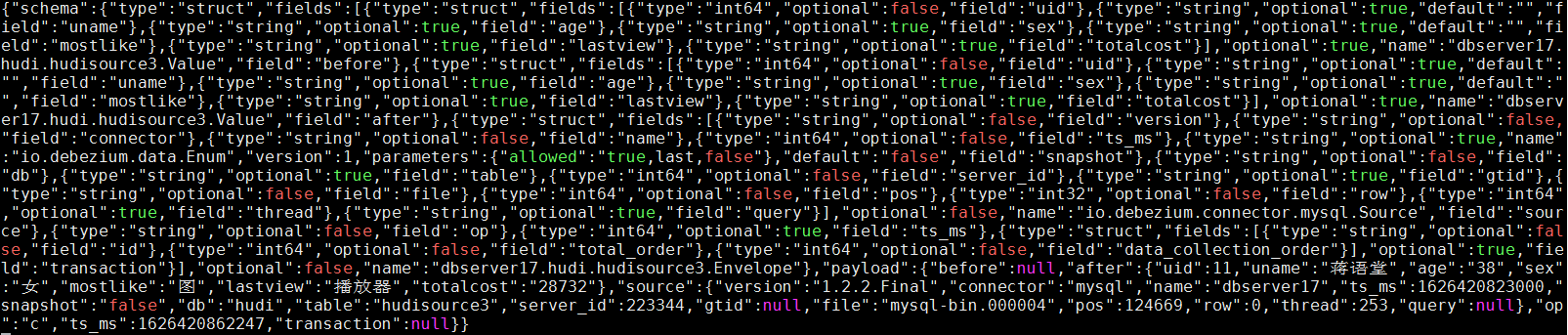
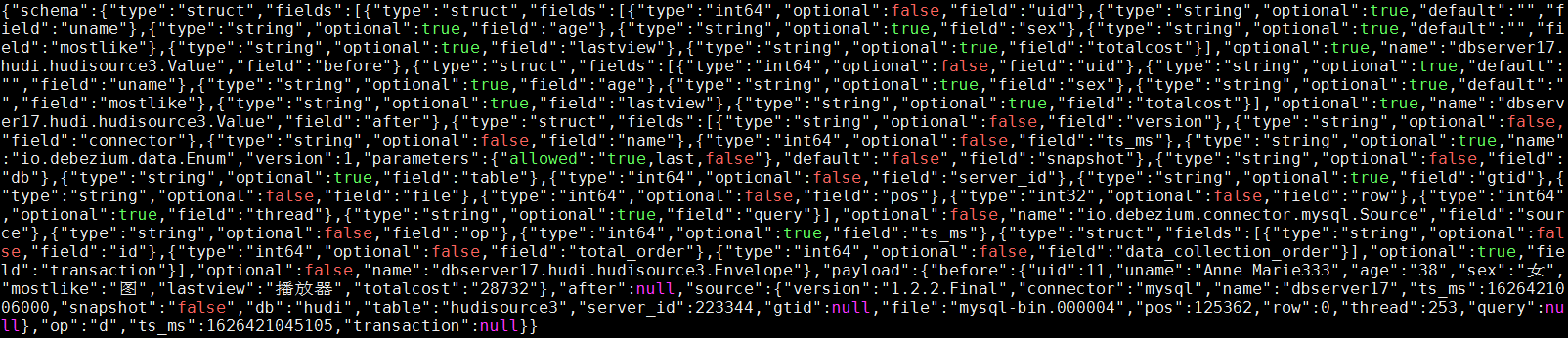
增加操作: insert into hudi.hudisource3 values (11,“蔣語堂”,“38”,“女”,“圖”,“播放器”,“28732”);
對應kafka訊息體:
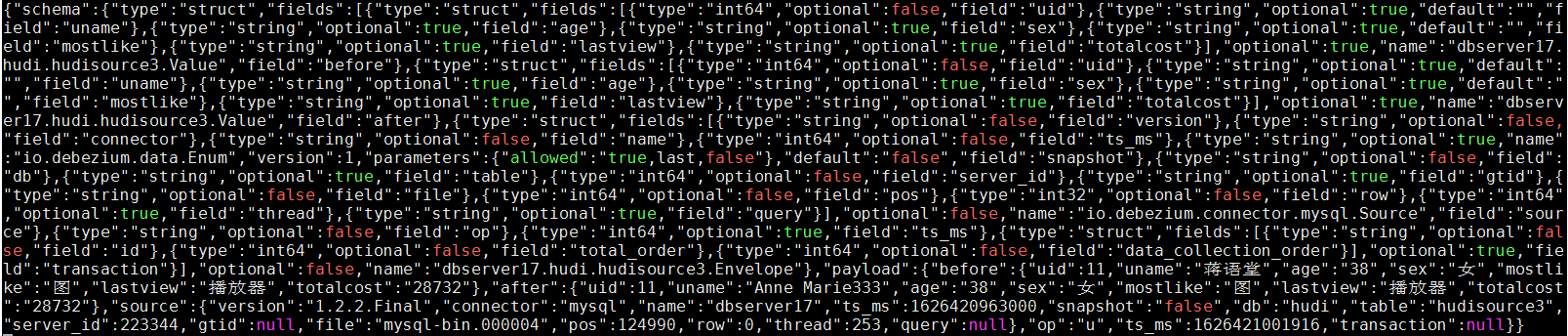
更改操作: UPDATE hudi.hudisource3 SET uname=‘Anne Marie333’ WHERE uid=11;
對應kafka訊息體:
洗掉操作: delete from hudi.hudisource3 where uid=11;
對應kafka訊息體:
除錯步驟
華為云MRS Hudi樣例工程獲取
根據實際MRS版本登錄github獲取樣例代碼: https://github.com/huaweicloud/huaweicloud-mrs-example/tree/mrs-3.1.0
打開工程SparkOnHudiJavaExample
樣例代碼修改及介紹
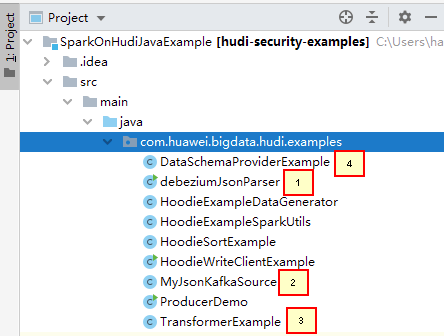
1.debeziumJsonParser
說明:對debezium的訊息體進行決議,獲取到op欄位,
原始碼如下:
package com.huawei.bigdata.hudi.examples;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.TypeReference;
public class debeziumJsonParser {
public static String getOP(String message){
JSONObject json_obj = JSON.parseObject(message);
String op = json_obj.getJSONObject("payload").get("op").toString();
return op;
}
}
2.MyJsonKafkaSource
說明:DeltaStreamer默認使用org.apache.hudi.utilities.sources.JsonKafkaSource消費kafka指定topic的資料,如果消費階段涉及資料的決議操作,則需要重寫MyJsonKafkaSource進行處理,
以下是原始碼,增加注釋
package com.huawei.bigdata.hudi.examples;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.parser.Feature;
import org.apache.hudi.common.config.TypedProperties;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamerMetrics;
import org.apache.hudi.utilities.schema.SchemaProvider;
import org.apache.hudi.utilities.sources.InputBatch;
import org.apache.hudi.utilities.sources.JsonSource;
import org.apache.hudi.utilities.sources.helpers.KafkaOffsetGen;
import org.apache.hudi.utilities.sources.helpers.KafkaOffsetGen.CheckpointUtils;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.apache.spark.streaming.kafka010.OffsetRange;
import java.util.Map;
/**
* Read json kafka data.
*/
public class MyJsonKafkaSource extends JsonSource {
private static final Logger LOG = LogManager.getLogger(MyJsonKafkaSource.class);
private final KafkaOffsetGen offsetGen;
private final HoodieDeltaStreamerMetrics metrics;
public MyJsonKafkaSource(TypedProperties properties, JavaSparkContext sparkContext, SparkSession sparkSession,
SchemaProvider schemaProvider) {
super(properties, sparkContext, sparkSession, schemaProvider);
HoodieWriteConfig.Builder builder = HoodieWriteConfig.newBuilder();
this.metrics = new HoodieDeltaStreamerMetrics(builder.withProperties(properties).build());
properties.put("key.deserializer", StringDeserializer.class);
properties.put("value.deserializer", StringDeserializer.class);
offsetGen = new KafkaOffsetGen(properties);
}
@Override
protected InputBatch<JavaRDD<String>> fetchNewData(Option<String> lastCheckpointStr, long sourceLimit) {
OffsetRange[] offsetRanges = offsetGen.getNextOffsetRanges(lastCheckpointStr, sourceLimit, metrics);
long totalNewMsgs = CheckpointUtils.totalNewMessages(offsetRanges);
LOG.info("About to read " + totalNewMsgs + " from Kafka for topic :" + offsetGen.getTopicName());
if (totalNewMsgs <= 0) {
return new InputBatch<>(Option.empty(), CheckpointUtils.offsetsToStr(offsetRanges));
}
JavaRDD<String> newDataRDD = toRDD(offsetRanges);
return new InputBatch<>(Option.of(newDataRDD), CheckpointUtils.offsetsToStr(offsetRanges));
}
private JavaRDD<String> toRDD(OffsetRange[] offsetRanges) {
return KafkaUtils.createRDD(this.sparkContext, this.offsetGen.getKafkaParams(), offsetRanges, LocationStrategies.PreferConsistent()).filter((x)->{
//過濾空行和臟資料
String msg = (String)x.value();
if (msg == null) {
return false;
}
try{
String op = debeziumJsonParser.getOP(msg);
}catch (Exception e){
return false;
}
return true;
}).map((x) -> {
//將debezium接進來的資料決議寫進map,在回傳map的tostring, 這樣結構改動最小
String msg = (String)x.value();
String op = debeziumJsonParser.getOP(msg);
JSONObject json_obj = JSON.parseObject(msg, Feature.OrderedField);
Boolean is_delete = false;
String out_str = "";
Object out_obj = new Object();
if(op.equals("c")){
out_obj = json_obj.getJSONObject("payload").get("after");
}
else if(op.equals("u")){
out_obj = json_obj.getJSONObject("payload").get("after");
}
else {
is_delete = true;
out_obj = json_obj.getJSONObject("payload").get("before");
}
Map out_map = (Map)out_obj;
out_map.put("_hoodie_is_deleted",is_delete);
out_map.put("op",op);
return out_map.toString();
});
}
}
3.TransformerExample
說明: 入湖hudi表或者hive表時候需要指定的欄位
以下是原始碼,增加注釋
package com.huawei.bigdata.hudi.examples;
import org.apache.hudi.common.config.TypedProperties;
import org.apache.hudi.utilities.transform.Transformer;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
/**
* 功能描述
* 對獲取的資料進行format
*/
public class TransformerExample implements Transformer, Serializable {
/**
* format data
*
* @param JavaSparkContext jsc
* @param SparkSession sparkSession
* @param Dataset<Row> rowDataset
* @param TypedProperties properties
* @return Dataset<Row>
*/
@Override
public Dataset<Row> apply(JavaSparkContext jsc, SparkSession sparkSession, Dataset<Row> rowDataset,
TypedProperties properties) {
JavaRDD<Row> rowJavaRdd = rowDataset.toJavaRDD();
List<Row> rowList = new ArrayList<>();
for (Row row : rowJavaRdd.collect()) {
Row one_row = buildRow(row);
rowList.add(one_row);
}
JavaRDD<Row> stringJavaRdd = jsc.parallelize(rowList);
List<StructField> fields = new ArrayList<>();
builFields(fields);
StructType schema = DataTypes.createStructType(fields);
Dataset<Row> dataFrame = sparkSession.createDataFrame(stringJavaRdd, schema);
return dataFrame;
}
private void builFields(List<StructField> fields) {
fields.add(DataTypes.createStructField("uid", DataTypes.IntegerType, true));
fields.add(DataTypes.createStructField("uname", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("age", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("sex", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("mostlike", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("lastview", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("totalcost", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("_hoodie_is_deleted", DataTypes.BooleanType, true));
fields.add(DataTypes.createStructField("op", DataTypes.StringType, true));
}
private Row buildRow(Row row) {
Integer uid = row.getInt(0);
String uname = row.getString(1);
String age = row.getString(2);
String sex = row.getString(3);
String mostlike = row.getString(4);
String lastview = row.getString(5);
String totalcost = row.getString(6);
Boolean _hoodie_is_deleted = row.getBoolean(7);
String op = row.getString(8);
Row returnRow = RowFactory.create(uid, uname, age, sex, mostlike, lastview, totalcost, _hoodie_is_deleted, op);
return returnRow;
}
}
4.DataSchemaProviderExample
說明: 分別指定MyJsonKafkaSource回傳的資料格式為source schema,TransformerExample寫入的資料格式為target schema
以下是原始碼
package com.huawei.bigdata.hudi.examples;
import org.apache.avro.Schema;
import org.apache.hudi.common.config.TypedProperties;
import org.apache.hudi.utilities.schema.SchemaProvider;
import org.apache.spark.api.java.JavaSparkContext;
/**
* 功能描述
* 提供sorce和target的schema
*/
public class DataSchemaProviderExample extends SchemaProvider {
public DataSchemaProviderExample(TypedProperties props, JavaSparkContext jssc) {
super(props, jssc);
}
/**
* source schema
*
* @return Schema
*/
@Override
public Schema getSourceSchema() {
Schema avroSchema = new Schema.Parser().parse(
"{\"type\":\"record\",\"name\":\"hoodie_source\",\"fields\":[{\"name\":\"uid\",\"type\":\"int\"},{\"name\":\"uname\",\"type\":\"string\"},{\"name\":\"age\",\"type\":\"string\"},{\"name\":\"sex\",\"type\":\"string\"},{\"name\":\"mostlike\",\"type\":\"string\"},{\"name\":\"lastview\",\"type\":\"string\"},{\"name\":\"totalcost\",\"type\":\"string\"},{\"name\":\"_hoodie_is_deleted\",\"type\":\"boolean\"},{\"name\":\"op\",\"type\":\"string\"}]}");
return avroSchema;
}
/**
* target schema
*
* @return Schema
*/
@Override
public Schema getTargetSchema() {
Schema avroSchema = new Schema.Parser().parse(
"{\"type\":\"record\",\"name\":\"mytest_record\",\"namespace\":\"hoodie.mytest\",\"fields\":[{\"name\":\"uid\",\"type\":\"int\"},{\"name\":\"uname\",\"type\":\"string\"},{\"name\":\"age\",\"type\":\"string\"},{\"name\":\"sex\",\"type\":\"string\"},{\"name\":\"mostlike\",\"type\":\"string\"},{\"name\":\"lastview\",\"type\":\"string\"},{\"name\":\"totalcost\",\"type\":\"string\"},{\"name\":\"_hoodie_is_deleted\",\"type\":\"boolean\"},{\"name\":\"op\",\"type\":\"string\"}]}");
return avroSchema;
}
}
將工程打包(hudi-security-examples-0.7.0.jar)以及json決議包(fastjson-1.2.4.jar)上傳至MRS客戶端
DeltaStreamer啟動命令
登錄客戶端執行一下命令獲取環境變數以及認證
source /opt/hadoopclient/bigdata_env
kinit developuser
source /opt/hadoopclient/Hudi/component_env
DeltaStreamer啟動命令如下:
spark-submit --master yarn-client \
--jars /opt/hudi-demo2/fastjson-1.2.4.jar,/opt/hudi-demo2/hudi-security-examples-0.7.0.jar \
--driver-class-path /opt/hadoopclient/Hudi/hudi/conf:/opt/hadoopclient/Hudi/hudi/lib/*:/opt/hadoopclient/Spark2x/spark/jars/*:/opt/hudi-demo2/hudi-security-examples-0.7.0.jar \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
spark-internal --props file:///opt/hudi-demo2/kafka-source.properties \
--target-base-path /tmp/huditest/delta_demo2 \
--table-type COPY_ON_WRITE \
--target-table delta_demo2 \
--source-ordering-field uid \
--source-class com.huawei.bigdata.hudi.examples.MyJsonKafkaSource \
--schemaprovider-class com.huawei.bigdata.hudi.examples.DataSchemaProviderExample \
--transformer-class com.huawei.bigdata.hudi.examples.TransformerExample \
--enable-hive-sync --continuous
kafka.properties配置
// hudi配置
hoodie.datasource.write.recordkey.field=uid
hoodie.datasource.write.partitionpath.field=
hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.NonpartitionedKeyGenerator
hoodie.datasource.write.hive_style_partitioning=true
hoodie.delete.shuffle.parallelism=10
hoodie.upsert.shuffle.parallelism=10
hoodie.bulkinsert.shuffle.parallelism=10
hoodie.insert.shuffle.parallelism=10
hoodie.finalize.write.parallelism=10
hoodie.cleaner.parallelism=10
hoodie.datasource.write.precombine.field=uid
hoodie.base.path = /tmp/huditest/delta_demo2
hoodie.timeline.layout.version = 1
// hive config
hoodie.datasource.hive_sync.table=delta_demo2
hoodie.datasource.hive_sync.partition_fields=
hoodie.datasource.hive_sync.assume_date_partitioning=false
hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.NonPartitionedExtractor
hoodie.datasource.hive_sync.use_jdbc=false
// Kafka Source topic
hoodie.deltastreamer.source.kafka.topic=hudisource
// checkpoint
hoodie.deltastreamer.checkpoint.provider.path=hdfs://hacluster/tmp/delta_demo2/checkpoint/
// Kafka props
bootstrap.servers=172.16.9.117:21005
auto.offset.reset=earliest
group.id=a5
offset.rang.limit=10000
注意:kafka服務端配置 allow.everyone.if.no.acl.found 為true
使用Spark查詢
spark-shell --master yarn
val roViewDF = spark.read.format("org.apache.hudi").load("/tmp/huditest/delta_demo2/*")
roViewDF.createOrReplaceTempView("hudi_ro_table")
spark.sql("select * from hudi_ro_table").show()
Mysql增加操作對應spark中hudi表查詢結果:

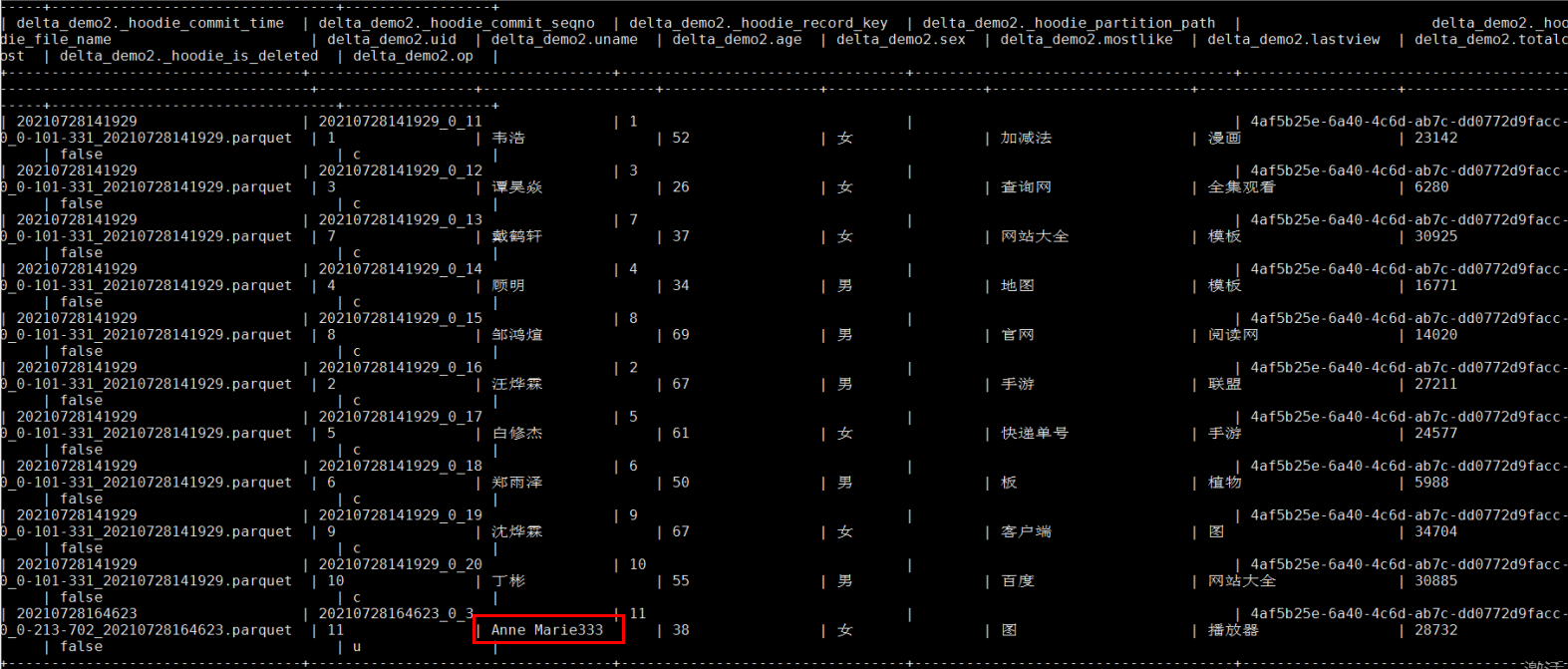
Mysql更新操作對應spark中hudi表查詢結果:

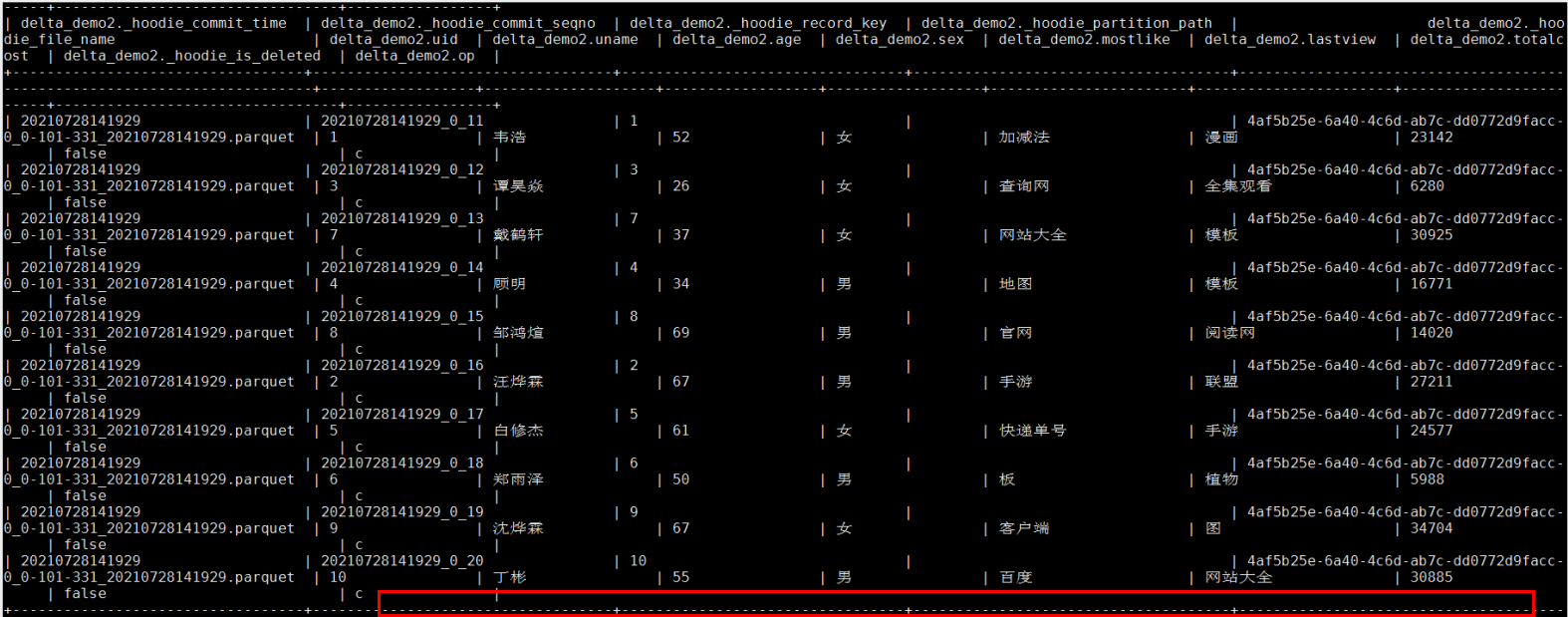
洗掉操作:

使用Hive查詢
beeline
select * from delta_demo2;
Mysql增加操作對應hive表中查詢結果:
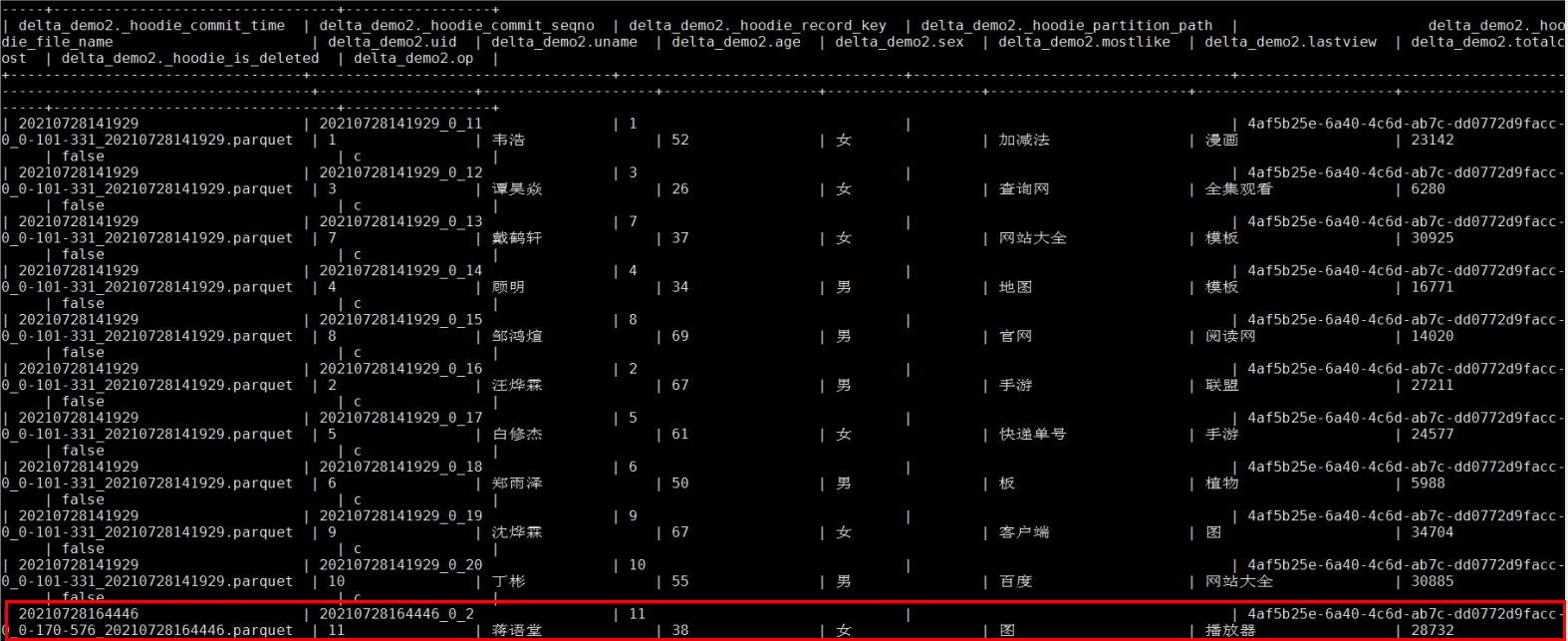
Mysql更新操作對應hive表中查詢結果:
Mysql洗掉操作對應hive表中查詢結果:
本文由華為云發布,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/449727.html
標籤:其他