標題:神經模塊網路
來源:CVPR 2016 https://openaccess.thecvf.com/content_cvpr_2016/html/Andreas_Neural_Module_Networks_CVPR_2016_paper.html
代碼:https://github.com/jacobandreas/nmn2
一、問題提出
增強了網路的可解釋性
VQA模型的分類:
(1)巨型網路 (monolithic network):傳統的神經網路,以CNN、RNN等為基礎,設計一個固定的網路架構處理 VQA 任務,比如CNN+LSTM 再連一個全連接分類器;
(2)神經模塊網路(Neural modular network ,NMN),該類方法認為問題是一系列基礎模塊的組合(如find, relate, count等),這些基礎模塊的功能可以用子網路來擬合,回答不同的問題需要選擇不同模塊網路來組合成一個大網路,因此網路結構是視問題而定的、動態的,相比于巨型網路,這種動態組合的網路更加直觀、可解釋,中間程序也更加透明,
本文首次提出了Neural Module Networks神經模塊網路(NMN),不是像傳統的神經網路模型一樣是一個整體,它是由多個模塊化網路組合而成,根據VQA資料集中每個questions定制一個網路模型,也就是說NMN模型的網路是根據question的語言結構動態生成的,
二、主要思想
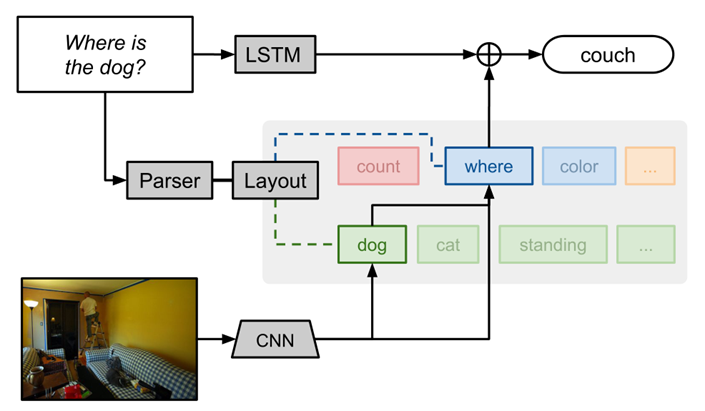
2.1 主要步驟:
Step1:使用語意分析器parser分析每個問題,并結合分析獲取模塊布局layout(包括回答問題所需要的基本計算模塊和之間的關系),
Setp2:組合生成針對特定任務的模塊,回答問題,模塊內部需要人工設計,模塊之間傳遞的資訊可能是原始影像特征、注意力或分類決策,NMN中的所有模塊都是獨立的和可組合的,這使得計算對于每個問題實體是不同的,并且在訓練期間可能不會被觀察到,
該圖中首先生成一個關注狗的注意力(attend模塊),它將其輸出傳遞給一個位置分類器(classify模塊),
Step3:最終答案使用了一個回圈網路(LSTM)來讀取問題輸入,并結合NMN的輸出綜合得到分類結果,
2.2 問題定義:
三元組(w, x, y)
w:自然語言問題
x:圖片
y:答案
模型由模塊m的集合完全確定,每個模塊都具有相關引數\(\theta_m\)和一個從字串映射到網路的網路布局layout的預測器P,給定\(\left(w,x\right)\),模型基于P(w)實體化一個網路,傳遞x (也可能是w)作為輸入,并在標簽上獲得一個分布(對于VQA任務,要求輸出模塊是一個分類器),因此,模型最終編碼一個預測分布\(p(y|w,x;\theta)\) ,
2.3 具體實作:
Part1:模塊定義
模塊操作三種基本資料型別:影像、未歸一化的注意力和標簽,
形式:
TYPE [INSTANCE] (ARG1,...)
TYPE:高級模塊型別(比如注意、分類等),
INSTANCE:考慮的模型的特定實體—例如,attend[red]定位紅色的東西,而attend[dog]定位狗,權重可以在型別級別和實體級別上共享,
模塊型別包括:
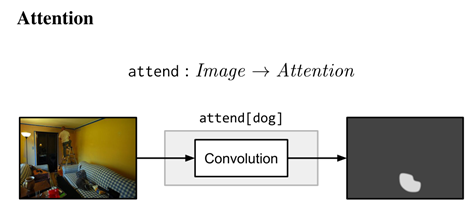
注意模塊attend[c]:將輸入影像中的每個位置與權重向量(每個c不同)卷積,以產生一個熱力圖或未歸一化的注意,
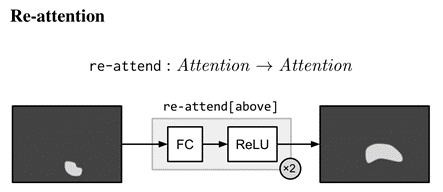
再注意力模塊re-attend[c]:帶校正非線性(ReLUs)的多層感知器,執行一個從一個注意到另一個注意的全連接映射,例如,re-attend[above]應該將注意力轉移到最活躍的區域,而re-attend[no]應該將注意力從活躍區域移開,
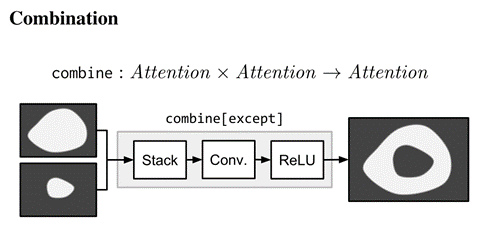
組合模塊combine[c]:將兩個注意力合并成一個注意力,例如,combine[and]應該只在兩個輸入都激活的區域激活,而combine[except]應該在第一個輸入激活而第二個輸入不激活的區域激活,
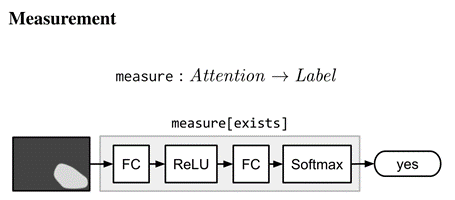
測量模塊measure[c]:單獨關注并通過標簽將其映射到一個分布,由于模塊之間傳遞的注意是未歸一化的,所以measure適用于評估被檢測物件是否存在,或者計算物件的集合,
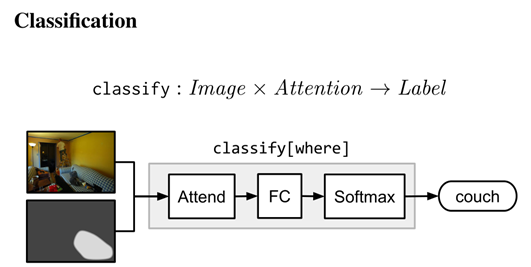
分類模塊classify[c]:需要注意輸入影像,并將它們映射到標簽上的分布,
Part2:從字串到模塊架構
Parsing:
用Stanford Parser決議每個問題,抽取句子中物件之間的語法關系,并生成抽象的句子表示;此外還執行基本的語意化,例如把kites變成kite、were變成be,減少了模塊實體的稀疏性,
例如:what color is the trunk 轉化為 color(truck)
Layout:
基于特定的任務,將符號表示轉化為模塊網路結構,
映射:
葉子節點 對應 attend模塊(使用注意力)
內部節點 對應 (根據它們的度)re-attend模塊或combine模塊
根節點 對應 回答是/否問題的measure模塊或者classify模塊
具體每個模塊的實體化不相同:
例如:attend[cat]和attend[trunck]引數不一樣
神經模塊網路結構統計:

NMN模塊可視化實體:

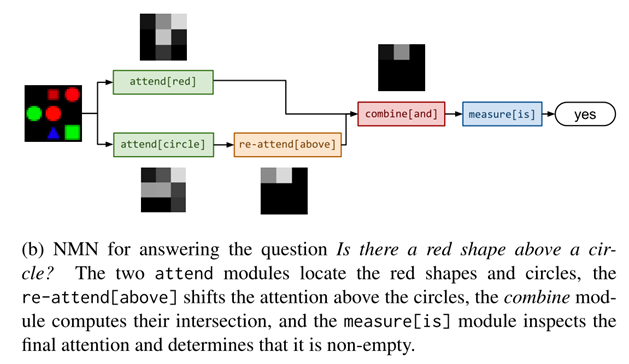
NMN模塊泛化:
除了提供句子,通過parser和layout得到模塊網路,還可以直接提供類似于sql的查詢陳述句,精確地指定需求:

Part3:
預測:包括LSTM網路和NMN模塊網路兩部分
LSTM網路允許我們在資料中建模潛在的語法規則,其次,它允許我們捕捉語意規律,
例如:what is flying和what are flying兩個問題,is和are都會被轉化為be,所以最終轉化為:what(fly);但它們的答案應該分別是kite和kites,
LSTM模塊和NMN模塊都輸出預測答案集上的分布,模型的最終預測結果是這兩種概率分布的幾何平均值,
最后,LSTM模塊和NMN模塊是聯合進行訓練的,
三、實驗
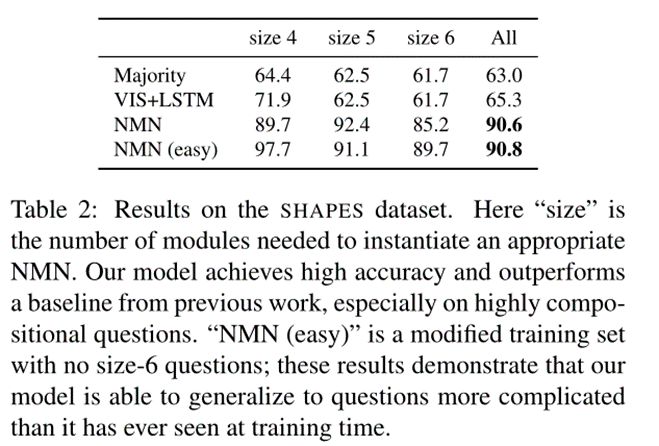
資料集:VQA資料集 SHAPE資料集
結果:
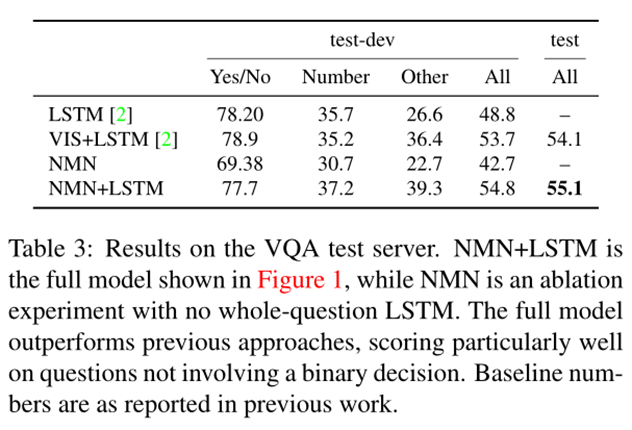
可視化:
正確案例:

錯誤案例:

四、總結
主要貢獻:
1、提出了神經模塊網路NMN,為學習神經模塊集合提供了一個通用的框架,這些神經模塊集合可以動態地組合成任意深度網路,
2、NMN在回答物件或者屬性問題上表現出色,
3、提出了SHAPE資料集,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/457596.html
標籤:其他
上一篇:【課程筆記】中科大資訊論(六)
下一篇:論文閱讀:《Probabilistic Neural-symbolic Models for Interpretable Visual Question Answering》