前言
自然語言處理 ( Natural Language Processing, NLP) 是計算機科學領域與人工智能領域中的一個重要方向,它研究能實作人與計算機之間用自然語言進行有效通信的各種理論和方法,用于分析理解機器與人之間的互動,常用的領域有:物體識別、文本糾錯、情感分析、文本分類、關鍵詞提取、自動摘要提取等方面,
本文將從分詞、詞頻、詞向量等基礎領域開始講解自然語言處理的原理,講解 One-Hot、TF-IDF、PageRank 等演算法及 LDA、LDiA、LSA 等語意分析的原理,
介紹 Word2vec、GloVe、Embedding 等常用詞嵌入及 NLTK、Jieba 等分詞工具的應用,
目錄
一、自然語言處理的概念
二、分詞器的原理及應用
三、詞向量演算法原理
四、文本相似度分析
五、通過主題轉換進行語意分析
六、詞嵌入的應用
一、自然語言處理的概念
1.1 自然語言處理的起源
語言是人類社會發展程序的產物,是最能體現人類智慧和文明的證明,也是人類與動物最大的區別,它是一種人與人交流的載體,像計算機網路一樣,我們使用語言相互傳遞知識,在人類歷史的幾千年,語言不斷地繁衍發展,
在計算機興趣的近幾十年,科學界正在試圖不斷努力,把人類的語言演變成分析資料特征的依據,在1970年,有兩位美國人 Richard Bandler 和 John Grinder 因不滿于傳統心理學派的治療程序冗長,及其效果常反復不定,而集合各家所長以及他們獨特的創見,在美國加州大學內(NLP的發源地)利用課余時間開始研究,經過三年多的實驗與練習,終于逐漸形成NLP神經語法程式學的基礎架構,
隨著近年來人工智能的崛起,自然語言處理(NLP)更成為一種專業分析人類語言智能工具,被應用到了多個層面:
(1)機器翻譯
機器翻譯是利用計算機將某一種語言文本自動翻譯成另一種語言文本的方法,它基于語言規則,利用統計的統計原理進度混合計算,得出最終結果,最常見于百度翻譯、金山 iciba 翻譯、有道翻譯、google 翻譯等,
(2)自動問答
自動問答通過計算機對人提出的問題的理解,利用自動推理等手段,在有關知識資源中自動求解答案并做出相應的回答,它利用語詞提取、關鍵字分析、摘要分析等方式提取問題的核心主干,然后利用 NLP 分析資料選擇出最合適的答案,常見的例子有在線問答 ask.com、百度知道、yahoo 回答等,
(3)語音處理
語言處理(speech processing)可以把將輸入語音信號自動轉換成書面文字或計算機命令,然后對任務進行操作處理,常見的應用場景有汽車的語言識別、餐廳智能點餐、機場火車站的智能預訂航班、智能機器人等,
(4)情感分析
從大量檔案中檢索出用戶的情感方向,對商品評價、服務評價等的滿意進行分析,對用戶進行商品服務推薦,在京東、淘寶等各大的購物平臺很常用,
1.2 自然語言處理的階段
自然語言實作一般都通過以下幾個階段:文本讀取、分詞、清洗、標準化、特征提取、建模,首先通過文本、新聞資訊、網路爬蟲等渠道獲取大量的文字資訊,然后利用分詞工具對文本進行處理,把陳述句分成若干個常用的單詞、短語,由于各國的語言特征有所區別,所以NLP也會有不同的庫支撐,對分好的詞庫進行篩選,排除掉無用的符號、停用詞等,再對詞庫進行標準化處理,比如英文單詞的大小寫、過去式、進行式等都需要進行標準化轉換,然后進行特征提取,利用 tf-idf、word2vec 等工具包把資料轉換成詞向量,最后建模,利用機器學習、深度學習等成熟框架進行計算,
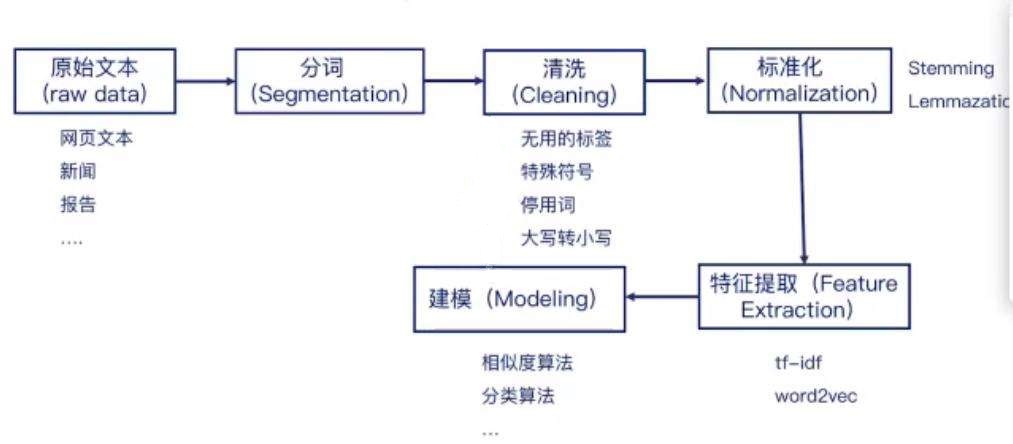
下面將對這幾個處理流程進行逐一介紹,
回到目錄
二、分詞器的原理及應用
|
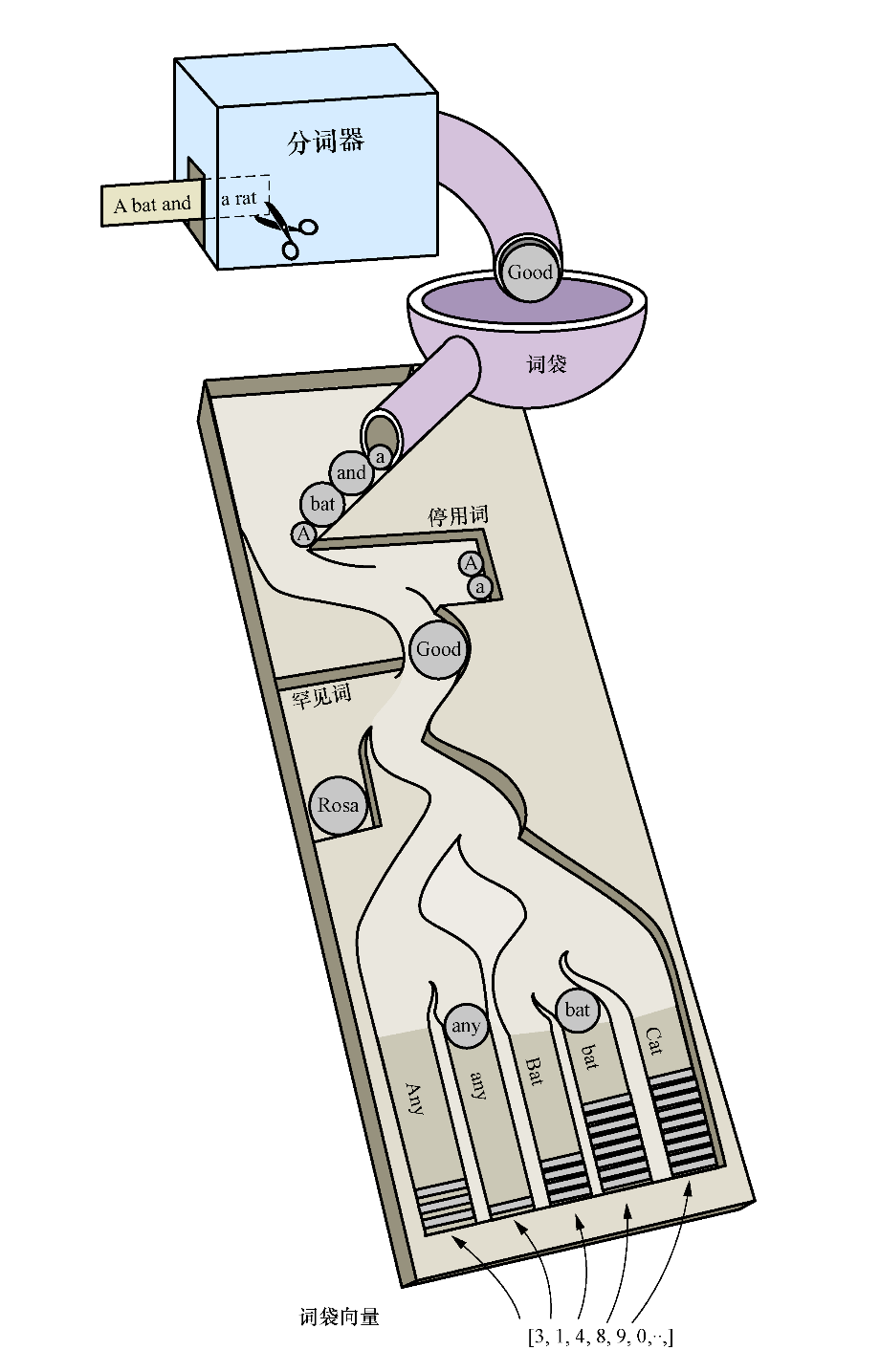
2.1 分詞器的基本原理 在自然語言處理的程序中,把切分檔案是流水線的第一步,它能夠把文本拆分為更小的文本塊或詞語片段多塊資訊,每塊資訊都可以被看成是一個元素,這此元素出現的頻率可以直接被看作為文本的向量, data='https://www.cnblogs.com/leslies2/archive/2022/03/28/NLP stands for Natural Language Processing.' data.split() 結果 ['NLP', 'stands', 'for', 'Natural', 'Language', 'Processing.'] 你可能已經看到,直接對陳述句進行拆分可以會把標點符號 ‘ . ’ 也帶進陣列,還有一些無用的運算子 ‘. ?!’ 等,最后勢必會影響輸出的結果,想要實作這類最簡單的資料清洗,可以使用正則運算式來解決, data='https://www.cnblogs.com/leslies2/archive/2022/03/28/NLP is the study of excellent communication–both with yourself, and with others.' data=https://www.cnblogs.com/leslies2/archive/2022/03/28/re.split(r'[-\s.?,!]',data) 當想去除一些無用的停用詞(例如 'a,A' )、對詞庫進行標準化處理(例如詞干還原,把進行式 building 轉化成 build,把過去式 began 轉化為 begin) 還有大小寫轉換時,可以使用成熟的庫來完成, 多國的語言都有差異,所以分詞器的處理方式也有區別,下面將介紹英語單詞與中文詞匯比較常用的分詞器 NLTK 和 Jieba , |
 |
2.2 NLTK 庫基礎功能介紹
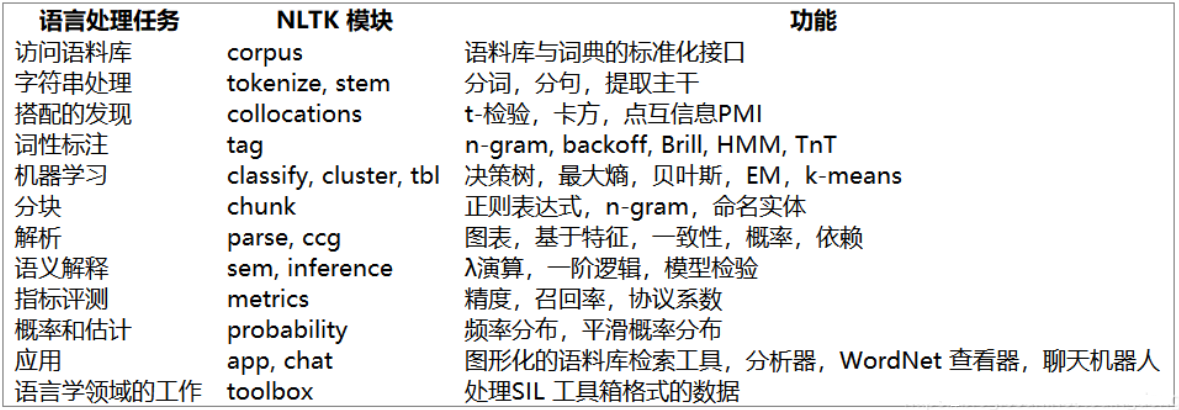
NLTK 使用 Python 程式撰寫,它提供了一套用于分類,標記化,詞干化,標記,決議和語意推理的文本處理庫,相關的模塊如下,
2.2.1 分句 SentencesSegment
例如有一段文本里面包含三個句子,希望把它分成一個一個的句子,此時可以使用NLTK中的 punktsentencesegmenter,
1 sent_tokenizer = nltk.data.load('tokenizers/punkt/english.pickle') 2 paragraph = "The first time I heard that song was in Hawaii on radio. ”+ 3 "I was just a kid, and loved it very much! What a fantastic song!" 4 sentences = sent_tokenizer.tokenize(paragraph) 5 print(sentences)
運行結果
['The first time I heard that song was in Hawaii on radio.',
'I was just a kid, and loved it very much!',
'What a fantastic song!']
2.2.2 分詞 WordPunctTokenizer
1 from nltk.tokenize import WordPunctTokenizer 2 sentence = "Are you old enough to remember Michael Jackson attending ”+ 3 “the Grammys with Brooke Shields and Webster sat on his lap during the show?" 4 words = WordPunctTokenizer().tokenize(sentence) 5 print(words)
運行結果
['Are', 'you', 'old', 'enough', 'to', 'remember', 'Michael', 'Jackson', 'attending',
'the', 'Grammys', 'with', 'Brooke', 'Shields', 'and', 'Webster', 'sat', 'on', 'his',
'lap', 'during', 'the', 'show', '?']
2.2.3 正則運算式 RegexpTokenizer
最簡單的方法去掉一些從檔案中存在的 \n \t 等符號
1 from nltk.tokenize import RegexpTokenizer 2 sentence='Thomas Jefferson began \n building \t Monticello at the age of 26.' 3 tokenizer=RegexpTokenizer(r'\w+|$[0-9.]+|\S+') 4 print(tokenizer.tokenize(sentence))
運行結果
['Thomas', 'Jefferson', 'began', 'building', 'Monticello', 'at', 'the', 'age', 'of', '26', '.']
2.2.4 分詞 TreebankWordTokenizer
TreebankWordTokenizer 擁有比 WordPunctTokenizer 更強大的分詞功能,它可以把 don't 等縮寫詞分為[ "do" , " n't " ]
1 from nltk.tokenize import TreebankWordTokenizer 2 sentence="Sorry! I don't know." 3 tokenizer=TreebankWordTokenizer() 4 print(tokenizer.tokenize(sentence))
運行結果
['Sorry', '!', 'I', 'do', "n't", 'know', '.']
2.2.5 詞匯統一化
2.2.5.1 轉換大小寫
詞匯統一化最常用的就是把大小進行統一化處理,因為很多搜索工具包都會把大小寫的詞匯例如 City 和 city 視為不同的兩個詞,所以在處理詞匯時需要進行大小寫轉換,當中最簡單直接的方法就是直接使用 str.lower() 方法,
2.2.5.2 詞干還原
當單詞中存在復數,過去式,進行式的時候,其詞干其實是一樣的,例如 gave , giving 詞干都是 give ,相同的詞干其實當中的意思是很接近的,通過詞干還原可以壓縮單詞的資料,減少系統的消耗,NLTK 中提供了 3 個常用的詞干還原工具:porter、lancaster、snowball ,其使用方法相類似,下面用 porter 作為例子,可以 playing boys grounded 都被完美地還原,但對 this table 等單詞也會產生歧義,這是因為被原后的單詞不一定合法的單詞,
1 from nltk.stem import porter as pt 2 3 words = [ 'wolves', 'playing','boys','this', 'dog', 'the', 4 'beaches', 'grounded','envision','table', 'probably'] 5 stemmer=pt.PorterStemmer() 6 for word in words: 7 pt_stem = stemmer.stem(word) 8 print(pt_stem)
運行結果

2.2.5.3 詞形并歸
想要對相同語意詞根的不同拼寫形式都做出統一回復的話,那么詞形歸并工具就很有用,它會減少必須要回復的詞的數目,即語言模型的維度,例如可以 good、goodness、better 等都歸屬于同一處理方式,通過wordnet.lemmatize(word,pos) 方法可指定詞性,與常用的英語單詞類似,n 為名詞 v為動詞 a為形容詞等等,指定詞性后還可以通過posterStemmer.stem() 還原詞干,
1 stemmer=PorterStemmer() 2 wordnet=WordNetLemmatizer() 3 word1=wordnet.lemmatize('boys',pos='n') 4 print(word1) 5 6 word2=wordnet.lemmatize('goodness',pos='a') 7 word2=stemmer.stem(word2) 8 print(word2)
運行結果
![]()
2.2.6 停用詞
在詞庫中往往會存在部分停用詞,使用 nltk.corpus.stopwords 可以找到 NLTK 中包含的停用詞
1 stopword=stopwords.raw('english').replace('\n',' ') 2 print(stopword)
運行結果

通過對比可以對檔案中的停用詞進行過濾
1 words = [ 'the', 'playing','boys','this', 'dog', 'a',] 2 stopword=stopwords.raw('english').replace('\n',' ') 3 words=[word for word in words if word not in stopword] 4 print(words)
運行結果
['playing', 'boys', 'dog']
2.2.3 把詞匯擴展到 n-gram
上面例子中基本使用單個詞作用分詞的方式,然而很多短語例如:ice cream,make sense,look through 等都會多個單詞組合使用,相同的單詞在不同的短語中會有不同的意思,因此,分詞也需要有 n-gram 的能力,針對這個問題 NTLK提供了 ngrams 函式,它可以按實作 2-gram、3-gram等多型別的元素劃分,
1 sentence='Build the way that works best for you '+\ 2 'with support for all your go-to integrations '+\ 3 'including Slack Jira and more.' 4 words=sentence.split() 5 print(list(ngrams(words,2)))
運行結果

2.3 Jieba 庫基礎功能介紹
NLTK 庫有著強大的分詞功能,然而它并不支中文,中文無論從語法、格式、結構上都有很大的差別,下面介紹一個常用的中文庫 Jieba 的基礎功能,
2.3.1 分詞 jieba.cut
jieba.cut 是最常用的分詞方法,回傳值為 generator,jieba.lcut 與 jieba.cut 類似,區別在于 jieba.lcut 直接回傳 list,在資料量比較大時,jieba.cut 會更節省記憶體,
1 def cut(self, sentence, cut_all=False, HMM=True, 2 use_paddle=False):
- sentence 可為 unicode 、 UTF-8 字串、GBK 字串,注意:不建議直接輸入 GBK 字串,可能無法預料地錯誤解碼成 UTF-8,
- 當 cut_all 回傳 bool,默認為 False,當 True 則回傳全分割模式,為 False 時回傳精準分割模式,
- HMM 回傳 bool,默認為 True,用于控制是否使用 HMM 隱馬爾可夫模型,
- use_paddle 回傳 bool, 默認為 False, 用來控制是否使用paddle模式下的分詞模式,paddle模式采用延遲加載方式,利用PaddlePaddle深度學習框架,訓練序列標注(雙向GRU)網路模型實作分詞,同時支持詞性標注,
使用例子
1 sentence='嫦娥四號著陸器地形地貌相機對玉兔二號巡視器成像' 2 word1=jieba.cut(sentence,False) 3 print(list(word1)) 4 word2=jieba.cut(sentence,True) 5 print(list(word2))
運行結果

2.3.2 搜索分詞 jieba.cut_for_search
jieba.cut_for_search 與 jieba.cut 精確模式類似,只是在精確模式的基礎上,對長詞再次切分,提高召回率,適合用于搜索引擎分詞,回傳值為 generator,jieba.lcut_for_search 與 jieba.cut_for_search 類似,但回傳值為 list,
1 def cut_for_search(self, 2 sentence: Any, 3 HMM: bool = True) -> Generator[str, Any, None]
- sentence 可為 unicode 、 UTF-8 字串、GBK 字串,
- HMM 回傳 bool,默認為 True,用于控制是否使用 HMM 隱馬爾可夫模型,
使用例子
1 word1=jieba.cut_for_search('尼康Z7II是去年底全新升級的一款全畫幅微單相機',False) 2 print(list(word1)) 3 word2=jieba.cut_for_search('尼康Z7II是去年底全新升級的一款全畫幅微單相機',True) 4 print(list(word2))
運行結果

2.2.3 載入新詞 jieba.load_userdict
通過此方法可以預先載入自定義的用詞,令分詞更精準,文本中一個詞占一行,每一行分三部分:詞語、詞頻(可省略)、詞性(可省略),用空格隔開,順序不可顛倒,
例如:設定 word.txt 文本
阿里云 1 n
云計算 1 n
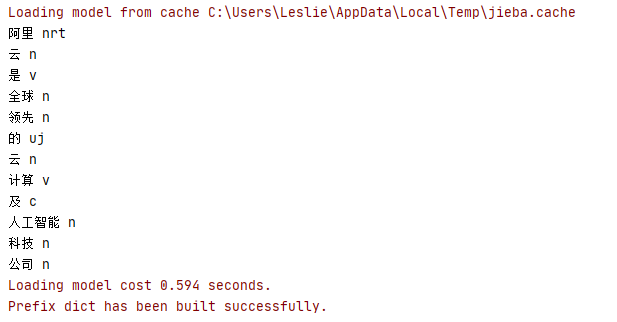
1 word1=jieba.cut('阿里云是全球領先的云計算及人工智能科技公司') 2 print(list(word1)) 3 jieba.load_userdict('C://Users/Leslie/Desktop/word.txt') 4 word2=jieba.cut('阿里云是全球領先的云計算及人工智能科技公司') 5 print(list(word2))
運行結果

2.2.4 動態調節詞典
通過 jieba.add_word 和 jieba.del_word 這兩個方法也可以動態地調節詞典
1 def add_word(self, word, freq=None, tag=None):
jieba.add_word 可以把自定義詞加入詞典,當中 freq 為詞頻,tag 為詞性,
1 def del_word(self, word):
相反,通過 jieba.del_word 可以動態洗掉加載的自定義詞
1 word1=jieba.cut('阿里云是全球領先的云計算及人工智能科技公司') 2 print(list(word1)) 3 jieba.add_word('阿里云') 4 jieba.add_word('云計算') 5 word2=jieba.cut('阿里云是全球領先的云計算及人工智能科技公司') 6 print(list(word2)) 7 jieba.del_word('阿里云') 8 word3=jieba.cut('阿里云是全球領先的云計算及人工智能科技公司') 9 print(list(word3))
運行結果

2.2.5 詞節詞頻 jieba.suggest_freq
此方法可調節單個詞語的詞頻,使其能(或不能)被分出來,注意:自動計算的詞頻在使用 HMM 新詞發現功能時可能無效,
1 def suggest_freq(self, segment, tune=False):
下面的例子就是把 “阿里云” 這個詞拆分的程序
word1=jieba.cut('阿里云是全球領先的云計算及人工智能科技公司') print(list(word1)) jieba.suggest_freq('阿里云',True) word2=jieba.cut('阿里云是全球領先的云計算及人工智能科技公司',False,False) print(list(word2)) jieba.suggest_freq(('阿里','云'),True) word3=jieba.cut('阿里云是全球領先的云計算及人工智能科技公司',False,False) print(list(word3))
運行結果

2.2.6 標注詞性 jieba.posseg
通過 posseg.cut 可以查看標注詞性,除此以外還可以 jieba.posseg.POSTokenizer 新建自定義分詞器
1 words=jieba.posseg.cut('阿里云是全球領先的云計算及人工智能科技公司') 2 for word,flag in words: 3 print(word,flag)
運行結果
2.2.7 使用 jieba 計算詞頻
下面例子介紹一下如何使用 jieba 計算一篇文章的詞頻,首先讀取文章內容,進行去標點處理,然后動態加入常用詞,使用 jieba.lcut 方法進行分詞,最后讀取停用詞,把文章的分詞集合進行過濾,對每個詞的詞頻進行計算,
1 def readFile(): 2 # 讀取檔案 3 file=open('C://Users/Leslie/Desktop/word.txt','r',102400,'utf8').read() 4 # 去標點 5 text=re.sub('[·,,\’!\"\#$%&\'()#!()*+,-./:;<=>?\@,:?¥★、….>【】[]《》?\“\”\‘\’\[\\]^_`{|}~]+' 6 ,'',file) 7 # 加入常用詞 8 jieba.add_word('云計算') 9 ...... 10 # 利用 Jieba 分詞 11 words=jieba.lcut(text) 12 print('總詞數:{0}'.format(len(words))) 13 return words 14 15 def stopWord(): 16 # 讀取停用詞 17 stopword=[line.strip() for line in open('C://Users/Leslie/Desktop/stopword.txt','r',1024,'utf8') 18 .readlines()] 19 return stopword 20 21 def wordFrequency(): 22 # 獲取文章的詞 23 fileWords=readFile() 24 # 獲取停用詞 25 stopWords=stopWord() 26 words={} 27 # 計算詞頻 28 for word in fileWords: 29 if word not in stopWords: 30 if word not in words: 31 words[word]=1 32 else: 33 words[word]+=1 34 print('單詞數: {0}'.format(len(words))) 35 return words 36 37 if __name__=='__main__': 38 words=wordFrequency() 39 for item in words.items(): 40 print(item)
運行結果
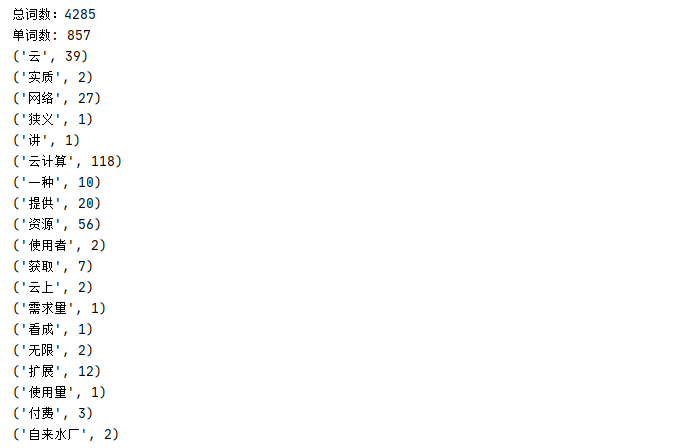
回到目錄
三、詞向量
完成分詞的作業后,在進行運算前,先要對資料進行向量化,常用的詞向量有 one-hot 獨熱向量、 tf-idf 向量和 embedding 詞嵌入等,下面將進一步介紹,
3.1 one-hot 獨熱向量
one-hot 獨熱向量是比較容易理解的一種詞向量,它是把詞匯表中的詞的數量與詞位置都進行記錄,每個陳述句中所有資訊都沒有丟失,這也是 one-hot 的優點,
下面的例子先將詞句按照原順序進行分詞,分詞完成后,[1 0 0 0 0 0 0 0] 為第一個詞 “珠穆朗瑪峰”,[0 1 0 0 0 0 0 0] 為每二個詞 “上”,如此類推,
然后把詞組進行重排列作用測驗資料 ['上', '如此', '星空', '是', '珠穆朗瑪峰', '的', '的', '迷人'],查看測驗資料的 one-hot 向量,
通過測驗結果可以看過,one-hot 對資料進行了全面記錄,測驗資料中每個詞出現的順序和次數都被完整地記錄下來,
1 def getWords(): 2 # 對句子進行分詞 3 sentence='珠穆朗瑪峰上的星空是如此的迷人' 4 words=jieba.lcut(sentence) 5 print('【原始陳述句】:{0}'.format(sentence)) 6 print('【分詞資料】:{0}'.format(words)) 7 return words 8 9 def getTestWords(): 10 # 把詞集進行重新排序后作為測驗資料 11 words=getWords().copy() 12 words.sort() 13 print('【測驗資料】:{0}'.format(words)) 14 return words 15 16 def one_hot_test(): 17 # 獲取分詞后資料集 18 words=getWords() 19 # 獲取測驗資料集 20 testWords=getTestWords() 21 size=len(words) 22 onehot_vectors=np.zeros((size,size),int) 23 # 獲取測驗資料 one_hot 向量 24 for i,word in enumerate(testWords): 25 onehot_vectors[i,words.index(word)]=1 26 return onehot_vectors 27 28 if __name__=='__main__': 29 print(one_hot_test())
運行結果

通過結果可以看出每一行都只會有一個為非零值,估計這也是把此方法稱作 one-hot 的原因,這樣看起來雖然很直觀,但是也浪費了很多的資料空間,一個簡單的句子已經要使用 8*8 的陣列,當使用大量訓練資料時,比如 500 篇 3000 字的文章,常用的文字就有2000個,常用詞可能會有 18000 個,模型所要耗費的存盤資源將會成指數級的提升,所以這方法的實用性比較低,
3.2 TF-IDF 向量
為了克服 one-hot 向量的弱點,設計出了一個新的向量表示方法 TF-IDF 向量,TF-IDF(term frequency–inverse document frequency) 是一種用于資訊檢索與資料挖掘的常用加權技術,用以評估一字詞對于一個檔案集或一個語料庫中的其中一份檔案的重要程度,常用于挖掘文章中的關鍵詞,而且演算法簡單高效,常被工業用于最開始的文本資料清洗,
TF-IDF 不再關注分詞出現的順序而是更關注其出現的頻率和次數,它由 TF 和 IDF 兩部分組成,TF 是統計一個詞在一篇文章中的出現頻次,IDF 則統計一個詞在檔案集中的多少個檔案出現,統計后字詞的重要性隨著它在檔案中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降,
3.2.1 TF 詞頻
TF 詞頻是代表詞在單篇文章中出現的頻率,為了更好理解 TF ,舉一個例子,假如在第一篇 1000 個總詞數的文章,“ 云計算 ” 這個詞出現了 50 次,那 TF 為 50 / 1000 ,即 0.05 ,而在第二篇有 10000 個總詞數的文章,“ 云計算 ” 出現了100 次,那 TF 為 100 / 10000,即 0.01,如此類推,下面是 TF 的計算公式:
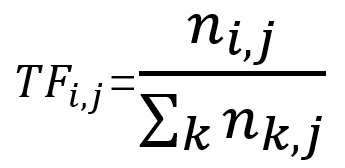
當中 ni,j 代表詞 i 在文章 j 中出現的頻次,而分母 nk,j 則代表文章 j 中的每個詞出現的次數的總和,
3.2.2 IDF 逆文本頻率
而 IDF 逆文本頻率指數是代表詞語在檔案中的稀缺程度,它等總檔案數目除以包含該詞語之檔案的數目,再將得到的商取以10為底的對數得到 ,例如有 1000 篇檔案,其中有 30 篇包含了 “向量” 這個詞,那 IDF 為 log(1000 / 30),考慮到當檔案不存這個詞時分母會為 0,所以默認情況下會為分母加 1,即 log (1000 / 30 +1),如此類推,下面是 IDF 的計算公式:
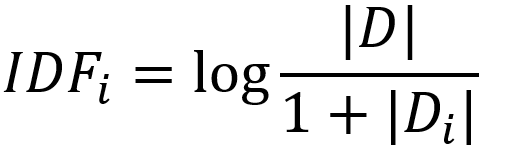
當中 D 代表所有文章的總數,Di 代表出現詞 i 的文章數,為了避免詞庫中某些詞在文章中沒有出現過而造成分母為 0 的現象,所以把分母作加 1 處理,
3.2.3 TF-IDF 計算
TF-IDF 顧名思義就是代表 TF 與 IDF 的乘積
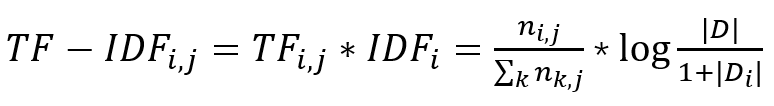
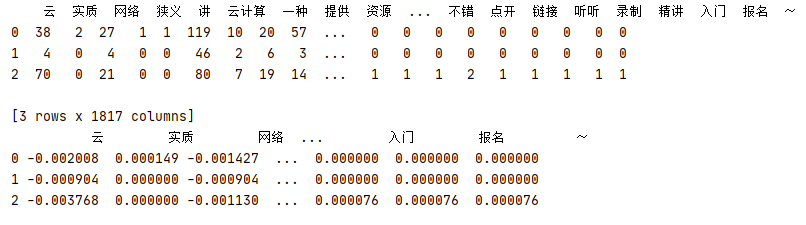
下面例子說明一下 TF-IDF 的計算方式,首先遍歷檔案夾里的所有檔案,找到分詞后進行 stopword 過濾,然后得到分詞的集合 wordKeys,
根據分詞集合 wordKeys 計算每篇文章中所包含的分詞數量 wordsValues,在此顯示一下這個分詞值,
最后根據 TF-IDF 計算公式計算 TF-IDF ,顯示計算結果,從計算結果可以看出,分詞數量最多的值往往是負值,這里因為 IDF 計算中包含此詞的檔案數會跟 IDF 成反比,由于測驗檔案都是在網上下載關于 "云計算” 相關的論文,所以 “云計算” 這些分詞的 TF-IDF 為負值,
1 # 分詞集合 2 wordKeys=[] 3 # 每個分詞的數量集合 4 wordValues=[] 5 # 每篇文章的詞量總數 6 totalCounts=[] 7 # tdidf 值 8 tdidf = [] 9 10 def readFile(filepath): 11 # 讀取檔案 12 file=open(filepath,'r',102400,'utf8').read() 13 # 去標點 14 text=re.sub('[·,,\’!\"\#$%&\'()#!()*+,-./:;<=>?\@,:?¥★、….>【】[]《》?\“\”\‘\’\[\\]^_`{|}~]+' 15 ,'',file) 16 # 加入常用詞 17 jieba.add_word('云計算') 18 # ... 19 # 利用 Jieba 分詞 20 words=jieba.lcut(text) 21 return words 22 23 def stopWord(): 24 # 讀取停用詞 25 stopword=[line.strip() for line in open('../stopword.txt','r',1024,'utf8') 26 .readlines()] 27 stopword.append('\n') 28 stopword.append(' ') 29 stopword.append('\u200b') 30 return stopword 31 32 def getFilePath(): 33 # 讀取目錄下所有檔案路徑 34 dir=os.walk('../files') 35 filePath=[] 36 for path,index,files in dir: 37 for file in files: 38 _path=os.path.join(path,file) 39 filePath.append(_path) 40 return filePath 41 42 def getKeys(): 43 readData=https://www.cnblogs.com/leslies2/archive/2022/03/28/[] 44 # 獲取檔案路徑 45 filePath=getFilePath() 46 # 獲取停用詞 47 stopWords = stopWord() 48 # 讀取所有文本的詞 49 for file in filePath: 50 readData=https://www.cnblogs.com/leslies2/archive/2022/03/28/readData+readFile(file) 51 # 過濾停用詞 52 for word in readData: 53 if word not in stopWords and word not in wordKeys: 54 wordKeys.append(word) 55 56 def getValues(): 57 # 獲取檔案路徑集合 58 filePath=getFilePath() 59 # 行 index 60 index=0 61 for file in filePath: 62 # 行值 63 values = [] 64 # 記錄每個檔案的分詞總數 65 totalCount=0 66 # 獲取分詞 67 words=readFile(file) 68 # 獲取每篇文章的分詞數量 69 counts=Counter(words) 70 for key in wordKeys: 71 if key in counts.keys(): 72 values.append(counts[key]) 73 totalCount+=counts[key] 74 else: 75 values.append(0) 76 # 插入行 77 wordValues.insert(index,values) 78 totalCounts.append(totalCount) 79 index+=1 80 81 def getTFIDF(): 82 list = np.array(wordValues) 83 # 分行計算 84 for index in range(0,len(wordValues)): 85 col=0 86 row=[] 87 # 分別計算 TF 值與 IDF 值 88 for value in wordValues[index]: 89 # 計算 TF 值 90 tf=value / totalCounts[index] 91 # 獲取當前列的集合 92 cols=list[:,col] 93 # 計算有多少篇檔案包含當前分詞 94 nonzerocount=np.count_nonzero(cols) 95 # 計算 IDF 96 idf=np.log10(len(list)/(nonzerocount+1)) 97 # 計算 TFIDF 把計算結果加入集合 98 row.append(tf*idf) 99 col+=1 100 # 插入行 101 tdidf.insert(index,row) 102 index+=1 103 104 if __name__=='__main__': 105 getKeys() 106 getValues() 107 # 查看過濾后每個分詞在每篇文章中的數量 108 dataset=pd.DataFrame(wordValues,columns=wordKeys) 109 print(dataset.head(3)) 110 # 查看計算后的 TFIDF 值 111 getTFIDF() 112 tfidfSet=pd.DataFrame(tdidf,columns=wordKeys) 113 print(tfidfSet.head(3))
運行結果
3.3 TfidfVectorizer 簡介
上面例子通過 python 手動實作 TF-IDF 的計算,其實在 sklearn 中已有 TfidfVectorizer 類支持 TF-IDF 運算,它包含大量的常用方法,使計算起來變得特別簡單,下面簡單介紹一下,
1 class TfidfVectorizer(CountVectorizer): 2 @_deprecate_positional_args 3 def __init__(self, *, input='content', encoding='utf-8', 4 decode_error='strict', strip_accents=None, lowercase=True, 5 preprocessor=None, tokenizer=None, analyzer='word', 6 stop_words=None, token_pattern=r"(?u)\b\w\w+\b", 7 ngram_range=(1, 1), max_df=1.0, min_df=1, 8 max_features=None, vocabulary=None, binary=False, 9 dtype=np.float64, norm='l2', use_idf=True, smooth_idf=True, 10 sublinear_tf=False):
引數說明
- input:str 型別 {'filename', 'file', 'content'},輸入值, 如果是'filename',序列作為引數傳遞給擬合器,預計為檔案名串列,這需要讀取原始內容進行分析; 如果是'file',序列專案必須有一個”read“的方法(類似檔案的物件),被呼叫作為獲取記憶體中的位元組數; 也可直接輸入預計為序列串,或位元組資料項都預計可直接進行分析,
- encoding:str 型別,編碼型別,默認為 ‘utf-8’by default
- decode_error: str 型別 {'strict', 'ignore', 'replace'} 三選一,默認為 ' strict' 表示UnicodeDecodeError將提高, 引數表示如果一個給出的位元組序列包含的字符不是給定的編碼,指示應該如何去做,
- strip_accents: str 型別 {'ascii', 'unicode', None} 三選一,默認為 ' None' ,在預處理步驟中去除編碼規則(accents),”ASCII碼“是一種快速的方法,僅適用于有一個直接的ASCII字符映射,"unicode"是一個稍慢一些的方法,None(默認)什么都不做
- lowercase: bool 型別,默認為 True,執行前把字母變為小寫
- preprocessor:callable or None,默認為None,當保留令牌和”n-gram“生成步驟時,覆寫預處理(字串變換)的階段
- tokenizer:callable or None 默認為 default, 當保留預處理和n-gram生成步驟時,覆寫字串令牌步驟
- analyzer:str型別 {'word', 'char'} or callable 定義特征為詞(word)或n-gram字符,如果傳遞給它的呼叫被用于抽取未處理輸入源檔案的特征序列
- stop_words:{'english'} 或 list, 默認為 None,english,用于英語內建的停用詞串列,list,該串列被假定為包含停用詞,串列中的所有詞都將從令牌中洗掉,None,不使用停用詞,max_df可以被設定為范圍 [0.7, 1.0) 的值,基于內部預料詞頻來自動檢測和過濾停用詞
- token_pattern:str型別,默認為 r"(?u)\\b\\w\\w+\\b",正則運算式顯示了”token“的構成,僅當analyzer == ‘word’時才被使用,兩個或多個字母數字字符的正則運算式(標點符號完全被忽略,始終被視為一個標記分隔符),
- ngram_range: tuple(min_n, max_n),默認為 (1,1),要提取的n-gram的n-values的下限和上限范圍,在min_n <= n <= max_n區間的n的全部值
- max_df: float in range [0.0, 1.0] or int, optional, 默認值為 1.0 ,當構建詞匯表時,嚴格忽略高于給出閾值的檔案頻率的詞條,語料指定的停用詞,如果是浮點值,該引數代表檔案的比例,整型絕對計數值,如果詞匯表不為None,此引數被忽略,
- min_df:float in range [0.0, 1.0] or int, optional, 默認為 1.0 ,當構建詞匯表時,嚴格忽略低于給出閾值的檔案頻率的詞條,語料指定的停用詞,如果是浮點值,該引數代表檔案的比例,整型絕對計數值,如果詞匯表不為None,此引數被忽略,
- max_features: optional,默認為 None ,如果不為 None,構建一個詞匯表,僅考慮 max_features 按語料詞頻排序,如果詞匯表不為None,這個引數被忽略
- vocabulary:Mapping or iterable, optional 默認為 None, 一個映射(Map)(例如,字典),其中鍵是詞條而值是在特征矩陣中索引,或詞條中的迭代器,如果沒有給出,詞匯表被確定來自輸入檔案,在映射中索引不能有重復,并且不能在0到最大索引值之間有間斷,
- binary:bool型別,默認為 False, 如果為 True,所有非零計數被設定為1,這對于離散概率模型是有用的,建立二元事件模型,而不是整型計數
- dtype:type,默認為 np.float 64 ,通過fit_transform()或transform()回傳矩陣的型別
- norm:'l1', 'l2', or None,默認為 ’l2',范數用于標準化詞條向量,None為不歸一化
- use_idf:bool,默認為 True,是否 啟動 inverse-document-frequency重新計算權重
- smooth_idf:bool 默認為 True,通過加1到檔案頻率平滑idf權重,為防止除零,加入一個額外的檔案
- sublinear_tf:bool默認為 False,是否應用線性縮放TF,例如,使用1+log(tf)覆寫 tf
常用方法
- fit(self, raw_documents, y=None): 表示用資料 raw_documents 來訓練模型,
- transform(selft ,raw_documents):將資料 raw_documents 使用通過學習的詞匯和檔案頻率進行運算,通過與 fit 同用,先呼叫 fix,當模型訓練好后,再使用 transform 方法來運算,
- fit_transform(self, raw_documents, y=None): 相當于結合了 fit 與 transform 兩個方法,用 raw_documents 來訓練模型,同時回傳運算后的資料,
- inverse_transform(self, X):將運算后的資料轉換成為原始資料,
TfidfVectorizer 模型可以直接通過 fit_transform 方法直接計算出 TF-IDF 向量,無需進行繁瑣的公式運算,還可在建立模型時設定如停用詞,n-gram,編碼型別等多個常用的運算條件,
1 corpus = [ 2 'In addition to having a row context', 3 'Usually a smaller text field', 4 'The TFIDF idea here might be calculating some rareness of words', 5 'The larger context might be the entire text column', 6 ] 7 8 def stopWord(): 9 # 讀取停用詞 10 stopword=[line.strip() for line in open('C://Users/Leslie/Desktop/stopword.txt','r',1024,'utf8') 11 .readlines()] 12 return stopword 13 14 def tfidfVectorizerTest(): 15 words=corpus 16 #建立tfidf模型 17 vertorizer=tfidfVectorizer(stop_words=stopWord(),ngram_range=(1,2)) 18 #訓練與運算 19 model=vertorizer.fit_transform(words) 20 #顯示分詞 21 print(vertorizer.vocabulary_) 22 #顯示向量 23 print(model) 24 25 if __name__=='__main__': 26 tfidfVectorizerTest()
運行結果
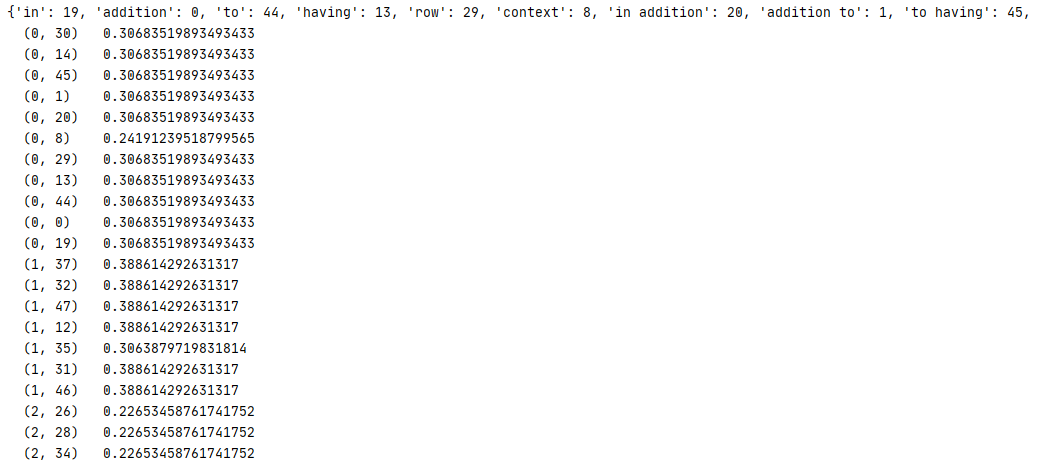
TfidfVectorizer 畢竟是針對外語單詞格式所設計,所以用到中文時需要把句子轉換成類似外語的格式,行利用 jieba 先進行分詞,然后重新組合成句子,在每個分詞后加上空格,
1 corpus = [ 2 '北京冬奧會完美落下帷幕', 3 '冬奧生態內容方面的表現給用戶留下深刻印象', 4 '全平臺創作者參與冬奧內容創作', 5 '此次冬奧會對于中國是一次重要的里程碑時刻', 6 ] 7 8 def stopWord(): 9 # 讀取停用詞 10 stopword=[line.strip() for line in open('C://Users/Leslie/Desktop/stopword.txt','r',1024,'utf8') 11 .readlines()] 12 return stopword 13 14 def getWord(): 15 # 轉換集合格式后再進行分詞 16 list=[jieba.lcut(sentence) for sentence in corpus] 17 # 在每個詞中添加空格符 18 word=[' '.join(word) for word in list] 19 return word 20 21 def tfidfVectorizerTest(): 22 words=getWord() 23 # 列印轉換格式后的分詞 24 print(str.replace('格式轉換:{0}\n'.format(words),',','\n\t\t')) 25 # 建立模型 26 vertorizer=tfidfVectorizer(stop_words=stopWord()) 27 # 模型訓練 28 model=vertorizer.fit_transform(words) 29 print('分詞:{0}\n'.format(vertorizer.vocabulary_)) 30 print(model) 31 32 if __name__=='__main__': 33 tfidfVectorizerTest()
運行結果

3.4 淺談 PageRank 演算法
除了 TF-IDF 演算法,還有一種較為常用的 PageRank 演算法,它是由 Mihalcea 與 Tarau于提出,其思想與 TF-IDF 有所區別,它是通過詞之間的相鄰關系構建網路,然后用迭代計算每個節點的 rank 值,排序 rank值即可得到關鍵詞,公式如下,其中 PR(Vi)表示結點Vi的rank值,In(Vi)表示結點Vi的前驅結點集合,Out(Vj)表示結點Vj的后繼結點集合,d為damping factor用于做平滑,其原理在此暫不作詳細講解,
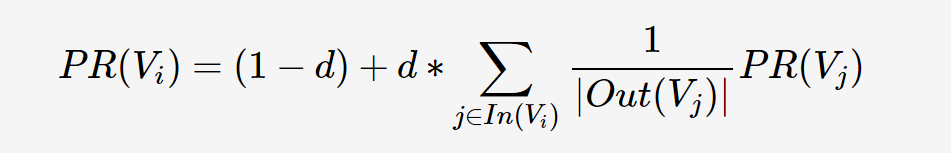
TextRank 演算法與 TF-IDF 演算法均嚴重依賴于分詞結果,如果某詞在分詞時被切分成了兩個詞,那么在做關鍵詞提取時無法將兩個詞黏合在一起(TextRank有部分黏合效果,但需要這兩個詞均為關鍵詞),因此是否添加標注關鍵詞進自定義詞典,將會造成準確率、召回率大相徑庭,TextRank 雖然考慮到了詞之間的關系,但是仍然傾向于將頻繁詞作為關鍵詞,其效果并不一定優于 TF-IDF,
回到目錄
四、文本相似度分析
4.1 余弦相似度定義
完成分詞后利用 TF-IDF 演算法把分詞成功轉換成向量,便可以開始對向量進行計算,最常用的方法是余弦相似度計算,為了更好地理解,假設在二維空間有向量 doc1(x1,y1)和 向量doc2 (x2, y2),可以簡單地理為分詞 word1,word2 在 doc1 中的詞頻為 x1, y1,在 doc2 中的詞頻為 x2, y2,
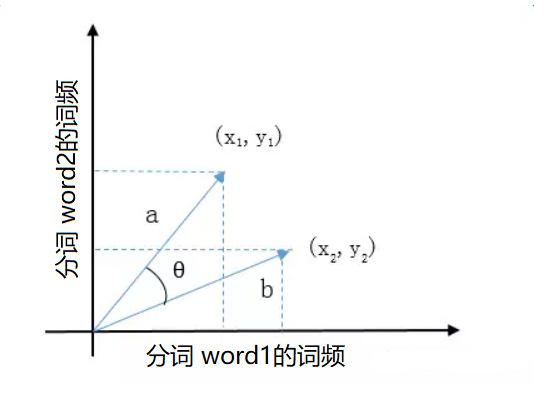
根據歐幾里得點積公式
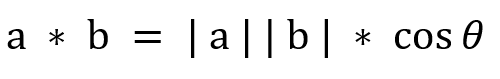
可推算出余弦相似度計算公式
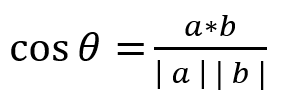
當值越大時證明相似度越高,當值越小時證明相似度越低,
在此例子中可以理解為當兩個分詞 word 1, word2 在 doc1 ,doc2 的詞頻非常接近時,兩篇文章的內容被視為非常相似,
當余弦相似度為0時,相當于 doc1 只含有 word 1,而 doc2 只含有 word2,則被視作向量之間沒有任何相似成分,當余弦相似度為 -1 時,則意味著方向正好相反,
現實應用中每篇文章肯定不止兩個分詞,根據同樣道理,可以把多維度的計算公式擴展如下
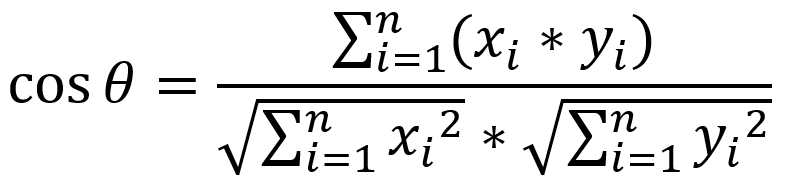
4.2 余弦相似度計算
在 sklearn.metrics.pairwise 中提供了余弦相似度計算的函式 cosine_similarity 和余弦距離計算函式 cosine_distances 可以通過簡單的運算計算出余弦相信度
4.2.1 cosine_similarity 函式
1 def cosine_similarity(X, Y=None, dense_output=True):
當中 X 代表第一個對比值,Y 代表第二個對比值,若 Y 為 None 時則會對 X 輸入的陣列作相似性對比,
當 dense_output 為True 則無論輸入是否稀疏,都將回傳密集輸出,若 dense_output 為 False 時,如果兩個輸入陣列都是稀疏的,則輸出是稀疏的,
1 x0=np.array([0.895,0.745]).reshape(1,-1) 2 y0=np.array([0.568,0.445]).reshape(1,-1) 3 similarity0=cosine_similarity(x0,y0) 4 print('similarity0 is:\n{0}\n'.format(similarity0)) 5 6 x1=np.arange(4).reshape(2,2) 7 similarity1=cosine_similarity(x1) 8 print('similarity1 is:\n{0}\n'.format(similarity1)) 9 10 x2=np.arange(10).reshape(2,5) 11 y2=np.arange(15).reshape(3,5) 12 similarity2=cosine_similarity(x2,y2) 13 print('similarity2 is:\n{0}\n'.format(similarity2))
運行結果

4.2.2 cosine_distances 函式
1 def cosine_distances(X, Y=None):
cosine_distances 用法與 cosine_similarity 類似,只是 cosine_distances 回傳的是余弦的距離,余弦相似度越大,余弦距離越小
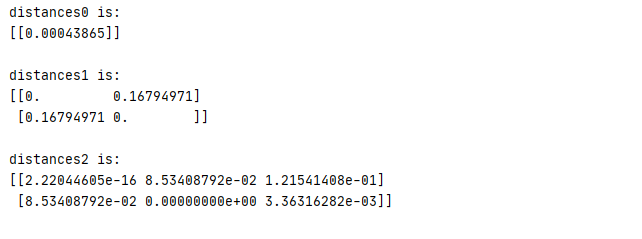
1 x0=np.array([0.895,0.745]).reshape(1,-1) 2 y0=np.array([0.568,0.445]).reshape(1,-1) 3 distances0=cosine_distances(x0,y0) 4 print('distances0 is:\n{0}\n'.format(distances0)) 5 6 x1=np.arange(4).reshape(2,2) 7 distances1=cosine_distances(x1) 8 print('distances1 is:\n{0}\n'.format(distances1)) 9 10 x2=np.arange(10).reshape(2,5) 11 y2=np.arange(15).reshape(3,5) 12 distances2=cosine_distances(x2,y2) 13 print('distances2 is:\n{0}\n'.format(distances2))
運行結果
4.3 文本相似度計算
根據余弦相似度,可以對 TF-IDF 向量進行比較,計算出文本之間的關聯度,此原理常被廣泛應用于聊天機器人,車機對話,文本自動回復等領域,先預設多個命令與回復,計算出 TF-IDF 向量,然后把輸入的命令 TF-IDF 向量與預設命令的 TF-IDF 向量進行對比,找出相似度最高的命令,最后輸出相關的回復,
下面以車機系統為例子,說明一下文本相似度計算的應用,command 代表多個車機的預設命令與回復陣列,先通過 jieba 把中文命令轉化為相關格式,對 TfidfVectorizer 模型進行訓練,然后分別計算 command 預計命令的 TF-IDF 向量和 inputCommand 輸入命令的 TF-IDF 向量,通過余弦相似度對比,找到相似度最高的命令,最后輸出回復,
1 # 車機的命令與回復陣列 2 command=[['請打開車窗','好的,車窗已打開'], 3 ['我要聽陳奕迅的歌','為你播放富士山下'], 4 ['我好熱','已為你把溫度調到25度'], 5 ['幫我打電話給小豬豬','已幫你撥小豬豬的電話'], 6 ['現在幾點鐘','現在是早上10點'], 7 ['我要導航到中華廣場','高德地圖已打開'], 8 ['明天天氣怎么樣','明天天晴'] 9 ] 10 11 # 利用 jieba 轉換命令格式 12 def getWords(): 13 comm=np.array(command) 14 list=[jieba.lcut(sentence) for sentence in comm[:,0]] 15 words=[' '.join(word) for word in list] 16 return words 17 18 # 訓練 TfidfVectorizer 模型 19 def getModel(): 20 words=getWords() 21 vectorizer=TfidfVectorizer() 22 model=vectorizer.fit(words) 23 print(model.vocabulary_) 24 return model 25 26 # 計算 consine 余弦相似度 27 def consine(inputCommand): 28 # 把輸入命令轉化為陣列格式 29 sentence=jieba.lcut(inputCommand) 30 words=str.join(' ',sentence) 31 list=[] 32 list.insert(0,words) 33 # 獲取訓練好的 TfidfVectorizer 模型 34 model=getModel() 35 # 獲取車機命令的 TF-IDF 向量 36 data0=model.transform(getWords()).toarray().reshape(len(command),-1) 37 # 獲取輸入命令的 TF-IDF 向量 38 data1=model.transform(list).toarray().reshape(1,-1) 39 # 余弦相似度對比 40 result=cosine_similarity(data0,data1) 41 print('相似度對比:\n{0}'.format(result)) 42 return result 43 44 if __name__=='__main__': 45 comm='我要聽陳奕迅的歌' 46 # 獲取余弦相似度 47 result=np.array(consine(comm)) 48 # 獲取相似度最高的命令 index 49 argmax=result.argmax() 50 # 讀取命令回復 51 data=https://www.cnblogs.com/leslies2/archive/2022/03/28/command[argmax][1] 52 print('命令:{0}\n回復:{1}'.format(comm,data))
運行結果

回到目錄
五、通過主題轉換進行語意分析
5.1 LSA 隱性語意分析的定義
上面的例子都是通過分詞的 TF-IDF 向量以余弦相似度對比分析文本內容的相似性,其實 TF-IDF 向量不僅適用于詞,還適用于多詞組合的 n-gram 分析,通過多個分詞的不同組合,可以揭示一篇文章的語意,核心主題等,NLP 開發人員發現一種提示詞組合的演算法,被稱為 LSA (Latent Semantic Analysis 隱性語意分析),
LSA 可用于文本的主題提取,挖掘文本背后的含義、資料降維等方面,例如一篇文章的分詞中 “ 服務、協議、資料交換、傳輸物件” 占比較大的,可能與 “ 云計算 ” 主題較為接近; “ 分詞、詞向量、詞頻、相似度” 占比較大的可能與 " 自然語言開發 " 主題較為接近,在現實的搜索引擎中,普通用戶所輸入的關鍵詞未必能與分詞相同,通過核心主題分析,往往更容易找出相關的主題文章,這正是 LSA 語意分析的意義,
5.2 SVD 奇異值分解原理
LSA 是一種分析 TF-IDF 向量的演算法,它是基于 SVD ( Singular Value Decomposition 奇異值分解 ) 技術實作的,SVD 是將矩陣分解成三個因子矩陣的演算法,屬于無監督學習模型,這種演算法也被常用在影像分析領域,
在影像分析領域 SVD 也被稱作 PCA 主成分分析,在《 Python 機器學習實戰 》 系列的文章中,曾對 PCA 主成分分析作詳細介紹,對此話題有興趣的朋友可閱讀《 Python 機器學習實戰 —— 無監督學習 》
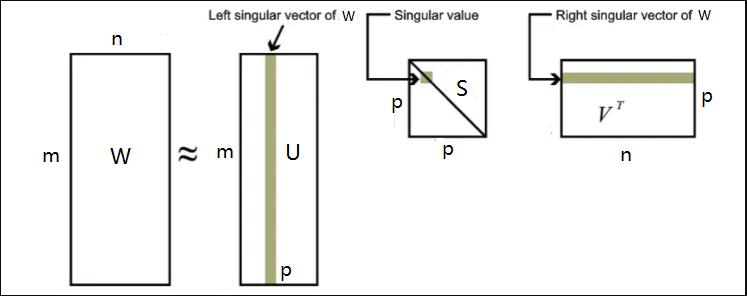
SVD 公式表示如下,m 為詞匯中的分詞數量,n 為檔案數量,p為庫的主題數量,通過 SVD 演算法,可以把包含大量分詞的文章劃分成多個主題的專欄,
![]()
其中向量 U 是 分詞-主題 矩陣,它給出分詞所具有的背景關系資訊,代表分詞與主題的相互關系,也被稱為 “ 左奇異向量 ”,
向量 S 是主題奇異值的物件線方陣,例如有 6 個主題的檔案庫 S 值就會是一個 6*6 的矩陣,
向量 V 是 主題-檔案 矩陣,它建立了新主題與檔案之間的關系,也被稱為 “ 右奇異向量 ”,
5.3 TruncatedSVD 模型
在 sk-learn 庫中提供了sklearn.decomposition.TruncatedSVD 模型用于進行 SVD 分析,SVD 是無監督模型,通過SVD 可以把多維的數量進行主題轉換實作降維,常被用于情感分析和垃圾資訊處理,
1 class TruncatedSVD(TransformerMixin, BaseEstimator): 2 @_deprecate_positional_args 3 def __init__(self, n_components=2, *, algorithm="randomized", n_iter=5, 4 random_state=None, tol=0.): 5 self.algorithm = algorithm 6 self.n_components = n_components 7 self.n_iter = n_iter 8 self.random_state = random_state 9 self.tol = tol
引數說明
- algorithm:str 型別 {'arpack', 'randomized'} 之一,默認值為 “randomized”,用于選擇 SVD 演算法,arpack 為 SciPy中 ARPACK 包裝器( "scipy.sparse.linalg.svds"); randomized 為演算法由于Halko 中的隨機演算法(randomized)
- n_components:int 型別,默認值為 2,選擇主題數量
- n_iter: int 型別,默認值為 5,運算時的迭代次數
- randow_state:int ,RandomState 實體或 None,默認值為 None,在隨機初始化 svd 期間使用,傳遞一個 int 以獲得可重現的結果多個函式呼叫,
- tol: float 型別,默認值為 0.0,當 algorithm 為 arpack 時使用,選擇機器精度,當 algorithm 為 randomized 演算法時自動忽略此設定,
轉換主題時可先利用 TfidfVectorizer 將資料進行 TF-IDF 向量化,然后使用 TruncatedSVD 模型設定轉換輸出的主題型別數量,對主題的相關資料進行情感分析,
下面例子是從今日頭條下載的資料,里面包含了財經、運動、娛樂、文化等多個主題,首先利用 jieba 進行分詞,然后使用 TD-IDF 進行向量化處理,然后使用 TruncatedSVD 模型把 30000 多個分詞進行主題化處理,轉換成 10 個 components,
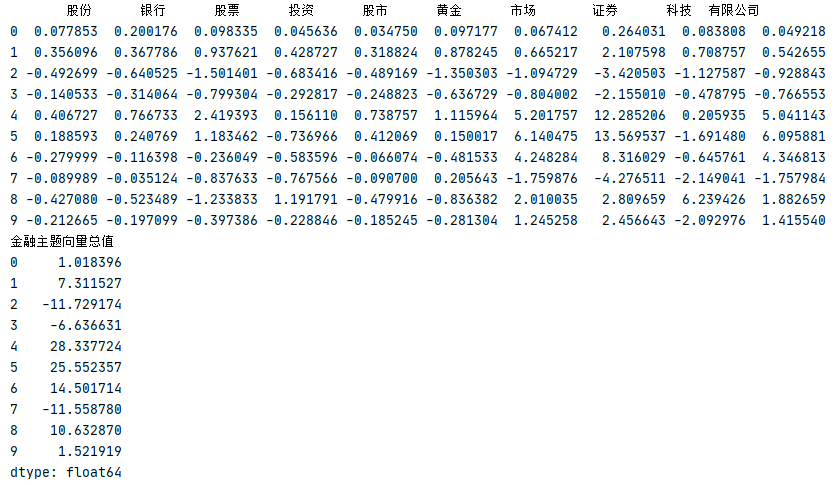
假設財經主題 finance 包含有 ['股份','銀行','股票','投資','股市','黃金','市場','證券','科技','有限公司'] 等常用關鍵字,在 componets 中找到對應 finance 主題的關鍵字向量,對其進行情感分析,通過 svdVectorsDisplay()可分別顯示金融主題最大正值內容和最小負值內容,
1 # 金融主題的關鍵字 2 finance=['股份','銀行','股票','投資','股市','黃金','市場','證券','科技','有限公司'] 3 4 # 利用 jieba 轉換命令格式 5 def getWords(): 6 file=open('C://Users/Leslie/Desktop/toutiao/news.txt','r',1024,'utf-8').read() 7 sentences=np.array(file.split('\n')) 8 # jieba 分詞 9 list=[jieba.lcut(sentence) for sentence in sentences] 10 # 轉換中文分詞格式 11 words=[' '.join(word) for word in list] 12 return words 13 14 # 訓練 TF-IDF 向量 15 def getTfidfVector(): 16 tfidf = TfidfVectorizer() 17 # 獲取分詞 18 words=getWords() 19 # 訓練模型,回傳 TF-IDF 向量 20 vector=tfidf.fit_transform(words) 21 return tfidf,vector 22 23 def svdComponent(): 24 # 獲取 TF-IDF 向量 25 tfidf,vectors=getTfidfVector() 26 # 建立 SVD 模型 27 svd=TruncatedSVD(n_components=10,n_iter=10) 28 # 獲取 TF-IDF 向量,訓練 SVD 模型 29 svd=svd.fit(vectors) 30 svd_vectors=svd.transform(vectors) 31 # 顯示主題 32 keys=tfidf.vocabulary_.keys() 33 # 獲取相關主題的 components 向量 34 dataframeComponents=pd.DataFrame(svd.components_,columns=keys) 35 # 按照 component 5 進行相關性排序 36 dataframeVectors = pd.DataFrame(svd_vectors).sort_values(5, ascending=False).head(10) 37 svdComponentDisplay(dataframeComponents) 38 svdVectorsDisplay(dataframeVectors) 39 40 def svdComponentDisplay(dataframe): 41 # 獲取與 finance 金融有關的關鍵詞主題向量 42 topic = dataframe[finance] * 10000 43 # 顯示與金融主題相關的SVD模型component主題 44 pd.options.display.max_columns = 10 45 # 列印主題向量及向量總值 46 print(topic) 47 print(topic.T.sum()) 48 49 def svdVectorsDisplay(dataframe): 50 print(dataframe) 51 words=getWords() 52 # 金融主題 finance 關鍵字相關性陳述句 53 for row in dataframe.iterrows(): 54 index = row[0] 55 print(words[index]) 56 57 if __name__=='__main__': 58 svdComponent()
運行結果
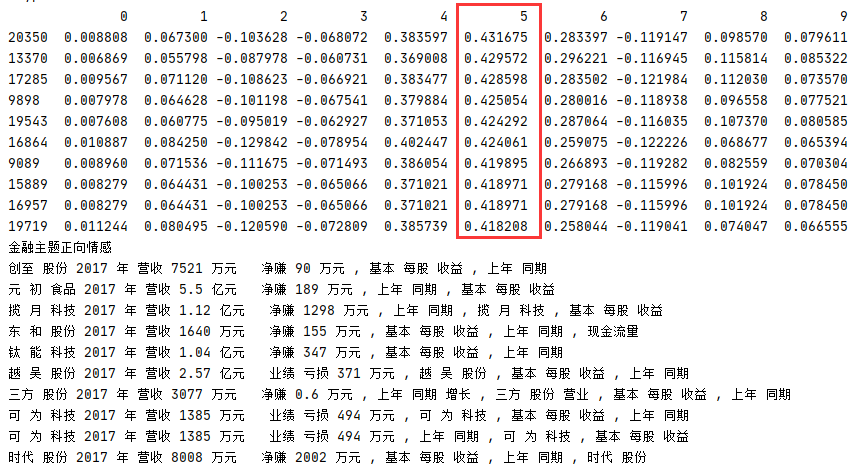
從運行結果可以看出,component 4 和 component 5 對金融主題的正向情感最高,嘗試列印主題 5 正向情感前10個最大值的內容
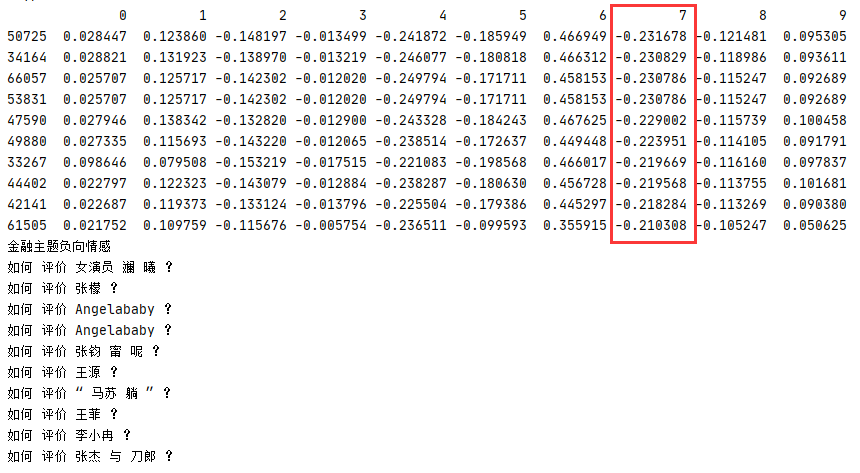
component 7 負向情感主題最高,列印主題 7 負向情感前 10 個最小值的內容,可見內容大部分是娛樂主題內容,與金融主題無關,
類似地也可以用娛樂關鍵字 entertainment ['電影', '范冰冰','電影節','活動','復仇者','粉絲','娛樂圈','明星'] 作為主題呼叫 svdComponentDisplay()方法進行資料篩選

進行主題轉換后查看 component 0 的娛樂正向情感資訊,可見內容基本上都是關于娛樂資訊

類似地查看 component 2 娛樂負向情感數量,大部分都是關于金融類的資訊
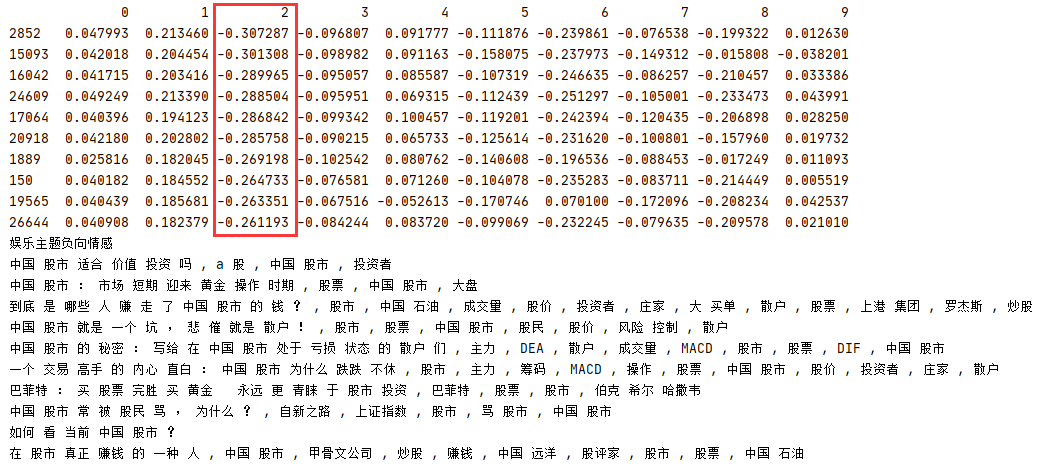
5.4 LDA 線性判別分析
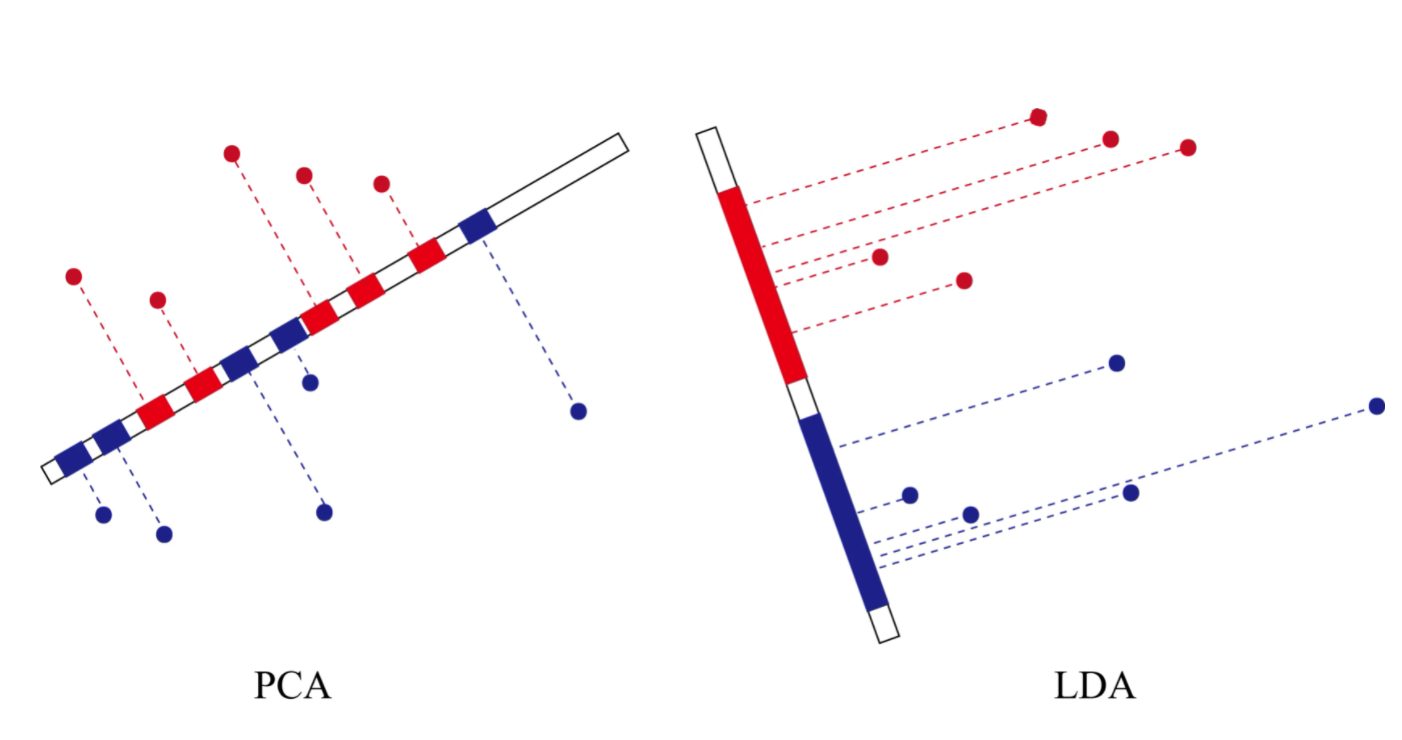
線性判別分析(Linear Discriminant Analysis,簡稱 LDA)是一種經典的資料主題分析方法,它與 LSA 最大區別在于 LDA 屬于監督學習模型,而 LSA 是無監督學習模型,LDA 的主要思想是將一個高維空間中的資料投影到一個較低維的空間中,且投影后要保證各個類別的類內方差小而類間均值差別大,這意味著同一類的高維資料投影到低維空間后相同類別會盡量聚在一起,而不同類別之間相距較遠,LDA 模型與 PCA 模型有點類似,然而最大區別在于:PCA方法尋找的是資料變化的主軸方向,從而根據主軸判別分析尋找的是用來有效分類的方向,這對樣本資料的主要變化資訊非常有效,然而卻忽略了次要變化的資訊,
而 LDA 模型是將高維樣本資料投影到低維度的向量空間,根據投影后的向量進行分類判斷,投影后希望每一種類別資料的投影點盡可能的接近,而不同類別的資料的類別中心之間的距離盡可能的大,
下圖就是將二維資料投影到一維直線上,里面顯示出 PCA 與 LDA 投影的區別:
5.5 LinearDiscriminantAnalysis 模型 在 sklearn 庫中提供了 sklearn.discriminant_analysis.LinearDiscriminantAnalysis 模型進行 LDA 線性分析,
1 class LinearDiscriminantAnalysis(LinearClassifierMixin, 2 TransformerMixin, 3 BaseEstimator): 4 def __init__(self, solver='svd', shrinkage=None, priors=None, 5 n_components=None, store_covariance=False, tol=1e-4, 6 covariance_estimator=None):
引數說明
- solver : str 型別 ['svd','lsqr',‘eigen’ ] 之一,默認為 ‘svd' ,選擇LDA超平面特征矩陣使用的方法,可以選擇的方法有奇異值分解"svd",最小二乘"lsqr"和特征分解"eigen",一般來說特征數非常多的時候推薦使用svd,而特征數不多的時候推薦使用eigen,如果使用 svd,則不能指定正則化引數shrinkage進行正則化,
- shrinkage:float 型別,或 [ 'auto',' None'] 正則化引數,默認為 None ,可以增強LDA分類的泛化能力,如果僅僅只是為了降維,則一般可以忽略這個引數,"auto" 代表讓演算法自己決定是否正則化,也可在 [0,1] 之間的值進行交叉驗證調參,該引數只在 solver 為"lsqr"和 "eigen" 時有效, 'svd' 時自動作廢,
- priors :array 陣列型別,默認為None,例如 [ n_class , ] ,用于定義類別權重,可以在做分類模型時指定不同類別的權重,進而影響分類模型建立,降維時一般不需要關注這個引數,
- n_components:int 型別,默認為 None ,即我們進行LDA降維時降到的維數,需要值必須小于輸入資料的維度減一,
- store_covariance:bool 型別,默認為 False,是否額外計算每個類別的協方差矩陣,
- tol:float 型別,默認為 1e-4,用它指定了用于SVD演算法中評判迭代收斂的閾值,
- warm_start:bool 型別,默認值為 False,當設定為True時,重用之前呼叫的解決方案作為初始化,否則,只需要洗掉前面的解決方案
- covariance_estimator:str 型別,[ 'covariance_estimator' 或 None ] 之一, 默認為None,如果不是 None,則使用 covariance_estimator 來估計協方差矩陣,而不是依賴于協方差估計器(具有潛在的收縮率),物件應具有擬合方法和 covariance_ 屬性,如 sklearn.covariance 中的估計器,如果為 None,則使用收縮率引數驅動估計值,
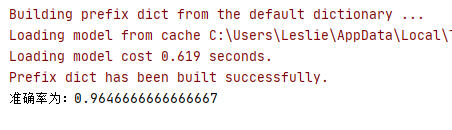
下面例子將使用 LinearDiscriminantAnalysis 模型對科技類文本和娛樂類文本進行分析,為了避免訓練時間過長,所以只拿了 4000 條資料進行訓練,把資料轉化為 TF-IDF 向量后,使用 LDA 模型進行訓練,只由只有 2 類,所以 n_components 設定為 1 即可,最后查看測驗結果,準確率已經在 90% 以上,
1 # 科技、娛樂的兩個文本路徑 2 paths=['C://Users/Leslie/Desktop/toutiao/news_finance.txt', 3 'C://Users/Leslie/Desktop/toutiao/news_entertainment.txt'] 4 # 科技類資訊標記為0,娛樂類資訊標記為1 5 result = [] 6 7 # 利用 jieba 轉換命令格式 8 def getWords(): 9 data =https://www.cnblogs.com/leslies2/archive/2022/03/28/ [] 10 type = 0 11 # 獲取路徑中的兩類檔案 12 for path in paths: 13 file=open(path,'r',1024,'utf-8').read() 14 #分行讀取,由于運行時間較長,所以只拿前2000條資料 15 sentences=np.array(file.split('\n'))[:2000] 16 # jieba 分詞,記錄分類結果 17 for sentence in sentences: 18 data.append(jieba.lcut(sentence)) 19 result.append(type) 20 type+=1 21 # 轉換中文分詞格式 22 words=[' '.join(word) for word in data] 23 return words 24 25 # 訓練 TF-IDF 向量 26 def getTfidfVector(): 27 tfidf = TfidfVectorizer() 28 # 獲取分詞 29 words=getWords() 30 # 訓練模型,回傳 TF-IDF 向量 31 vector=tfidf.fit_transform(words) 32 return vector.toarray() 33 34 def ldaTest(): 35 # 把 TF-IDF 向量切分為訓練資料與測驗資料 36 X_train,X_test,y_train,y_test=train_test_split(getTfidfVector(),result,random_state=22) 37 # 由于只是二分類,n_components 為 1 即可 38 lda=LDA(n_components=1) 39 # 訓練模型 40 lda.fit(X_train,y_train) 41 # 輸出準確率 42 y_model=lda.predict(X_test) 43 print('準確率為:{0}'.format(accuracy_score(y_test,y_model))) 44 45 if __name__=='__main__': 46 ldaTest()
運行結果
5.6 LDiA 隱性狄利克雷分布
隱性狄利克雷分布 ( Latent Dirichlet Allocation,簡稱 LDiA)與 LSA 類似也是一種無監督學習模型,但與相對于 LSA 的線性模型不同的是 LDiA 可以將檔案集中每篇檔案的主題按照概率分布的形式給出,從而更精確地統計出詞與主題的關系,
LDiA 假設每篇文章都是由若干個主題線性混合而成的,每個主題都是由若干個分詞組合而成,文章中每個主題的概率與權重以及每個分詞被分配到主題的概率都滿足 “ 狄利克雷概率 ” 的分布特征,估計這個也演算法命名的原因,其計算公式如下:
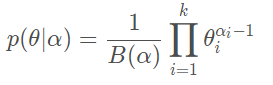
當中 B (α)為
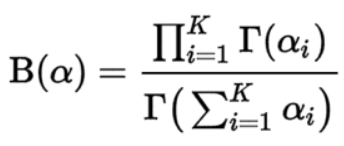
5.7 LatentDirichletAllocation 模型
在 sklearn 庫中提供了 sklearn.decomposition.LatentDirichletAllocation 模型進行 LDiA 分析
1 class LatentDirichletAllocation(TransformerMixin, BaseEstimator): 2 @_deprecate_positional_args 3 def __init__(self, n_components=10, *, doc_topic_prior=None, 4 topic_word_prior=None, learning_method='batch', 5 learning_decay=.7, learning_offset=10., max_iter=10, 6 batch_size=128, evaluate_every=-1, total_samples=1e6, 7 perp_tol=1e-1, mean_change_tol=1e-3, max_doc_update_iter=100, 8 n_jobs=None, verbose=0, random_state=None):
引數說明
- n_components:int 型別,默認為 10 ,即我們進行LDA降維時降到的維數,需要值必須小于輸入資料的維度減一,
- doc_topic_prior: float 型別,默認為None, 即狄利克雷概率計算公式中的 θ 引數, 如果為 None 即 θ 默認為 1/ n_components,
- topic_word_prior: float 型別,默認為None, 狄利克雷概率計算公式中的 α 引數 ,如果為 None 即 α 默認為 1/ n_components,
- learning_method: str 型別 {'batch', 'online'}之一,默認為 'batch',代表用于更新_component 的方法,如果資料量非常大時 ’online' 會比 ‘batch’ 運行更快,
- learning_decay:float 型別,默認值為 0.7 ,控制學習時的速率,僅在 learning 為 "online"時有效,取值一般在 [ 0.5, 1.0] 之間
- learning_offset:float 型別,默認值為10.0,用于降低學習早期迭代的權重,僅在 learning 為 "online"時有效,取值要大于1,
- max_iter:int 型別,默認值為 10,部分求解器需要通過迭代實作,這個引數指定了模型優化的最大迭代次數,
- batch_size: int 型別,默認為128,EM 迭代演算法時每次選擇的文本數,僅在 learning 為 "online" 時有效
- evaluate_every: int 型別,默認為-1,影響 fit 方法的運行,為 0 或負數時不會對訓練資料的模型指標,它可能幫助改善資料的收斂性,但也會影響訓練的效率,或許會延長訓練時間
- total_samples : int 型別, 默認為 1e6,輸入的檔案總數,只在方法 partial_fit() 中有效
- perp_tol:float 型別,默認為 1e-1, 指批量學習中的容忍度,僅在 evaluate_every 大于0時有效,
- mean_change_tol: float 型別,默認為 1e-3 , 即E步更新變分引數的閾值,所有變分引數更新小于閾值則E步結束,轉入M步
- max_doc_update_iter: int 型別,默認為 100,即E步更新變分引數的最大迭代次數,如果E步迭代次數達到閾值,則轉入M步,
- n_jobs:默認為 None,CPU 并行數,若設定為 -1 的時候,則用所有 CPU 的內核運行程式,
- verbose:日志冗長度,int型別,默認為0,就是不輸出訓練程序,1的時候偶爾輸出結果,大于1,對于每個子模型都輸出,
- random_state:亂數種子,推薦設定一個任意整數,同一個隨機值,模型可以復現,
LDiA 與 LSA 相似屬于無監督學習模型,常被用于情感分析與垃圾過濾等領域,下面例子將結合 LDiA 與 LDA 模型的特點,先將資訊進行主題轉換,把 4000 個短信轉換成200個主題,再進行資訊分類,
還是以上面的科技類文本和娛樂類文本作為例子,先進行 TF-IDF 向量轉換,再經過 LDiA 主題轉換,最后使用 LDA 進行訓練測驗,
1 # 科技、娛樂的兩個文本路徑 2 paths=['C://Users/Leslie/Desktop/toutiao/news_finance.txt', 3 'C://Users/Leslie/Desktop/toutiao/news_entertainment.txt'] 4 # 科技類資訊標記為0,娛樂類資訊標記為1 5 result = [] 6 7 # 利用 jieba 轉換命令格式 8 def getWords(): 9 data =https://www.cnblogs.com/leslies2/archive/2022/03/28/ [] 10 type = 0 11 # 獲取路徑中的兩類檔案 12 for path in paths: 13 file=open(path,'r',1024,'utf-8').read() 14 #分行讀取,為了避免訓練時間過長,只獲取 4000 行資料 15 sentences=np.array(file.split('\n'))[2000:4000] 16 # jieba 分詞,記錄分類結果 17 for sentence in sentences: 18 data.append(jieba.lcut(sentence)) 19 result.append(type) 20 type+=1 21 # 轉換中文分詞格式 22 words=[' '.join(word) for word in data] 23 return words 24 25 # 訓練 TF-IDF 向量 26 def getLdiaVector(): 27 tfidf = TfidfVectorizer() 28 # 獲取分詞 29 words=getWords() 30 # 訓練模型,回傳 TF-IDF 向量 31 vector=tfidf.fit_transform(words) 32 # 訓練 LDiA 模型,轉換為 200個主題 33 ldia=LDiA(n_components=200,doc_topic_prior=2e-3,topic_word_prior=1e-3,random_state=42) 34 return ldia.fit_transform(vector) 35 36 def ldaTest(): 37 # 把 TF-IDF 向量切分為訓練資料與測驗資料 38 X_train,X_test,y_train,y_test=train_test_split(getLdiaVector(),result,random_state=22) 39 # 由于只是二分類,n_components 為 1 即可 40 lda=LDA(n_components=1) 41 # 訓練模型 42 lda.fit(X_train,y_train) 43 # 輸出準確率 44 y_model=lda.predict(X_test) 45 print('準確率為:{0}'.format(accuracy_score(y_test,y_model))) 46 47 if __name__=='__main__': 48 ldaTest()
運行結果
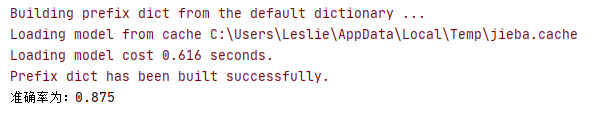
雖然準確率只有 87%,遠遠不如直接使用 LDA 模型,但 LDiA 模型依然可以幫助用戶從一個小型的訓練集中泛化出模型,處理不同詞的組合,
回到目錄
六、詞嵌入的應用
至今為止,文章的代碼都是使用 sk-learn 機器學習作為基礎的,其實自然語言處理在 Tensonflow 深度學習中應用更廣,下面將從基礎知識入手,介紹 NLP 在深度學習的應用,
6.1 詞嵌入原理
在機器學習中會利用 TF-IDF 等向量進行計算,而在Tensorflow 中常用詞嵌入的方式進行計算,獲取詞嵌入的方式有兩種,一種是通過詞向量進行模型訓練學習得來,另一種通過預訓練模型把預先計算好詞嵌入,然后將其加入模型中,也稱為預訓練詞嵌入,常用的預訓練詞嵌入有 Word2doc、GloVe、Doc2vec 等,
Tensorflow 中準備 Embedding 層進行詞嵌入,相比起傳統的 one-hot 編碼,它提供了低維度高密集型的詞向量,其主要引數如下,其中最常用到的是 input_dim,output_dim,input_length 這3個引數,input_dim 是代表最大可插入的分詞個資料,output_dim 是代表對分詞特征分析的維度,這個引數需要根據分詞數量而定,input_length 是限制單個測驗物件的最大分詞數量,若單個測驗物件超出此單詞數系統將會自動截取,
1 @keras_export('keras.layers.Embedding') 2 class Embedding(Layer): 3 def __init__(self, 4 input_dim, 5 output_dim, 6 embeddings_initializer='uniform', 7 embeddings_regularizer=None, 8 activity_regularizer=None, 9 embeddings_constraint=None, 10 mask_zero=False, 11 input_length=None, 12 **kwargs):
引數說明:
- input_dim:int 型別,大或等于0 的整數,代表作為特征的分詞個數
- output_dim:int 型別,大于0的整數,代表全連接嵌入的維度
- embeddings_initializer: 嵌入矩陣的初始化方法,為預定義初始化方法名的字串,或用于初始化權重的初始化器,可參考keras.initializers
- embeddings_regularizer: 嵌入矩陣的正則項,為Regularizer物件
- embeddings_constraint: 嵌入矩陣的約束項,為Constraints物件
- mask_zero:bool 型別,默認為 False,用于確定是否將輸入中的‘0’看作是應該被忽略的‘填充’(padding)值,該引數在使用遞回層處理變長輸入時有用,設定為True的話,模型中后續的層必須都支持masking,否則會拋出例外,如果該值為True,則下標0在字典中不可用,input_dim應設定為|vocabulary| + 2,
- input_length:int 型別,默認為 None,限制每個插入物件最大單詞數量,每行資料不足此數量會自動加入0 作為補充,超過此資料會截斷后面的值,如果要在該層后接Flatten層,然后接Dense層,則必須指定該引數,否則Dense層的輸出維度無法自動推斷,
要使用 Embedding 層首先要對資料進行一下轉換,例如上面例子的中文分詞原來為下面格式

現在需要把文本轉換為編碼的格式,然后才能作為 Embedding 的輸入資料

下面的例子繼續使用科技、娛樂兩類檔案作為測驗資料,先利用 jieba 作分詞處理,然后呼叫 getEncode 方法進行自編碼,把中文單詞字串轉換成數字編碼,再建立 Model 使用 Embedding 嵌入詞進行測驗,注意通過詞嵌入后需要進行 Flatten 拉直后再進行計算,
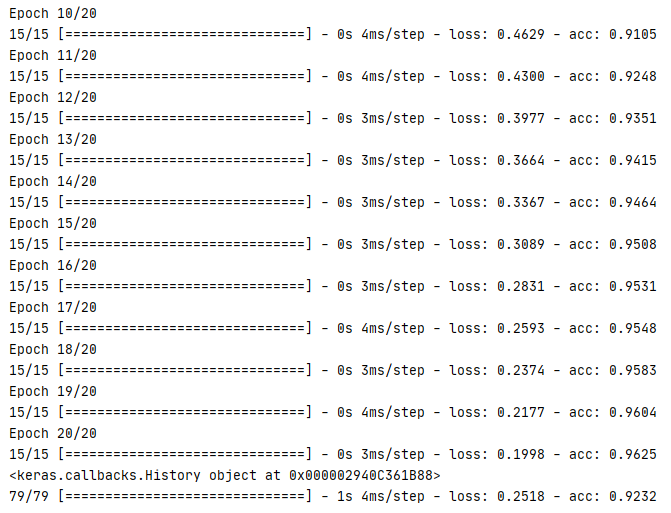
在此例子中使用了 10000 個單詞,由于是短文本,所以把 input_length設定為 10 個單詞,而且只通過一個 Dense 層,準確率已經達到 90 % 以上,
1 # 科技、娛樂的兩個文本路徑 2 paths=['C://Users/Leslie/Desktop/toutiao/news_finance.txt', 3 'C://Users/Leslie/Desktop/toutiao/news_entertainment.txt'] 4 # 科技類資訊標記為0,娛樂類資訊標記為1 5 result = [] 6 # 最大單詞數 7 max_features=10000 8 # 單個陳述句最大的詞數量限制 9 maxlen=10 10 11 # 利用 jieba 轉換命令格式 12 def getWords(): 13 data =https://www.cnblogs.com/leslies2/archive/2022/03/28/ [] 14 type = 0 15 # 獲取路徑中的兩類檔案 16 for path in paths: 17 file=open(path,'r',1024,'utf-8').read() 18 #分行讀取,讀取前 5000 行資料 19 sentences=np.array(file.split('\n'))[:5000] 20 # jieba 分詞,記錄分類結果 21 for sentence in sentences: 22 data.append(jieba.lcut(sentence)) 23 result.append(type) 24 type+=1 25 return data 26 27 # 自編碼 28 def getEncode(): 29 # 獲取所有分詞 30 sentences=getWords() 31 encode=list() 32 words= {} 33 index=0 34 # 回圈所有句子 35 for sentence in sentences: 36 array = [] 37 # 把分詞轉換成編碼 38 for key in sentence: 39 if key not in words: 40 words[key]=index 41 index+=1 42 array.append(words[key]) 43 # 記錄每個句子的編碼 44 encode.append(array) 45 # 回傳自編碼 46 return encode 47 48 # Model 49 def getModel(): 50 model=Sequential() 51 model.add(Embedding(max_features,20,input_length=maxlen)) 52 model.add(Flatten()) 53 model.add(Dense(1,activation='sigmoid')) 54 model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc']) 55 model.summary() 56 return model 57 58 def test(): 59 model=getModel() 60 # 獲取句子的編碼 61 encodes=getEncode() 62 X_train,X_test,y_train,y_test=train_test_split(encodes,np.array(result),random_state=22) 63 X_train=preprocessing.sequence.pad_sequences(X_train,maxlen=maxlen) 64 X_test=preprocessing.sequence.pad_sequences(X_test,maxlen=maxlen) 65 # 輸出準確率 66 history=model.fit(X_train,y_train,epochs=20,batch_size=500) 67 print(history) 68 model.fit(X_test,y_test) 69 70 if __name__=='__main__': 71 test()
運行結果
上面例子中的詞嵌入都是通過詞頻統計計算出來了,而了 21 世紀初 Bengio 等人提出一種新演算法 NNLM(Nerual Network Language Model),就是通過無監督學習的方式預先計算出一個低維詞向量,然后把向量直接加載 Embedding 層,這樣就可以大大減小的模型的訓練時間與語料搜集的難度,最常見的預訓練詞嵌入有 Word2vec 和 GloVe,
6.2 Word2vec 原理與應用
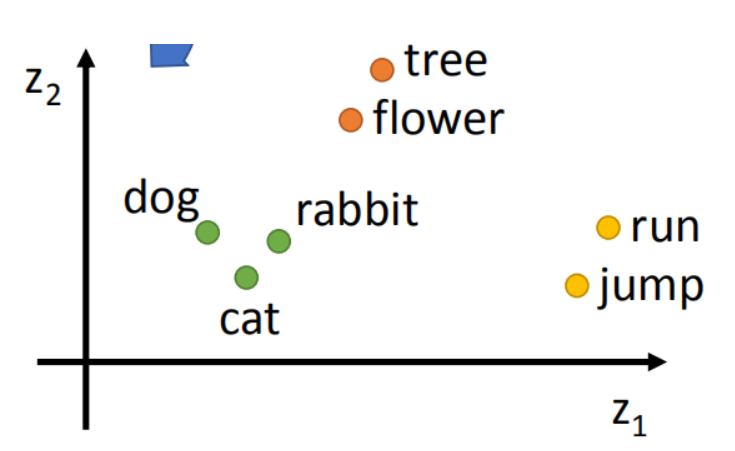
Word2vec 同 Google 的 Tomas Mikolov 于 2013 年研發,它是通過無監督學習訓練而成,因此訓練資料不需要人工組織、結構化和標注,這對于 NLP 來說可以說是非常完美,Word2vec 與其他詞向量相似,以向量來衡量詞語之間的相似性以及相鄰的詞匯是否相識,這是基于語言學的“距離相似性” 原理,“距離相似性” 可以用詞向量的幾何關系可以代表這些詞的關系,用兩個詞之前的距離長短來衡量詞之間的關系,如果把詞向量的多維關系轉化為二維映射或者會更容易理解,如下圖 dog 、cat、rabbit 的相對更為接近,所以被是認為有一定的關系,
6.2.1 Word2vec 模型
在 gensim 庫中,包含了最常用的 gensim.models.word2vec.Word2Vec 模型,在使用 Word2vec 模型前,首先要對模型進行預訓練,由于各國有不同的文化差異,所以需要準備不同的語料庫,詞料庫資訊越全面,訓練出來的模型準確性就會越高,
1 class Word2Vec(utils.SaveLoad): 2 def __init__( 3 self, sentences=None, corpus_file=None, vector_size=100, alpha=0.025, window=5, min_count=5, 4 max_vocab_size=None, sample=1e-3, seed=1, workers=3, min_alpha=0.0001, 5 sg=0, hs=0, negative=5, ns_exponent=0.75, cbow_mean=1, hashfxn=hash, epochs=5, null_word=0, 6 trim_rule=None, sorted_vocab=1, batch_words=MAX_WORDS_IN_BATCH, 7 compute_loss=False, callbacks=(),comment=None, max_final_vocab=None, shrink_windows=True, 8 )
引數說明
- sentences: iterable 或 optional 默認為 None ,以此引數匯入要訓練的語料,它是一個可迭代物件,由于語料庫往往比較大,匯入時建議使用 Text8Corpus 、LineSentence
- corpus_file: str 型別,可以直接輸入 LineSentence 檔案路徑來匯入要訓練的語料,以此引數代替 sentences 可以提升讀入效率,sentences 和 corpus_file 必需填入一個,否則系統會報錯
- vector_size:int 型別,默認值為 100,表示訓練后輸出向量的維度
- alpha:float型別,默認值為 0.025,表示初始學習率
- window:int 型別,默認為 5,表示句子中當前和預測單詞之間的最大距離,取詞視窗大小
- min_count:int 型別,默認為 5 ,表示檔案中總頻率低于此值的單詞會被忽略,如果檔案總詞數低于此值系統將會被錯
- max_vocab_size:int 型別,默認為 None ,表示構建詞匯表最大數,詞匯大于這個數按照頻率排序,去除頻率低的詞匯
- sample:float 型別,默認為 1e-3 ,表示高頻詞進行隨機下采樣的閾值,范圍是(0, 1e-5)
- seed :int 型別,默認為1 ,向量初始化的亂數種子
- workers:int 型別,默認為3,同時運行的 的 CPU 數
- min_alpha:float 型別,默認為 0.0001, 隨著學習進行,學習率線性下降到這個最小數
- sg :int 型別,默認為 0,訓練時演算法選擇 0 為 skip-gram, 1 為 CBOW
- hs : int 型別,默認為 0,當 hs為 0 并且 negative 引數不為零j時,用負采樣,為一時 使用 softmax
- negative:int 型別,默認為 5,使用負采樣,大于 0 是使用負采樣, 負數值就會進行增加噪音詞
- ns_exponent:float 型別,默認為 0.75 ,表示負采樣指數,確定負采樣抽樣形式:1.0:完全按比例抽,0.0 對所有詞均等采樣,負值對低頻詞更多的采樣,
- cbow_mean:int 型別,默認為 1,用于選擇 CBOW 的計算方式, 0 代表使用背景關系單詞向量的總和,1 表示使用均值; 只有使用 CBOW 演算法時適用,skip-gram 時忽略此引數
- hashfxn:運算式函式,默認為 hash 希函式,用于隨機初始化權重,以提高訓練的可重復性,
- epoch :int 型別,默認為 5 ,代表迭代次數
- null_word: 默認為 0 空填充資料
- trim_rule:運算式函式,默認為 None ,代表詞匯修剪規則,指定某些詞語是否應保留在詞匯表中,默認是詞頻小于 min_count 則丟棄,可以是自己定義規則
- sorted_vocab :int 型別,默認為1 ,表示排序規則,1 代表按照降序排列,0 表示不排序;實作方法:gensim.models.word2vec.Word2VecVocab.sort_vocab()
- batch_words:int 型別,默認為 10000 ,表示每批次最大的詞數量,大于10000 cython 會進行截斷
- compute_loss:bool 型別,默認為 False, 是否保存損失函式值,False 為不保存,True 就會保存
- callbacks : 表示式函式,默認為(),表示在訓練期間的特定階段執行的回呼序列 gensim.models.callbacks.CallbackAny2Vec
- max_final_vocab:默認為None 通過自動選擇匹配的 min_count 將詞匯限制為目標詞匯大小,如果 min_count 有引數就用給定的數值
- shrink_window: bool 型別,默認為 True,4.1 版本新引數,若為 True,始終在視窗最左側 [1,‘window’] 作為引數對背景關系單詞的距離進行位置權重計算,若為 Flase 則以中間項為標準進行計算,
訓練 Word2vec 訓練前先要做好準備,在 https://dumps.wikimedia.org/zhwiki/latest/ 網上可以找到最新的中文語料庫,可以根據需求下載,由于下載的是 *.bz2 的壓縮檔案,而包含簡體/繁體多種字型,所以讀取時首先利用 WikiCorpu 要對檔案進行解壓,由于中文單詞與國外有所區別,所以完成解壓后,需要利用 jieba 進行分詞處理,處理期間可通過 zhconv 把繁體字轉換成簡體字,完成轉換后保存資料,
格式轉換后可開始對 Word2Vec 模型進行預訓練,由于資料量通常比較大,建議完成預訓練后使用 Word2Vec.save (path) 方法保存模型,方便下次直接使用 Word2Vec.load(path) 重新加載,路徑最好通過 os.path 生成,直接寫入絕對路徑容易報錯,
1 # 定議下載后壓縮檔案的路徑,解壓轉換為簡體的新文本路徑 2 wikipath = 'E://Tools/words/word2vec/zhwiki-latest-pages-articles.xml.bz2' 3 filepath = 'E://Tools/words/word2vec/wiki.simple.txt' 4 modelpath = 'E://Python_Projects/ANN/venv/word2ver_wiki_cn.model' 5 6 if __name__=='__main__': 7 convert() 8 saveModel() 9 10 def saveModel(): 11 # 通過 os.path 獲取路徑避免引起LineSentence路徑錯誤 12 sentencesPath = os.path.abspath(filepath) 13 modelPath = os.path.abspath(modelpath) 14 # 生成逐行讀取物件 LineSentence 15 sentences = LineSentence(sentencesPath) 16 # 建議 word2vec 物件進行學習 17 model = Word2Vec(sentences, window=8, min_count=5, workers=10) 18 # 保存模型 19 model.save(modelPath) 20 21 def convert(): 22 # 定義寫入檔案物件 23 write=open(filepath,'w',10240,'utf-8') 24 # 讀取 bz2 壓縮檔案 25 wiki = WikiCorpus(wikipath) 26 # 分行讀取 27 for sentences in wiki.get_texts(): 28 data=https://www.cnblogs.com/leslies2/archive/2022/03/28/'' 29 # 分句讀取 30 for sentence in sentences: 31 # 把繁體字轉換為簡體字 32 simpleSentence=zhconv.convert(sentence,'zh-cn') 33 # 通過 jieba 進行分詞 34 for word in jieba.lcut(simpleSentence): 35 data+=word+' ' 36 # 換行 37 data+='\n' 38 # 寫入檔案 39 write.write(data)
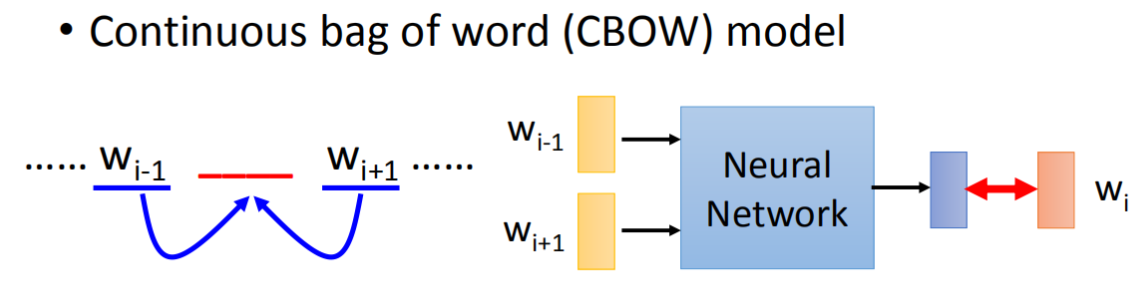
訓練 Word2vec 有兩種方法 Skip-gram 方法和 CBOW(continuous bag-of-words)連續詞袋,可以通過 sg 引數選擇演算法,0 為 skip-gram, 1 為 CBOW,默認使用 skip- gram
Skip-gram 演算法是通過輸入單詞預測周邊的詞
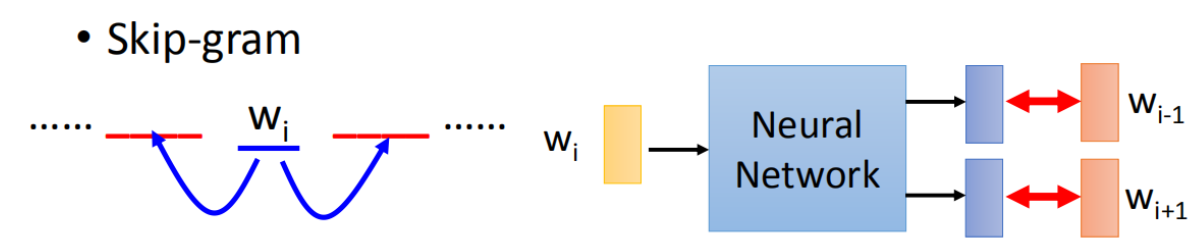
CBOW 演算法則是基于鄰近的詞預測目標詞
6.2.2 KeyedVectors 詞向量的常用方法
完成 Word2Vec 模型的預訓練后,可以通過 Word2Vec.load(path) 重新加載訓練好的模型, 通過 Word2Vec.wv 可獲取訓練后的詞向量物件 KeyedVectors,
KeyedVectors 詞向量物件有下面幾種常用的方法
6.2.2.1 獲取 keyedVectors 向量值
通過 wv.vectors 可以獲取模型的全域向量,通過 wv [ '向量名‘ ] 可以獲取對應的向量,由于 vector_size 默認維度是100,所以每個向量也是一個 1 * 100 的陣列 ,
1 modelPath=os.path.abspath('E://Python_Projects/ANN/venv/word2ver_wiki_cn.model') 2 model=Word2Vec.load(modelPath) 3 print( model.wv[ '朱元璋' ])
運行結果

若要進行組合向量查詢,可直接通過向量疊加完成,例如若要查詢 “唐朝的名詩及其作者” 等可以通過下面的等式完成
vector= wv['唐朝']+wv['詩人‘]+wv[’作品']
若發現結果中不僅包含有詩人和作品,還有其他朝代等資訊,即可通過減法排除
vector= wv['唐朝']+wv['詩人‘]+wv[’作品']-wv['朝代']
6.2.2.2 向量相鄰詞 most_similar
方法 wv. most_similar( positive=None, negative=None, topn=10)可根據給定的向量查詢其相鄰的詞,其中 positive 是代表捕捉相關的向量詞組合,topn是默認回傳前10個詞,negative 是代表要排除的向量詞,從例子中可以看,以 “唐朝” 查詢到的大多都是不同的朝代,但排除 “朝代”關系后,顯示的變成唐朝人物 “羅弘信” 等,地區 “魏州” 等資訊,選擇了“唐朝”和 ”皇帝“ 再排除 “朝代” 資訊后,還有會有 “唐玄宗”,“唐高宗”,“武則天” 等皇帝資訊,
1 modelPath=os.path.abspath('E://Python_Projects/ANN/venv/word2ver_wiki_cn.model') 2 model=Word2Vec.load(modelPath) 3 4 list0=model.wv.most_similar(positive=['唐朝'],topn=10) 5 print(list0) 6 list1=model.wv.most_similar(positive=['唐朝'],negative=['朝代'],topn=10) 7 print(list1) 8 list2=model.wv.most_similar(positive=['唐朝','皇帝'],topn=10) 9 print(list2)
運行結果

6.2.2.3 檢測不相關詞 doesnt_match
通過 wv.doesnt_match(words) 可監測多個詞組合中不相關的詞,例如通過 wv.doesnt_match(['唐朝','李世民','詩詞','計算機']),系統會測驗出 計算機
6.2.2.4 余弦相似度計算 most_similar
通過 wv.most_similarity(w1,w2) 可以計算出給定兩個詞之間的余弦相似充,例如通過 wv.similarity('唐太宗','李世民'),計算出的相鄰度為 0.78733486
6.2.2.5 詞頻查詢 expandos
在 gensim 4.0 以上版本,系統已用 wv.expandos 代替 wv. vocab,可以通過此屬性可查詢每個分詞的數量等資訊
6.2.3 Word2Vec 在 Embedding 層的應用
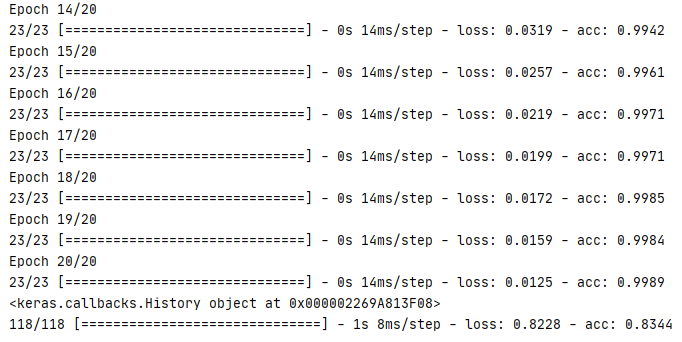
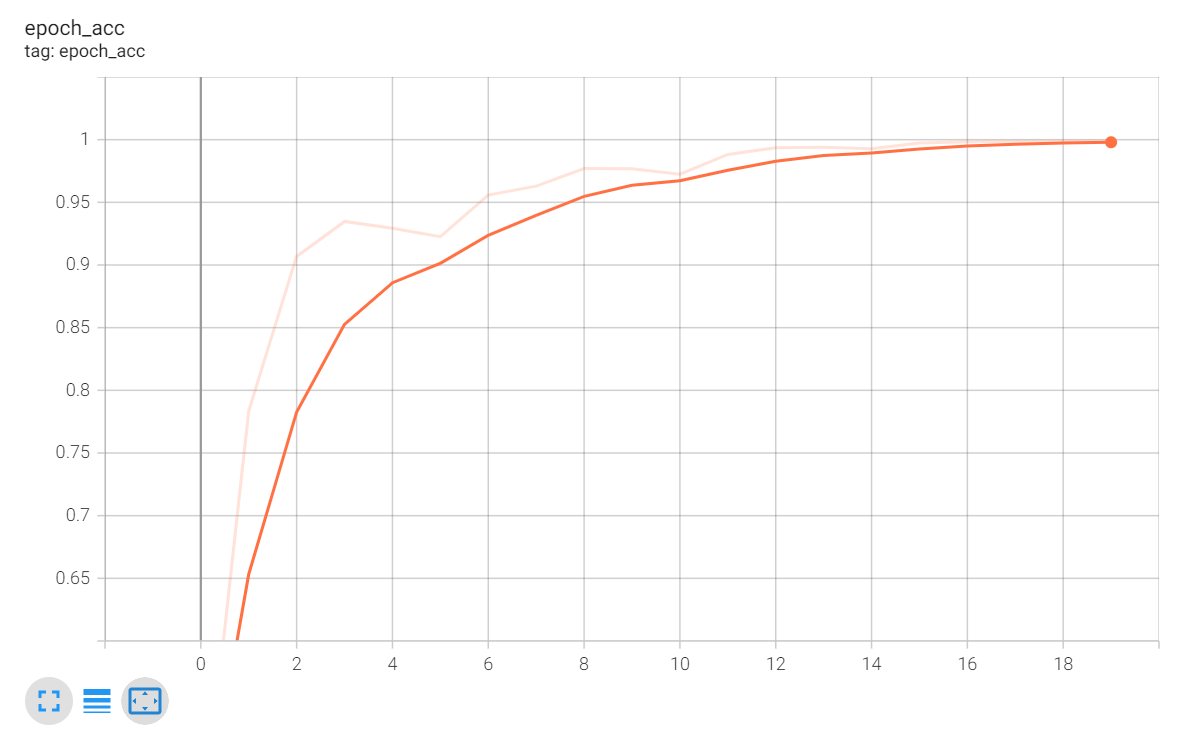
在模型的 Embedding 層中,可以使用預訓練的 word2vec 使用提升模型的準確性,通過 https://www.cluebenchmarks.com/ 網站下載分類測驗資料,里面有 16 大類的今日頭條APP里面的檔案,以 paths 陣列記錄不同型別的文本路徑,利用 jieba 進行分詞處理,然后呼叫 getWord()把分詞進行編碼處理,處理后的分詞及編碼記錄在 dict 全域變數 words 中,再通過 getEmbedding() 方法,把預訓練后的分量加入入 Embedding 層,把該層的 trainable 設定為 False ,讓訓練時資料不會影響 word2vec 的向量值,最后進行模型測驗,可以看到簡單的三層模型測驗資料準確率可達到 80% 以上,已經相當不錯了,
1 # 科技、娛樂、文學等16類文本路徑 2 paths=['C://Users/Leslie/Desktop/toutiao/news_finance.txt', 3 'C://Users/Leslie/Desktop/toutiao/news_entertainment.txt', 4 'C://Users/Leslie/Desktop/toutiao/news_culture.txt', 5 ..........] 6 # 記錄型別標記 0,1,2,3... 7 result = [] 8 # 記錄分詞與其對應編碼 9 words = {} 10 # 定義 maxlen 超過100個截取 11 maxlen=100 12 # 定義向量主題數 13 vector_size=100 14 15 # 利用 jieba 轉換命令格式 16 def getWords(): 17 data =https://www.cnblogs.com/leslies2/archive/2022/03/28/ [] 18 type = 0 19 # 獲取路徑中的16類檔案 20 for path in paths: 21 file=open(path,'r',1024,'utf-8').read() 22 #分行讀取 23 sentences=np.array(file.split('\n'))[:5000] 24 # jieba 分詞,記錄分類結果 25 for sentence in sentences: 26 data.append(jieba.lcut(sentence)) 27 result.append(type) 28 type+=1 29 return data 30 31 # 自編碼 32 def getEncode(): 33 # 獲取所有分詞 34 sentences=getWords() 35 encode=list() 36 index=0 37 # 回圈所有句子 38 for sentence in sentences: 39 array = [] 40 # 把分詞轉換成編碼 41 for key in sentence: 42 if key not in words: 43 words[key]=index 44 index+=1 45 array.append(words[key]) 46 # 記錄每個句子的編碼 47 encode.append(array) 48 # 回傳自編碼 49 return encode 50 51 # 獲取word2vec中對應的向量生成 Embedding 陣列 52 def getEmbedding(): 53 # 加載訓練好的 word2vec 模型 54 modelPath=os.path.abspath('E://Python_Projects/ANN/venv/word2ver_wiki_cn.model') 55 model=Word2Vec.load(modelPath) 56 # 向量初始化 57 embedding=np.zeros((len(words), vector_size)) 58 # 若word2vec有此分詞則加載此向量,若沒有則設定為0 59 for key,value in words.items(): 60 if model.wv.__contains__(key): 61 embedding[value]=model.wv.get_vector(key) 62 return embedding 63 64 # 生成Model 65 def getModel(): 66 model=Sequential() 67 model.add(Embedding(len(words),vector_size,input_length=maxlen)) 68 model.add(Flatten()) 69 model.add(Dense(500,activation='relu')) 70 model.add(Dense(100,activation='relu')) 71 model.add(Dense(3,activation='sigmoid')) 72 model.compile(optimizer=optimizers.Adam(0.003), 73 loss=losses.sparse_categorical_crossentropy, 74 metrics=['acc']) 75 model.summary() 76 return model 77 78 def test(): 79 # 獲取句子的分詞編碼 80 encodes=getEncode() 81 # 獲取模型 82 model=getModel() 83 # 在 Embedding 層加入預訓練好的 word2vec 模型 84 model.layers[0].set_weights([getEmbedding()]) 85 # 訓練時不修改 word2vec 模型中的向量 86 model.layers[0].trainable=False 87 # 分拆訓練資料與測驗資料 88 X_train,X_test,y_train,y_test=train_test_split(encodes,np.array(result),random_state=60) 89 X_train=preprocessing.sequence.pad_sequences(X_train,maxlen=maxlen) 90 X_test=preprocessing.sequence.pad_sequences(X_test,maxlen=maxlen) 91 # 輸出準確率 92 callback= keras.callbacks.TensorBoard(log_dir='logs') 93 history=model.fit(X_train,y_train,epochs=20,batch_size=500,callbacks=callback) 94 print(history) 95 model.fit(X_test,y_test) 96 97 if __name__=='__main__': 98 test()
運行結果
Tensorborad 準確率
6.3 GloVe 詞嵌入
除了 Word2Vec 庫,另一個常用的庫就是 GloVe(Global Vectors for Word Representation),它是由斯坦福大學研究人員在 2014 年開發的,這種嵌入方法基于全詞頻統計的方式對分詞進行了全域矩陣因式分解,它可以直接把單詞表達成實數向量,這些向量捕捉到了單詞之間一些語意特性,比如相似性(similarity)、類比性(analogy)等,通過對向量的運算,比如歐幾里得距離或者cosine相似度,可以計算出兩個單詞之間的語意相似性,
GloVe 庫的應用與 Word2Vec 類似,可以直接通過網路下載語料庫,對 GloVe 進行預訓練,然后保存模型,再把從 Embedding 層注入預訓練好的向量,對數量進行測驗,若要在 window 10 或以上版本中使用 Glove,建議使用 glove_python 包,首先必須先安裝 GCC (可通過 Homebrew 下載對應版本)和 Visual Studio Build Tool 14 以上版本,然后通過 pip install glove_python 執行安裝(也可鏈接 GitHub:glove_python-0.1.0-cp37-cp37m-win_amd64.zip 直接下載安裝包),
GloVe 常用方法如下
1 #準備資料集 2 sentense = [['摘要','人工智能','AI','開發'],['我們','是','機器人'],......] 3 corpus_model = Corpus() 4 corpus_model.fit(sentense, window=10) 5 #訓練 6 glove = Glove(no_components=100, learning_rate=0.05) 7 glove.fit(corpus_model.matrix, epochs=10, 8 no_threads=1, verbose=True) 9 glove.add_dictionary(corpus_model.dictionary) 10 #模型保存 11 glove.save('glove.model') 12 glove = Glove.load('glove.model') 13 #語料保存 14 corpus_model.save('corpus.model') 15 corpus_model = Corpus.load('corpus.model')
完成訓練后,使用 Glove.load() 就可以重新加載,然后把向量加載到 Embedding 層,使用方式與 Word2Vec 非常類似,在此就不再做重復介紹,
利用 gensim.scripts.glove2word2vec 還可以把 glove 向量轉化為 Word2Vec 向量使用
1 # 用于轉換并加載glove預訓練詞向量 2 from gensim.test.utils import datapath, get_tmpfile 3 from gensim.models import KeyedVectors 4 # 將glove轉換為word2vec 5 from gensim.scripts.glove2word2vec import glove2word2vec 6 7 path='檔案夾路徑' 8 glove_file=datapath(os.path.join(path, "glove.txt")) 9 word2vec_file=get_tmpfile(os.path.join(path,"word2vec.txt")) 10 glove2word2vec(glove_file, word2vec_file)
回到目錄
本章總結
本文介紹了 NLP 自然語言處理的理論與實作方法,以 One-Hot、TF-IDF、PageRank 為基礎的演算法,講述 LDA、LDiA、LSA 等語意分析的原理,介紹 Jieba 分詞工具的中文文本中的應用,以及Word2Vec、GloVe 等預訓練模型,
其實本文講述的 NLP 在 Embedding 中的應用只是冰山一角,自然語言處理在回圈神經網路 RNN 中才能真正發揮其優勢,在下篇文章 《 TensorFlow 2.0 深度學習實戰 —— 回圈神經網路 RNN 》 會從實用的角度更深入地介紹 NLP 的應用場景,敬請留意,
希望本篇文章對相關的開發人員有所幫助,由于時間倉促,錯漏之處敬請點評,
對 .Python 開發有興趣的朋友歡迎加入QQ群:790518786 共同探討 !
對 JAVA 開發有興趣的朋友歡迎加入QQ群:174850571 共同探討!
對 .NET 開發有興趣的朋友歡迎加入QQ群:162338858 共同探討 !
AI人功智能相關文章
Python 機器學習實戰 —— 監督學習(上)
Python 機器學習實戰 —— 監督學習(下)
Python 機器學習實戰 —— 無監督學習(上)
Python 機器學習實戰 —— 無監督學習(下)
Tensorflow 2.0 深度學習實戰——介紹損失函式、優化器、激活函式、多層感知機的實作原理
TensorFlow 2.0 深度學習實戰 —— 淺談卷積神經網路 CNN
NLP 自然語言處理實戰
作者:風塵浪子
https://www.cnblogs.com/leslies2/p/15976351.html
原創作品,轉載時請注明作者及出處
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/451318.html
標籤:其他