作者:程德昊,Fluent Member,KubeSphere Member
Fluent Operator? 介紹
隨著云原生技術的快速發展,技術的不斷迭代,對于日志的采集、處理及轉發提出了更高的要求,云原生架構下的日志方案相比基于物理機或者是虛擬機場景的日志架構設計存在很大差別,作為 CNCF 的畢業專案,Fluent Bit 無疑為解決云環境中的日志記錄問題的首選解決方案之一,但是在 Kubernetes 中安裝部署以及配置 Fluent Bit 都具有一定的門檻,加大了用戶的使用成本,
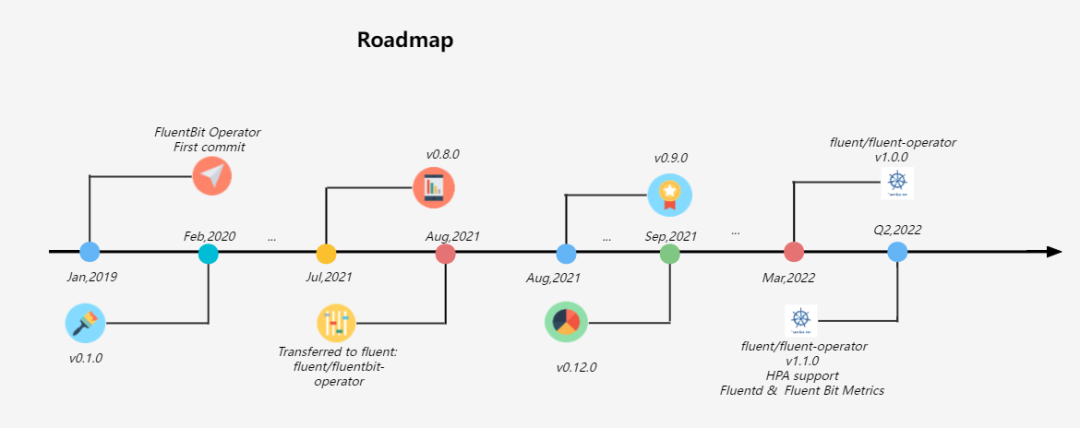
2019 年 1 月 21 日,KubeSphere 社區為了滿足以云原生的方式管理 Fluent Bit 的需求開發了 Fluentbit Operator,并在 2020 年 2 月 17 日發布了 v0.1.0 版本,此后產品不斷迭代,在 2021 年 8 月 4 日 正式將 Fluentbit Operator 捐獻給 Fluent 社區,
Fluentbit Operator 降低了 Fluent Bit 的使用門檻,能高效、快捷的處理日志資訊,但是 Fluent Bit 處理日志的能力稍弱,我們還沒有集成日志處理工具,比如 Fluentd,它有更多的插件可供使用,基于以上需求,Fluentbit Operator 集成了 Fluentd,旨在將 Fluentd 集成為一個可選的日志聚合和轉發層,并重新命名為 Fluent Operator(GitHub 地址:https://github.com/fluent/fluent-operator),在 2022 年 3 月 25 日 Fluent Operator 發布了 v1.0.0 版本,并將繼續迭代 Fluentd Operator,預計在 2022 年第 2 季度發布 v1.1.0 版本,增加更多的功能與亮點,
使用 Fluent Operator 可以靈活且方便地部署、配置及卸載 Fluent Bit 以及 Fluentd,同時, 社區還提供支持 Fluentd 以及 Fluent Bit 的海量插件,用戶可以根據實際情況進行定制化配置,官方檔案提供了詳細的示例,極易上手,大大降低了 Fluent Bit 以及 Fluentd 的使用門檻,
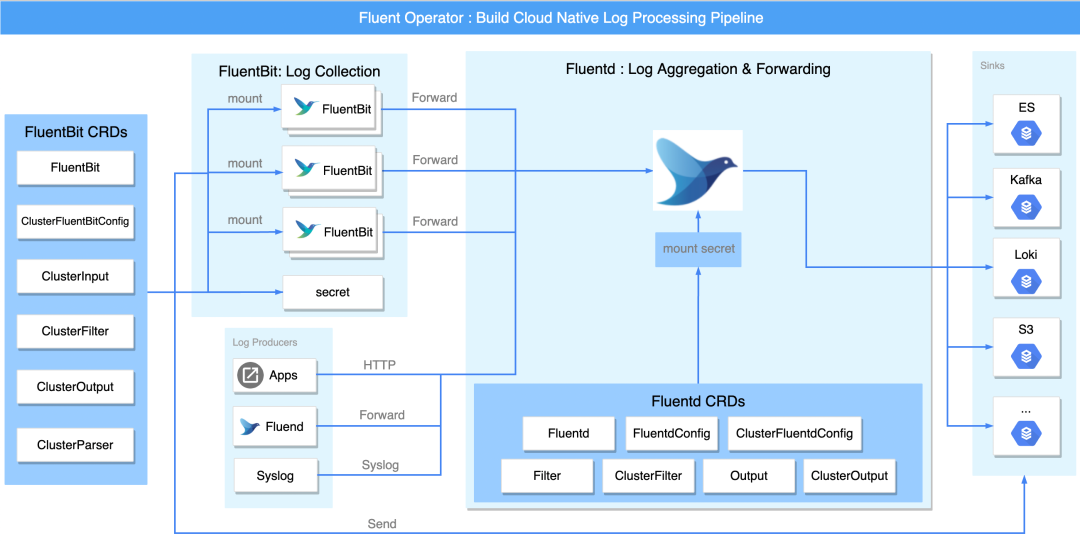
日志流水線的各個階段
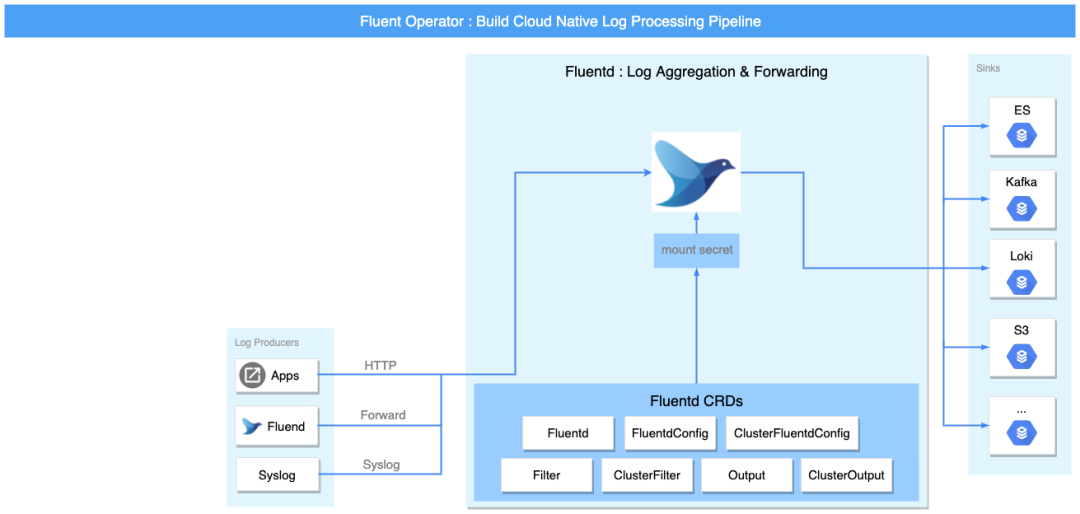
Fluent Operator 可以單獨部署 Fluent Bit 或者 Fluentd,并不會強制要求使用 Fluent Bit 或 Fluentd,同時還支持使用 Fluentd 接收 Fluent Bit 轉發的日志流進行多租戶日志隔離,這極大地增加了部署的靈活性和多樣性, 為了更全面的了解 Fluent Operator,下圖以完整的日志流水線為例,將流水線分為三部分:采集和轉發、過濾以及輸出,
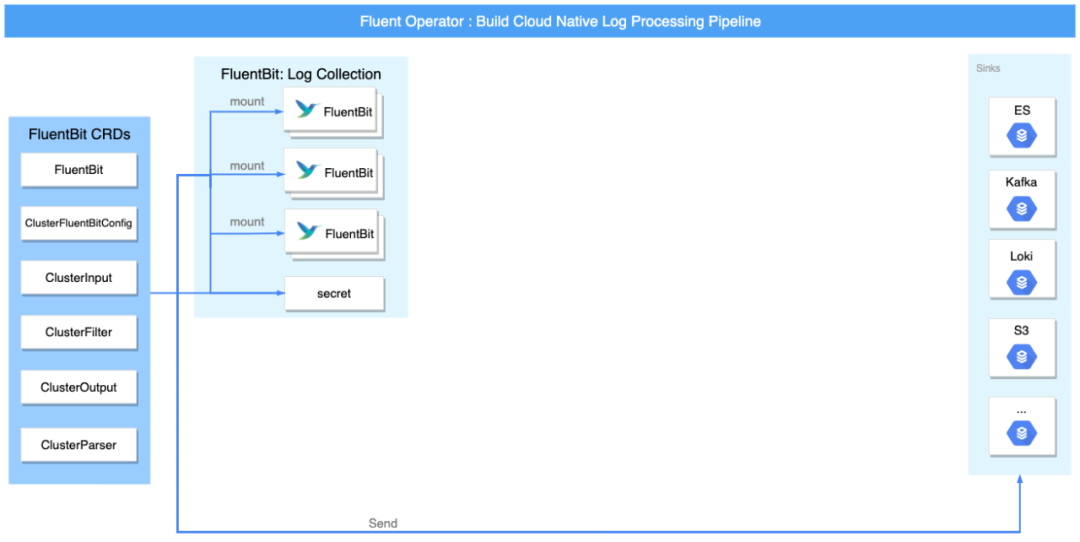
采集和轉發
Fluent Bit 與 Fluentd 均可以采集日志,
單獨部署時,可以通過 Fluent Bit 的 intput 插件或者 Fluentd 的 forward 以及 http 等插件來滿足對日志收集的需求,兩者結合時,Fluentd 可使用 forward 接受 Fluent Bit 的日志流轉發,
在性能方面,Fluent Bit 相比 Fluentd 更輕量,記憶體消耗更小(約為 650KB),所以主要由 Fluent Bit 負責采集與轉發日志,在各個節點上通過以 DaemonSet 形式安裝的 Fluent Bit 來收集和轉發日志,
過濾
日志收集的資料往往過于雜亂與冗余,這要求日志處理中間件提供對日志資訊進行過濾和處理的能力,Fluent Bit 或 Fluentd 均支持 filter 插件,用戶可以根據自身需求,整合和定制日志資料,
輸出
Fluent Bit output 或 Fluentd output 插件將處理后的日志資訊輸出到多個目的地,目的地可以是 Kafka、Elasticsearch 等第三方組件,
CRD 簡介
Fluent Operator 為 Fluent Bit 和 Fluentd 分別定義了兩個 Group:fluentbit.fluent.io 和 fluentd.fluent.io,
fluentbit.fluent.io
fluentbit.fluent.io? 分組下包含以下 6 個 CRDs:
- Fluentbit CRD 定義了 Fluent Bit 的屬性,比如鏡像版本、污點、親和性等引數,
- ClusterFluentbitConfig CRD 定義了 Fluent Bit 的組態檔,
- ClusterInput CRD 定義了 Fluent Bit 的 input 插件,即輸入插件,通過該插件,用戶可以自定義采集何種日志,
- ClusterFilter CRD 定義了 Fluent Bit 的 filter 插件,該插件主要負責過濾以及處理 fluentbit 采集到的資訊,
- ClusterParser CRD 定義了 Fluent Bit 的 parser 插件,該插件主要負責決議日志資訊,可以將日志資訊決議為其他格式,
- ClusterOutput CRD 定義了 Fluent Bit 的 output 插件,該插件主要負責將處理后的日志資訊轉發到目的地,
fluentd.fluent.io
fluentd.fluent.io? 分組下包含以下 7 個 CRDs:
- Fluentd CRD 定義了 Fluentd 的屬性,比如鏡像版本、污點、親和性等引數,
- ClusterFluentdConfig CRD 定義了 Fluentd 集群級別的組態檔,
- FluentdConfig CRD 定義了 Fluentd 的 namespace 范圍的組態檔,
- ClusterFilter CRD 定義了 Fluentd 集群范圍的 filter 插件,該插件主要負責過濾以及處理 Fluentd 采集到的資訊,如果安裝了 Fluent Bit,則可以更進一步的處理日志資訊,
- Filter CRD 該 CRD 定義了 Fluentd namespace 的 filter 插件,該插件主要負責過濾以及處理 Fluentd 采集到的資訊,如果安裝了 Fluent Bit,則可以更進一步的處理日志資訊,
- ClusterOutput CRD 該 CRD 定義了 Fluentd 的集群范圍的 output 插件,該插件主要負責將處理后的日志資訊轉發到目的地,
- Output CRD 該 CRD 定義了 Fluentd 的 namespace 范圍的 output 插件,該插件主要負責將處理后的日志資訊轉發到目的地,
編排原理簡介 (instance + mounted secret + CRD 的抽象能力)
盡管 Fluent Bit 與 Fluentd 都有收集、處理(決議和過濾)以及輸出日志的能力,但它們有著不同的優點,Fluent Bit 相對 Fluentd 更為輕量與高效,而 Fluentd 插件更為豐富,
為了兼顧這些優點,Fluent Operator 允許用戶以多種方式靈活地使用 Fluent Bit 和 Fluentd:
- Fluent Bit only 模式:如果您只需要在收集日志并在簡單處理后將日志發送到最終目的地,您只需要 Fluent Bit,
- Fluentd only 模式:如果需要通過網路以 HTTP 或 Syslog 等方式接收日志,然后將日志處理并發送到最終的目的地,則只需要 Fluentd,
- Fluent Bit + Fluentd 模式:如果你還需要對收集到的日志進行一些高級處理或者發送到更多的 sink,那么你可以組合使用 Fluent Bit 和 Fluentd,
Fluent Operator 允許您根據需要在上述 3 種模式下配置日志處理管道,Fluentd 與 Fluent Bit 具有豐富的插件以滿足用戶的各種自定義化需求,由于 Fluentd 與 Fluent Bit 的配置掛載方式相似,所以以 Fluent Bit 組態檔的掛載方式來進行簡單介紹,
在 Fluent Bit CRD 中每個 ClusterInput, ClusterParser, ClusterFilter,ClusterOutput 代表一個 Fluent Bit 配置部分,由 ClusterFluentBitConfig 標簽選擇器選擇,Fluent Operator 監視這些物件,構建最終配置,最后創建一個 Secret 來存盤安裝到 Fluent Bit DaemonSet 中的配置,整個作業流程如下所示:

因為 Fluent Bit 本身沒有重新加載介面(詳細資訊請參閱此已知問題),為了使 Fluent Bit 能夠在 Fluent Bit 配置更改時獲取并使用最新配置,添加了一個名為 fluentbit watcher 的包裝器,以便在檢測到 Fluent Bit 配置更改時立即重新啟動 Fluent Bit 行程,這樣,無需重新啟動 Fluent Bit pod 即可重新加載新配置,
為了使用戶配置更為方便,我們基于 CRD 強大的抽象能力將應用以及配置的引數提取出來,用戶可以通過定義的 CRD 來對 Fluent Bit 以及 Fluentd 進行配置,Fluent Operator 監控這些物件的變化從而更改 Fluent Bit 以及 Fluentd 的狀態及配置,特別是插件的定義,為了使用戶更為平滑地過渡,我們在命名上基本與 Fluent Bit 原有的欄位保持一致,降低使用的門檻,
如何實作多租戶日志隔離
Fluent Bit 可以高效的采集日志,但是如果需要對日志資訊進行復雜處理,Fluent Bit 則稍顯力不從心,而 Fluentd 則可以借助其豐富的插件完成對日志資訊的高級處理,fluent-operator 為此抽象了 Fluentd 的各種插件,以便可以對日志資訊進行處理來滿足用戶的自定義需求,
從上面 CRD 的定義可以看出,我們將 Fluentd 的 config 及插件的 CRD 分成了 cluster 級別與 namespace 級別的 CRD,通過將 CRD 定義為兩種范圍,借助 Fluentd 的 label router 插件,就可以達到多租戶隔離的效果,
我們在 clusterfluentconfig 添加了 watchNamespace 欄位,用戶可以根據自己的需求選擇監聽哪些 namespace,如果為空,則表示監控所有的 namespace,而 namesapce 級別的 fluentconfig 只能監聽自己所位于的 namespace 中的 CR 及全域級別的配置,所以 namespace 級別的日志既可以輸出到該 namespace 中的 output,也可以輸出到 clsuter 級別的 output,從而達到多租戶隔離的目的,
Fluent Operator vs logging-operator
差別
- 兩者皆可自動部署 Fluent Bit 與 Fluentd,logging-operator 需要同時部署 Fluent Bit 和 Fluentd,而 Fluent Operator 支持可插拔部署 Fluent Bit 與 Fluentd,非強耦合,用戶可以根據自己的需要自行選擇部署 Fluentd 或者是 Fluent Bit,更為靈活,
- 在 logging-operator 中 Fluent Bit 收集的日志都必須經過 Fluentd 才能輸出到最終的目的地,而且如果資料量過大,那么 Fluentd 存在單點故障隱患,Fluent Operator 中 Fluent Bit 可以直接將日志資訊發送到目的地,從而規避單點故障的隱患,
- logging-operator 定義了 loggings,outputs,flows,clusteroutputs 以及 clusterflows 四種 CRD,而 Fluent Operator 定義了 13 種 CRD,相較于 logging-operator,Fluent Operator 在 CRD 定義上更加多樣,用戶可以根據需要更靈活的對 Fluentd 以及 Fluent Bit 進行配置,同時在定義 CRD 時,選取與 Fluentd 以及 Fluent Bit 配置類似的命名,力求命名更加清晰,以符合原生的組件定義,
- 兩者均借鑒了 Fluentd 的 label router 插件實作多租戶日志隔離,
展望:
- 支持 HPA 自動伸縮;
- 完善 Helm Chart,如收集 metrics 資訊;
- ...
用法詳解
借助 Fluent Operator 可以對日志進行復雜處理,在這里我們可以通過 fluent-operator-walkthrough 中將日志輸出到 elasticsearch 與 kafka 的例子對 Fluent Operator 的實際功能進行介紹,要獲得 Fluent Operator 的一些實際操作經驗,您需要一個 Kind 集群,同時你還需要在這種型別的集群中設定一個 Kafka 集群和一個 Elasticsearch 集群,
# 創建一個 kind 的集群并命名為 fluent
./create-kind-cluster.sh
# 在 Kafka namespace 下創建一個 Kafka 集群
./deploy-kafka.sh
# 在 elastic namespace 下創建一個 Elasticsearch 集群
./deploy-es.sh
Fluent Operator 控制 Fluent Bit 和 Fluentd 的生命周期,您可以使用以下腳本在 fluent 命名空間中啟動 Fluent Operator:
./deploy-fluent-operator.sh
Fluent Bit 和 Fluentd 都已被定義為 Fluent Operator 中的 CRD,您可以通過宣告 FluentBit 或 Fluentd 的 CR 來創建 Fluent Bit DaemonSet 或 Fluentd StatefulSet,
Fluent Bit Only 模式
Fluent Bit Only 將只啟用輕量級的 Fluent Bit 對日志進行采集、處理以及轉發,
使用 Fluent Bit 收集 kubelet 的日志并輸出到 Elasticsearch
cat <<EOF | kubectl apply -f -
apiVersion: fluentbit.fluent.io/v1alpha2
kind: FluentBit
metadata:
name: fluent-bit
namespace: fluent
labels:
app.kubernetes.io/name: fluent-bit
spec:
image: kubesphere/fluent-bit:v1.8.11
positionDB:
hostPath:
path: /var/lib/fluent-bit/
resources:
requests:
cpu: 10m
memory: 25Mi
limits:
cpu: 500m
memory: 200Mi
fluentBitConfigName: fluent-bit-only-config
tolerations:
- operator: Exists
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterFluentBitConfig
metadata:
name: fluent-bit-only-config
labels:
app.kubernetes.io/name: fluent-bit
spec:
service:
parsersFile: parsers.conf
inputSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
filterSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
outputSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterInput
metadata:
name: kubelet
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
spec:
systemd:
tag: service.kubelet
path: /var/log/journal
db: /fluent-bit/tail/kubelet.db
dbSync: Normal
systemdFilter:
- _SYSTEMD_UNIT=kubelet.service
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterFilter
metadata:
name: systemd
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
spec:
match: service.*
filters:
- lua:
script:
key: systemd.lua
name: fluent-bit-lua
call: add_time
timeAsTable: true
---
apiVersion: v1
data:
systemd.lua: |
function add_time(tag, timestamp, record)
new_record = {}
timeStr = os.date("!*t", timestamp["sec"])
t = string.format("%4d-%02d-%02dT%02d:%02d:%02d.%sZ",
timeStr["year"], timeStr["month"], timeStr["day"],
timeStr["hour"], timeStr["min"], timeStr["sec"],
timestamp["nsec"])
kubernetes = {}
kubernetes["pod_name"] = record["_HOSTNAME"]
kubernetes["container_name"] = record["SYSLOG_IDENTIFIER"]
kubernetes["namespace_name"] = "kube-system"
new_record["time"] = t
new_record["log"] = record["MESSAGE"]
new_record["kubernetes"] = kubernetes
return 1, timestamp, new_record
end
kind: ConfigMap
metadata:
labels:
app.kubernetes.io/component: operator
app.kubernetes.io/name: fluent-bit-lua
name: fluent-bit-lua
namespace: fluent
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterOutput
metadata:
name: es
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
spec:
matchRegex: (?:kube|service)\.(.*)
es:
host: elasticsearch-master.elastic.svc
port: 9200
generateID: true
logstashPrefix: fluent-log-fb-only
logstashFormat: true
timeKey: "@timestamp"
EOF
使用 Fluent Bit 收集 kubernetes 的應用日志并輸出到 Kafka
cat <<EOF | kubectl apply -f -
apiVersion: fluentbit.fluent.io/v1alpha2
kind: FluentBit
metadata:
name: fluent-bit
namespace: fluent
labels:
app.kubernetes.io/name: fluent-bit
spec:
image: kubesphere/fluent-bit:v1.8.11
positionDB:
hostPath:
path: /var/lib/fluent-bit/
resources:
requests:
cpu: 10m
memory: 25Mi
limits:
cpu: 500m
memory: 200Mi
fluentBitConfigName: fluent-bit-config
tolerations:
- operator: Exists
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterFluentBitConfig
metadata:
name: fluent-bit-config
labels:
app.kubernetes.io/name: fluent-bit
spec:
service:
parsersFile: parsers.conf
inputSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
filterSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
outputSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterInput
metadata:
name: tail
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
spec:
tail:
tag: kube.*
path: /var/log/containers/*.log
parser: docker
refreshIntervalSeconds: 10
memBufLimit: 5MB
skipLongLines: true
db: /fluent-bit/tail/pos.db
dbSync: Normal
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterFilter
metadata:
name: kubernetes
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
spec:
match: kube.*
filters:
- kubernetes:
kubeURL: https://kubernetes.default.svc:443
kubeCAFile: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
kubeTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
labels: false
annotations: false
- nest:
operation: lift
nestedUnder: kubernetes
addPrefix: kubernetes_
- modify:
rules:
- remove: stream
- remove: kubernetes_pod_id
- remove: kubernetes_host
- remove: kubernetes_container_hash
- nest:
operation: nest
wildcard:
- kubernetes_*
nestUnder: kubernetes
removePrefix: kubernetes_
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterOutput
metadata:
name: kafka
labels:
fluentbit.fluent.io/enabled: "false"
fluentbit.fluent.io/mode: "k8s"
spec:
matchRegex: (?:kube|service)\.(.*)
kafka:
brokers: my-cluster-kafka-bootstrap.kafka.svc:9091,my-cluster-kafka-bootstrap.kafka.svc:9092,my-cluster-kafka-bootstrap.kafka.svc:9093
topics: fluent-log
EOF
Fluent Bit + Fluentd 模式
憑借 Fluentd 豐富的插件,Fluentd 可以充當日志聚合層,執行更高級的日志處理,您可以使用 Fluent Operator 輕松地將日志從 Fluent Bit 轉發到 Fluentd,
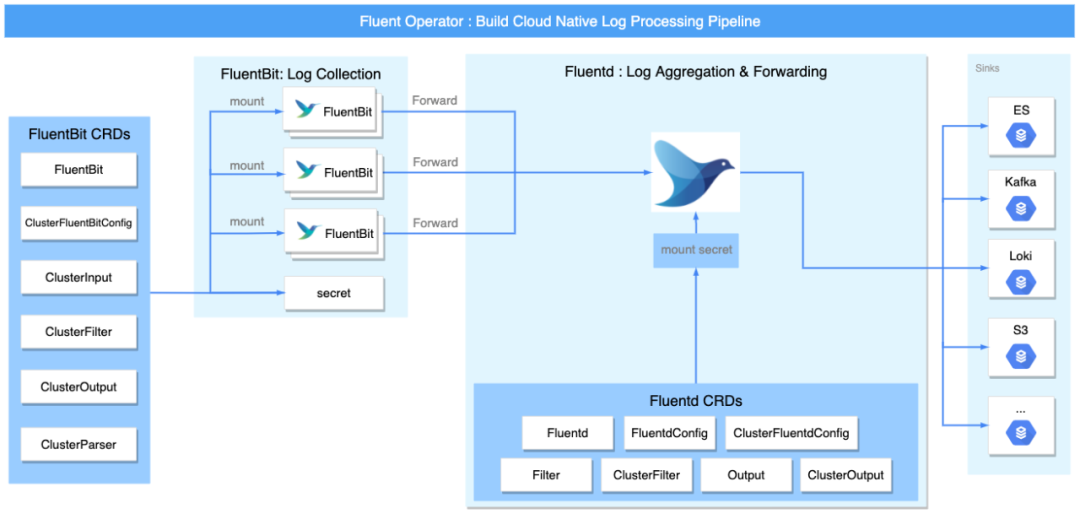
將日志從 Fluent Bit 轉發到 Fluentd
要將日志從 Fluent Bit 轉發到 Fluentd,您需要啟用 Fluent Bit 的 forward 插件,如下所示:
cat <<EOF | kubectl apply -f -
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterOutput
metadata:
name: fluentd
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/component: logging
spec:
matchRegex: (?:kube|service)\.(.*)
forward:
host: fluentd.fluent.svc
port: 24224
EOF
部署 Fluentd
Fluentd forward Input 插件會在部署 Fluentd 時默認啟用,因此你只需要部署下列 yaml 來部署 Fluentd:
apiVersion: fluentd.fluent.io/v1alpha1
kind: Fluentd
metadata:
name: fluentd
namespace: fluent
labels:
app.kubernetes.io/name: fluentd
spec:
globalInputs:
- forward:
bind: 0.0.0.0
port: 24224
replicas: 1
image: kubesphere/fluentd:v1.14.4
fluentdCfgSelector:
matchLabels:
config.fluentd.fluent.io/enabled: "true"
ClusterFluentdConfig: Fluentd 集群范圍的配置
如果你定義了 ClusterFluentdConfig,那么你可以收集任意或者所有 namespace 下的日志,我么可以通過 watchedNamespaces 欄位來選擇所需要采集日志的 namespace,以下配置是采集 kube-system 以及 default namespace 下的日志:
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- default
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/scope: "cluster"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-es
labels:
output.fluentd.fluent.io/scope: "cluster"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-cluster-fd
EOF
FluentdConfig: Fluentd namespace 范圍的配置
如果你定義了 FluentdConfig,那么你只能將與該 FluentdConfig 同一 namespace 下的日志發送到 Output,通過這種方式實作了不同 namespace 下的日志隔離,
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: FluentdConfig
metadata:
name: namespace-fluentd-config
namespace: fluent
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
outputSelector:
matchLabels:
output.fluentd.fluent.io/scope: "namespace"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: Output
metadata:
name: namespace-fluentd-output-es
namespace: fluent
labels:
output.fluentd.fluent.io/scope: "namespace"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-namespace-fd
EOF
根據 namespace 將日志路由到不同的 Kafka topic
同樣您可以使用 Fluentd 的 filter 插件根據不同的 namespace 將日志分發到不同的 topic,在這里我們包含在 Fluentd 內核中的插件 recordTransformer,該插件可以對事件進行增刪改查,
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config-kafka
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- default
clusterFilterSelector:
matchLabels:
filter.fluentd.fluent.io/type: "k8s"
filter.fluentd.fluent.io/enabled: "true"
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/type: "kafka"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFilter
metadata:
name: cluster-fluentd-filter-k8s
labels:
filter.fluentd.fluent.io/type: "k8s"
filter.fluentd.fluent.io/enabled: "true"
spec:
filters:
- recordTransformer:
enableRuby: true
records:
- key: kubernetes_ns
value: ${record["kubernetes"]["namespace_name"]}
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-kafka
labels:
output.fluentd.fluent.io/type: "kafka"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- kafka:
brokers: my-cluster-kafka-bootstrap.default.svc:9091,my-cluster-kafka-bootstrap.default.svc:9092,my-cluster-kafka-bootstrap.default.svc:9093
useEventTime: true
topicKey: kubernetes_ns
EOF
同時使用集群范圍與 namespace 范圍的 FluentdConfig
當然,你可以像下面一樣同時使用 ClusterFluentdConfig 與 FluentdConfig,FluentdConfig 會將 fluent namespace 下的日志發送到 ClusterOutput,而 ClusterFluentdConfig 同時也會將 watchedNamespaces 欄位下的 namespace(即 kube-system 以及 default 兩個 namespace)發送到 ClusterOutput,
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config-hybrid
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- default
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/scope: "hybrid"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: FluentdConfig
metadata:
name: namespace-fluentd-config-hybrid
namespace: fluent
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/scope: "hybrid"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-es-hybrid
labels:
output.fluentd.fluent.io/scope: "hybrid"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-hybrid-fd
EOF
在多租戶場景下同時使用集群范圍與 namespace 范圍的 FluentdConfig
在多租戶場景下,我們可以同時使用集群范圍與 namespace 范圍的 FluentdConfig 達到日志隔離的效果,
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: FluentdConfig
metadata:
name: namespace-fluentd-config-user1
namespace: fluent
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
outputSelector:
matchLabels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/user: "user1"
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/user: "user1"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config-cluster-only
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- kubesphere-system
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/scope: "cluster-only"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: Output
metadata:
name: namespace-fluentd-output-user1
namespace: fluent
labels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/user: "user1"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-user1-fd
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-user1
labels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/user: "user1"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-cluster-user1-fd
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-cluster-only
labels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/scope: "cluster-only"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-cluster-only-fd
EOF
為 Fluentd 輸出使用緩沖區
您可以添加一個緩沖區來快取 output 插件的日志,
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config-buffer
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- default
clusterFilterSelector:
matchLabels:
filter.fluentd.fluent.io/type: "buffer"
filter.fluentd.fluent.io/enabled: "true"
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/type: "buffer"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFilter
metadata:
name: cluster-fluentd-filter-buffer
labels:
filter.fluentd.fluent.io/type: "buffer"
filter.fluentd.fluent.io/enabled: "true"
spec:
filters:
- recordTransformer:
enableRuby: true
records:
- key: kubernetes_ns
value: ${record["kubernetes"]["namespace_name"]}
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-buffer
labels:
output.fluentd.fluent.io/type: "buffer"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- stdout: {}
buffer:
type: file
path: /buffers/stdout.log
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-buffer-fd
buffer:
type: file
path: /buffers/es.log
EOF
Fluentd Only 模式
你同樣可以開啟 Fluentd Only 模式,該模式只會部署 Fluentd statefulset,
使用 Fluentd 從 HTTP 接收日志并輸出到標準輸出
如果你想單獨開啟 Fluentd 插件,你可以通過 HTTP 來接收日志,
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: Fluentd
metadata:
name: fluentd-http
namespace: fluent
labels:
app.kubernetes.io/name: fluentd
spec:
globalInputs:
- http:
bind: 0.0.0.0
port: 9880
replicas: 1
image: kubesphere/fluentd:v1.14.4
fluentdCfgSelector:
matchLabels:
config.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: FluentdConfig
metadata:
name: fluentd-only-config
namespace: fluent
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
filterSelector:
matchLabels:
filter.fluentd.fluent.io/mode: "fluentd-only"
filter.fluentd.fluent.io/enabled: "true"
outputSelector:
matchLabels:
output.fluentd.fluent.io/mode: "true"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: Filter
metadata:
name: fluentd-only-filter
namespace: fluent
labels:
filter.fluentd.fluent.io/mode: "fluentd-only"
filter.fluentd.fluent.io/enabled: "true"
spec:
filters:
- stdout: {}
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: Output
metadata:
name: fluentd-only-stdout
namespace: fluent
labels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- stdout: {}
EOF
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/458289.html
標籤:其他