模型結構演進
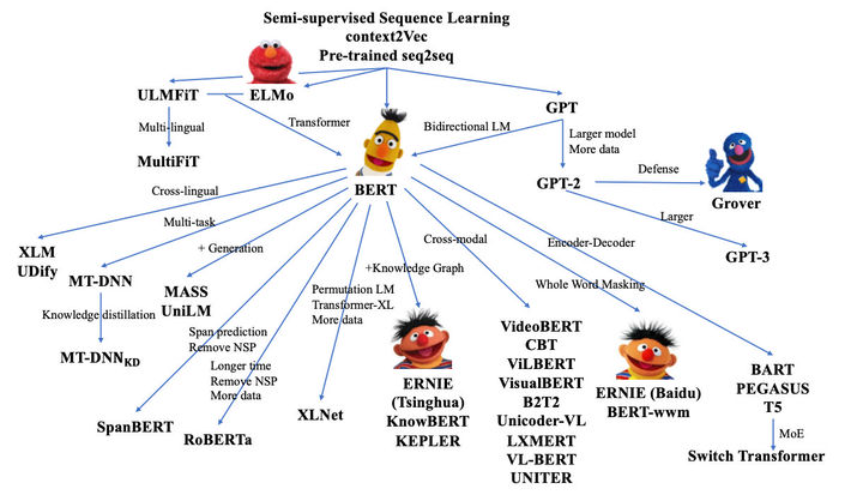
本文以演進方向和目的為線索梳理了一些我常見到但不是很熟悉的預訓練語言模型:
首先來看看“完全版的BERT”:
RoBERTa: A Robustly Optimized BERT Pretraining Approach(2019)可看成是完全體的BERT,主要3方面改進,首先采用了 Dynamic mask,即每個文本進入訓練時動態 mask 掉部分 token,相比原來的 Bert,可以達到同一個文本在不同 epoch 被 mask 掉的 token 不同,相當于做了一個資料增強,其次,不使用 NSP 任務,效果會有一定提升,最后,RoBERTa 增大了訓練時間和訓練資料、 batch size 以及對 BPE(輸入文本的分詞方法)進行了升級,
演進方向一:Unified Sequence Modeling
想做大統一的模型可以從兩方面著手,第一是任務混合,第二是結構混合,
任務混合指將NLU和NLG同時進行預訓練,比如XLNet、MPNet采用的Permutaioon language modeling,兼顧背景關系與自回歸;或者是UniLM, GLM采用的Multi-task training,通過對注意力矩陣的設計使得這兩種任務同時訓練,
結構混合則更多使用Seq2seq去做理解和生成,比如MASS、T5和BART,但也面臨如下挑戰:
- 編碼器-解碼器占用更多的引數,引數利用率較低(即使有引數共享)
- Seq2seq的結構在NLU任務上表現差,好于BERT但低于RoBERTa和GLM
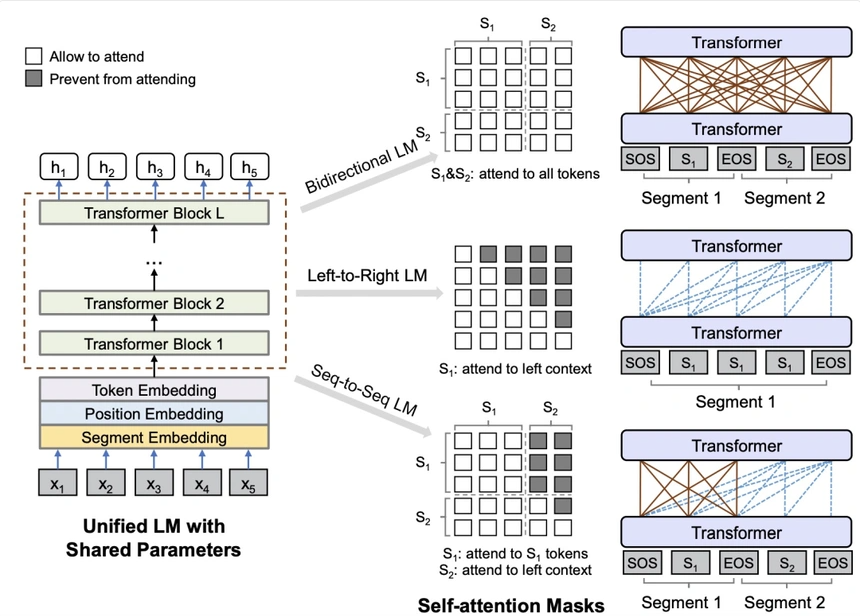
Unified Language Model Pre-training for Natural Language Understanding and Generation(NIPS 2019)提出了UniLM預訓練語言模型,本文認為EMLo采用前向+后向LSTM、GPT采用從左至右的單向Transformer、BERT采用雙向Attention都有優缺點,UniLM融合了3種語言模型優化目標,通過控制mask在一個模型中同時實作了3種語言模型優化任務,在pretrain程序交替使用3種優化目標,下圖比較形象的描述了UniLM是如何利用mask機制來控制3種不同的優化任務,核心思路是利用mask控制生成每個token時考慮哪些背景關系的資訊,
XLNet: Generalized Autoregressive Pretraining for Language Understanding(NIPS 2019)提出了XLNet模型,融合了BERT和GPT這兩類預訓練語言模型的優點,并且解決了BERT中pretrain和finetune階段存在不一致的問題(pretrain階段添加mask標記,finetune程序并沒有mask標記),XLNet融合了AR模型(類GPT,ELMo)和AE模型各自的優點,既能建模概率密度,適用于文本生成類任務,又能充分使用雙向背景關系資訊,XLNet實作AR和AE融合的主要思路為,對輸入文本進行排列組合,然后對于每個排列組合使用AR的方式訓練,不同排列組合使每個token都能和其他token進行資訊互動,同時每次訓練又都是AR的,
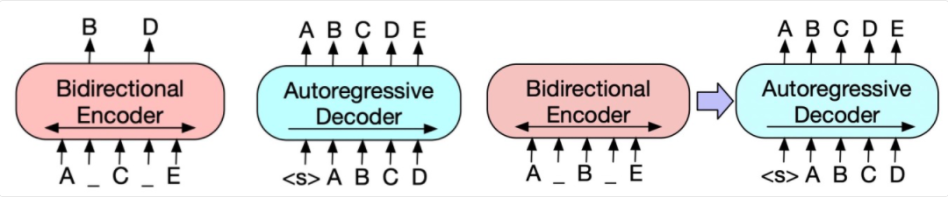
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension(2019)提出了一種新的預訓練范式,包括兩個階段:首先原文本使用某種noise function進行破壞,然后使用sequence-to-sequence模型還原原始的輸入文本,下圖中左側為Bert的訓練方式,中間為GPT的訓練方式,右側為BART的訓練方式,首先,將原始輸入文本使用某些noise function,得到被破壞的文本,這個文本會輸入到類似Bert的Encoder中,在得到被破壞文本的編碼后,使用一個類似GPT的結構,采用自回歸的方式還原出被破壞之前的文本,
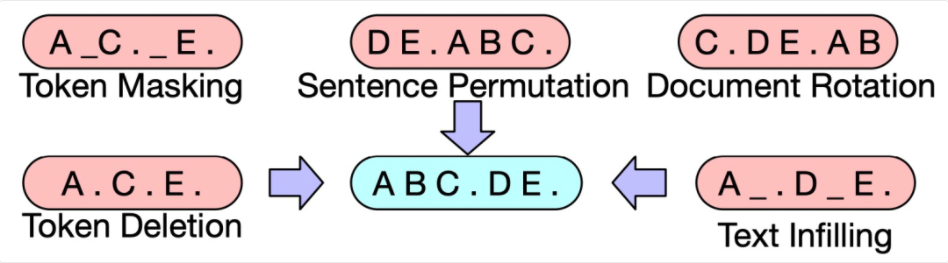
文中嘗試了多種型別的noise function,如token masking、sentence permutation、text infilling等,其中sentence permutation+text infilling的方式取得了最好的效果,Text infilling指的是隨機mask某些span,下圖展示了文中提出的一些noise function方法,
演進方向二:Cognitive-Inspired Architectures
為了模擬決策能力、邏輯推理能力、反實時推理能力(復盤),需要模型有短時記憶與長期記憶,短時記憶用來決策和推理,長期記憶用來回憶事實和經驗,
像Transformer-XL, CogQA, CogLTX這類模型,就是增加了Maintainable Working Memory,通過樣本維度的記憶提升長距離理解能力,實作推理;REALM, RAG這類模型則是對語料、物體或者三元組進行記憶,具有Sustainable Long-Term Memory,將資訊提前編碼,在需要的時候檢索出來,
演進方向三:提升mask策略
如SpanBERT、百度ERNIR、NEZHA、WWM
ERNIE: Enhanced Representation through Knowledge Integration(2019)ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding(2019)同名作業,主要關注用外部知識輔助設計預訓練任務,v1設計了entity-level的MLM任務,mask掉的不是單個token,而是輸入文本中某個entity對應的連續多個token;v2引入了更多task(如v1的entity-level mask、Capitalization Prediction Task、Token-Document Relation Prediction Task等),采用continual multitask learning的方式不斷構造新的任務,并且以增量的方式進行多任務學習,每來一個任務都把歷史所有任務放到一起進行多任務學習,避免忘記歷史學到的知識,
演進方向四:Knowledge-Enhanced Pre-Training
預訓練模型可以從大量語料中進行學習,但知識圖譜、領域知識不一定能學到,
對于這個問題可以有兩種解決方案,一種是外掛型,把知識通過各種方法和文本一起輸入進去,比如清華ERNIE、K-BERT,另一種是強迫型,在領域資料、結構化文本上精調,讓模型記住這些知識,比如百度ERNIE、WWM,
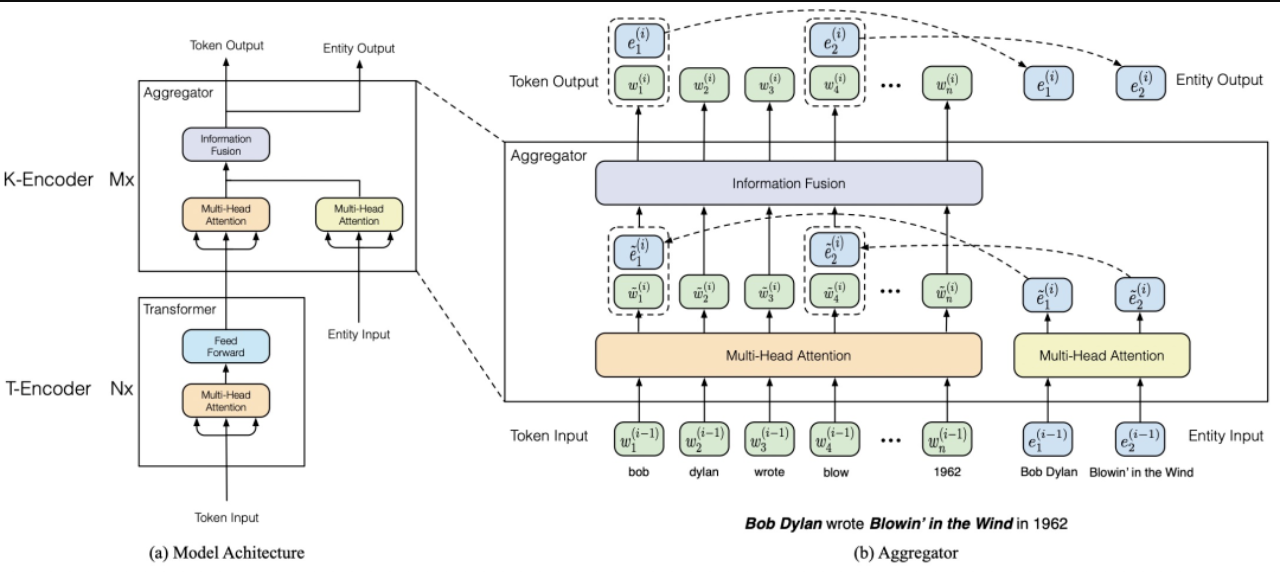
ERNIE: Enhanced Language Representation with Informative Entities(2019)則引入知識圖譜對BERT進行優化,模型主要分為T-Encoder和K-Encoder兩個部分,T-Encoder類似BERT,K-Encoder識別輸入文本中的物體并獲取這些物體的embedding,然后融合到輸入文本的對應token位置,每層都會融合上一層的token embedding和entity embedding,此外,ERNIE在預訓練階段增加了token-entity relation mask任務,在20%的entity上,會mask掉token和entity的對齊關系,讓模型來預測當前token對應的是哪個entity,
演進方向五:模型壓縮
引數共享、模型剪枝(可以修剪head或者砍掉層)、知識蒸餾、模型量化(FP16等,低位元模型跟硬體強相關,很難泛化)
ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS(2020)提出了一個輕量級的Bert模型,以此降低Bert的運行開銷,本文主要提出了兩個優化:首先是Factorized embedding parameterization,即對輸入的embedding進行分解,原始的Bert將token輸入的embedding維度E和模型隱藏層維度H系結了,即E=H,本文提出可以讓E和H解綁,將E變成遠小于H的維度,再用一層全連接將輸入embedding映射到H維,這樣模型embedding部分引數量從$V$$H$下降到了$V$$E+E*H$,Cross-layer parameter sharing,前者Cross-layer parameter sharing讓Bert每層的引數是共享的,以此來減小模型引數量,除了上述兩個降低Bert運行開銷的優化外,ALBERT提出了inter-senetnce loss這一新的優化目標,原來Bert中的NSP任務可以理解為topic prediction和coherence prediction兩個任務,其中topic prediction是一種特別簡單的任務,由于其任務的簡單性,導致coherence prediction學習程度不足,本文提出將coherence prediction單獨分離出來,相比Bert,正樣本仍然是一個document相鄰的兩個segment,負樣本變成這兩個segment的順序交換,
演進方向六:Multilingual Pre-Training
BERT之前的跨語言學習主要有兩種方法:
- 引數共享,比如使用跨語言平行語料讓模型可以同時學到不同知識
- 學習語言無關的約束,將編碼結偶為語言相關的部分和無關的部分
有了預訓練方法之后,我們就可以在不同語言進行預訓練了,mBERT在Wiki資料上進行多語言的MLM,之后XLM-R用了更好的語料后表現有所提升,但這兩個模型都沒有利用平行語料,于是XLM同時利用了平行語料,在平行語料做MLM,利用另一個語言的知識預測mask token,
后續研究還有Unicoder、ALM、InfoXLM、HICTL、ERNIE-M等,生成任務則有mBART、XNLG,
參考文獻:
https://mp.weixin.qq.com/s/NA29niCVDq1WD1vlwqTd_g
https://zhuanlan.zhihu.com/p/381282229
https://arxiv.org/abs/2106.07139
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/458528.html
標籤:其他
下一篇:小熊飛槳練習冊-02眼疾識別