標題:視覺問答中關于組合泛化的多模態圖神經網路
來源:NeurlPS 2020https://proceedings.neurips.cc/paper/2020/hash/1fd6c4e41e2c6a6b092eb13ee72bce95-Abstract.html
代碼:https://github.com/raeidsaqur/mgn
一、問題提出
重點:組合泛化問題

例子:自然語言為例,比如人們能夠學習新單詞的含義,然后將其應用到其他語言環境中,一個人如果學會了一個新動詞 'dax' 的意思,就能立即類推到 'sing and dax' 的意思,” 類似地,在訓練的時候,可能在測驗集中出現了訓練集中沒有出現過的元素“組合”(這些元素在訓練集中存在),如:訓練集中有“紅色的狗”、“綠色的貓”,但是測驗集中的資料是“紅色的貓”,
問題:在最近的研究表明,模型無法推廣到新的輸入,而這些輸入僅僅是訓練集組合分布所見元素中的未遇見過的組合[6],
一般地,使用卷積神經網路(CNN)構建多模態表示的神經架構將整個影像處理為單個全域表示(例如向量),但無法捕獲這種細粒度相關性[29],
基于神經符號的VQA方法(比如NMNs、NS-VQA和NS-CL)雖然在CLEVR等基準上取得了接近完美的分數[28,29],但即使視覺輸入的分布保持不變(輸入影像不變),這些模型也無法推廣到新的語言結構組合(問題發生變化)[6],一個關鍵原因是缺乏關于影像和文本資訊的細粒度的表示,這種表示允許在視覺和語言空間上進行聯合合成推理,
二、主要思想
作者提出了一種基于圖的多模態表示學習方法——多模態圖網路(MGN),重點是可以實作更好的泛化效果,圖結構可以去捕獲物體、屬性和關系,從而可以在不同模態(例如影像和文本)的概念之間建立更緊密的耦合,
動機:
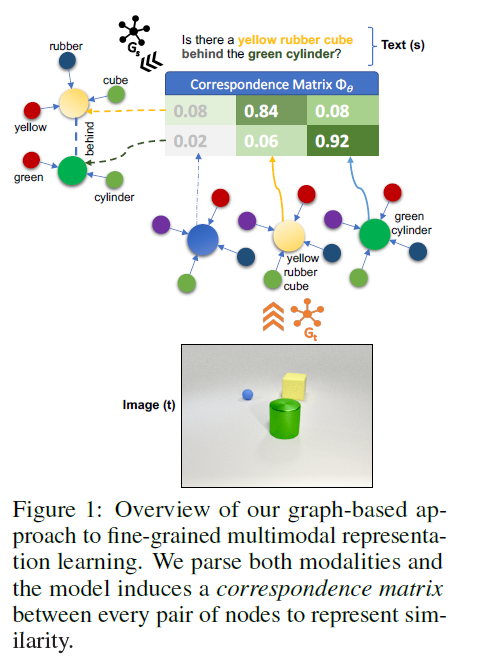
考慮圖中的影像和相關的問題:“在大的綠色圓柱體后面有一個黃色的橡皮立方體,”回答這個問題需要首先找到綠色圓柱體,然后掃描它后面的空間,尋找黃色的橡膠立方體,具體來說,1)雖然可能存在其他物件(例如,另一個球),但關于它們的資訊可以被抽象出來,2)需要在代表“黃色”和“立方體”的視覺和語言輸入之間建立細粒度的聯系,
核心思想:將文本和影像都表示為圖,自然可以使兩種模式之間的概念更緊密地耦合,并為推理提供合成空間,具體來說,首先將影像和文本決議為單獨的圖,物件物體和屬性作為節點,關系作為邊,然后,我們使用類似于圖神經網路[16]中使用的訊息傳遞演算法(message passing),在兩種模式的節點對之間匯出相似因子矩陣(correspondence factor matrix),最后,使用基于圖的聚合機制來生成輸入的多模態向量表示,
具體模型:
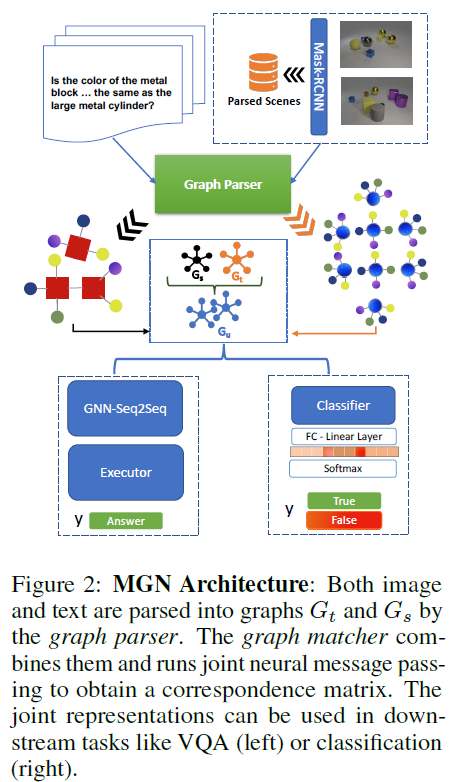
Part1:圖結構
多模態輸入實體:元組(s,t),其中s是源文本輸入(例如,問題或標題),t是對應的目標影像,
圖形決議器(Graph Parser):
輸入:元組(s,t)
輸出:相應的以物件為中心的圖\(G_s=(V_s,A_s,X_s,E_s)\)和\(G_t=(V_t,A_t,X_t,E_t)\),
其中,圖中所有節點構成集合V,A是圖的鄰接矩陣,X是圖G中所有節點V的特征矩陣,E是圖G中所有邊的特征矩陣,
具體的方法:
對輸入文本s,使用物體識別模塊將物件和屬性捕獲為圖形節點V,然后使用關系匹配模塊捕獲節點的關系作為圖\(G_s\)中的邊,

對影像t,使用預訓練的Mask RCNN和ResNet-50 FPN影像語意分割模塊來獲取物件、屬性和位置坐標(x、y、z),這些節點在圖\(G_t\)中形成單獨的節點,
在\(G_s\)和\(G_t\)中構造節點和邊之后,通過使用預先訓練的語言模型中的詞向量嵌入(word embadding)(假設維度為d)作為文本圖節點(物件、屬性)和邊(關系)的特征向量,從而獲得特征矩陣X和E,對于影像場景圖,我們使用從“決議場景”(來自Mask-RCNN通道)獲得的物件和屬性標簽作為語言模型的輸入,來獲得特征嵌入,
圖形匹配器(Graph Matcher):
輸入:圖\(G_s=(V_s,A_s,X_s,E_s)\)和\(G_t=(V_t,A_t,X_t,E_t)\)
輸出:生成多模態向量表示\({\vec{h}}_{s,t}\)(維度為2d)——它捕獲源節點(文本)和匹配目標節點(影像)的潛在聯合表示,
具體方法:
將兩個圖進行合并,其中節點的初始特征表示:\(h_i^{\left(0\right)}=x_i\epsilon\ X\),之后利用圖神經網路的訊息傳遞演算法,通過聚合其鄰居的表示來迭代更新向量節點表示,在資訊傳遞的最后,每個節點都獲得了來自周圍鄰居的資訊,
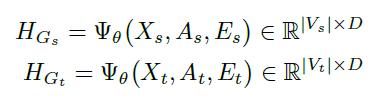
訊息傳遞演算法:1. AGGREGATE(聚合)、2. MERGE(合并),經過k次迭代后,節點的特征表示向量\(h_v^{\left(k\right)}\)就可以捕獲到圖中k-hop鄰域內的節點資訊,
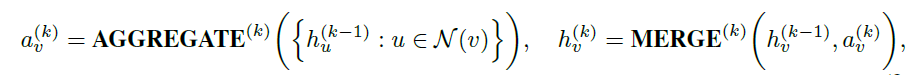
當進行圖分類任務時,需要將點特征轉化為全域特征;使用求和或者圖池化的方法(READOUT函式),結合了最終迭代中的節點特征,從而獲得整個圖\(G_s\)或\(G_t\)的特征表示:
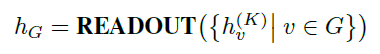
之后,為了將文本空間的特征投影到視覺空間,使用源圖和目標圖的向量區域節點表示\(H_{G_s}\)和\(H_{G_t}\),計算得到一個soft correspondence matrix \(\mathrm{\Phi}\)(相似性矩陣):
\[\mathrm{\Phi}=H_{G_s}{H_{G_t}}^T\in\ R^{|V_s|\times|V_t|} \]其中第i個行向量\(\mathrm{\Phi}_i\in\ R^{V_t}\)表示圖\(G_t\)的節點和\(V_s\)中任意節點的潛在相似性關系的概率分布(可以視為用來衡量兩個不同圖中節點之間的匹配度的似然分數),為了得到源節點特征和目標節點特征之間的離散相似性分布,將“sinkhorn normalization”(一種正則化方法)應用于相似性矩陣,以滿足矩形雙隨機矩陣約束(對于\(\sum_{j\in V_t}\mathrm{\Phi}_{i,j}=1,\forall\ i\in\ V_s\ \ \ and\ \ \ \sum_{i\in V_s}\mathrm{\Phi}_{i,j}=1,\forall\ j\in\ V_t\)),
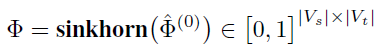
最后,給定\(\mathrm{\Phi}\),可以獲取一個從源(文本)潛空間\(L(G_s)\)到目標(影像)潛空間\(L(G_t)\)的投影函式:
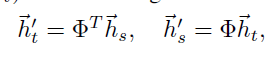
最終聯合多模態表示\(h_{s,t}\)包括\([h_s,{\vec{h}}_s^\prime]\)的concat拼接操作,其中\({\vec{h}}_s^\prime\)是文本特征h_t到視覺空間上的投影,
Part2:下游任務
任務1:字幕分類任務
在這個任務中,給定一幅影像和一個標題,模型必須預測該影像背景關系中的標題是真(T)還是假(F),用來測驗模型處理影像空間成分變化的能力,

影像來自CLEVR資料集[28],字幕使用模板生成正確和錯誤樣例,為了衡量模型的泛化性能,在測驗期間,交換物件屬性值,并評估模型是否能夠在不降低性能的情況下檢測到新的屬性值組成,
模型:
\(h_{s,t}\)可以被饋送到一個具有sigmoid激活函式的全連接層,以進行二分類分類0/1(匹配/不匹配),
損失函式選擇二元交叉熵損失函式:
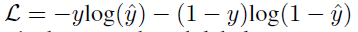
VQA任務:
CLOSURE資料集:基于CLEVR資料集生成,CLOSURE中的問題模板系統地使用原始語言構造,在生成的問題中創建看不見的組合,使用了七種不同的模板,針對五種廣泛的CLEVR問題型別之一(計數、存在、數值比較、屬性比較和查詢),

模型:
\(h_{s,t}\)被提供給一個基于注意力機制的seq2seq模型,該模型具有encoder-decoder結構,
使用雙向LSTM[24]作為encoder,在時間步i,encoder接受一個具有padding的包括可變長度的單詞token的問題\(q_i\),以及\(h_{s,t}\)作為輸入:
之后使用雙向LSTM進行編碼:
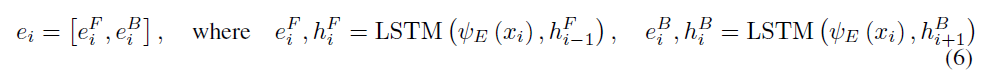
decoder是具有注意力機制的LSTM網路:利用前一個輸出序列\(y_{t-1}\),經過LSTM網路產生向量\(o_t\),之后送入注意力層并獲取加權后的encoder向量:
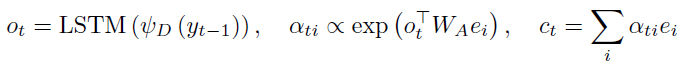
最后,decoder輸出\(o_t\)和\(c_t\)被送到一個具有softmax激活的全連接層,以獲得預測的符號序列\(y_t\),\(y_t\)后續被用來回答VQA任務的問題,
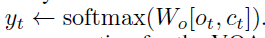
三、實驗
Task1:
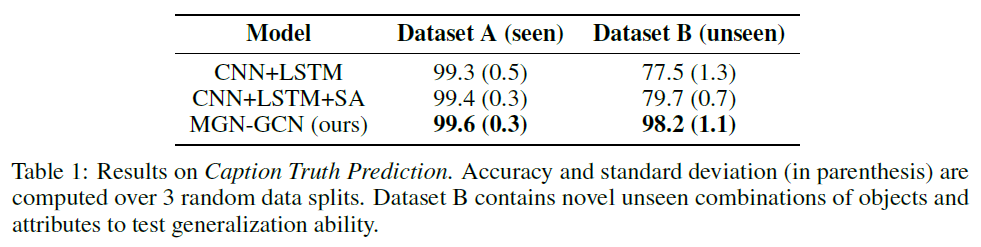
補充:資料集B包含新的看不見的物件和屬性組合,以測驗泛化能力,
Task2:
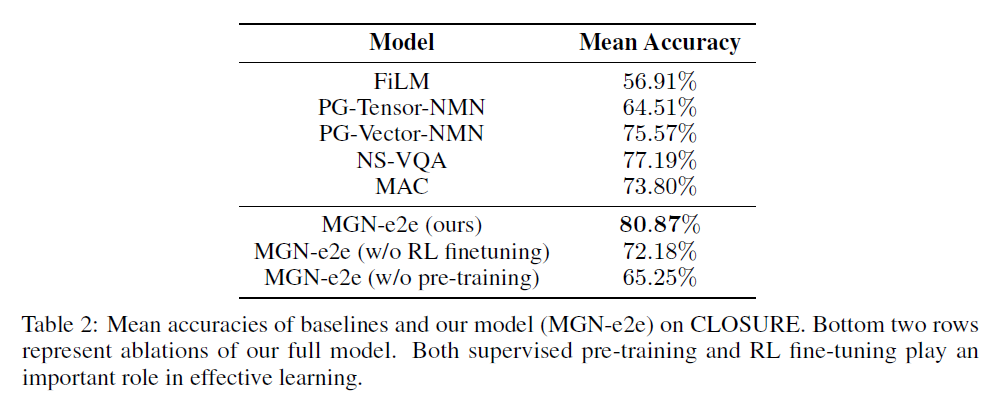
補充:有監督的預訓練和微調在有效學習中都發揮著重要作用,
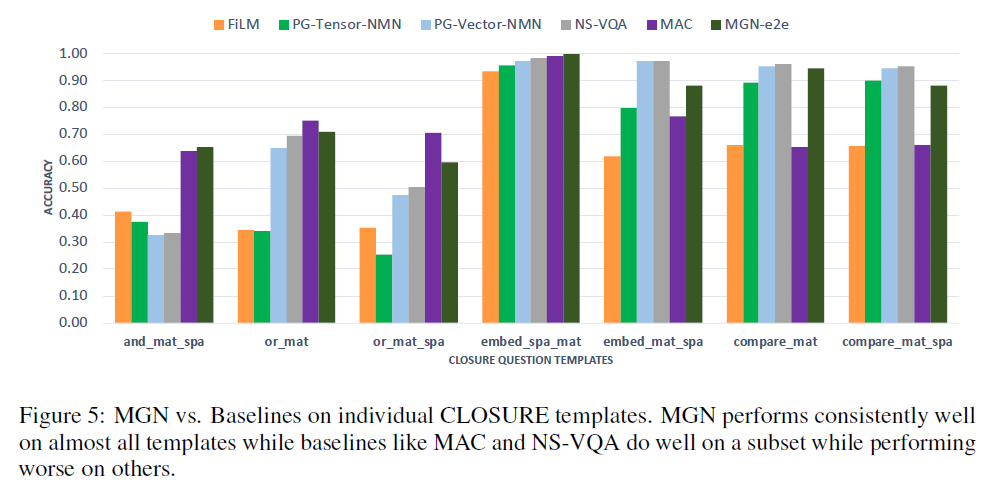
補充:MAC模型總體表現強勁,然而這些模型在邏輯關系上表現不佳(embed_mat_spa,compare _mat),另一方面,MGN在所有7個模板中都表現良好,
四、存在的問題
目前MGN模型主要訓練的資料集還只是簡單的影像組成的資料集,后續可以考慮如何擴展到更大更自然的影像資料集的挑戰中,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/453830.html
標籤:其他
上一篇:同態加密在聯邦計算中的應用
下一篇:論文閱讀:《Multimodal Graph Networks for Compositional Generalization in Visual Question Answering》