我正在使用 Beautiful Soup 將來自網站的一些資訊放入 Excel 表格中。

粗體標題顯示在標題列中,而冒號后面的文本顯示在行中。
我正在做的是查找文本并搜索 next_sibling -->
book_year = sibling.pre.find('b',text='Anno:').next_sibling.get_text().strip()
問題在于,在某些情況下,冒號后的文本被分成不同的#text 部分。所以如果我使用 next_sibling,它只會得到部分資訊。
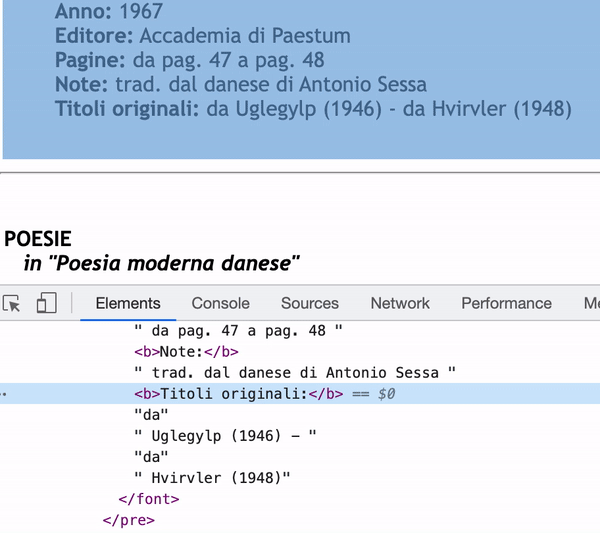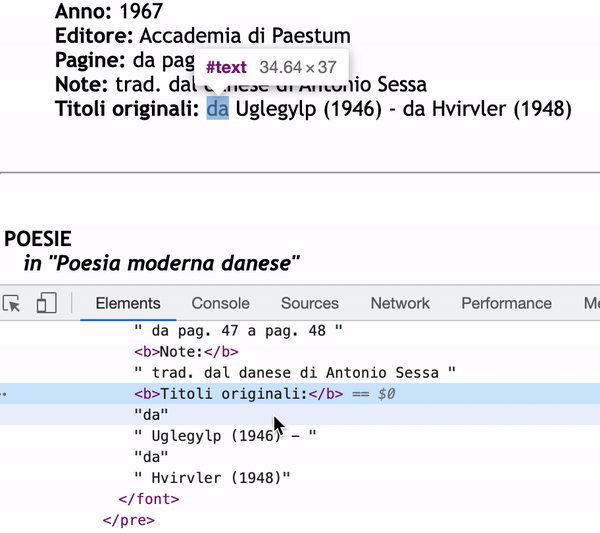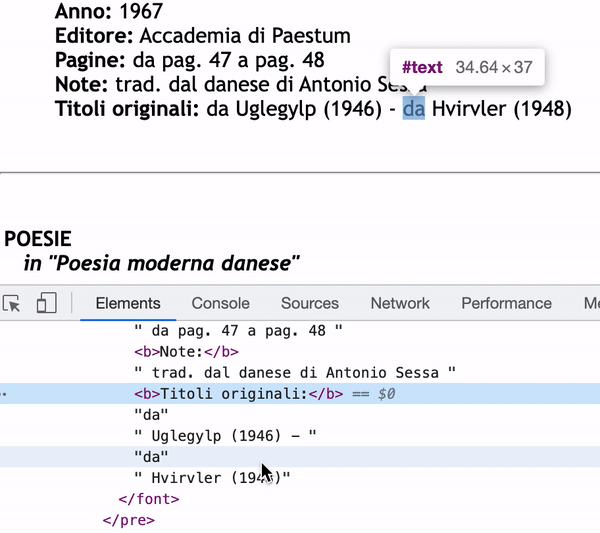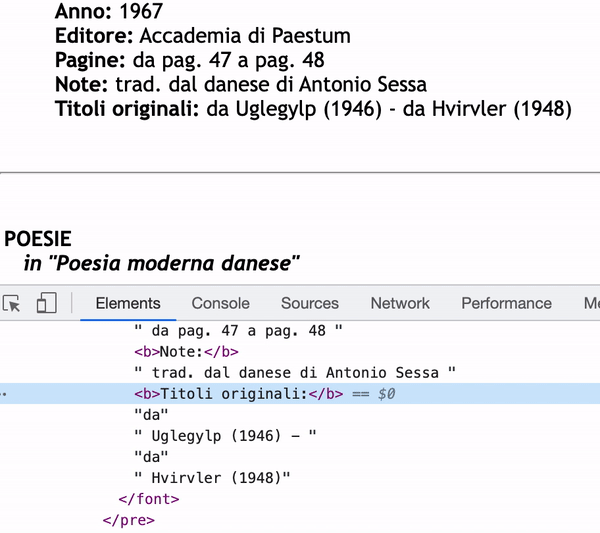
正如您在檢查器中看到的那樣,如果我使用 next_sibling , Titoli originali:的內容只會是“da” 。
有沒有辦法統一所有這些#text 部分?你會如何處理這個問題?謝謝
更新:
這是我正在抓取的網站 --> 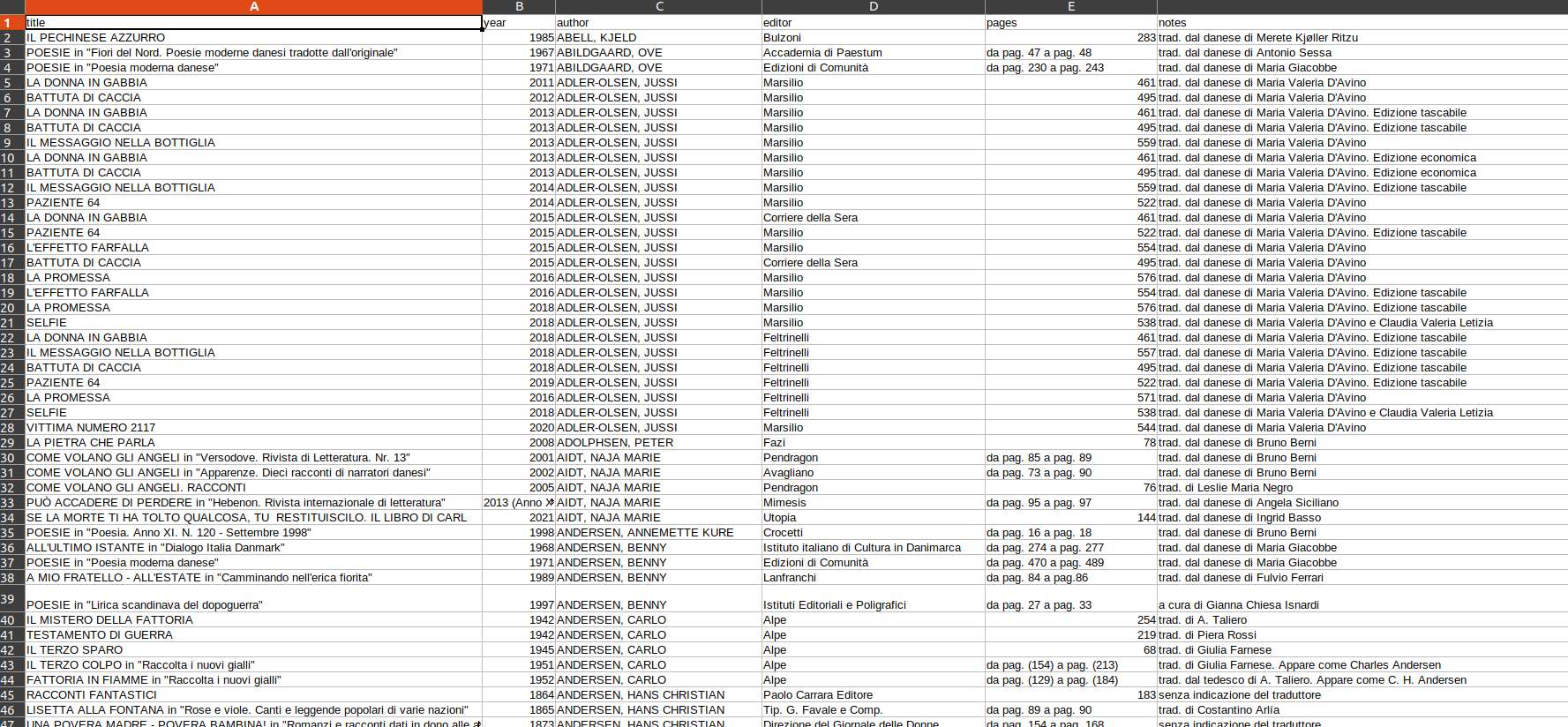
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/457780.html
標籤:Python html python-3.x 网页抓取 美丽的汤
上一篇:如何抓取網站上的特定資訊