蘇斌,華為云資料庫資深架構師,擁有16年資料庫內核研發經驗,之前作為MySQL官方InnoDB團隊主要研發人員,參與和主導了多個重要特性的開發和發布,目前在華為公司負責和參與華為云RDS主要產品RDS for MySQL和GaussDB(for MySQL)內核功能的設計和研發,云服務環境下,如何解決客戶基于大量資料創建索引的性能問題,成為云服務廠商的一個挑戰,華為云GaussDB(for MySQL)通過引入并行創建索引技術,很好地解決了批量索引創建和臨時添加索引等性能瓶頸問題,幫助用戶更快建立好索引,想要進一步了解快速創建索引的秘訣,請不要錯過本文,
關于MySQL索引
我們都知道,資料庫使用索引技術加快資料的查詢,MySQL資料庫也支持若干種索引結構提高查詢的性能(詳情請參見MySQL官網官方檔案),其中使用最廣泛的是B+tree索引,因為B+tree索引在查詢和修改的性能之間有很好的平衡,同時其存盤和維護的代價也是比較優的,MySQL的表本身由聚簇索引(必須是B+tree索引)表示,再加上若干個二級索引,包括B+tree索引,共同組成一個MySQL的獨立表,可以說MySQL的表是由一組索引共同組成的,我們都知道索引是一把雙刃劍,充分的索引可以更好地提升可以適配的查詢的性能,但是需要維護這些索引使得其和資料同步,所以在資料修改操作階段,更多的索引也會帶來更高的開銷,索引創建與否的權衡通常是動態的,用戶不一定能做到在表定義之初就知道需要建立哪些索引,需要隨著業務的發展變化而調整索引,這也帶來了動態索引創建的一些問題,
MySQL的索引創建邏輯
我們先看一下MySQL索引創建的邏輯,首先,MySQL索引的創建可以使用兩種不同的DDL(Data Definition Language: 資料定義語言)演算法來實作,第一種是COPY演算法,它非常低效,就是在兩個表之間進行資料拷貝,來完成表結構相關的修改,尤其是它要求加表鎖,現在基本不使用了,第二種是INPLACE演算法,該演算法不要求加鎖,因此很多DDL操作是不阻塞DML(Data Manipulation Language: 資料操縱陳述句)操作的,比如創建索引,該演算法具體的實作在存盤引擎層面完成,可以進行更多的優化,實際上DDL陳述句還有一種INSTANT演算法,但是它無法支持創建索引操作,這里不展開介紹,對于INPLACE演算法,在5.7版本之前,是采用索引記錄不斷地向建好的空索引插入的方式,由于插入的資料的無序性,該方法導致了明顯的性能問題和潛在的空間浪費,在5.7版本以后,MySQL優化了建索引步驟,將其改進為對已排序的索引記錄進行自底向上批量插入并且緊湊拼裝的創建方式,如果有多個索引要創建,會單獨對每個索引執行相同的演算法,新的演算法會經歷讀取資料、排序資料和創建索引這幾個主要步驟,總體而言,創建索引這類DDL操作,會比普通的DML等操作要費時,而該類DDL耗時會導致用戶在繼續動態添加索引加速查詢的時候,需要等待很長的時間,極大影響業務;而且用戶的MySQL實體開啟了Binlog復制,耗時的DDL操作容易引起備庫的長時間落后,
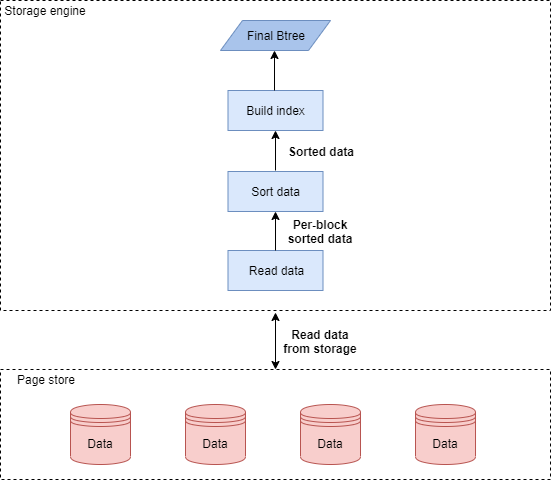
MySQL的創建索引流程圖
云化場景下索引創建的問題
隨著越來越多用戶把資料托管在云服務上,以及用戶資料量的不斷增長,前述的動態添加索引導致的問題非常影響用戶體驗,同時客戶的單表資料逐漸達到幾TB甚至幾十TB,客戶對創建索引太慢所帶來的性能問題的抱怨越來越多,尤其是創建索引周期如果太長,我們可能很難找到一段合適的業務低峰期來動態創建索引,避免業務的波動,因此,如何在云服務環境下,解決客戶基于大量資料創建索引的性能問題,成為云服務廠商的一個挑戰,
在云化場景下,還有一個主要場景對客戶的體驗非常重要,我們知道客戶的業務要遷移上云,需要對資料進行大規模的遷移(華為云提供了資料復制服務DRS工具支持各類資料遷移場景),資料遷移比較高效的方式為:
- 邏輯匯出源端資料
- 在目標端建表(注意,表不含二級索引)
- 將源端匯出的資料插入到目標端
- 對目標端的表建立二級索引
如果涉及動態資料同步,相關步驟會更復雜一些,由于和該主題無關,這里不展開,以上步驟中,需要重點注意的是步驟2和4,在目標端創建表的時候先不創建二級索引,這個優化對性能影響很大,尤其是一個表有很多二級索引的場景,我們知道B+tree索引的插入如果是有序的,對插入性能和結果的空間利用率是最好的,因為B+tree索引的分裂會在插入區域的尾部產生,同時由于分裂演算法的優化,分裂產生的頁面填充率會比較高;相反地,如果是隨機插入,尤其是并發地隨機插入,很容易導致B+tree索引在不同的節點進行分裂,并且分裂后的頁面填充率都處于一個半滿的狀態,導致B+tree最終的一個膨脹,
有了這個背景之后,我們就容易理解上面的問題,插入表資料的時候,我們屏蔽了二級索引,等所有資料都準備好了,再采用批量建立索引的方式創建二級索引,這對于二級索引創建效率是最高的,如果不這么做,每插入一條記錄,就要去插入相應的二級索引,那么二級索引就是一個無序的隨機插入,并發起來性能會變差很多,雖然在資料同步準備好后,批量創建二級索引是一個有效的方案,但是如果資料量很大,這么創建二級索引還是非常耗時,導致客戶在資料遷移完之后需要等待很長時間才能開展業務,這個等待周期可能是小時甚至天級別的,雖然可以考慮表級別的并發創建索引,但是這個方法也有明顯的缺點:應用場景有限,要求有多表;以及表和表之間的并發其實不是一個最有效的并發形式,相互影響比較大,
GaussDB(for MySQL)****如何快速創建索引?
綜上所述,在創建索引這個點上存在兩個性能瓶頸點:一個是用戶遷移資料之后的批量索引創建;第二個是用戶臨時需要添加一個二級索引,無論哪個點,我們都需要更快的建立好索引,提升用戶的使用體驗,
華為云GaussDB(for MySQL)引入了并行創建索引的技術,它改進了社區版MySQL創建索引只用單執行緒的問題,以此提高創建索引的效率,并一起解決了前述兩個痛點,前面提到的社區版創建索引邏輯是單執行緒的,首先存在資源利用率不夠飽滿的問題;其次創建索引程序是CPU和IO開銷交替進行的程序,在做一個操作的時候,即使不是資源競爭的操作也只有等待,多執行緒創建索引可以充分利用CPU和IO資源,同時有的執行緒在做CPU計算時,別的執行緒可以并發的做IO操作,
GaussDB(for MySQL)使用的并行創建索引,是一個全鏈路的并行技術,前面提到,創建索引包含了若干個階段,我們的并行創建演算法,對這里的每個階段都做并行處理,從讀取資料、排序、到創建索引,都是并行操作,每一步都由指定的N個執行緒并發處理,它的邏輯如下圖所示:
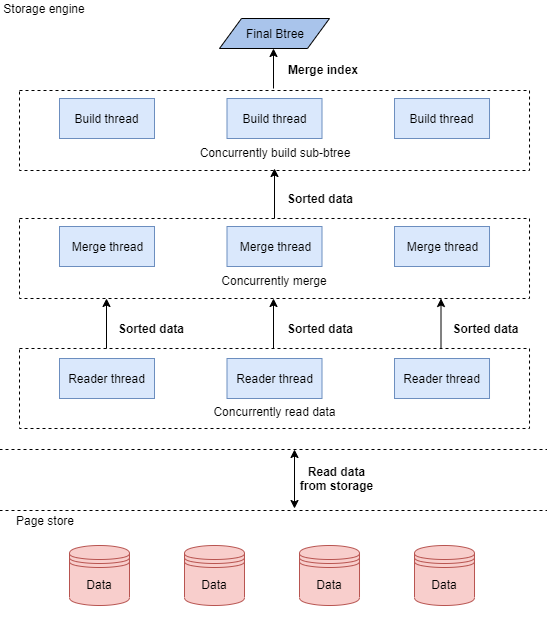
GaussDB(for MySQL)尤其對資料的歸并排序做了多種優化,使得我們常規的歸并排序能夠充分的并行,充分利用CPU、記憶體和IO的資源,在并行創建索引之后的合并步驟,也使用了一套簡化的演算法,正確處理各種索引結構的場景,
支持的索引和場景
GaussDB(for MySQL)的并行創建索引功能,目前支持的索引為B+tree二級索引,對于VIRTUAL index二級索引,將會在不久的將來提供全面的支持,而MySQL的SPATIAL index和FULLTEXT index不在該并行創建索引覆寫范圍內,
特別要注意的是,主鍵索引的創建目前也是不支持并行的,因此如果一個并行創建索引的SQL陳述句包含創建主鍵索引,或者前面提及的SPATIAL index與FULLTEXT index,那么客戶端將會收到一個告警,提示該操作不支持并行創建索引,同時該陳述句會采用單執行緒創建索引的方式執行完成,
從SQL陳述句的角度,如前所述,創建索引可以采用不同的演算法,由于COPY演算法(ALGORITHM=COPY)不是采用批量插入的方式,因此不會受益于該并行創建索引優化,而對于INPLACE演算法,如果創建索參考的是非rebuild的方式,都可以受益于該優化;一旦需要使用rebuild的方式創建索引,因為涉及到主鍵索引的建立,將無法使用并行創建索引的演算法,
示例
下面我們通過幾個實體來了解一下如何使用并行創建索引演算法加快創建速度,以及我們的條件約束是如何生效的,
-
我們使用sysbench的表,表內有1億條資料
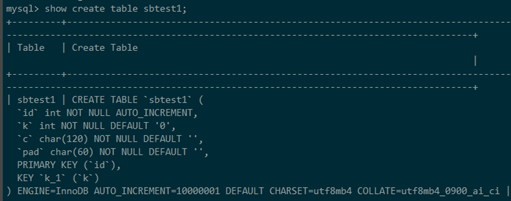
-
在該表的k欄位建索引,采用社區默認單執行緒,耗時146.82s

-
通過設定innodb_rds_parallel_index_creation_threads= 4啟用4個執行緒建索引,可以看到建索引耗時38.72s,速度提升3.79倍,
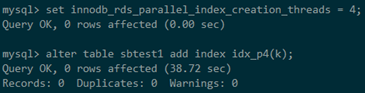
-
假設我們要修改主鍵索引,雖然指定了多執行緒,但是會收到一個warning,實際上只能通過單執行緒建索引
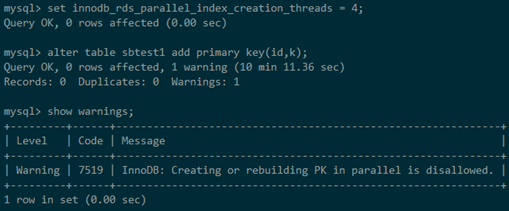
注意事項
首先對innodb_rds_parallel_index_creation_threads這個引數進行一下說明,它控制了系統中所有并行DDL可以使用的總執行緒數,取值范圍是[1-128],該引數取值為1表示使用原始的單執行緒創建索引,取值為N,表示接下來的DDL使用N個執行緒創建,如果一個DDL使用了100個執行緒在執行,那么另外一個也要使用并行的DDL且最多只能使用剩下的28個執行緒;而如果128個執行緒都被并行DDL陳述句占用了,新來的DDL只能走原始的單執行緒創建的邏輯,
雖然該并行創建索引加快了索引的創建速度,但是在具體使用場景下,還是需要有審慎的評估,我們知道在并行演算法應用之后,該DDL對硬體資源的使用會盡可能的充分,這也意味著其它操作就得不到太多的資源了,因此,針對不同的場景需要具體地分析,它決定了我們如何創建索引,
對于遷移場景,由于這時候還沒有任何業務接入,用戶希望盡快完成所有索引的創建,因此可以盡量設定多執行緒數,比如我們是16核規格的實體,那么我們就可以把并行執行緒的數量指定為16,加速完成操作,
如果是用戶業務運行階段要創建索引,我們還是不希望DDL操作,對正在運行的業務如DML操作等有太多的影響,因此,這時候創建索引可以指定相對少一些的執行緒數量,比如2-4(或者根據CPU規格以及負載決定,同時不鼓勵并發地執行多個DDL操作),這樣既能相對地加速創建索引的行程,也能保證DML的正常進行,
綜上所述,GaussDB(for MySQL)支持了并行創建索引,通過縮短創建索引使用的時間,很好地解決了客戶關切的兩類問題,提升了客戶的體驗,但技術無止境,在創建索引領域,還有其它的問題需要我們優化解決,例如如何減少創建索引步驟對IO的影響等等,我們后續會針對這些點進行優化,給客戶帶來更多的驚喜,
本文由華為云發布,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/449775.html
標籤:其他
上一篇:fabric2.2.網路部署
下一篇:【演算法】偽代碼書寫規則