磁區
磁區概念
在邏輯上磁區表與未磁區表沒有區別,在物理上磁區表會將資料按照磁區鍵的列值存盤在表目錄的子目錄中,目錄名=“磁區鍵=鍵值”,其中需要注意的是磁區鍵的值不一定要基于表的某一列(欄位),它可以指定任意值,只要查詢的時候指定相應的磁區鍵來查詢即可,我們可以對磁區進行添加、洗掉、重命名、清空等操作,分為靜態磁區和動態磁區兩種,靜態磁區與動態磁區的主要區別在于靜態磁區是手動指定,而動態磁區是通過資料來進行判斷,詳細來說,靜態磁區的列實在編譯時期,通過用戶傳遞來決定的;動態磁區只有在 SQL 執行時才能決定,
磁區案例
Hive的磁區功能可以幫助用戶快速的查找和定位,這里我們給出了一個應用場景,通過使用Hive磁區功能創建日期和小時磁區,快速查找定位對應的用戶與IP地址,具體步驟如下:
步驟 1 創建一張磁區表,包含兩個磁區dt和ht分別表示日期和小時:
CREATE TABLE partition_table001 ( name STRING, ip STRING ) PARTITIONED BY (dt STRING, ht STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
步驟 2 啟用hive動態磁區時,需要設定如下兩個引數:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
步驟 3 把partition_table001表某個日期磁區下的資料(如下圖所示)load到目標表partition_table002中,

- 如果沒有目標表則創建目標表partition_table002:
CREATE TABLE IF NOT EXISTS partition_table002 LIKE partition_table001;

- 如果使用靜態磁區,必須指定磁區的值,如將partition_table001表中日期磁區為“20190520”、小時磁區為“00”的資料加載入表partition_table002中:
INSERT OVERWRITE TABLE partition_table002 PARTITION (dt='20190520', ht='00') SELECT name, ip FROM partition_table001 WHERE dt='20190520' and ht='00';
查詢一下表partition_table002中我們插入的資料,結果如下圖所示:

- 如果希望插入每天24小時的資料,則需要執行24次上面的陳述句,而使用動態磁區會根據select出的結果自動判斷資料該load到哪個磁區中去,只需要一句陳述句即可完成,命令及結果如下所示:
INSERT OVERWRITE TABLE partition_table002 PARTITION (dt, ht) SELECT * FROM partition_table001 WHERE dt='20190520';

步驟 4 查看表格partition_table002下的所有磁區資訊使用如下命令:
SHOW PARTITIONS partition_table002;
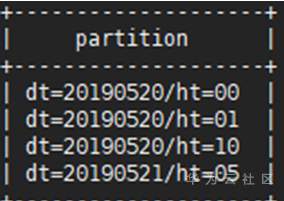
或者擁有admin權限的用戶使用dfs –ls <表存盤目錄>命令如下:
dfs -ls hdfs://hacluster/user/hive/warehouse/partition_table002;

說明:
靜態磁區和動態磁區可以混合使用,在動靜結合使用時需要注意靜態磁區值必須在動態磁區值的前面,在select中按位置順序出現在最后(因為靜態磁區提前產生,動態磁區運行時產生),如果動態磁區作為父路徑,則子靜態磁區無法提前生成,會報錯為動態磁區不能為靜態的父路徑,當靜態磁區是動態磁區的子磁區時,執行DML操作會報錯,因為磁區順序決定了HDFS中目錄的繼承關系,這點是無法改變的,
分桶
分桶概念
對于每一個表或者磁區, Hive可以進一步組織成桶,也就是說分桶是更為細粒度的資料范圍劃分,Hive會計算桶列的哈希值再以桶的個數取模來計算某條記錄屬于那個桶,把表(或者磁區)組織成桶(Bucket)有兩個理由:
-
獲得更高的查詢處理效率,桶為表加上了額外的結構,Hive在處理有些查詢時能利用這個結構,具體而言,連接兩個在(包含連接列的)相同列上劃分了桶的表,可以使用Map端連接(Map-side join)高效的實作,
-
使取樣(sampling)更高效,在處理大規模資料集時,在開發和修改查詢的階段,如果能在資料集的一小部分資料上試運行查詢,會帶來很多方便,
分桶案例
步驟 1 創建一張含有桶的表格,例如創建一個含有四個桶的表格bucketed_table:
CREATE TABLE bucketed_table (id INT, name STRING) CLUSTERED BY (id) INTO 4 BUCKETS;
**步驟 2 ** 設定hive.enforce.bucketing屬性為true,以便自動控制上reduce的數量從而適配bucket的個數,推薦命令如下(當然也可以手動設定引數“mapred.reduce.task”去適配bucket的個數,只是多次手動修改會比較麻煩):
set hive.enforce.bucketing = true;
步驟 3 向表里插入準備好的沒有劃分桶的資料,例如將沒有劃分桶的表users的資料插入目標表bucketed_table:
INSERT OVERWRITE TABLE bucketed_table SELECT * FROM users;
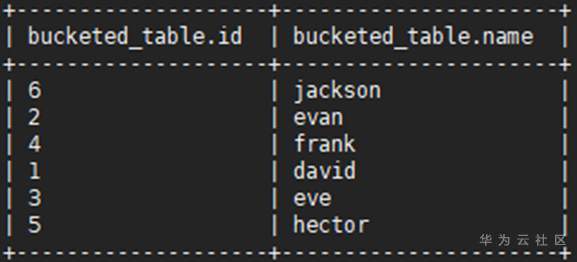
步驟 4 查看表格bucketed_table下的所有分桶資訊,需要擁有admin權限的用戶使用dfs –ls <表或磁區存盤目錄>命令如下:
dfs -ls hdfs://hacluster/user/hive/warehouse/bucketed_table;

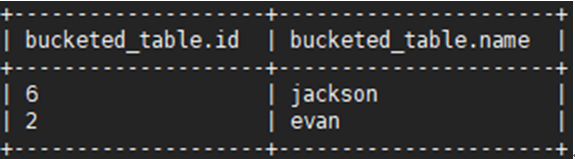
步驟 5 對桶中的資料進行采樣,使用抽樣命令TABLESAMPLE(BUCKET x OUT OF y),例如對表格bucketed_table從第一個桶開始抽取1個桶資料量的樣本:
SELECT * FROM bucketed_table TABLESAMPLE(BUCKET 1 OUT OF 4 ON id);
說明:
抽樣命令TABLESAMPLE(BUCKET x OUT OF y)中,y必須是表格中分桶數的倍數或者因子,Hive根據y的大小,決定抽樣的比例,x表示從哪個桶開始抽取,例如,表格的總分桶數為16,tablesample(bucket 3 out of 8),表示總共抽取(16/8=)2個bucket的資料,分別為第3個桶和第(3+8=)11個桶的資料,
本文由華為云發布,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/451285.html
標籤:其他
上一篇:【編程教室】PONG - 100行代碼寫一個彈球游戲
下一篇:【華為云會議開發指南】開發流程