在搜索推薦中,通常使用相似Embedding進行推薦,此時就會有一個問題:如何快速找到與一個Embedding相近的其他Embedding
如果兩個Embedding在同一個向量空間中,我們就可以通過很多種方式(內積、余弦、歐氏距離等)計算其相似度;例如在推薦系統中,用戶和物品的Embedding都在同一個空間中,物品總數為\(n\),那么計算一個用戶和所以物品向量相似度的時間復雜度是\(O(n)\),而\(n\)通常都能達到百萬甚至上億,這樣的計算方式是無法接受的;
1 樸素方法
1.1 聚類
如果將相似點聚類在一起,在檢索相似向量的時候則可以快速縮小范圍,只計算目標Embedding所在的聚類范圍內的相似度,這里可以使用叫常見的[[K-means]]聚類方法;
但是這種方法在聚類的邊緣會出現些問題,如果只檢索類別內的向量,則可能遺漏在其他類別中的相近點;另外,對于K-means方法,K值得選擇也是一個問題,如果K選的太大,則迭代程序會很緩慢;K值選的太小,則搜索范圍無法有效降低;
- K值得選擇經驗:K=Embedding的維度開4次方根,調參按照2的整數次冪進行調整
1.2 索引
例如使用經典的[[Kd-tree]]向量空間索引演算法中,同樣存在邊緣點的問題,Kd-tree會找到最鄰近的區域,但是其他區域同樣存在可能的最近點;另外Kd-tree的索引結構較為復雜,導致離線和在線的維護也相對復雜;
2 區域敏感哈希基本原理
區域敏感哈希(Locality Sensitive Hashing, LSH)高效地解決了Embedding匹配的問題,
區域敏感哈希基本思想,是將相鄰的點落入同一個“桶”,這樣在進行最鄰近搜索時,僅需要在一個桶內或鄰近幾個桶內進行搜索,只需要保證每個桶內的元素個數保持在一個較小的范圍內;
如下圖所示例子,首先需要確定一個結論:在[[歐式空間]]中,將高位空間的點映射到低維空間,原本接近的點在低維空間中肯定依然接近,但原本遠離的點則有一定概率變成接近的點,
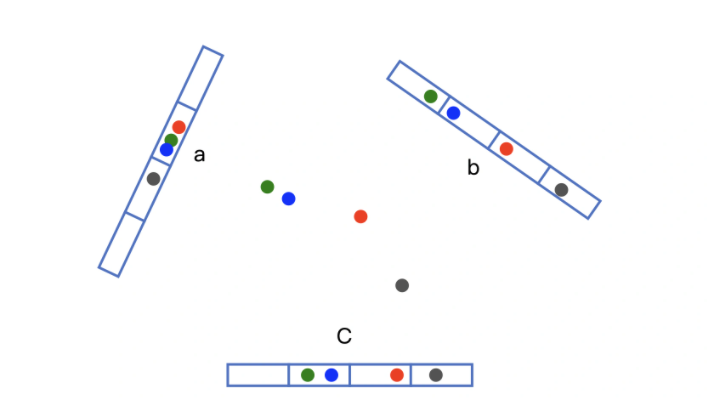
利用上面的低維空間保留高位空間相近距離關系的性質,我們可以設計構造多個“桶”,假設\(v\)是高位空間中的\(k\)維Embedding向量,\(x\)是隨機生成的\(k\)維向量,可以得到一個數值\(h(v) = v \cdot x\),
根據這個數值,我們設計哈希函式\(h(v)\)進行分桶:
\[h^{x,b}(v)=\lfloor\frac{x\cdot v+b}{w}\rfloor \]上面公式中\(w\)是分桶寬度,\(b\)是0到\(w\)之間的一個均勻分布隨機變數,其作用是避免分桶邊界固化,為了避免映射操作損失資訊,可以使用\(m\)個哈希函式進行分桶,如果同時掉入多個桶,則其相似的概率將會增加,在確定了桶后,就在其有限的集合內進行[[K近鄰]]搜索即可,
3 多桶策略
當存在多個哈希函式的時候,聚合中的點可能以不同的分布方式落在多個桶當中,最簡單的就是一個點在匹配的桶中都出現(AND)以及在任意一個桶中出現(OR)兩種策略,多桶策略還可以更復雜,比如三個分桶,可以選擇同時落入兩個桶中的點作為候選點,下面有一些建議的策略:
- 點數越多,越應該增加每個分桶函式中桶的個數;點數越少,越應該減少桶的個數;
- Embedding的維度越高,越應該增加分桶哈希函式的數量,并使用且的方式作為多桶策略;若Embedding維度低,則可以少用哈希函式,并用或的方式作為分桶策略;
4 存盤部署思路
例如在商品推薦系統中,商品稱為(item)有對應的item_id,可以使用以下方案:
- 存盤 item_id: BucketId
- 存盤 BucketId: item_id
在召回的時候,先使用目標item_id找到對應的BucketId,然后再通過BucketId桶中的商品,實際上就是建立[[倒排索引]]的思路,
5 總結
LSH相比一些樸素的方法,高效地解決了相似向量查找的問題,通過多桶機制減小其哈希分桶的損失;但是也存在一些問題,大資料量情況下哈希函式的個數不好確定,另外在進行哈希計算的時候,可能會存在哈希沖突,導致召回率降低,
此外向量相似查找,還有一些基于樹、基于量化、基于圖的方法,根據不同的場景也可一試,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/449781.html
標籤:其他