目錄
- 1 統計學習
- 2 監督學習
- 2.1 基本概念
- 2.2 問題的形式化
- 3 統計學習三要素
- 3.1 模型
- 3.2 策略
- 3.3 演算法
- 4 模型評估于模型選擇
- 4.1 訓練誤差與測驗誤差
- 4.2 過擬合與模型選擇
- 5 正則化與交叉驗證——兩種常用的模型選擇方法
- 6 泛化能力
- 6.1 泛化誤差
- 6.2 泛化誤差上界
- 7 生成模型與判別模型
- 8 分類問題
- 9 標注問題
- 10 回歸問題
1 統計學習
統計學習是關于計算機基于資料構建概率統計模型并運用模型對資料進行預測與分析的一門學科,
統計學習由監督學習、非監督學習、半監督學習和強化學習組成,
本書主要討論監督學習,
統計學習方法的主要步驟:
(1)得到一個有限的訓練資料集合;
(2)確定包含所有可能的模型的假設空間,即學習模型的集合;
(3)確定模型選擇的準則,即學習的策略;
(4)實作求解最優模型的演算法,即學習的演算法;
(5)通過學習方法選擇最優模型;
(6)利用學習的最優模型對新資料進行預測或分析,
2 監督學習
2.1 基本概念
輸入空間與輸出空間:輸入與輸出的所有可能取值的集合,通常,輸出空間遠遠小于輸入空間,
每個具體的輸入是一個實體,通常由特征向量表示,
特征空間:所有特征向量存在的空間,
輸入、輸出變數習慣上用大寫字母 \(X\)、\(Y\) 表示,而變數所取的具體值習慣用小寫字母表示,如輸入實體 \(x\) 的特征向量記作$$x_i = (x^{(1)}, x^{(2)}, ..., x^{(i)}, ..., x^{(n)}) ^T$$ 其中 \(x^{(i)}\) 表示 \(x\) 的第 \(i\) 個特征,
要注意的是 \(x_i\) 表示輸入變數中的第 \(i\) 個,
訓練集常表示為
樣本 或 樣本點:測驗資料也由輸入和輸出對組成,輸入與輸出對稱作樣本或樣本點,
回歸問題:輸入變數與輸出變數均為連續變數的預測問題,
分類問題:輸出變數為有限個離散變數的預測問題,
標注問題:輸入變數與輸出變數均為變數序列的預測問題,
監督學習的目的在于學習一個由輸入到輸出的映射,這一映射由模型來表示,即學習的目的在于找到最好的這樣的模型,
假設空間:模型屬于由輸入空間到輸出空間的映射的集合,這個集合稱為假設空間,一般有無窮多個,
假設空間意味著學習范圍的確定,
例如,該映射集合是輸入變數的線性函式,那么模型的假設空間就是所有這些線性函式構成的函式集合,
2.2 問題的形式化
監督學習利用訓練資料集學習一個模型,再用模型對測驗樣本集進行預測,因為這個程序需要訓練資料集,而資料集往往是由人工給出的,所以稱作監督學習,監督學習分為學習和預測兩個程序,由學習系統和預測系統完成,如下圖,
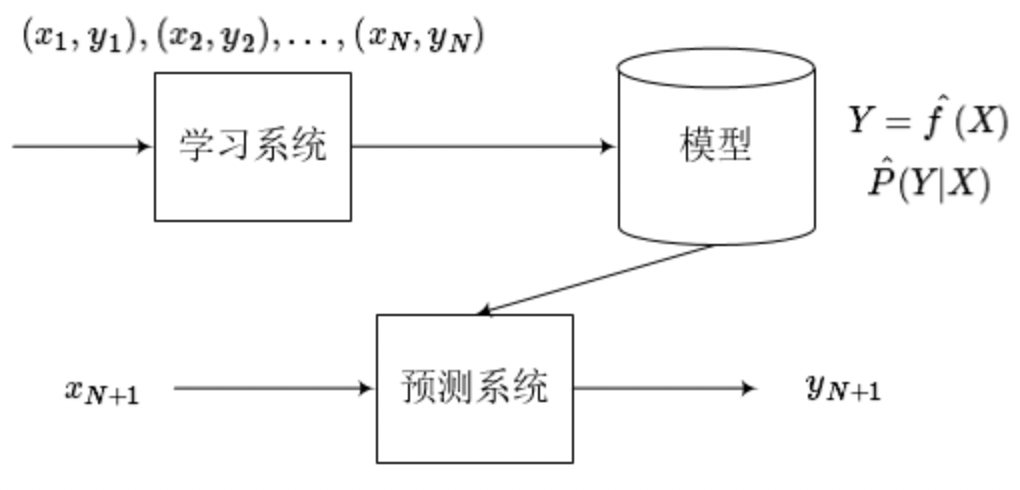 監督學習問題
監督學習問題
3 統計學習三要素
方法 = 模型 + 策略 + 演算法
3.1 模型
假設空間用 \(\mathcal F\) 表示, 假設空間可以定義為決策函式的集合
\[\mathcal{F} = \left\{f|Y = f(X) \right\} \]其中,\(X\) 和 \(Y\) 是定義在輸入空間 \(\mathcal X\) 和輸出空間 \(\mathcal Y\) 上的變數,這時 \(\mathcal F\) 通常是由一個引數向量決定的函式族:
\[\mathcal {F} = \left\{ f | Y = \mathcal f_\theta(X), \theta \in \mathbf R^n \right \} \]引數向量 \(\theta\) 取值于 \(n\) 維歐氏空間 \(\mathbf R^n\),稱為引數空間,
同樣,假設空間也可以定義為條件概率的集合
\[\mathcal{F} = \left\{ P|P(Y|X)\right\} \]其中,\(X\) 和 \(Y\) 是定義在輸入空間 \(\mathcal X\) 和輸出空間 \(\mathcal Y\) 上的隨機變數,這時 \(\mathcal F\) 通常是由一個引數向量決定的條件概率分布族:
\[\mathcal {F} = \left\{P|P_{\theta}(Y|X), \theta \in \mathbf R^n\right\} \]引數向量 \(\theta\) 取值于 \(n\) 維歐式空間 \(\mathbf R^n\),也稱為引數空間,
書中將決策函式表示的模型為非概率模型,由條件概率表示的模型為概率模型,
3.2 策略
按照什么樣的準則學習或選擇最優的模型?
首先引入損失函式與風險函式的概念,
損失函式,也叫代價函式:度量模型一次預測的好壞,描述錯誤的程度,它是非負實值函式,記作 \(L(Y, f(X))\),
風險函式,也叫期望損失、期望風險:度量平均意義下模型預測的好壞,記作
常用的損失函式有:
(1) 0-1 損失函式
(2) 平方損失函式
\[L(Y, f(X)) = (Y - f(X))^2 \](3)絕對損失函式
\[L(Y, f(X)) = |Y - f(X)| \](4)對數損失函式,或稱,對數似然損失函式
\[L(Y, P(Y|X)) = -logP(Y|X) \]損失函式越小,模型就越好,
學習的目標就是選擇期望風險最小的模型,
給定一個訓練資料集
\[T = \left\{(x_1, y_1), (x_2, y_2), ..., (x_N, y_N) \right\} \]經驗風險,也叫經驗損失:模型 \(f(X)\) 關于訓練資料集的平均損失,記作 \(R_{emp}\):
期望風險\(R_{exp}(f)\) :是模型關于聯合分布的期望損失,(理論)
經驗風險\(R_{emp}(f)\) :是模型關于訓練樣本集的平均損失,(現實)
根據大數定律,當樣本容量 \(N\) 趨于無窮時,經驗風險 \(R_{emp}(f)\) 趨于期望風險 \(R_{exp}(f)\),
所以,自然便有一個想法,通過經驗風險去估計期望風險,但現實中樣本數量有限,估計的結果不是很理想,所以需要兩個基本策略:經驗風險最小化和結構風險最小化,
經驗風險最小化(ERM):該策略認為經驗風險最小的模型是最優的模型,也就是求解:
其中,\(\mathcal F\) 是假設空間,
當樣本容量足夠大時,經驗風險最小化效果較好,現實中也常用,比如,“極大似然估計”就是經驗風險最小化的一個例子,但是,樣本容量較小時,其效果未必很好,會產生“過擬合”現象,
當模型是條件概率分布,損失函式是對數損失函式時,經驗風險最小化就等價于極大似然估計,
結構風險:在經驗風險上加上表示模型復雜度的正則化項或罰項,在假設空間、損失函式、訓練資料集確定的情況下,結構風險的定義是:
其中,\(J(f)\) 為模型的復雜度,是定義在假設空間 \(\mathcal F\) 上的泛函,模型 \(f\) 越復雜,復雜度 \(J(f)\) 就越大,反之越簡單則越小,\(\lambda\geq0\) 是系數,用以權衡經驗風險和模型復雜度,
結構風險小,需要經驗風險和模型復雜度同時小,對訓練資料和未知的測驗資料都有較好的預測,比如,“貝葉斯估計”中的“最大后驗概率估計”就是結構風險最小化的一個例子,
當模型是條件概率分布,損失函式是對數損失函式,模型復雜度由模型的先驗概率表示時,結構風險最小化就等價于最大后驗概率估計,
結構風險最小化(SRM):它是為了防止過擬合而提出來的策略,等價于“正則化”,該策略認為結構風險最小的模型是最優的模型,也就是求解:(該公式和下面 4.3 提及的正則化公式一樣)
綜上,監督學習問題就變成了經驗風隙訓結構風險函式的最優化問題,這時經驗或結構風險函式是最優化的目標函式,
3.3 演算法
演算法是指學習模型的具體計算方法,從假設空間中選擇最優模型,最后需要考慮用什么樣的計算方法求解最優模型,在不存在決議解的情況下,通過演算法,來保證找到全域最優解,并且使求解程序非常高效,
總之,統計學習方法之間的不同也就這三要素的不同,三要素確定了,統計學習方法就確定了,
4 模型評估于模型選擇
4.1 訓練誤差與測驗誤差
當損失函式給定時,基于損失函式的模型的訓練誤差和模型的測驗誤差就成為了學習方法評估的標準,
注意,統計學習方法具體的損失函式未必是評估時使用的損失函式,當然,二者一致是比較理想的,
假設學習到的模型是 \(Y = \hat{f}(X)\)
訓練誤差:表示的是模型 \(Y = \hat{f}(X)\) 關于訓練資料集的平均損失:
其中,\(N\) 是訓練樣本容量,
測驗誤差:表示的是模型 \(Y = \hat{f}(X)\) 關于測驗資料集的平均損失:
其中,\(N'\) 是測驗樣本容量,
特別地,當損失函式是0-1損失時,測驗誤差即為常見的測驗資料集上的誤差率:
\[e_{test} = \frac{1}{N'}\sum^{N'}_{i=1}I(y_i\neq \hat{f}(x_i)) \]其中,\(I\) 是指示函式,即 \(y \neq \hat{f}(x)\) 時為 \(1\),否則為 \(0\),
相應地,常見測驗資料集上的準確率為:
\[r_{test} = \frac{1}{N'}\sum^{N'}_{i=1}I(y_i= \hat{f}(x_i)) \]顯然,\(r_{test} + e_{test} = 1\),
通常將學習方法對未知資料的預測能力稱為泛化能力,
4.2 過擬合與模型選擇
過擬合:是指學習時選擇的模型所包含的引數過多,以至于出現該模型對已知資料預測得很好,但對未知資料預測得很差的現象,可以說,模型的選擇旨在避免過擬合并提高模型的預測能力,
 過擬合問題的例子
過擬合問題的例子
下圖描述了訓練誤差和測驗誤差與模型的復雜度之間的關系,
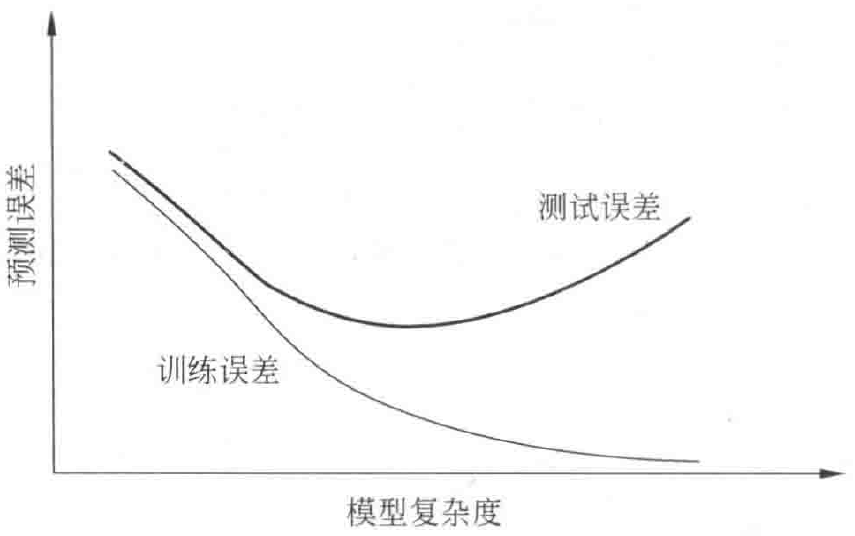 訓練誤差和測驗誤差與模型的復雜度之間的關系
訓練誤差和測驗誤差與模型的復雜度之間的關系
5 正則化與交叉驗證——兩種常用的模型選擇方法
正則化:用于解決過擬合現象,是結構風險最小化策略的實作,其作用是選擇經驗風險和模型復雜度同時較小的模型,
正則化一般有如下形式:
\[\mathop{min}\limits_{f \in \mathcal F} \frac{1}{N}\sum^N_{i=1}L(y_i, f(x_i))+\lambda J(f) \]其中,第一項是經驗風險,第二項是正則化項,\(\lambda \geq 0\) 為調整二者之間關系的系數,正則化項一般是模型復雜度的單調遞增函式,模型越復雜,正則化值就越大,
正則化項可以取不同的形式:
(1)在回歸問題中,損失函式是平方損失,正則化項可以是引數向量的 \(L_2\) 范數:
其中,\(\lVert\mathcal w\lVert\) 表示引數向量 \(\mathcal w\) 的 \(L_2\) 范數,(正則化項系數的 \(\frac{1}{2}\) 是為了方便求導約掉而存在的)
(2)正則化項也可以是引數向量的 \(L_1\) 范數:
其中,\(\lVert\mathcal w\lVert_1\) 表示引數向量 \(\mathcal w\) 的 \(L_1\) 范數,
除了正則化,還可以:
在給定樣本數充足的情況下,隨機將資料集分為三部分,訓練集、驗證集、測驗集,訓練集用于訓練模型,驗證集用于模型的選擇,測驗集用于最終對學習方法的評估,在學習到不同復雜度的模型中,選擇對驗證集有最小預測誤差的模型,但是,當資料不充足的情況下,可以采用交叉驗證,
交叉驗證:其基本思想是重復地使用資料;把給定的資料進行切分,將切分的資料集組合為訓練集和測驗集,在此基礎上反復訓練、測驗、模型選擇,
(1)簡單交叉驗證
隨機將資料分為兩部分,一部分作為訓練集,一部分作為測驗集(如,70%作為訓練,30%作為測驗),選出測驗誤差最小的模型,
(2)\(S\) 折交叉驗證
應用最廣泛的一種,首先隨機切分 \(S\) 個互不相交的大小相同的子集;然后利用 \(S-1\) 個子集的資料去訓練模型,利用余下的子集去測驗模型;這一程序可以有 \(S\) 種選擇來重復進行;最后選出 \(S\) 次測評中測驗誤差最小的模型,
(3)留一交叉驗證
\(S\) 折交叉驗證的特殊情形是 \(S=N\),往往在資料缺乏時采用,其中 \(N\) 是資料集的容量,
6 泛化能力
6.1 泛化誤差
泛化能力:是指由該方法學習到的模型對未知資料的預測能力,常常通過測驗誤差來評價學習方法的泛化能力,
泛化誤差:如果學習到的模型是 \(\hat f\),則用這個模型對未知資料預測的誤差為泛化誤差:
實際上,泛化誤差就是 \(\hat f\) 的期望風險,
6.2 泛化誤差上界
泛化誤差上界:學習方法的泛化能力分析往往是通過研究泛化誤差的概率上界進行的,簡稱為泛化誤差上界,
具體來說,就是通過比較兩種學習方法的泛化誤差上界,來比較它們的優劣,
性質:它是樣本容量的函式,容量增加,泛化上界趨于 \(0\);它是假設空間容量的函式,假設空間容量越大,模型就越難學,泛化誤差上界就越大,
定理:(泛化誤差上界)對二分類問題,當假設空間是有限個函式的集合 \(\mathcal F = \left\{f_1, f_2, ..., f_d \right\}\) 時,對任意一個函式 \(f \in \mathcal F\),至少以概率 \(1-\delta\),以下不等式成立:
\[R(f) \leq \hat R(f)+\varepsilon(d, N, \delta) \]其中,
\[\varepsilon(d, N, \delta) = \sqrt{\frac{1}{2N}(logd+log\frac{1}{\delta})} \]不等式左端 \(R(f)\) 是泛化誤差,有端則是泛化誤差上界,
在泛化誤差上界 \(\hat R(f)+\varepsilon(d, N, \delta)\) 中,第一項 \(\hat R(f)\) 是訓練誤差,訓練誤差越小,泛化誤差也就越小;第二項 \(\varepsilon(d, N, \delta)\) 是 \(N\) 的單調遞減函式,當 \(N\) 趨近于無窮時趨近于 \(0\);同時,它也是 \(\sqrt {logd}\) 階的函式,假設空間 \(\mathcal F\) 包含的越多,其值越大,
(證明程序,略)
7 生成模型與判別模型
監督學習方法也可以分為生成方法和判別方法,所學到的模型分別為生成模型和判別模型,
生成模型:生成方法由資料學習聯合概率分布 \(P(X, Y)\),然后求出條件概率分布 \(P(Y|X)\) 作為預測的模型,即生成模型:
比如:樸素貝葉斯法和隱馬爾可夫模型,
判別模型:判別方法由資料直接學習決策函式 \(f(X)\) 或者條件概率分布 \(P(Y|X)\) 作為預測的模型,即判別模型,
比如:\(k\) 近鄰法、感知機、決策樹、logsic回歸模型、最大熵模型、支持向量機、提升方法和條件隨機場等,
二者各有優劣,
8 分類問題
分類問題包括學習和分類兩個程序,程序與監督學習問題相似,
評價分類器性能的指標一般是分類準確率 (accuracy),
分類準確率 (accuracy):對于給定的測驗資料集,分類器正確分類的樣本數與總樣本數之比,也就是損失函式是0-1損失時測驗資料集上的準確率,
對于二分類問題常用的評價指標是精確率 (precision)和召回率 (recall),
可查看精確率和召回率?
通常以關注的類為正類,其他類為負類,分類器在測驗資料集上的預測或正確或錯誤,4種情況分別記作:
TP——將正類預測為正類數
FN——將正類預測為負類數
FP——將負類預測為正類數
TN——將負類預測為負類數
精確率 (precision):
召回率 (recall):
此外,還有 \(F_1\) 值,是精確值和召回率的回呼和均值,即
\[\frac{2}{F_1} = \frac{1}{P} + \frac{1}{R} \]\[F_1 = \frac{2TP}{2TP+FP+FN} \]精確率和召回率都高時,\(F_1\) 值也會高,
許多統計學習方法可以用于分類:\(k\) 近鄰法、感知機、樸素貝葉斯法、決策樹、決策串列、logsitc回歸模型、支持向量機、提升方法、貝葉斯網路、神經網路、Winnow等,
9 標注問題
標注問題的輸入是一個觀測序列,輸出則是一個標記序列或狀態序列,
標注問題的目的在于學習一個模型,使它能夠對觀測序列給出標記序列作為預測,
注意,可能的標記個數是有限的,但其組合所成的標記序列的個數是依序列長度呈指數級增長的,
標注問題包括學習和標注兩個程序,
10 回歸問題
回歸問題按照輸入變數的個數,分為一元回歸和多元回歸,線性回歸和非線性回歸,
回歸學習最常用的損失函式是平方損失函式,由此,回歸問題可由最小二乘法求解,
本文來自博客園,作者:by_yanxx,轉載請注明原文鏈接:https://www.cnblogs.com/powehi/p/16061427.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/449778.html
標籤:其他
下一篇:nmap使用指南