
導讀:今天給大家分享的主題是搜索匹配問題在 DiDi Food 中的一些探索與應用,本文首先介紹了搜索相關性的一些背景,之后介紹了業界常見的三種匹配模型,以及在DiDi Food業務中的模型效果對比,
匹配模型包括:1. 基于表征的深度匹配模型;2. 基于互動的深度匹配模型;3. 同時基于表征與互動的深度模型,文章最后會介紹目前搜索匹配演算法在 DiDi Food 業務中的一些效果,
1. 搜索相關性
搜索相關性模型本質上是一個匹配的程序,即用戶通過一個具體請求,例如發送一個 query 來抽取想要得到的資訊,搜索引擎就是要將用戶的意圖與網站的資訊做一個匹配來回傳給用戶,具體到 DiDi Food 的業務場景中就是:用戶輸入 query 進行搜索后,搜索引擎將與用戶 query 匹配的店鋪、菜品回傳給用戶,這個程序可以抽象為一個 query-doc 的語意間隔匹配問題,
語意匹配
語意匹配與傳統的字符匹配同屬于傳統的 NLP 文本匹配任務,區別在于語意匹配不一定要求兩端文本上存在相同的單詞,更關注兩段文本在表達意思上是否滿足目標任務,
這里通過下表具體解釋兩者的區別:

在一般的語意匹配演算法中,訓練資料為 label 好的 query-doc 關系組,目標函式為 f(q,d)或 P(r|q,d),分別對應判別模型和生成模型,query 和 doc 一般通過對應的特征向量或 one-hot-id,label 可以是[0,1]這樣的離散值,也可以是連續的數值得分,
Matching vs. Ranking
在一般的搜索與推薦任務中,目前業界主流的做法都是根據業務目標將其拆解為匹配問題(很多稱為召回問題)和排序問題,
在搜索中,匹配問題的目標通常是要解決 query-doc 的相關性,即 query-doc 的語意間隔問題,它的輸入往往是 query 和某一特定的 doc,Matching 的難點在于找到正確的匹配 case,剔除錯誤的匹配 case,
排序問題的目標通常是要解決串列序的問題,它的輸入往往是一系列的 doc,Ranking 的難點在于將正確或轉化率高的元素放到串列的頭部,
在 DiDi Food 的業務場景中也根據匹配與排序問題的不同分為策略粗排與策略精排兩部分,
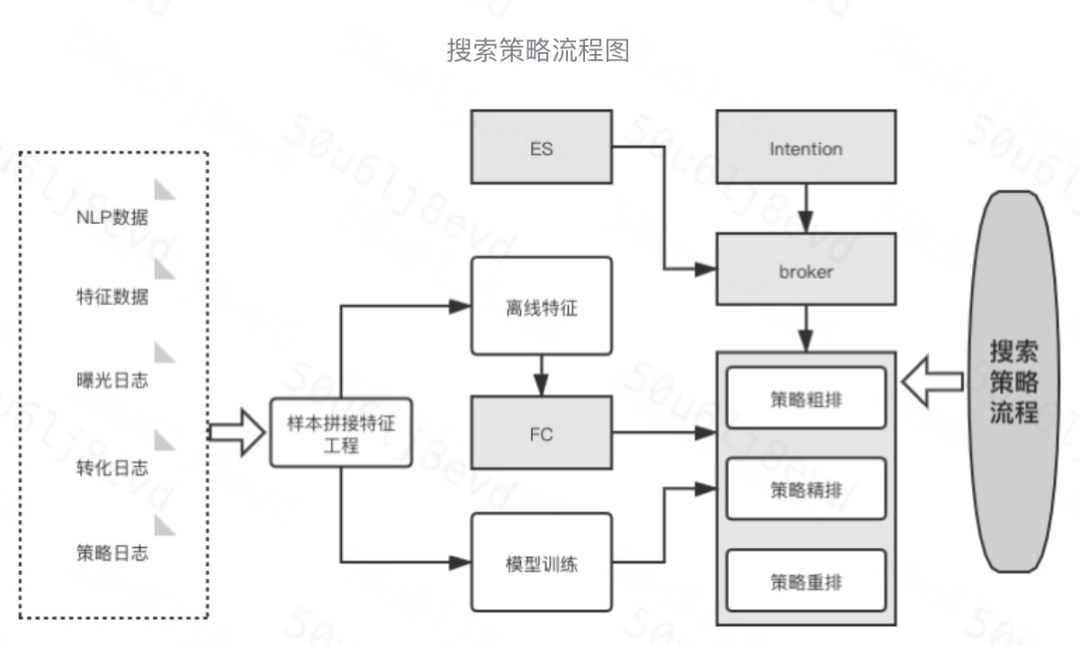
-
通過意圖模塊對用戶的意圖進行分析,其中包括 query 糾錯、同近義詞擴展等,
-
broker 通過 ES 將店帶菜進行召回,策略對所有召回店帶菜做搜索粗排,這里屬于匹配演算法,目標找到相關性較高的店帶菜,
-
將粗排結果的 top N 個店帶菜做搜索精排,這里屬于轉化率模型,目標提高用戶的下單轉化,
-
對店帶菜做搜索重排,這里主要包括一些產品規則等,最后將結果透傳回 broker
2. 深度匹配演算法#
相較于傳統的匹配演算法,例如 TF-IDF, LSA, BM25 等,DiDi Food 在搜索場景中探索了業界主流的幾種深度模型,我們把常見的用于匹配的深度學習模型分為三類,包括:基于 representation 表征的深度模型,基于interaction互動的深度模型以及同時基于表征與互動的深度模型,
為方便后文介紹,這里先區別以下幾個概念:
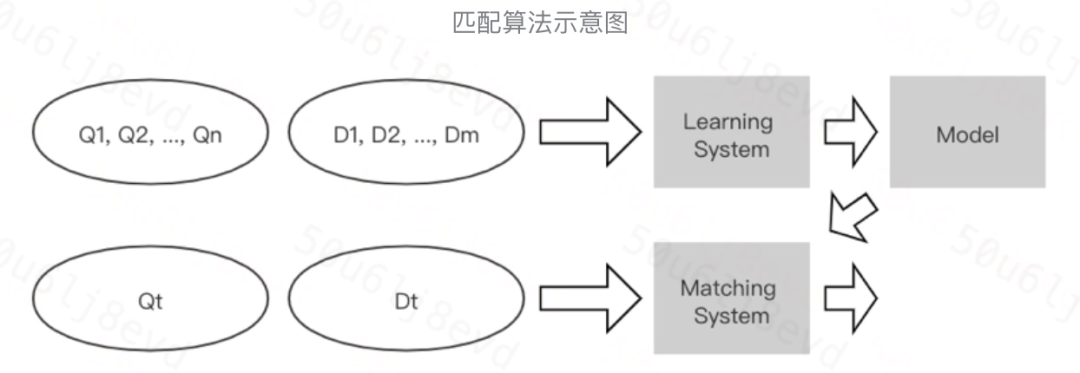
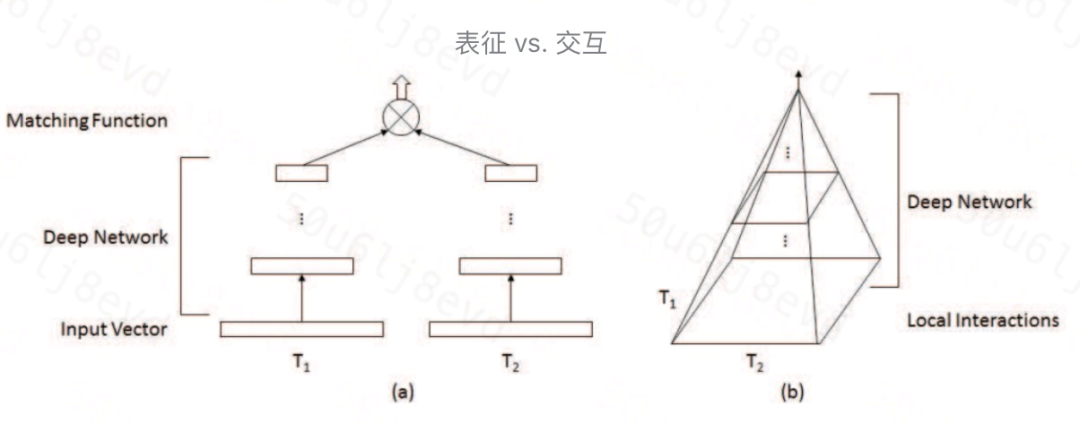
1. Representation vs. Interaction
Match(T1, T2)=F(Φ(T1), Φ(T2))
-
Representation based
學習文本的表征,可以提前把文本的語意向量計算好,在線預測時不用實時計算,在學習出文本向量前,兩者沒有任何互動,可能導致細粒度匹配信號丟失,同時兩個文本的向量可能屬于不同的向量空間,需要通過上層的融合層和loss拉進兩個向量間的距離,
F函式為一個復雜的表征函式,Φ是一個簡單的打分函式, -
Interaction based
通過區域互動矩陣保留有細粒度、精細化的匹配信號,上層使用更大粒度的pattern進行匹配資訊提取,同時該類模型的可解釋性更好,缺點在于一般此類模型的在線計算代價更大,F函式為一個簡單的映射函式,Φ是一個復雜的深度模型函式,
2. Similarity vs. Relevance

-
Simiarity:通常是判斷兩個同質的文本的語意、意思是否相似,其匹配函式是對稱的,代表任務有 NLP 的同義句識別,
-
Relevance:通常是判斷兩個不同質的文本(query 與 doc)是否相關,其匹配函式是不對稱的,代表任務有搜索網頁檢索,
3. Global vs. Local
- Global Distribution:從全域匹配更偏向語意上的匹配
- Local Context:從區域匹配更偏向字符上的匹配
4. Exact Term Matches vs. Inexact Term Matches vs. Term Position Matches
-
Exact Term Matches:傳統的 IR 模型(例如 BM25演算法)是基于 query 和 doc 的精確匹配計數計算的,它們可以在最少甚至沒有訓練資料的情況下使用,可以直接用于新任務或語料庫,
-
Inexact Term Matches:query 和 doc 之間的非精確匹配是指利用嵌入空間學習 term語意進行匹配的技術,
-
Term Position Matches:query 和 doc 中 term 的匹配位置不僅反映檔案的潛在相關部分所在位置(例如標題、段首等),而且還反映了 query 各個 term 匹配彼此的聚合程度,

上方左圖說 case 為當 query 為 president of united states 時,exact term matches 和 inexact term matches 的匹配效果(綠色越深表明匹配程度越高);
上方右圖說明當 query term 在 doc 中的匹配位置較為集中時相關性才高,當匹配位置相距較遠或較分散時說明匹配程度很低,
Representation Based Model##
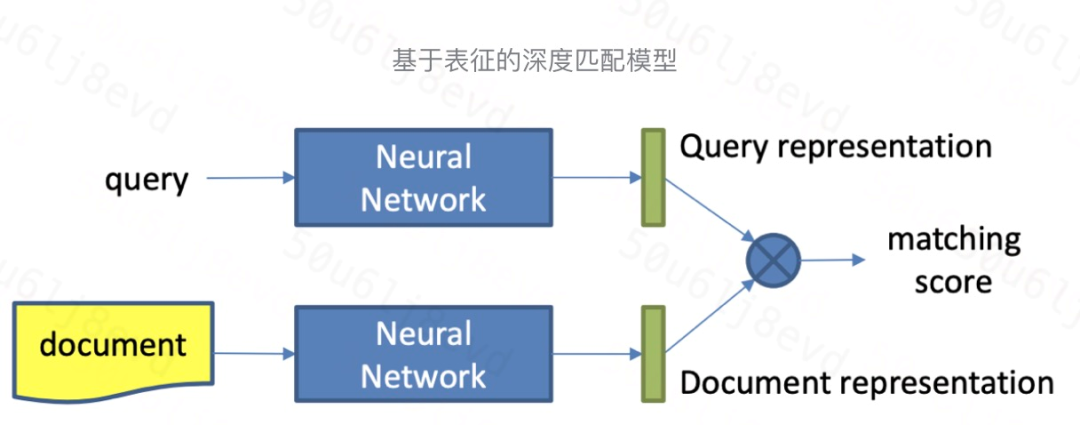
基于表征的深度匹配模型基本結構如圖所示,一般分為兩步:
-
計算 query 和 doc 的 representation
-
對兩者的 representation 進行 matching 計算
我們以DSSM模型為例,
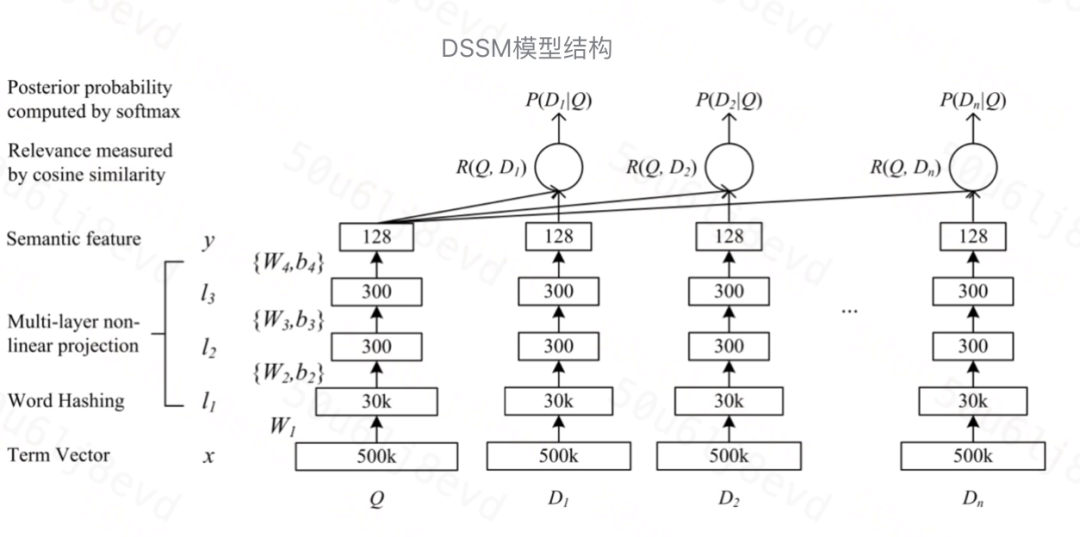
輸入層
輸入層是把文本映射到一個向量空間里并輸入到 DNN 中,這里英文和中文的處理方式有很大不同,
英文的出入層處理方式是通過 word hashing 方式,通常是用 letter-trigrams 來切分單詞(3個字母為一組,#表示開始和結束符),
例如 boy 這個單詞,會被切為 bo,boy,oy
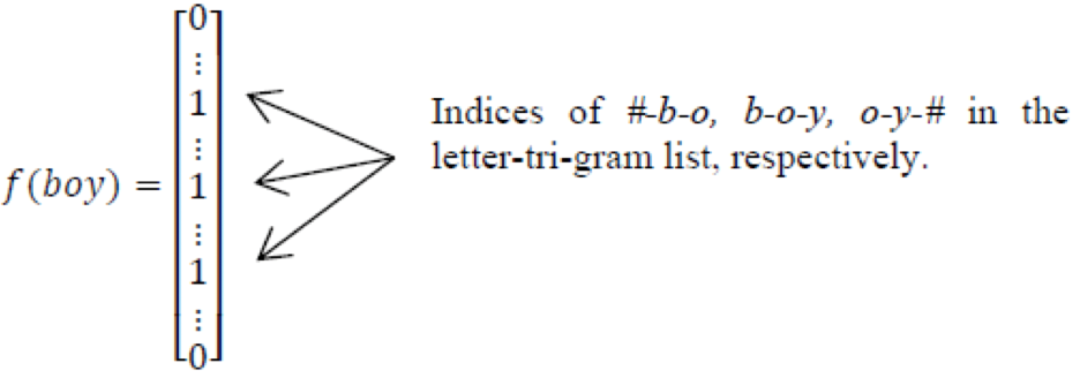
word hashing 的好處有兩個:
-
壓縮空間:50萬個單詞的 one-hot 向量空間可以通過 letter-trigrams 壓縮為一個3萬維的向量空間,
-
增強泛化能力:三個字母的表達往往能代表英文中的前綴和后綴,而前后綴往往具有通用的語意,
除此之外,之所以選擇3個字母的切分粒度,是綜合考慮了向量空間和單詞沖突,
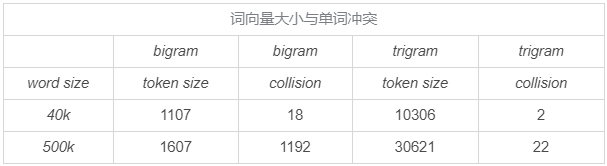
中文的分詞是 NLP 領域的難題,準確度往往難以滿足要求,所以對于中文的處理方式是不做分詞處理,直接以單字作為最小粒度,
常用單字數量為1.5萬左右,而雙字的話大約到百萬級了,所以這里出于向量空間的考慮,采用單字向量即(one-hot)作為輸入,向量空間約1.5萬維左右,
表示層
DSSM 的表示層采用 BOW(bag of words)的方式,相當于把字向量的位置資訊拋棄了,整個句子的詞都放在了一個袋子里,不分先后順序,這樣做會損失一定資訊,后續的 CNN-DSSM和LSTM-DSSM 可以在一定程度上解決這個問題,緊接著是一個含有多個隱藏層的 DNN,
用 Wi 表示第i層的權值矩陣,用bi表示第i層的偏置項,則可以得到下面公式,
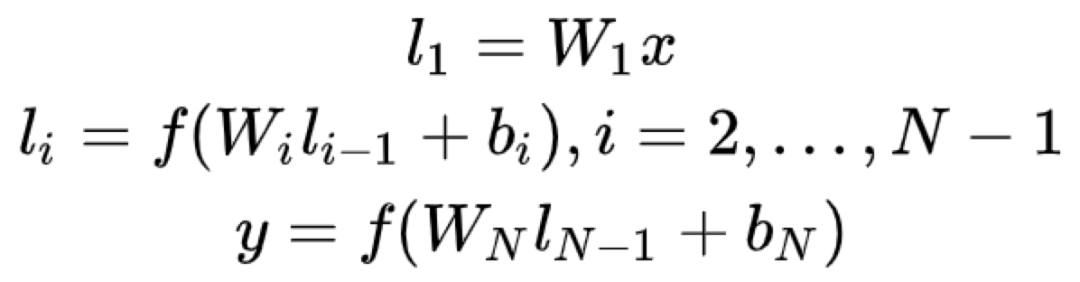
用 tanh 作為隱藏層和輸出層的激活函式,最終輸出一個128維的低維語意向量,
匹配層
query 和 doc 的語意相似性可以用這兩個語意向量(128維)的 cosine 距離,即余弦相似度來表示,
通過 softmax 函式可以把 query 與證樣本 doc 的語意相似性轉化為一個后驗概率,
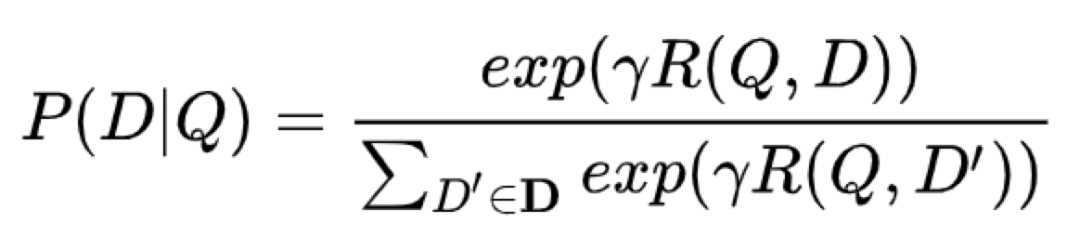
其中,γ 為 softmax 的平滑因子,在訓練階段,通過極大似然估計,我們最小化損失函式,
Interaction Based Model
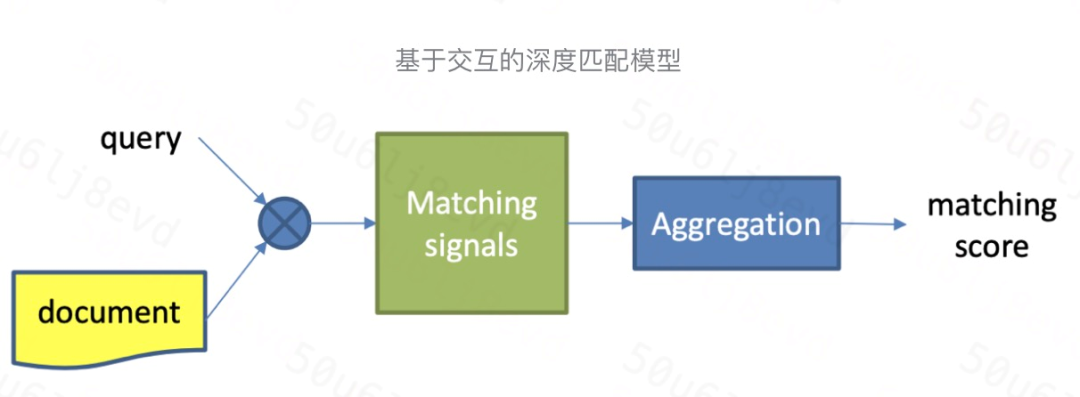
基于互動的深度匹配模型基本結構如圖所示,一般分為兩步:
- 建立基本的底層匹配信號
- 根據底層匹配信號提取匹配 pattern
我們以 DRMM 模型為例,
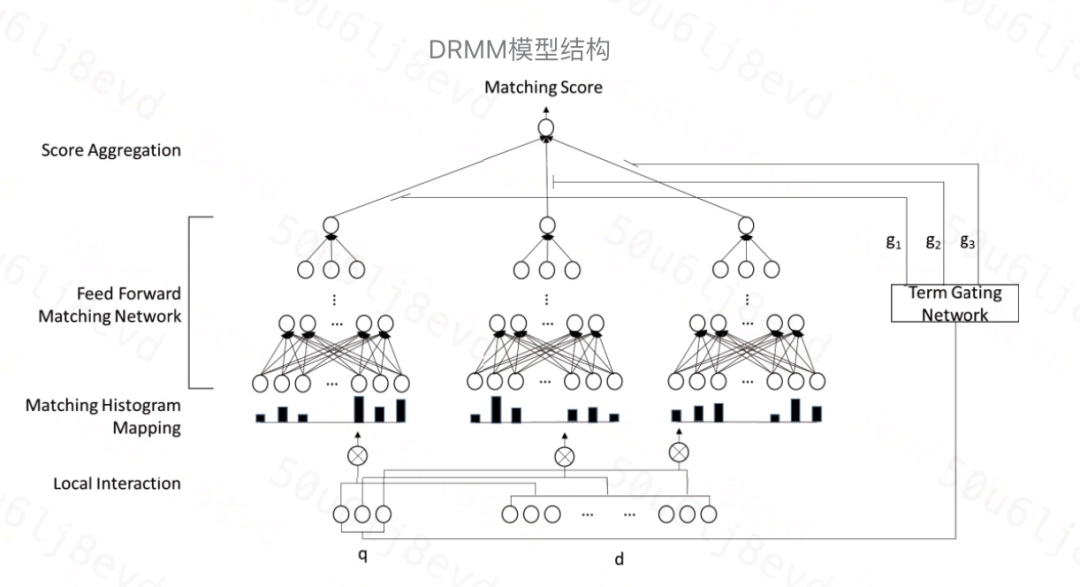
輸入層
query 和 doc 通過預訓練好的詞向量 q={w1, w2,...,wM},d={w1, w2,...,wN}作為輸入,
其中每一個 w 都是一個t維的詞向量,
區域互動矩陣-匹配直方圖

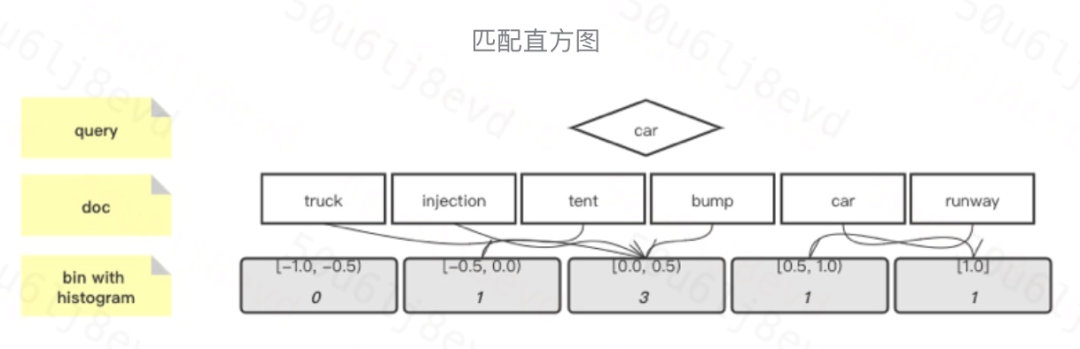
模型首先對 query 和 doc 每個 term 對都建立了區域互動關系,傳統的區域互動矩陣存在一個重要問題,即 query 和 doc 的長度都是不定的,而模型需要轉換成固定長度,除此之外,區域匹配矩陣保留了位置表征,這對于位置敏感的任務非常有效,但該模型認為在搜索匹配問題中,更關注匹配信號的強度,所以該模型將其轉化為匹配直方圖,
匹配直方圖將兩兩 term 的相似度根據分桶原理放入不同的桶中,例如 cosine 相似度的取值范圍在[-1, 1]之間,所以將 interval 離散化成有序的 bins,對每個 bin 中的區域互動值數量進行累計,本文使用固定大小的 bins,將精確匹配的作為單獨的 bin(即匹配分數為1的),
假設bin的大小為0.5,那么可以得到5個 bins,即{[-1, -0.5), [-0.5, -0), [0, 0.5), [0.5, 1), [1, 1]}升序排列,給定 query 為 car 以及一個檔案(truck, injection, tent, bump, car, runway),對應的余弦相似度分別為(0.2, 0.3, -0.25, 0.4, 1.0, 0.75),可以得到匹配直方圖為[0, 1, 3, 1, 1],
模型嘗試了3種匹配直方圖映射的計數方式
- 基于計數的直方圖 CH:最簡單的轉換方法,直接計算每個 bin 中對應值的數量,
- 歸一化直方圖 NH:對每個bin中的計數值進行歸一化(基于總數量),關注不能互動值數量的相對大小,
- 基于計數值對數的直方圖 LCH:對每個 bin 中的計數值取對數,同樣是為了壓縮取值范圍,讓模型可以更容易學到乘性關系,
隱藏層
模型采用 DNN 作為隱藏層而非與區域互動矩陣對應的 CNN,這樣避免了池化層對于一些細微信號的丟失,
term 門網路
DRMM 采用了基于 query term 級別的聯合深度網路,可以清楚地建模每個 query term 的重要性,這里使用了 term 門網路,計算每個 query term 的聚合權重:
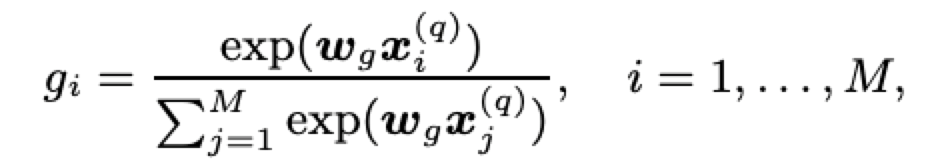
模型嘗試了兩種不同的輸入向量:
-
Term Vector (TF):xi(q)表示第 i 個詞的詞向量,wg 表示同樣維度的 term 門網路權重向量,
-
逆檔案頻率(IDF):IDF 是表征單詞重要性的重要信號,這里 xi(q)表示第 i 個單詞的 IDF,wg 即為一個常數,
Representation & Interaction Based Model
此類模型融合了基于互動的匹配模型與基于表征的匹配模型的優點,分為對應的 local model 和 distributed model 兩部分,distributed model 在匹配之前將 query 和 doc 文本投影到嵌入空間中;而 local model 在互動矩陣上操作,將每個 query 與每個 doc 進行比較,最終得分是來 local 得分和 distributed 網路的得分之和,
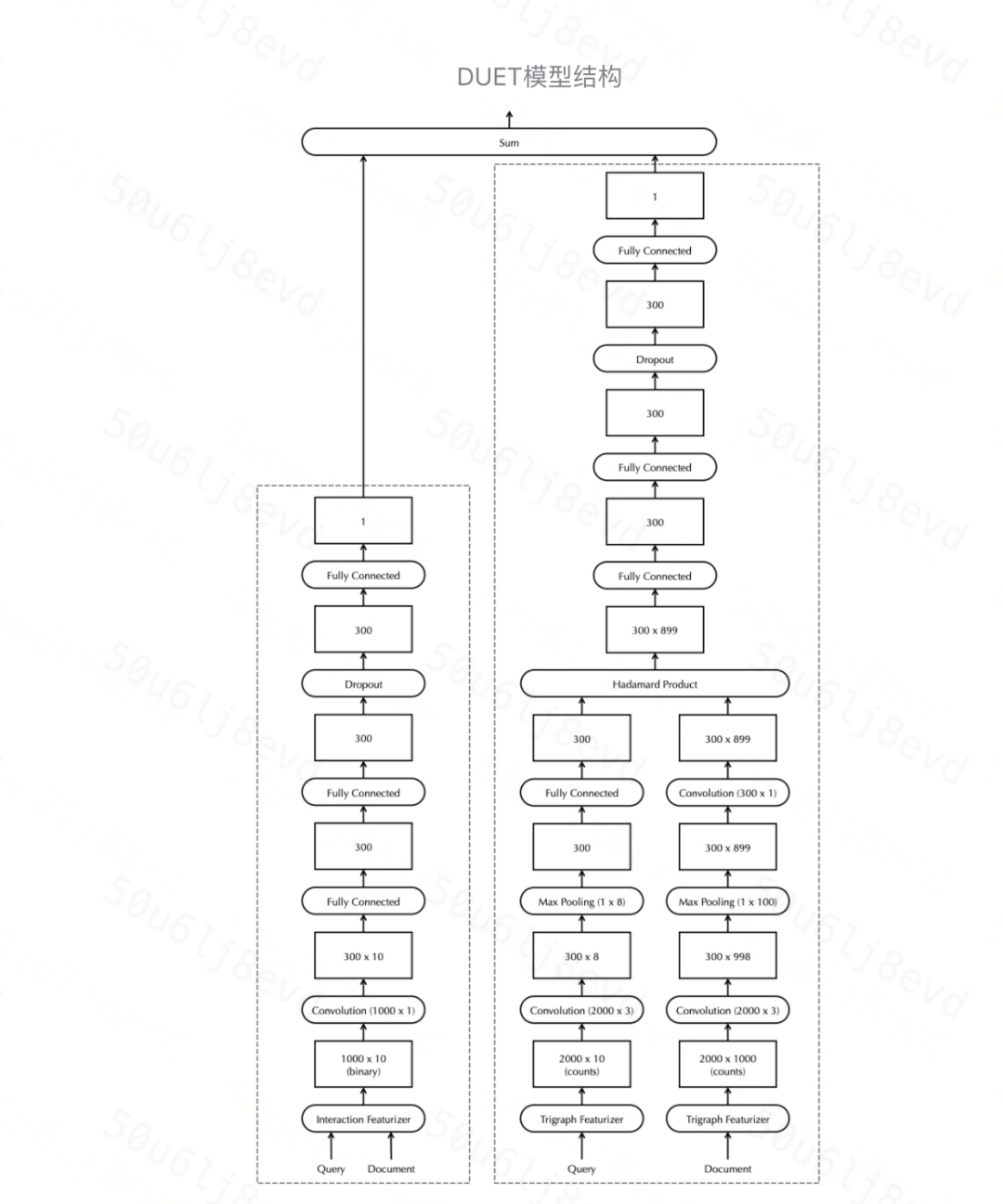
輸入層
我們固定所有 query 和 doc 的輸入長度,僅考慮 query 中的前10個term Q=[q1, q2, ..., q10]和 doc 中的前1000個term D=[d1, d2, ..., d1000],如果 query 或 term 短于這些目標維度,則輸入向量用0填充,其中,q 和 d 都是 m × 1的向量,
query 中 term 數 nq;doc 中 term 數 nd,
Local model
Local Model 基于 query term 在 doc 中的精準匹配來衡量 doc 的相關性,每個 term 表達為 one-hot 的向量(m 維,m 為詞典大小),然后,模型生成區域互動矩陣 X=D^T × Q,大小為 nd × nq,獲取 query term 在 doc 中的每個精確匹配和位置資訊,但是 X 不保留 term 本身的資訊,因此,**Local Model 不能從訓練語料中學習 term 的特定屬性,也不能對不同 term 之間的互動進行建模,
X 首先經過卷積層,有 c 個 filters,其核大小為 nd × 1(doc的term數),跨距為1,
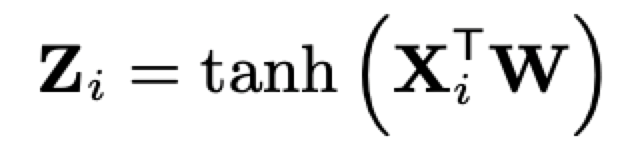
Zi,是 qi 與 doc 中的所有 term 進行匹配的函式的輸出,Xi 是區域互動矩陣 X 的第 i 行,W(nd × c 矩陣)是卷積層要學習的引數,Z 的維度為 c × nq,模型使用 c=300的filters,卷積層的輸出然后通過兩個全連接層、drop-out 層、最終的全連接層,得到一個單個的實數值,Local Model 中的所有節點都使用雙曲正切作為激活函式進行非線性處理,
Distributed model
Distributed Model 學習 query 和 doc 文本的稠密低維向量表示,然后計算它們在嵌入空間中的相似性,不同于 Local Model 中對 term 進行 one-hot 編碼,Distributed Model 用了基于 trigram 的方式對每個 term 進行表示,然后用 trigram 頻率矢量來表達這個 term(長度為 md),
在 distributed 部分中,不直接計算矩陣 Q(md × nq)和矩陣 D(md × nd)的互動,**而對這種基于字符的輸入先學習一系列的非線性轉換,
對于 query 和 doc,第一步是卷積,md × 3的卷積窗,filter size 為300,它將3個連續 term 投影到一個300維向量,stride 為1,再投影接下來的3個 term,依此類推,其中,對于 query,卷積層生成維數為300 × 8的張量;對于 doc,它生成維度300 × 998,
接下來,是 max-pooling 層,對于 query,池化層的核維數為1 × 8,對于 doc,維數為1 × 100,因此,對于 query,得到300 × 1的矩陣Q~,對于doc,得到300 × 899的矩陣D,D可以被解釋為899個獨立的 embedding,每個 embedding 對應于 doc 內不同的相等大小的文本跨度,該模型選擇基于視窗的最大池策略,而不是 CDSSM 采用的全域最大池策略,是因為基于視窗的方法允許模型區分 doc 不同部分中的匹配項,當處理長檔案,尤其是包含許多不同主題的混合檔案時,保留匹配位置的模型可能更適用,
query 的最大池化層的輸出后續連接全連接層;對于 doc,300 × 899的維度矩陣輸出,由另一卷積層運算(filter size 為300、kernel size 為300 × 1、stride 為1),**這些卷積層和最大池層的組合使得 distributed 模型能夠學習文本的適當表示,以實作有效的非精確匹配,
為了進行匹配,我們對 embedded doc 和 query 進行 element-wise or Hadamard product,然后,我們將此矩陣通過完連接層和 dropout 層,直到得到一個分數,與 local 模型一樣,distributed 模型采用 tanh 函式進行非線性分析,
輸出層
DUET 模型將 local 部分與 distributed 部分的結果直接加和作為最終相關性得分,這樣同時保留了 interaction 和 representation 部分的優勢,
3. 模型效果分析
我們找到一些在公開資料集上常見搜索相關性演算法的指標作為參考,
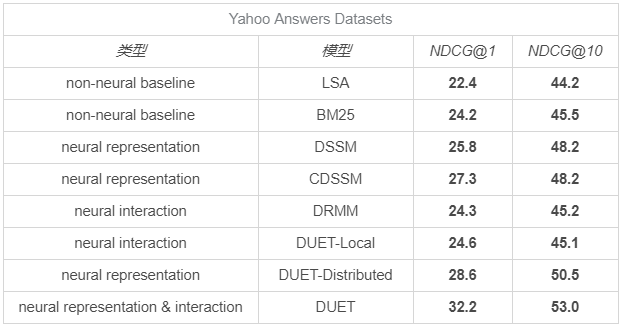
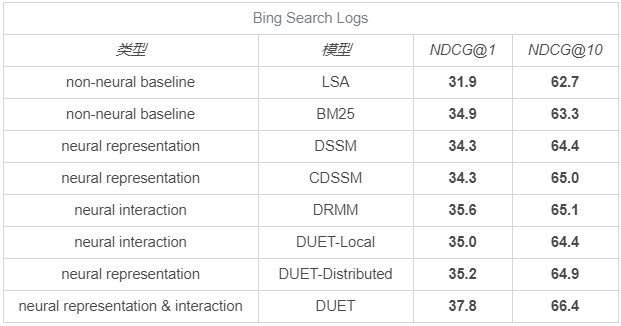
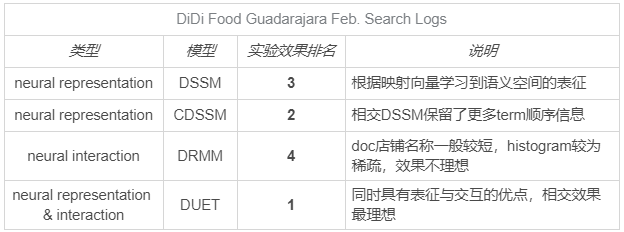
在 DiDi Food 業務中,我們用 Guadalajara 城2月份的資料作為訓練集,嘗試了 DSSM,CDSSM,DRMM 和 DUET 四種模型,得到離線效果為下表,
4. 團隊招聘

R lab 是滴滴17年底成立的一級部門,肩負不斷探索滴滴邊界范訓創新產品,R 意為 Rebuild,我們不創造用戶需求,而通過獨立思考,從第一性原理出發探究本質,重構一個個業務領域,創造新體驗替換舊體驗,為用戶創造價值,目前主要業務為 DiDi Food 國際外賣業務及國內探索業務,目前 DiDi Food 業務已經開國墨西哥、巴西、日本,為當地用戶提供優質服務,國內探索業務也在持續進行,
目前部門業務快速發展,急需各類人才,演算法,服務端,測驗,客戶端,戰略,產品,運營等,歡迎有興趣的小伙伴加入,
投遞簡歷至hr郵箱:[email protected]
作者介紹
李明陽:
滴滴出行,高級演算法工程師,滴滴 R lab Strategy Tech 交易策略方向,從事搜索演算法策略相關作業,負責搜索相關性排序,搜索少無結果推薦,熱詞推薦等專案,
歡迎關注滴滴技術公眾號!

本文由博客群發一文多發等運營工具平臺 OpenWrite 發布
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/45328.html
標籤:其他
上一篇:用python做時間序列預測八:Granger causality test(格蘭杰因果檢驗)
下一篇:淺談微前端在滴滴車服中的應用實踐