我在使用sparkstreaming的時候遇見了一個奇怪的現象:spark進行reduce等計算的時候只是使用了其中的一部分excutor,并且很規律的是這些excutor都是在一臺機子上,不清楚這是什么原因,有人遇見過這種情況嗎嗎,一起討論一下?
uj5u.com熱心網友回復:
是你資料都來自于這臺機吧?你可以嘗試reparation后cache。然后在cache后的rdd/dataset上進行后續操作uj5u.com熱心網友回復:
不是的,我的資料來自kafka完全不是同一臺機子,同時我也進行了reparation,因為kafka上面有只四個磁區,所以我就將RDD磁區數目調高到了36,不是單單是磁區數目影響的,我嘗試將所有資料分到0區,有時候還是能正常分配,所以跟磁區數應該關系不是太大
uj5u.com熱心網友回復:
是指你從kafka讀取資料的receiver是一臺機子。另外關鍵是cache,而不是reparation。cache可以在spark內部設定最多2個的資料磁區副本,也就是理論上會把資料分布到每臺機子(只要磁區數夠分配)。
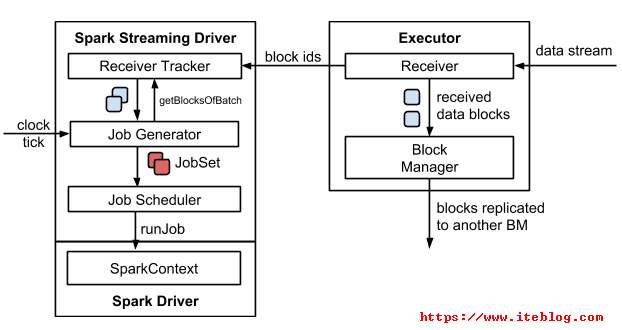
sparkStreaming的receiver,本質也是一個executor。對于一個流的RDD,這executor的機器,就是資料來源機。
uj5u.com熱心網友回復:
昨天忘了說了,其實我是有過reparation后cache的,因為后面有兩個地方會用到這個rdd,因此我進行了cache

uj5u.com熱心網友回復:
樓主好。我也遇到了這個問題,所有的task全部都集中到了一臺機器上,但是確定是資料在多臺機器上的。uj5u.com熱心網友回復:
樓主好,我也遇到了這個問題,所有的job都集中到了一臺機器上算,但是資料是在多臺機器上的。請問樓主怎么解決了。
uj5u.com熱心網友回復:
不清楚是什么原因,你重啟兩次服務試試看看是不是一直都是這臺機子運行,觀察一下資源是不是夠用
uj5u.com熱心網友回復:
問題已經解決了,通過查看work的錯誤日志發現,slave節點與主節點netty通信出現了例外,然后查看SPARK_CLASSPATH路徑下的netty相關的jar包沖突了。去掉一個就好了。轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/45787.html
標籤:Spark
上一篇:微信小程式 藍牙重連例外 errCode:10004,errMsg:notifyBLECharacteristicValueChange:fail setNot