偏差與方差
偏差(Bias)
用所有可能的訓練資料集訓練出的所有模型的輸出的平均值與真實模型的輸出值之間的差異,含義:度量了學習演算法的期望預測與真實結果的偏離程度,即刻畫了學習演算法本身的擬合能力,
其數學定義為 \(bias^2(x) = (\overline{f}(x) - y)^2\)
方差(variance)
不同的訓練資料集訓練出的模型輸出值之間的差異,含義:度量了同樣大小的訓練集的變動所導致的學習性能的變化,即刻畫了資料擾動所造成的影響,
其數學定義為
$var(x) = {\mathbb{E}}_{D}[(f(x;D) - \overline{f}(x))^2] $
而泛化誤差也就是錯誤率\(error = bias^2(x) + var(x) + \epsilon^2\),其中\(\epsilon\)為當前學習任務上的噪聲,
偏差-方差窘境
在訓練不足時,學習器的擬合能力不夠強,訓練資料的擾動不足以使學習器產生顯著變化,此時偏差主導了泛化錯誤率;隨著訓練程度的加深,學習器的擬合能力逐漸增強,訓練資料發生的擾動漸漸能被學習器學到,方差逐漸主導了泛化錯誤率;在訓練程度充足后,學習器的擬合能力已經非常強,訓練資料發生的輕微擾動都會導致學習器發生顯著變化,若訓練資料自身的、非全域的特性被學習器學到了,則將發生過擬合,
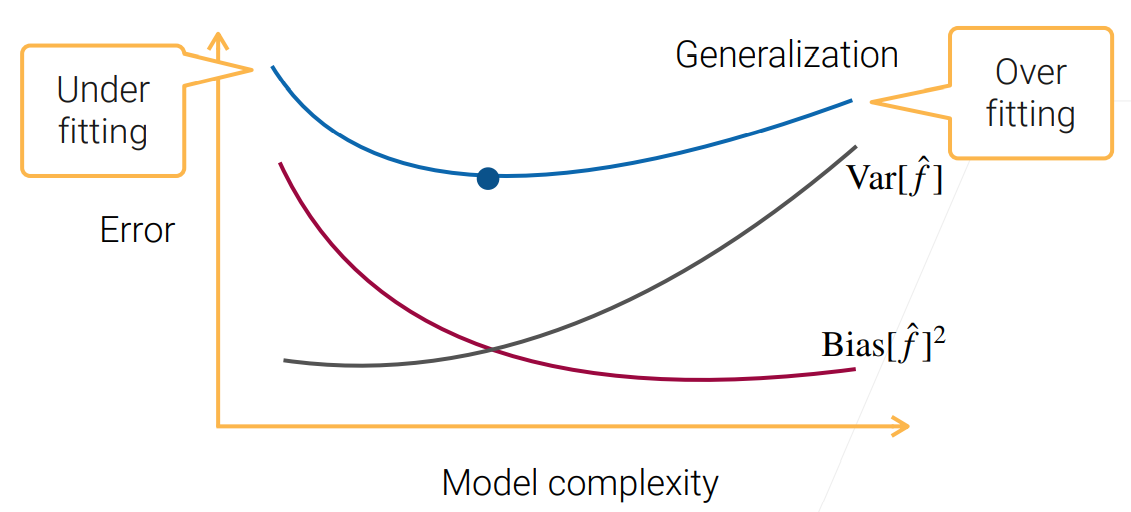
為什么能降低方差
對于每個樣本\(x\),假設在不同資料集上學習得到的模型對樣本的輸出服從某種分布\(\mathcal{L},G_1(x),G_2(x),\ldots,G_n(x)\)為來自分布獨立同分布的隨機變數,Bagging的集策略為對弱學習器求平均,即得到模型\(F(x) = \frac{G_1(x)+G_2(x)+\ldots+G_n(x)}{n}\)
設隨機變數\(Gi\)的方差為\(\delta^2\),則
\[var(F(x))=Var(\frac{G_1(x)+G_2(x)+\ldots+G_n(x)}{n}) = Var(\frac{G_1(x)}{n}+\frac{G_2(x)}{n}+\ldots+\frac{G_n(x)}{n}) = Var(\frac{\delta^2}{n^2}) * n = \frac{\delta^2}{n}\]可以看到Bagging集成之后方差變小了,也就是說在不同資料集上訓練得到的模型對樣本的預測值之間的差距變小,
若各子模型完全相同,而不是完全獨立,則
\[Var(F(x))=Var(\frac{G_1(x)+G_2(x)+\ldots+G_n(x)}{n}) = Var(\frac{G_1(x)}{n}+\frac{G_2(x)}{n}+\ldots+\frac{G_n(x)}{n}) = \delta^2\]此時并不會降低variance,bagging方法得到的各子模型是有一定相關性的,屬于上面兩個極端狀況的中間態,因此可以一定程度降低variance,但對于Adaboost來說,其子模型之間是強相關的,因此子模型之和并不能顯著降低variance,
為什么偏差不變
因為Bagging中的子樣本集具有相似性,因此各模型有近似相等的bias,由于模型之間雖不完全獨立,但模型之間也沒有強依賴關系,\(E[\frac{\sum {X_i}}{n}] = E[X_i]\)
因此單個模型和集成之后的模型關于樣本的預期值差別不大,bias也近似,而對于Boosting,其訓練好一個弱分類器之后計算錯誤作為下一個分類器的輸入,這個程序本身就是在不斷減小損失函式,來使得模型偏差不斷降低,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/458530.html
標籤:其他
上一篇:小熊飛槳練習冊-02眼疾識別