背景:
當前的熱門演算法中,除了神經網路在影像和文字、音頻等領域大放異彩之外,集成學習中的xgboost,lightGBM,CatBoost也在kaggle等機器學習平臺上成為了炙手可熱的工具,
明確概念:
1、Boosting(提升)
2、Adaptive Boosting(自適應增強)
3、Gradient Boosting(梯度提升)
4、Decision Tree(決策樹)
一、Boosting
關于boosting(提升演算法)的概念,上文有簡單介紹過,提升演算法(這是一類演算法族的稱呼,不是指某種具體演算法)是通過改變訓練樣本的權重(如果基分類器不支持則通過調整采樣的方式改變基分類器的訓練樣本分布),學習多個分類器,并將這些分類器進行線性組合,提高分類的性能,下面要講的集成演算法都屬于提升演算法
二、Adaboost(Adaptive Boosting自適應增強演算法)
針對分類任務,李航的《統計學習方法》中有詳細介紹


總結一下流程如下圖所示
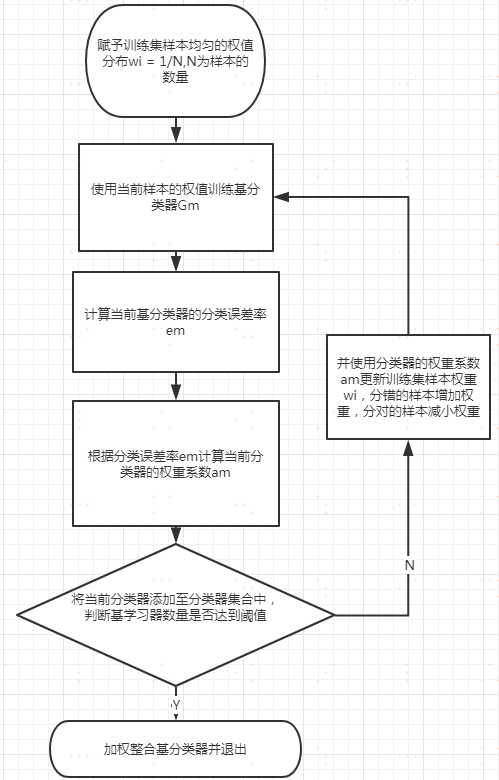
經過上述學習,我們已經可以明確adaboost的核心是
1)計算基分類器的誤差
2)計算基分類器的權重
3)更新樣本的權重
4)最后的結合策略
針對回歸任務,adaboost有以下步驟

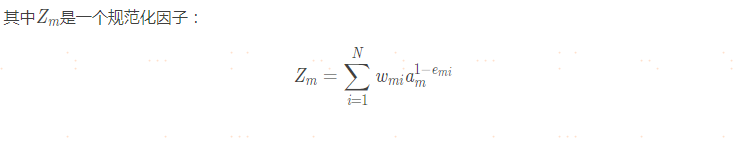

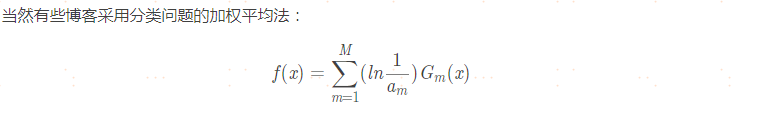

三、GBDT(GBDT泛指所有梯度提升樹演算法,包括XGBoost,它也是GBDT的一種變種,為了區分它們,GBDT一般特指“Greedy Function Approximation:A Gradient Boosting Machine”里提出的演算法,只用了一階導數資訊,)
參考自:https://zhuanlan.zhihu.com/p/46445201
GBDT是以CART樹(回歸樹)作為基分類器的boosting演算法,與Adaboost通過每次調整樣本的權值來訓練不同的基分類器不同,GBDT是通過將殘差作為擬合目標訓練心得基分類器,
先看一下GBDT應用于回歸任務的原理


其實,我一直對GBDT中的“梯度提升”很不理解,因為最優化理論中,梯度下降優化演算法已經很熟悉了,拿兩者進行比較,我總是覺得GBDT依然是“梯度下降”而非“梯度提升”,如下圖是某個博客上的對比

,這分明都是使用的“梯度下降”,
在參考了很多資料之后,我終于明白了GBDT為什么使用“梯度提升”的叫法了,這里的“梯度提升”并不是和“梯度下降”對立的概念,相反,應該把它拆解開來
“梯度提升”=“梯度”+“提升”
“梯度”是指GBDT演算法中使用梯度近似擬合殘差的做法
“提升”是指boosting方法中將弱學習器提升為強學習器的做法
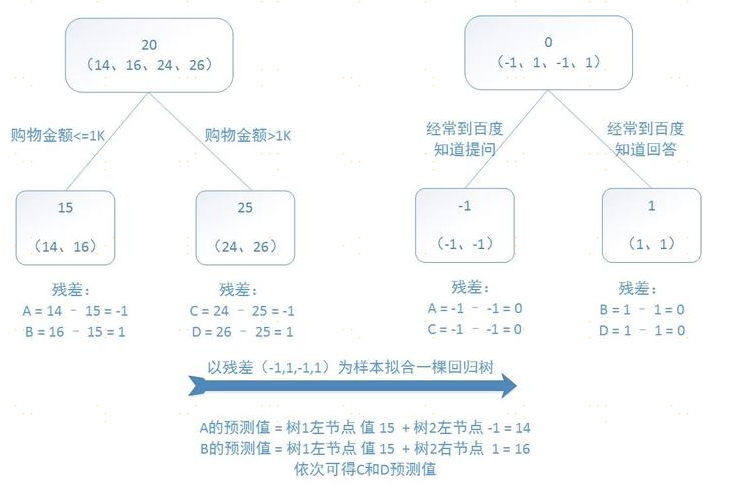
再附一個GBDT實際應用于回歸任務的例子
GBDT應用于分類任務
針對二分類任務,


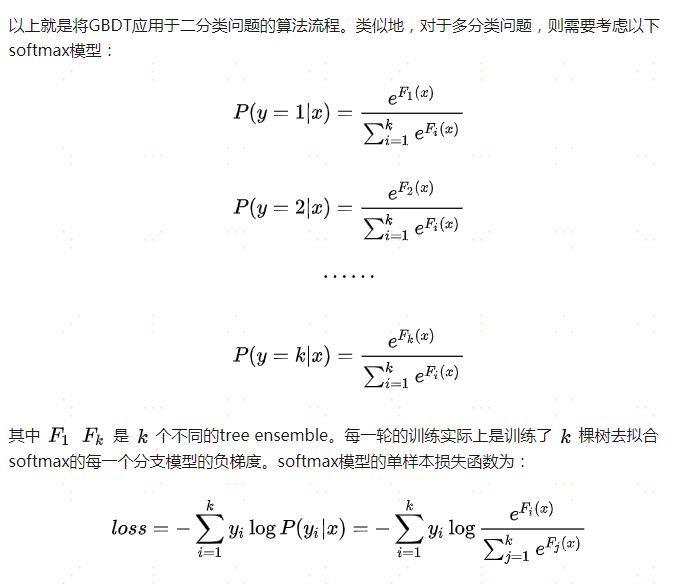

以上,最重要的一點就是,針對分類任務每個基分類器擬合的是真實標簽與和對應類別預測概率的殘差,
四、XGBoost(eXtreme Gradient Boosting)
從名字就可以看出,xgboost是GBDT的增強版本,
如果把xgboost對gbdt的所有改進細節列出來,那牽扯的point有點多,所以選擇幾個點進行闡述,
為了用最容易理解的思路,我們就假設不知道xgboost演算法,先去思考GBDT的程序中有哪些點可以改進:
1、基學習器的選擇,
GBDT使用CART(回歸樹)作為基學習器,我們還可以考慮支持其他的基學習器,所以xgboost也支持線性學習器
2、損失函式的選擇,
GBDT大多數情況下采用平方誤差和作為損失函式,我們還可以考慮更優秀的損失函式,所以xgboost實作了自己的損失函式,
3、特征分裂點及特征選擇,
GBDT采用CART樹的特征分裂點及特征選擇方式,具體為串行遍歷所有的特征分裂點和特征,選擇平方誤差和最小的特征及特征分裂點;
這個程序中,我們注意到各特征及分割點的損失函式的計算可以并行執行,而且如果對樣本按照特征排序的結果在全域可以復用,可大大提高計算效率,而xgboost也是這樣做的,
另外,GBDT的每棵樹的特征選擇策略都是相同的,方差較小,多樣性不足,我們可以借鑒隨機森林中列抽樣(隨機變數選擇)的思想,xgboost也實作了這一點,
4、不同的樹對于殘差的擬合策略
GBDT采用殘差的一階導數代替殘差進行擬合(這里需要說明,許多資料說用一階導代替殘差的原因是殘差難以獲得,這好扯淡啊,擬合一階導的優點明明是為了更快地進行擬合,而且當損失函式為平方誤差和時,一階導就等于殘差),發散一下我們就想到了梯度下降和牛頓法,那我們能不能使用二階導來擬合殘差呢,答案是肯定的,且xgboost也是這樣做的,而且通過二階導擬合策略計算出了xgboost的損失函式(見步驟2),損失函式不僅考慮到了經驗風險,也考慮到了結構風險,通過結構風險正則化,使得xgboost泛化性能更佳,更不容易過擬合,
五、LightGBM
該演算法在精度,運行效率和記憶體消耗等方面在絕大多數資料集上的表現都優于xgboost,
我們沿用上面的思路,繼續思考在xgboost的優化基礎上,怎樣進一步優化GB類的演算法,
1、boosting程序中,最耗時的就是特征選擇及連續特征分裂點選取的問題,xgboost已經通過pre-sorted預排序的方法進行了優化,但是如果樣本對應的特征列舉值過多,還是會導致耗時過長的問題,所以我們可以考慮HistoGram(直方圖)演算法,通過預先對樣本的特征進行分桶(bin)的方式,在選擇分裂點的時候遍歷各個桶,就可以有效地提高運行效率,雖然會稍微損失一點精度,但是可以通過其它的優化進行彌補,
2、結點的分裂策略,GBDT和xgboost在樹的分裂程序中,都采用level-wise(類似層序遍歷)的分裂方式,這種方式平等地對待了分裂貢獻可能相差很大的同一層的不同子結點,lightGBM采用leaf-wise(類似深度優先遍歷)分裂策略,每一步都選擇最深的貢獻最大的子結點進行分裂,
3、采樣方法,無論是GBDT還是xgboost,我們都是在不停地訓練基學習器去擬合殘差,當殘差小于某個閾值時停止訓練,可能存在這樣一種情況,對于大多數樣本來講,其梯度已經較小,而小部分樣本的梯度仍較大,所以我們想到可以在每次訓練新的基學習器時,保留梯度較大的樣本,減少梯度較小的樣本數量(隨機采樣),這便是GOSS方法(Gradient-based One-Side Sampling),
ok,,,寫得自己很不滿意,先出第一版,后面迭代優化吧,,,還想補一下catboost,,,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/45432.html
標籤:其他