摘要:本文詳細介紹基于深度學習的手勢識別系統,在介紹手勢識別演算法原理的同時,給出了Python的實作代碼以及PyQt的UI界面,手勢識別采用了基于MediaPipe的改進SSD演算法,進行手掌檢測后對手部關節坐標進行關鍵點定位;在系統界面中可以選擇手勢圖片、視頻進行檢測識別,也可通過電腦連接的攝像頭設備進行實時識別手勢;可對影像中存在的多個手勢進行姿勢識別,可選擇任意一個手勢顯示結果并標注,實時檢測速度快、識別精度較高,博文提供了完整的Python代碼和使用教程,適合新入門的朋友參考,完整代碼資源檔案請轉至文末的下載鏈接,本博文目錄如下:
目錄- 前言
- 1. 效果演示
- 2. 手勢識別原理介紹
- 2.1 研究現狀
- 2.2 Mediapipe深度學習框架
- 2.3 手勢識別原理
- 2.4 代碼實作演示
- 下載鏈接
- 結束語
?點擊跳轉至文末所有涉及的完整代碼檔案下載頁?
完整資源下載鏈接:https://mianbaoduo.com/o/bread/mbd-YpmXlZ9s
代碼介紹及演示視頻鏈接:https://www.bilibili.com/video/BV12a411v7vr(正在更新中,歡迎關注博主B站視頻)
前言
隨著計算機性能的發展,人機互動越來越頻繁,在工程應用方面,計算機通過對手勢的分析理解,可以進一步開發出相應的遠程操控系統,在疫情當下,可以更好的實作零接觸操作,同時通過手勢也可以進一步了解人的表情與情感,例如在警匪影片中,通過手勢的微小變化,對罪犯的闡述進行分析判斷,但這只是更深層次的系統設想,
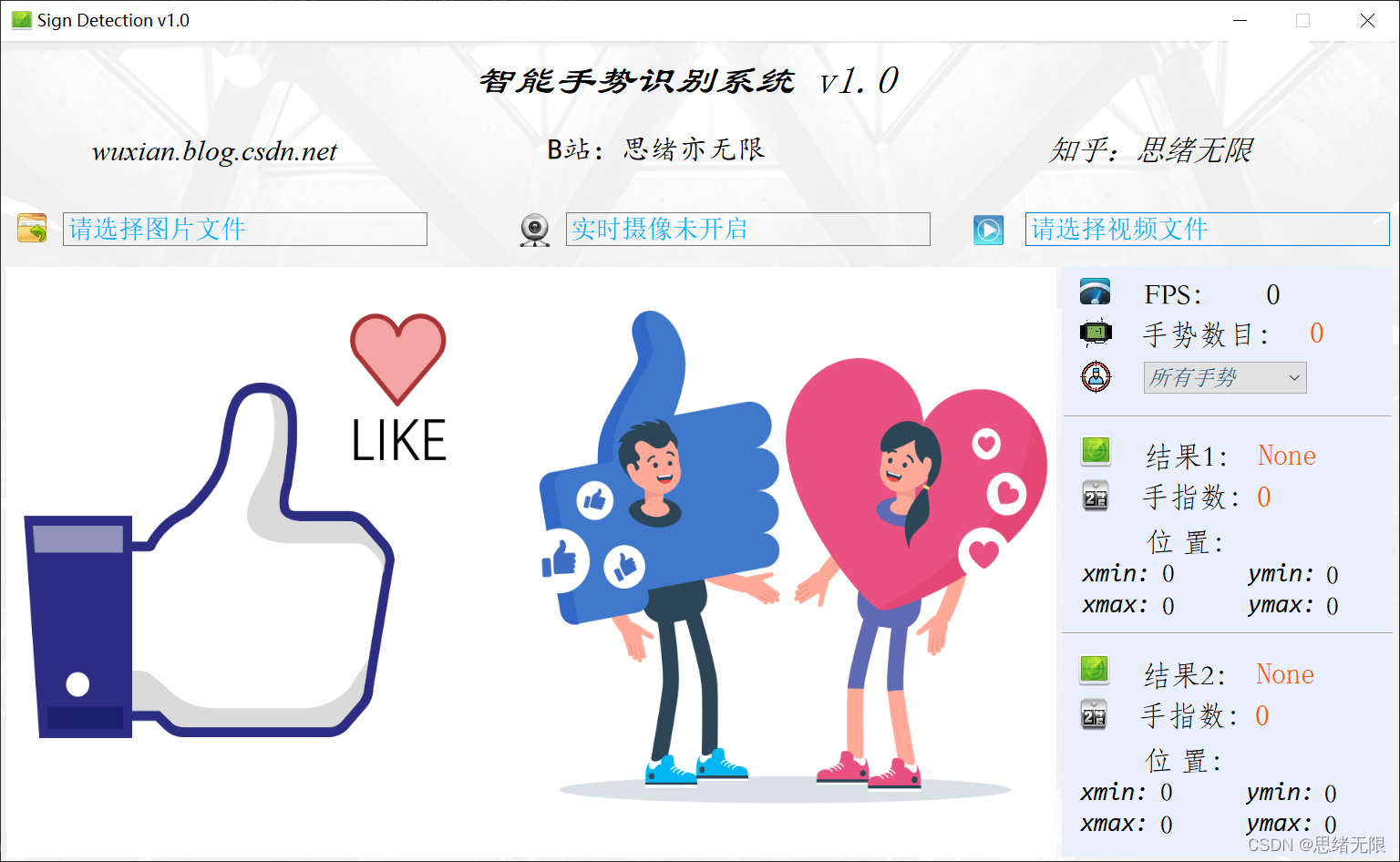
手勢識別是個計劃已久的專案,通過手勢可以傳達很多資訊,從而實作很多好玩的事情,比如石頭剪刀布、切水果等游戲,網上也有一些相關手勢識別的博客或代碼,不過很少有人對其進行詳細介紹,為了便于演示和交付用戶使用,我們將其開發成一個可以展示的完整軟體,方便選擇檔案和實時檢測,對此這里給出博主設計的界面,關注過的朋友可能清楚我的簡約風,功能上也滿足了圖片、視頻和攝像頭的識別檢測,希望大家可以喜歡,初始界面如下圖:
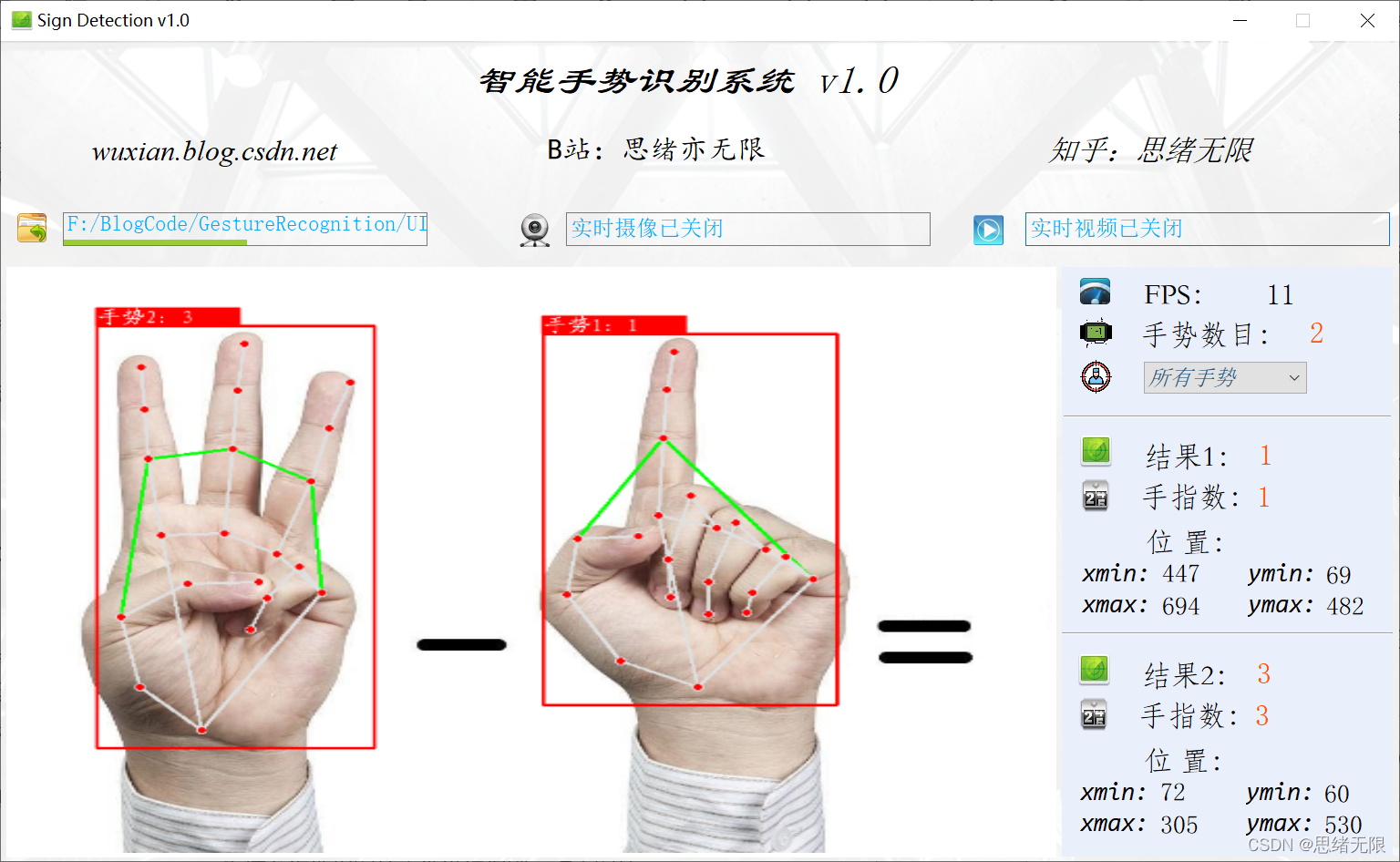
檢測手勢時的界面截圖(點擊圖片可放大)如下圖,可識別畫面中存在的多個手勢,也可開啟攝像頭或視頻檢測:
詳細的功能演示效果參見博主的B站視頻或下一節的動圖演示,覺得不錯的朋友敬請點贊、關注加收藏!系統UI界面的設計作業量較大,界面美化更需仔細雕琢,大家有任何建議或意見和可在下方評論交流,
1. 效果演示
手勢識別系統借助深度學習演算法,開發有選擇圖片識別、視頻識別以及攝像畫面識別,結果的可視化顯示功能,這里給出幾張動圖供大家參考,
(一)選擇手勢圖片識別
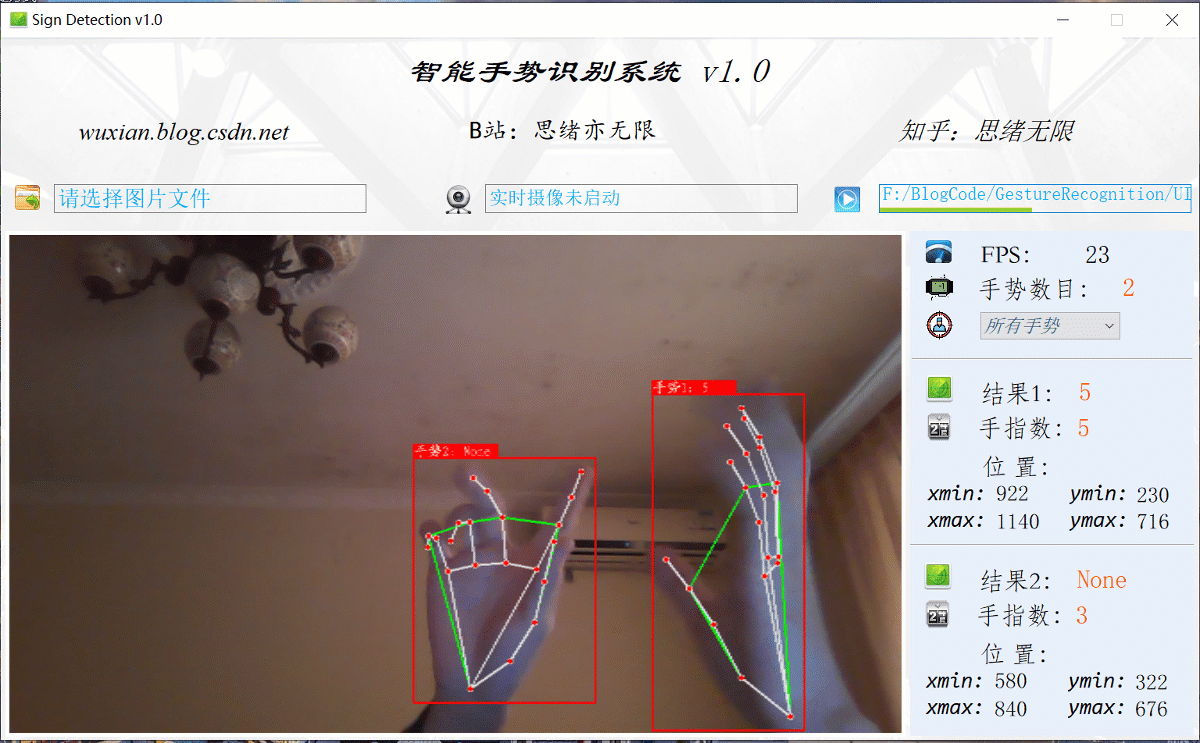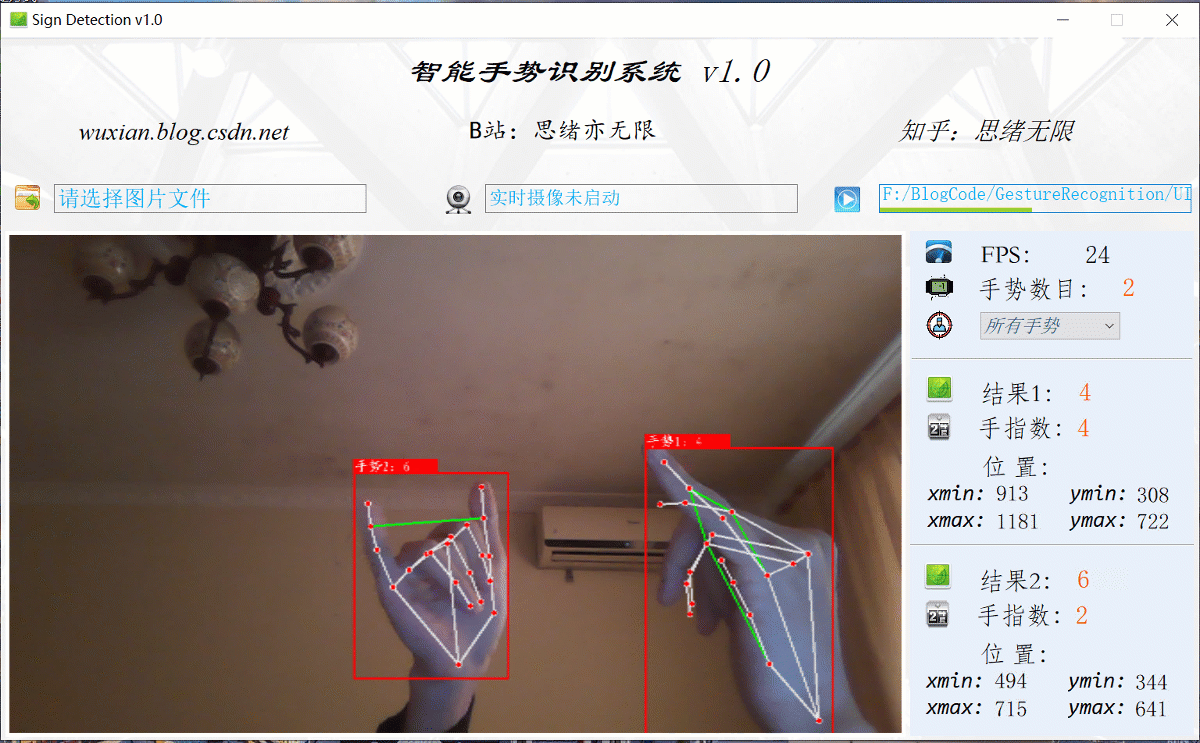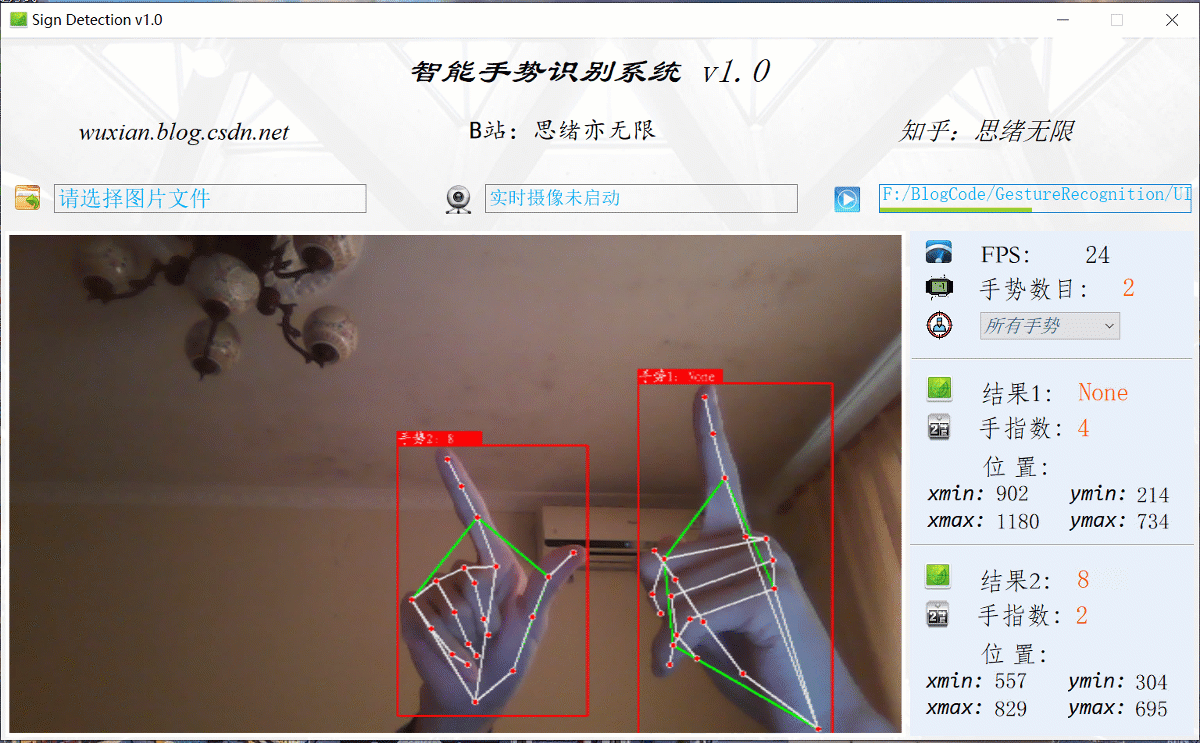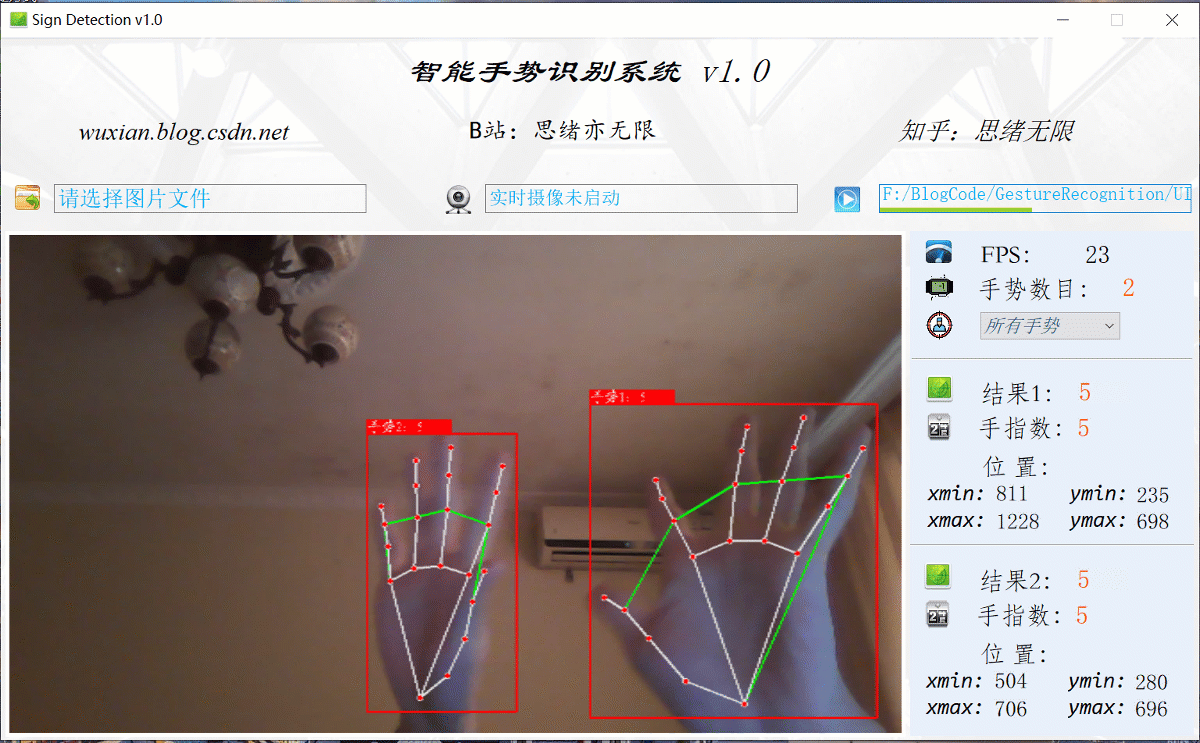
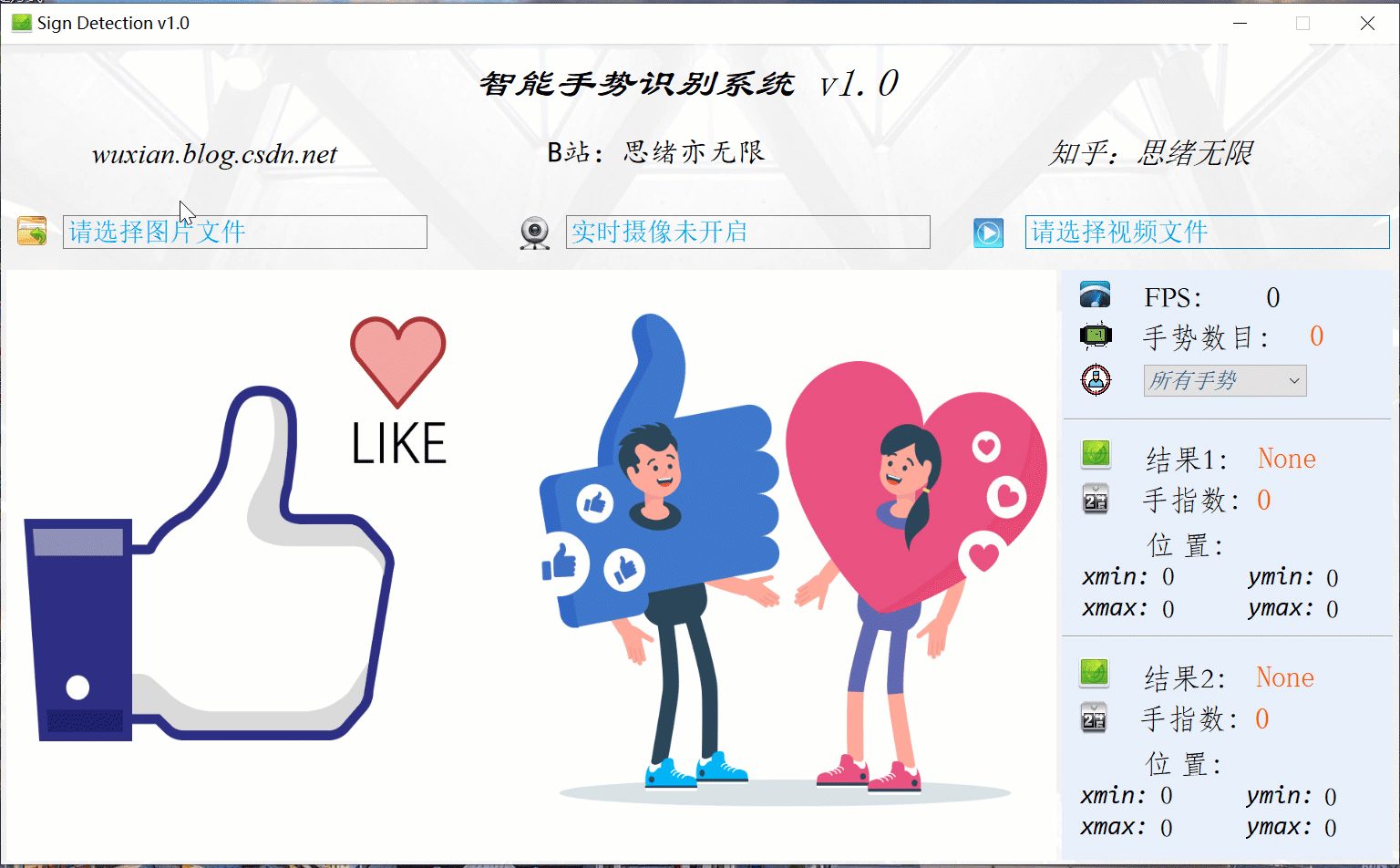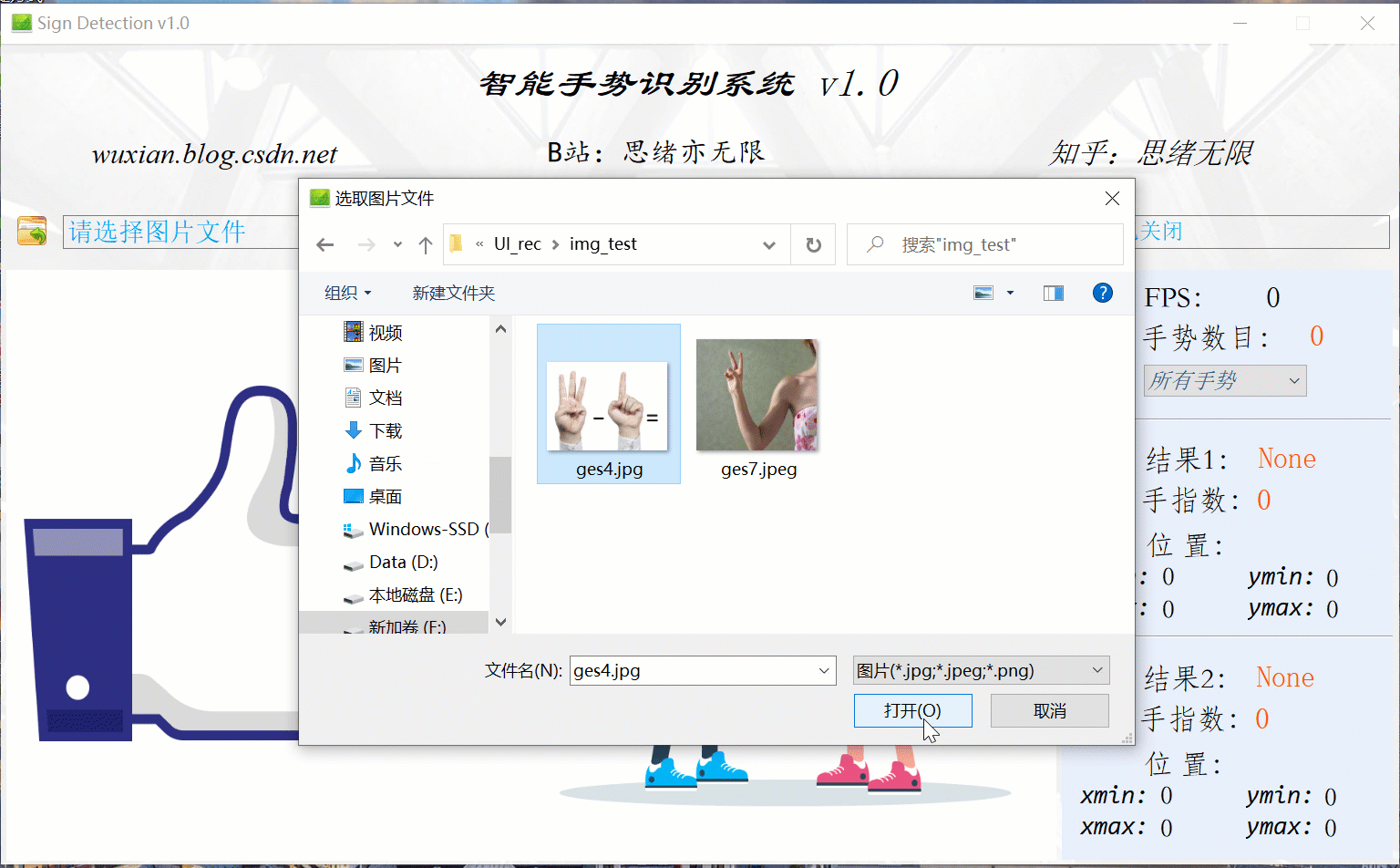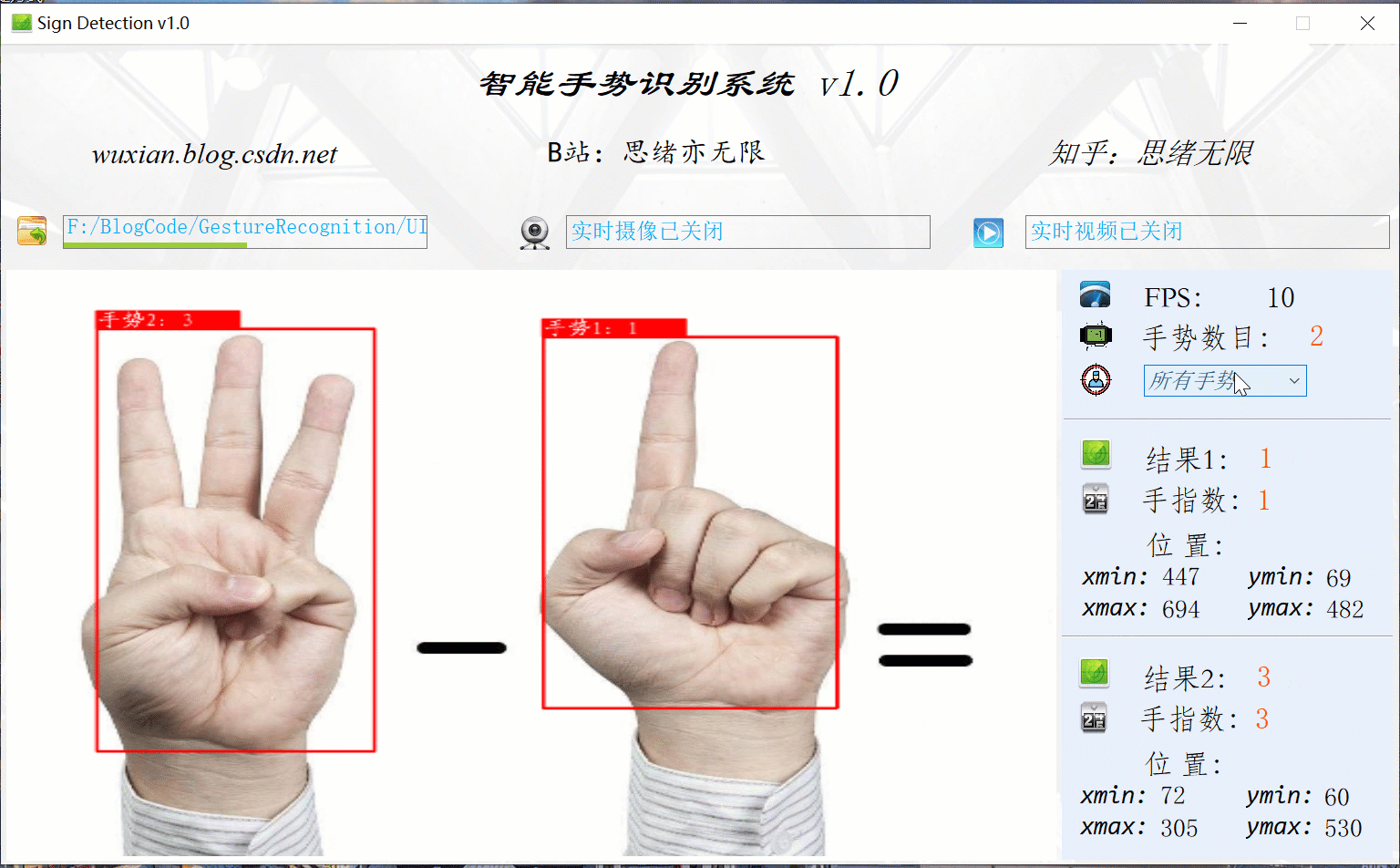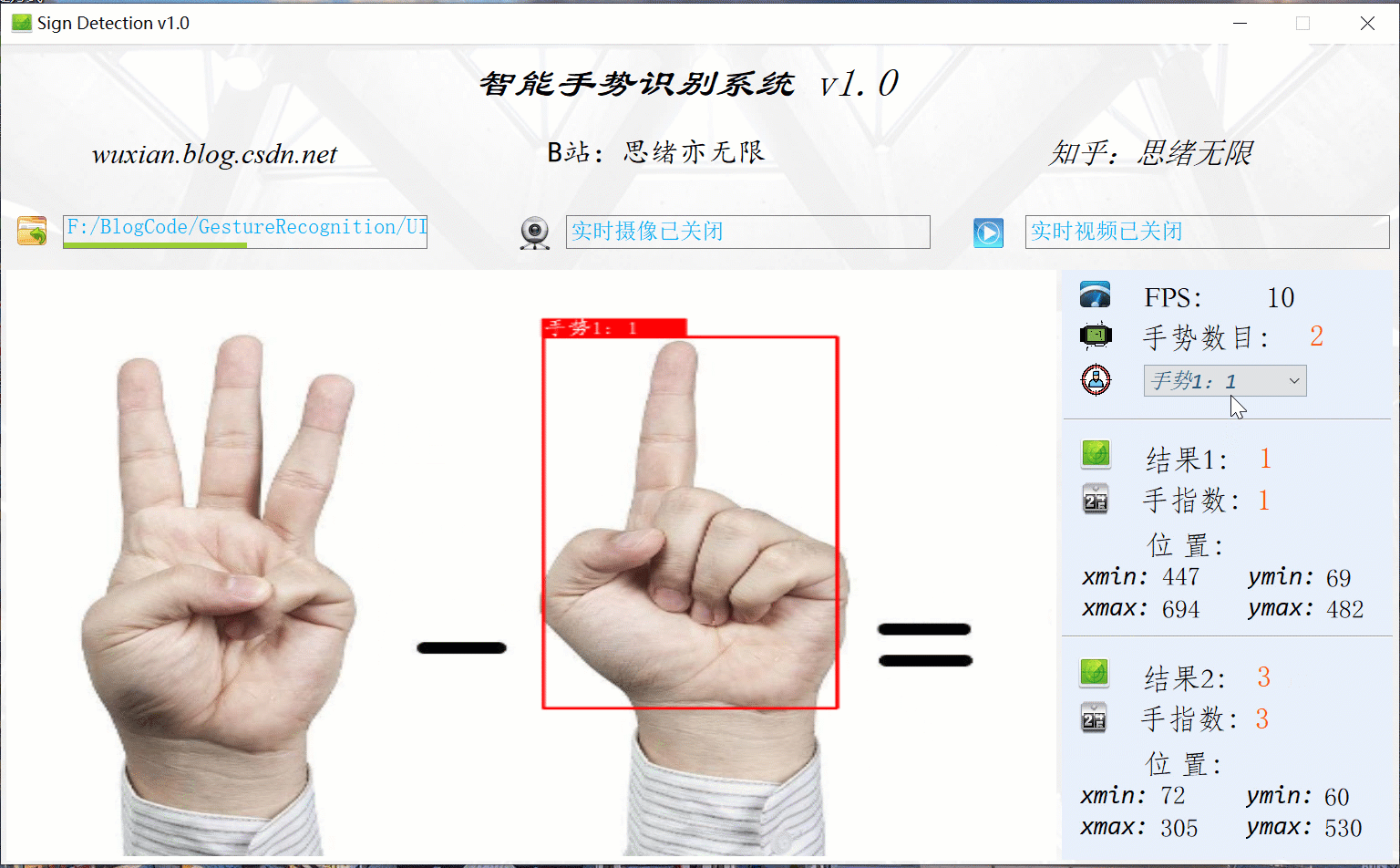
可點擊手勢識別系統中的圖片選擇按鈕,即可彈出圖片檔案選擇視窗,選中檔案后自動顯示識別結果;對于多個手勢,可通過下拉框選擇單獨顯示結果,本功能的界面展示如下圖所示:
(二)手勢視頻識別效果展示
對于視頻檔案同樣可以通過對應的視頻選擇按鈕,選中可用的視頻后自動利用演算法對視頻幀進行逐個識別,此時對演算法和設備的實時性要求較高,但系統同樣能夠保持高的檢測速度,效果如下圖所示:
(三)攝像頭檢測效果展示
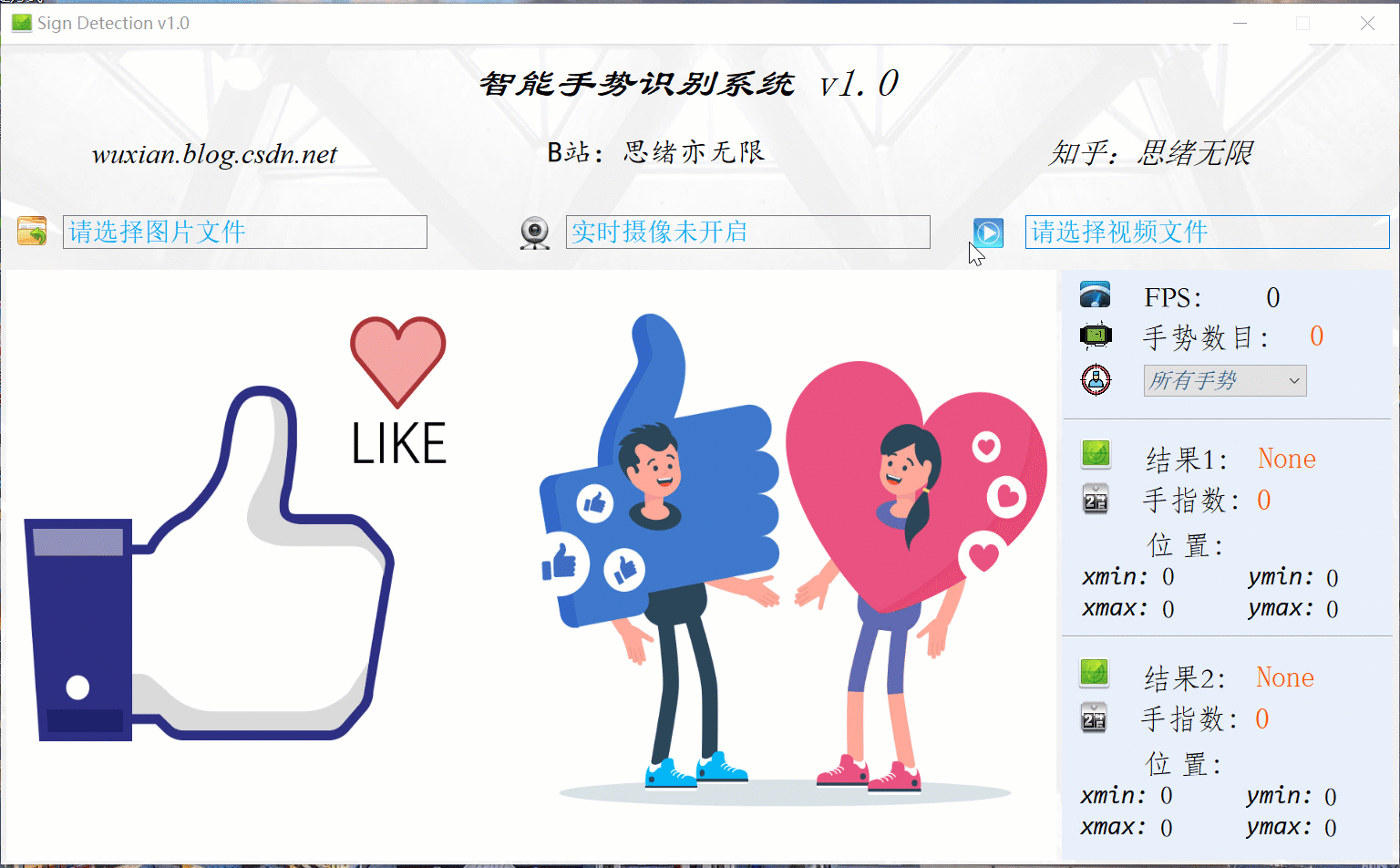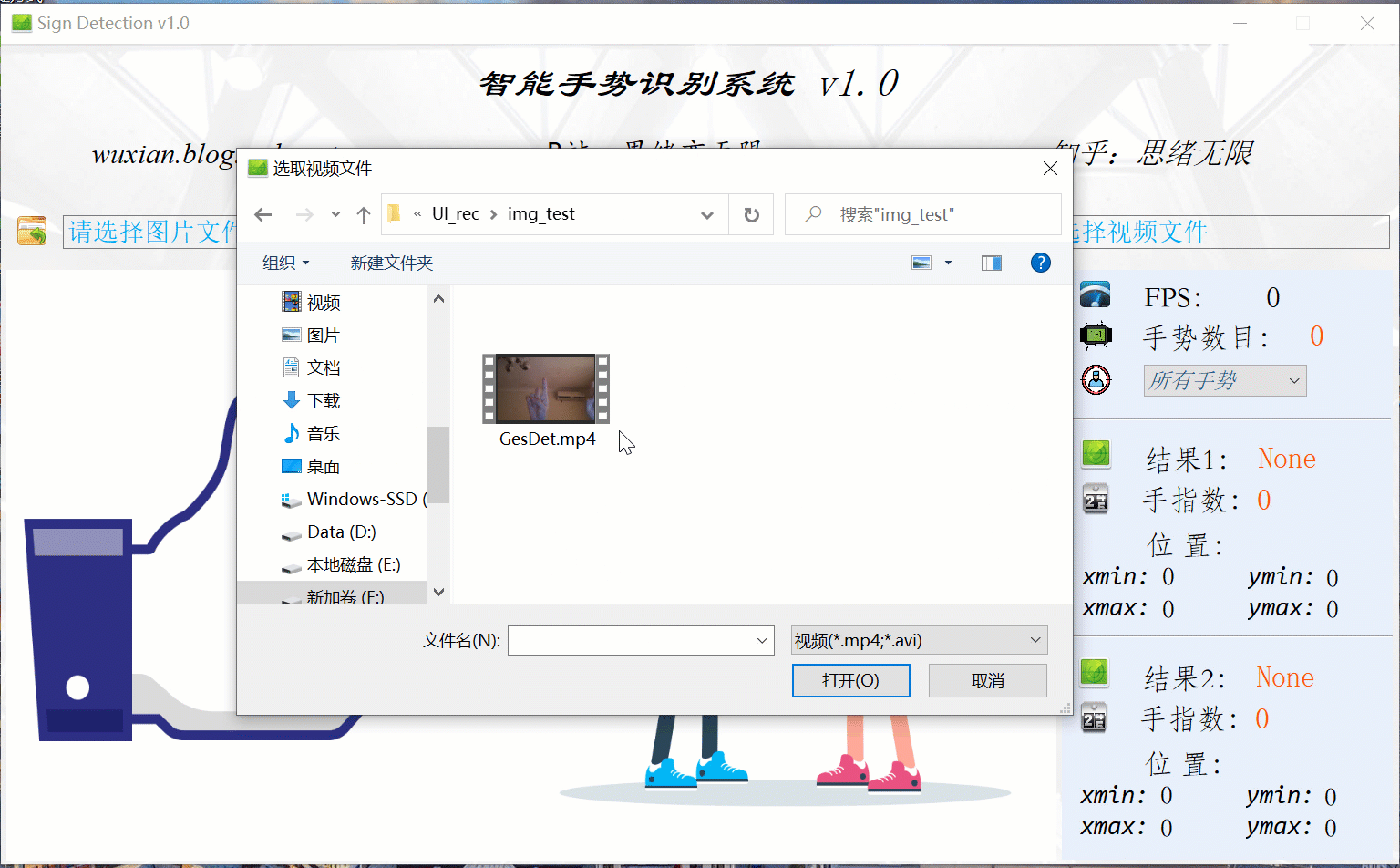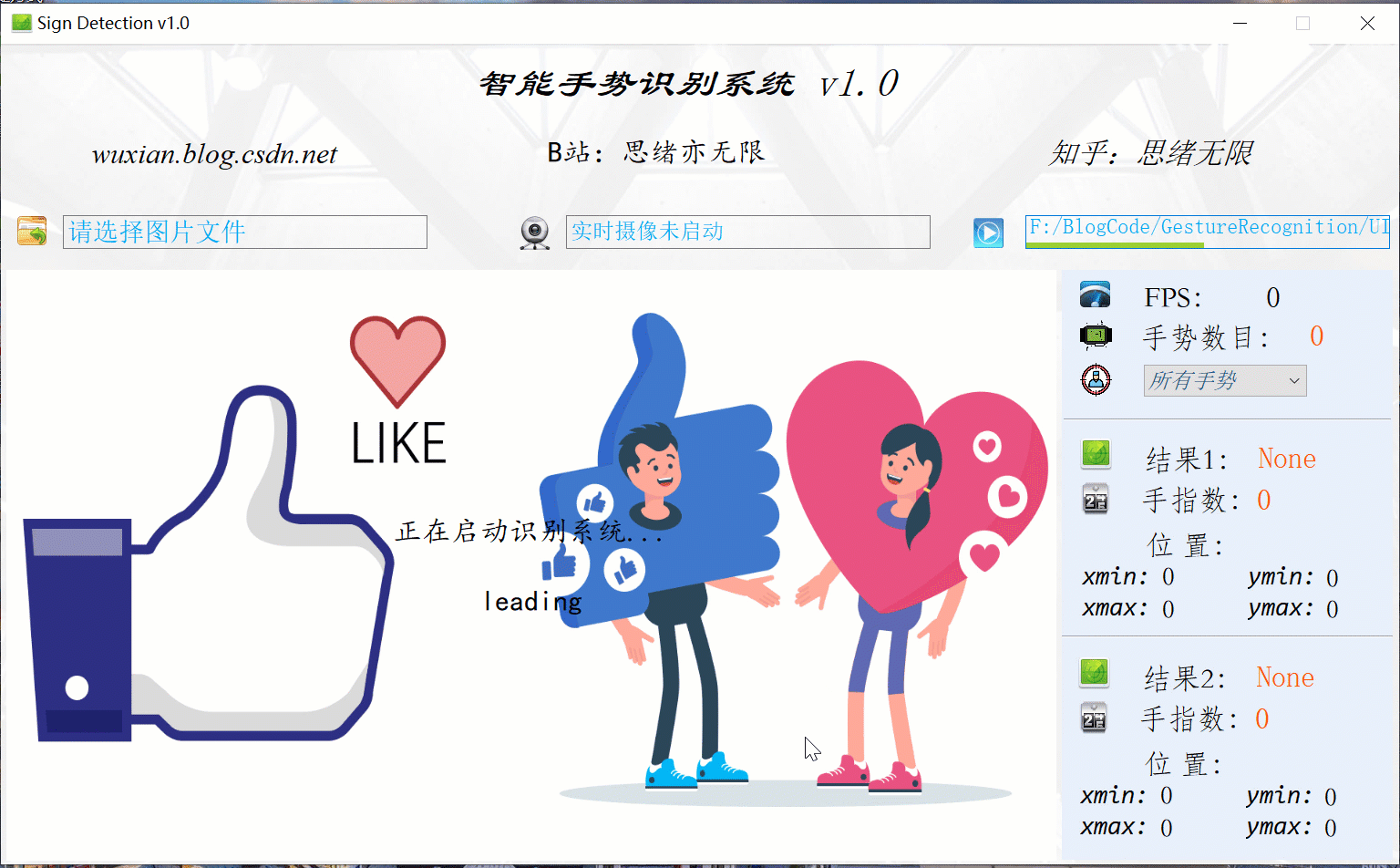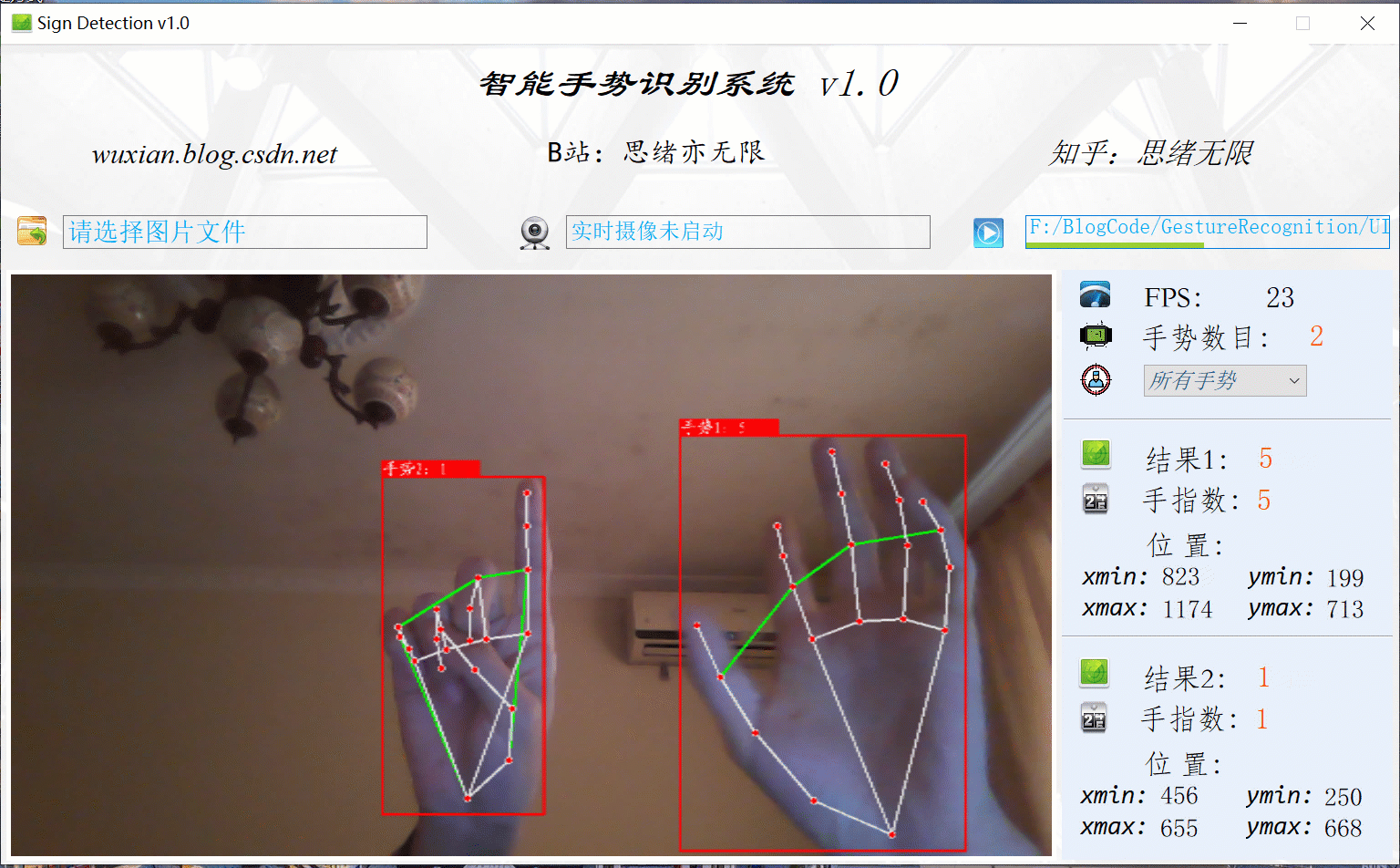
在真實場景中,我們往往利用設備攝像頭獲取實時畫面,同時需要對畫面中的手勢進行識別,因此本文考慮到此項功能,如下圖所示,點擊攝像頭按鈕后系統進入準備狀態,系統顯示實時畫面并開始檢測畫面中的手勢,識別結果展示如下圖:
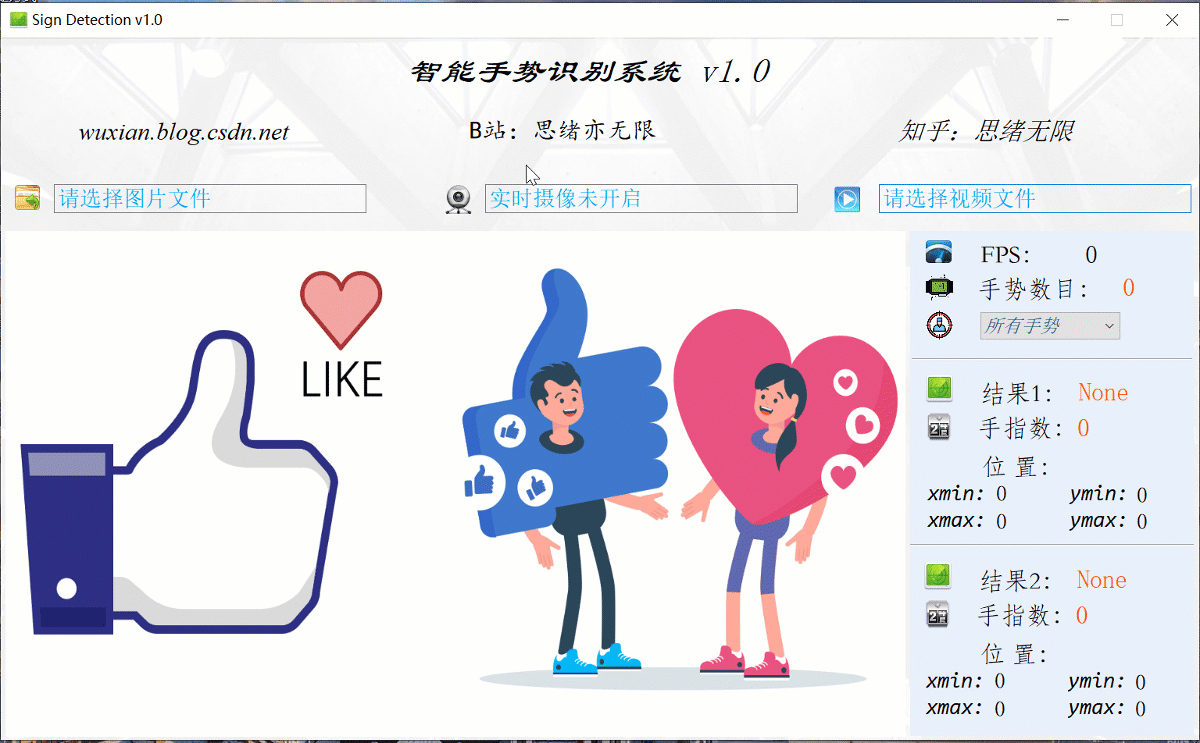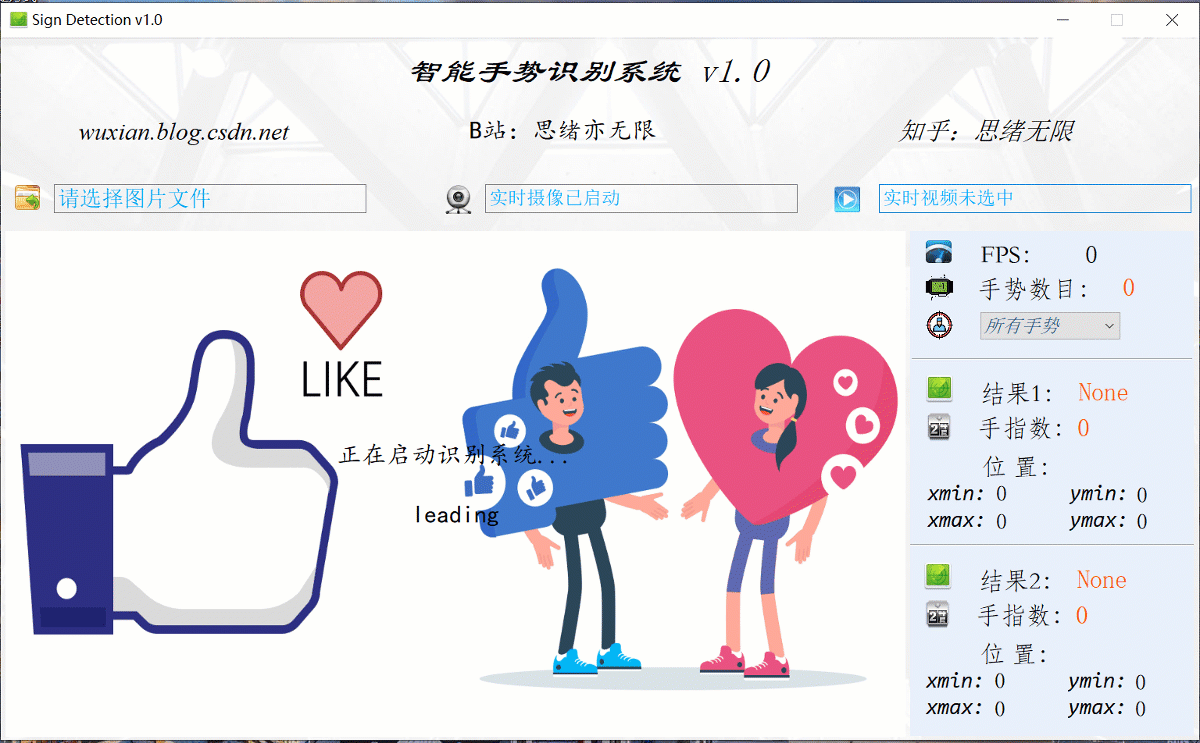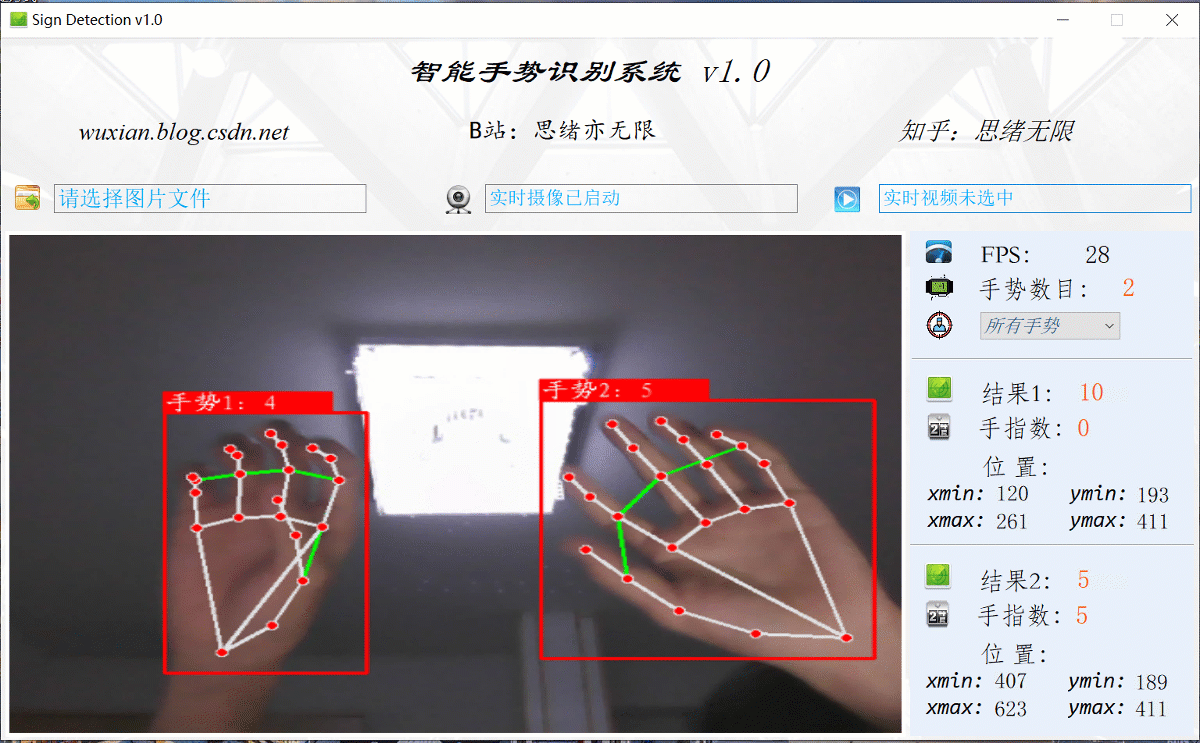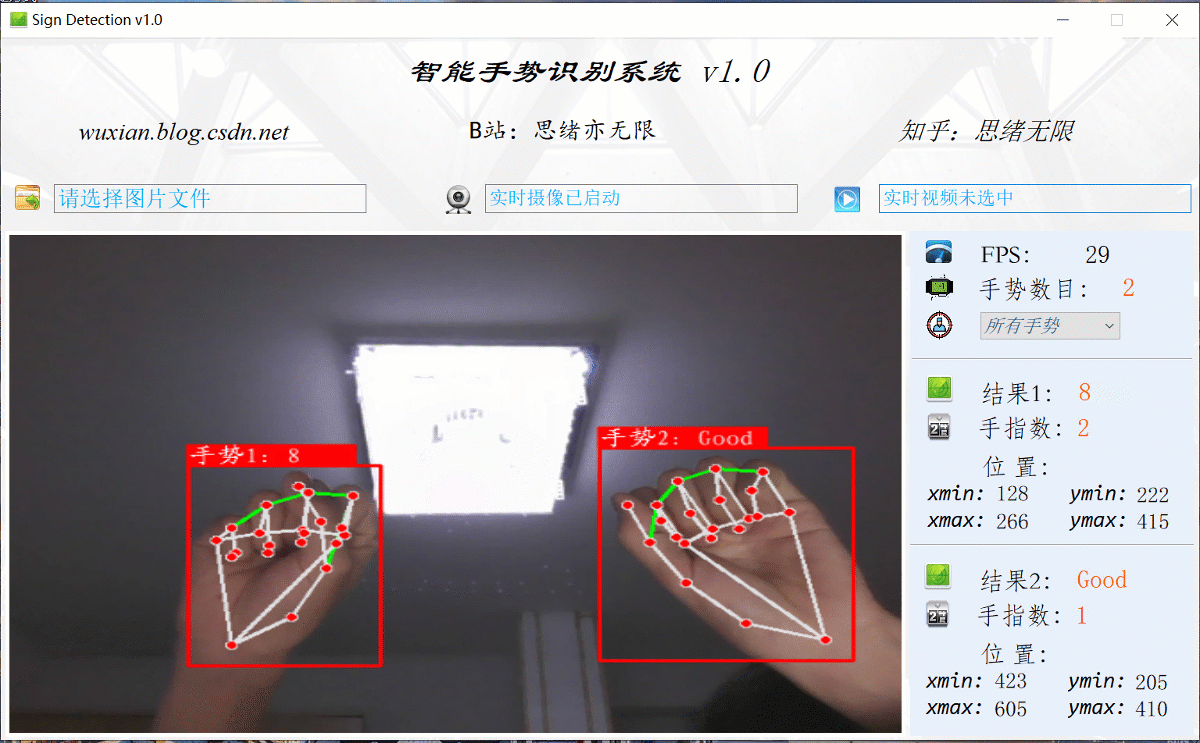
2. 手勢識別原理介紹
2.1 研究現狀
目前現階段手勢識別的研究方向主要分為:基于穿戴設備的手勢識別和基于視覺方法的手勢識別,基于穿戴設備的手勢識別主要是通過在手上佩戴含有大量傳感器的手套獲取大量的傳感器資料,并對其資料進行分析,該種方法相對來雖然精度比較高,但是由于傳感器成本較高很難在日常生活中得到實際應用,同時傳感器手套會造成使用者的不便,影響進一步的情感分析,所以此方法更多的還是應用在一些特有的相對專業的儀器中,而本博客更多的還是將關注點放在基于視覺方法的手勢研究中,在此特地以Mediapipe的框架為例,方便讀者更好的復現和了解相關領域,
基于視覺方法的手勢識別主要分為靜態手勢識別和動態手勢識別兩種,從文字了解上來說,動態手勢識別肯定會難于靜態手勢識別,但靜態手勢是動態手勢的一種特殊狀態,我們可以通過對一幀一幀的靜態手勢識別來檢測連續的動態視頻,進一步分析前后幀的關系來完善手勢系統,在本博客中向大家推薦一篇比較基礎的中文期刊幫助大家簡單了解:
由解迎剛老師發表在計算機工程與應用上的《基于視覺的動態手勢識別研究綜述》,論文從傳感開始介紹,然后在介紹了相關檢測演算法,將手勢識別分為了手勢檢測與分割、手勢追蹤、特征提取、手勢分類與識別四個方面來介紹[1],還有許多手勢識別的英文綜述可供大家參考,感興趣的可以了解一下,
2.2 Mediapipe深度學習框架
Mediapipe深度學習框架的官網是https://google.github.io/mediapipe/,大家可以直接通過本博客訪問其網站,MediaPipe 是一款由 Google Research 開發并開源的多媒體機器學習模型應用框架,首先在官網首頁我們就可以直接看到MediaPipe能干的有:
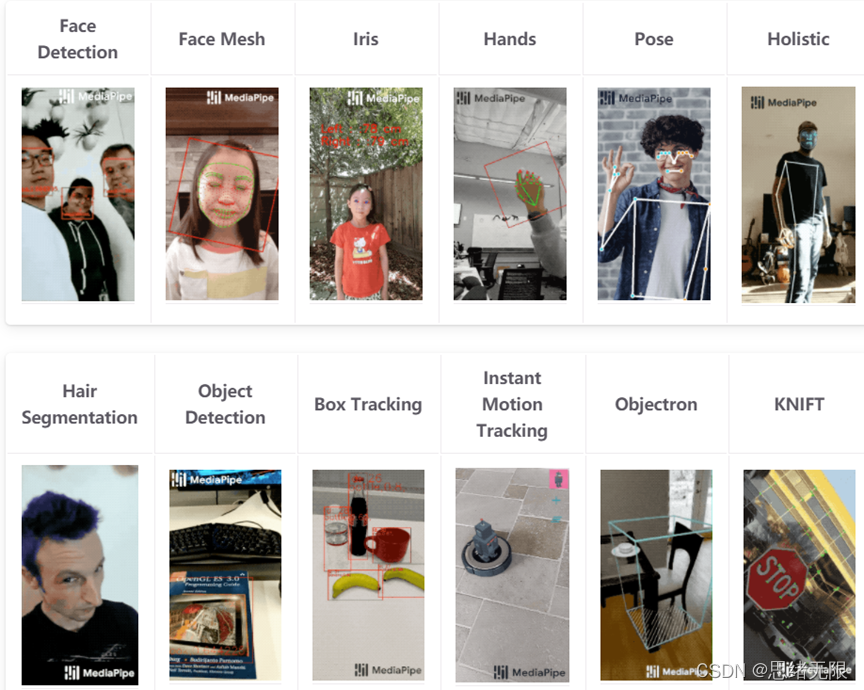
從左到右分別是人臉檢測,人臉關鍵點檢測,瞳孔檢測、手勢識別、身體姿態識別、全身的動作識別,更難的像發絲檢測、簡單的目標檢測、追蹤和實時物體控制,3D物體檢測和標志標牌檢測,然后MediaPipe支持的語言有如下:

2.3 手勢識別原理
在官方的網址上可以知道,MediaPipe的手勢識別演算法主要分為兩個部分,第一個部分是手掌識別模型,第二個是手部關鍵點標記模型,
MediaPipe在訓練手掌模型中,使用的是單階段目標檢測演算法SSD,同時利用三個操作對其進行了優化:1.NMS;2.encoder-decoder feature extractor;3.focal loss,NMS主要是用于抑制演算法識別到了單個物件的多個重復框,得到置信度最高的檢測框;encoder-decoder feature extractor主要用于更大的場景背景關系感知,甚至是小物件(類似于retanet方法);focal loss是有RetinaNet上提取的,主要解決的是正負樣本不平衡的問題,這對于開放環境下的目標檢測是一個可以漲點的技巧,利用上述技術,MediaPie在手掌檢測中達到了95.7%的平均精度,在沒有使用2和3的情況下,得到的基線僅為86.22%,增長了9.48個點,說明模型是可以準確識別出手掌的,而至于為啥做手掌檢測器而不是手部,主要是作者認為訓練手部檢測器比較復雜,可學習到的特征不明顯,所以做的是手掌檢測器,
MediaPipe通過對整個影像進行手掌檢測后,使用手部關鍵點模型通過回歸對被檢測手部區域內的21個三維手部關節坐標進行精確的關鍵點定位,即直接進行坐標預測,標記點如圖所示:
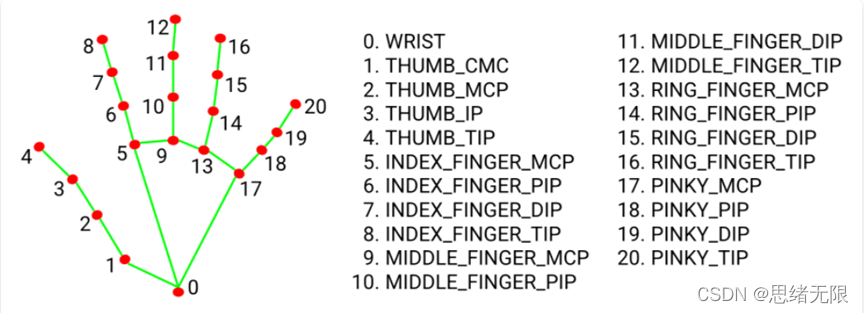
在此我們就簡單的介紹了MediaPipe,接下來我們將通過代碼來使用python呼叫MediaPipe實作手勢識別,主要從三個方面來寫這個腳本:第一個如果識別靜態照片的手勢;第二個如何識別視頻流中的手勢;第三個如果實時識別攝像頭影像,
2.4 代碼實作演示
實作代碼前首先進行依賴安裝,這里需要安裝python-opencv和MediaPipe,可使用以下命令:
pip install opencv-python
pip install mediapipe
首先是引入庫檔案,這里主要用到的是一個mediapipe的sdk包和opencv的包,其他的numpy、time、math都是python和深度學習的基礎包,不多介紹,
import mediapipe as mp
import cv2
import numpy as np
import time
import math
接下來我們將通過mediapipe的sdk來引入我們需要的手勢識別的API,其代碼如下:
mp_drawing = mp.solutions.drawing_utils #點和線的樣式
mp_drawing_styles = mp.solutions.drawing_styles #點和線的風格
mp_hands = mp.solutions.hands # 手勢識別的API
然后我們將預設一張手勢識別的圖片,可以填入相對路徑和絕對路徑,并預設一組數字,用于后期的手勢分析,
IMAGE_List = ['jpgDet.jpg'] # 圖片串列
gesture = [0,1,2,3,4,5] # 預設數字
以下就是手勢識別的主程式,也就是主要核心內容,通過mediapipe的api我們可以分析出檢測到的是左手還是右手,并獲取相應手的21個關鍵點坐標,
with mp_hands.Hands(
static_image_mode = True, # False表示為影像檢測模式
max_num_hands = 2, # 最大可檢測到兩只手掌
model_complexity = 0, # 可設為0或者1,主要跟模型復雜度有關
min_detection_confidence = 0.5, # 最大檢測閾值
) as hands:
for idx ,file in enumerate(IMAGE_List):
image = cv2.flip(cv2.imread(file),1) # 讀取圖片
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB) # 將其標為RGB格式
t0 = time.time()
results =hands.process(image) # 使用API處理影像影像
'''
results.multi_handedness
包括label和score,label是字串"Left"或"Right",score是置信度
results.multi_hand_landmarks
results.multi_hand_landmrks:被檢測/跟蹤的手的集合
其中每只手被表示為21個手部地標的串列,每個地標由x、y和z組成,
x和y分別由影像的寬度和高度歸一化為[0.0,1.0],Z表示地標深度
以手腕深度為原點,值越小,地標離相機越近,
z的大小與x的大小大致相同,
'''
t1 = time.time()
fps = 1 / (t1 - t0) # 實時幀率
# print('++++++++++++++fps',fps)
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # 將影像變回BGR形式
dict_handnumber = {} # 創建一個字典,保存左右手的手勢情況
if results.multi_handedness: # 判斷是否檢測到手掌
if len(results.multi_handedness) == 2: # 如果檢測到兩只手
for i in range(len(results.multi_handedness)):
label = results.multi_handedness[i].classification[0].label # 獲得Label判斷是哪幾手
index = results.multi_handedness[i].classification[0].index # 獲取左右手的索引號
hand_landmarks = results.multi_hand_landmarks[index] # 根據相應的索引號獲取xyz值
mp_drawing.draw_landmarks(
image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS, #用于指定地標如何在圖中連接,
mp_drawing_styles.get_default_hand_landmarks_style(), # 如果設定為None.則不會在圖上標出關鍵點
mp_drawing_styles.get_default_hand_connections_style()) # 關鍵點的連接風格
gesresult = ges(hand_landmarks) # 傳入21個關鍵點集合,回傳數字
dict_handnumber[label] = gesresult # 與對應的手進行保存為字典
else: # 如果僅檢測到一只手
label = results.multi_handedness[0].classification[0].label # 獲得Label判斷是哪幾手
hand_landmarks = results.multi_hand_landmarks[0]
mp_drawing.draw_landmarks(
image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS, #用于指定地標如何在圖中連接,
mp_drawing_styles.get_default_hand_landmarks_style(), # 如果設定為None.則不會在圖上標出關鍵點
mp_drawing_styles.get_default_hand_connections_style()) # 關鍵點的連接風格
gesresult = ges(hand_landmarks) # 傳入21個關鍵點集合,回傳數字
dict_handnumber[label] = gesresult # 與對應的手進行保存為字典
if len(dict_handnumber) == 2: # 如果有兩只手,則進入
# print(dict_handnumber)
leftnumber = dict_handnumber['Right']
rightnumber = dict_handnumber['Left']
'''
顯示實時幀率,右手值,左手值,相加值
'''
s = 'FPS:{0}\nRighthand Value:{1}\nLefthand Value:{2}\nAdd is:{3}'.format(int(fps),rightnumber,leftnumber,str(leftnumber+rightnumber)) # 影像上的文字內容
elif len(dict_handnumber) == 1 : # 如果僅有一只手則進入
labelvalue = https://www.cnblogs.com/sixuwuxian/p/list(dict_handnumber.keys())[0] # 判斷檢測到的是哪只手
if labelvalue =='Right': # 左手,不知為何,模型總是將左右手搞反,則引入人工代碼糾正
number = list(dict_handnumber.values())[0]
s = 'FPS:{0}\nRighthand Value:{1}\nLefthand Value:0\nAdd is:{2}'.format(int(fps),number,number)
else: # 右手
number = list(dict_handnumber.values())[0]
s = 'FPS:{0}\nLefthand Value:{1}\nRighthand Value:0\nAdd is:{2}'.format(int(fps),number,number)
else:# 如果沒有檢測到則只顯示幀率
s = 'FPS:{0}\n'.format(int(fps))
y0,dy = 50,25 # 文字放置初始坐標
# image = cv2.flip(image,1) # 反轉影像
for i ,txt in enumerate(s.split('\n')): # 根據\n來豎向排列文字
y = y0 + i*dy
cv2.putText(image,txt,(50,y),cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,0),3)
cv2.imshow('MediaPipe Gesture Recognition',image) # 顯示影像
cv2.imwrite('save/{0}.jpg'.format(idx),image)
if cv2.waitKey(5) & 0xFF == 27:
break
運行以上代碼,通過讀取一張手勢圖片,呼叫演算法對畫面中的手勢進行識別,其中手指數目、畫面幀率、手勢結果等資訊標記在影像中,如下圖所示:

視頻識別在代碼結構上與圖片識別是一致的,主要的原理就是通過cv2.VideoCapture()函式將視頻讀取成每一幀,并對每一幀影像進行檢測,回傳結果,以下我直接貼出原始碼,相關注釋與圖片識別相同,定義好cv2.VideoCapture函式,傳入視頻路徑,并預設好手勢串列,
cap = cv2.VideoCapture('GesDet.mp4') # 視頻路徑
gesture = [0,1,2,3,4,5] # 預設數字
使用while回圈去遍歷每一幀影像,并使用imshow來展示檢測結果,注意這里的static_image_mode引數要設定為False,
with mp_hands.Hands(
static_image_mode = False, # False表示為視頻流檢測
max_num_hands = 2, # 最大可檢測到兩只手掌
model_complexity = 0, # 可設為0或者1,主要跟模型復雜度有關
min_detection_confidence = 0.5, # 最大檢測閾值
min_tracking_confidence = 0.5 # 最小追蹤閾值
) as hands:
while True: # 判斷相機是否打開
success ,image = cap.read() # 回傳兩個值:一個表示狀態,一個是影像矩陣
if image is None:
break
image.flags.writeable = False # 將影像矩陣修改為僅讀模式
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
t0 = time.time()
results =hands.process(image) # 使用API處理影像影像
'''
results.multi_handedness
包括label和score,label是字串"Left"或"Right",score是置信度
results.multi_hand_landmarks
results.multi_hand_landmrks:被檢測/跟蹤的手的集合
其中每只手被表示為21個手部地標的串列,每個地標由x、y和z組成,
x和y分別由影像的寬度和高度歸一化為[0.0,1.0],Z表示地標深度
以手腕深度為原點,值越小,地標離相機越近,
z的大小與x的大小大致相同,
'''
t1 = time.time()
fps = 1 / (t1 - t0) # 實時幀率
# print('++++++++++++++fps',fps)
image.flags.writeable = True # 將影像矩陣修改為讀寫模式
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # 將影像變回BGR形式
dict_handnumber = {} # 創建一個字典,保存左右手的手勢情況
if results.multi_handedness: # 判斷是否檢測到手掌
if len(results.multi_handedness) == 2: # 如果檢測到兩只手
for i in range(len(results.multi_handedness)):
label = results.multi_handedness[i].classification[0].label # 獲得Label判斷是哪幾手
index = results.multi_handedness[i].classification[0].index # 獲取左右手的索引號
hand_landmarks = results.multi_hand_landmarks[index] # 根據相應的索引號獲取xyz值
mp_drawing.draw_landmarks(
image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS, #用于指定地標如何在圖中連接,
mp_drawing_styles.get_default_hand_landmarks_style(), # 如果設定為None.則不會在圖上標出關鍵點
mp_drawing_styles.get_default_hand_connections_style()) # 關鍵點的連接風格
gesresult = ges(hand_landmarks) # 傳入21個關鍵點集合,回傳數字
dict_handnumber[label] = gesresult # 與對應的手進行保存為字典
else: # 如果僅檢測到一只手
label = results.multi_handedness[0].classification[0].label # 獲得Label判斷是哪幾手
hand_landmarks = results.multi_hand_landmarks[0]
mp_drawing.draw_landmarks(
image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS, #用于指定地標如何在圖中連接,
mp_drawing_styles.get_default_hand_landmarks_style(), # 如果設定為None.則不會在圖上標出關鍵點
mp_drawing_styles.get_default_hand_connections_style()) # 關鍵點的連接風格
gesresult = ges(hand_landmarks) # 傳入21個關鍵點集合,回傳數字
dict_handnumber[label] = gesresult # 與對應的手進行保存為字典
if len(dict_handnumber) == 2: # 如果有兩只手,則進入
# print(dict_handnumber)
leftnumber = dict_handnumber['Right']
rightnumber = dict_handnumber['Left']
'''
顯示實時幀率,右手值,左手值,相加值
'''
s = 'FPS:{0}\nRighthand Value:{1}\nLefthand Value:{2}\nAdd is:{3}'.format(int(fps),rightnumber,leftnumber,str(leftnumber+rightnumber)) # 影像上的文字內容
elif len(dict_handnumber) == 1 : # 如果僅有一只手則進入
labelvalue = https://www.cnblogs.com/sixuwuxian/p/list(dict_handnumber.keys())[0] # 判斷檢測到的是哪只手
if labelvalue =='Left': # 左手,不知為何,模型總是將左右手搞反,則引入人工代碼糾正
number = list(dict_handnumber.values())[0]
s = 'FPS:{0}\nRighthand Value:{1}\nLefthand Value:0\nAdd is:{2}'.format(int(fps),number,number)
else: # 右手
number = list(dict_handnumber.values())[0]
s = 'FPS:{0}\nLefthand Value:{1}\nRighthand Value:0\nAdd is:{2}'.format(int(fps),number,number)
else:# 如果沒有檢測到則只顯示幀率
s = 'FPS:{0}\n'.format(int(fps))
y0,dy = 50,25 # 文字放置初始坐標
image = cv2.flip(image,1) # 反轉影像
for i ,txt in enumerate(s.split('\n')): # 根據\n來豎向排列文字
y = y0 + i*dy
cv2.putText(image,txt,(50,y),cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,0),3)
cv2.imshow('MediaPipe Gesture Recognition',image) # 顯示影像
# cv2.imwrite('save/{0}.jpg'.format(t1),image)
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
相機實時檢測相比于前面兩種,主要是cv2.VideoCapture()中,我們傳入的不在是檔案路徑,而是一個一個的數字,以電腦自帶攝像頭為例,我們傳入引數0,如果有多個相機也可傳入相應的相機代號,
cap = cv2.VideoCapture(0) # 0代表電腦自帶攝像頭
讀取視頻或攝像頭畫面進行識別的程序,與前面讀取圖片檔案相似,通過回圈讀取畫面幀逐個識別手勢,并標記在畫面中,運行結果如下圖所示:
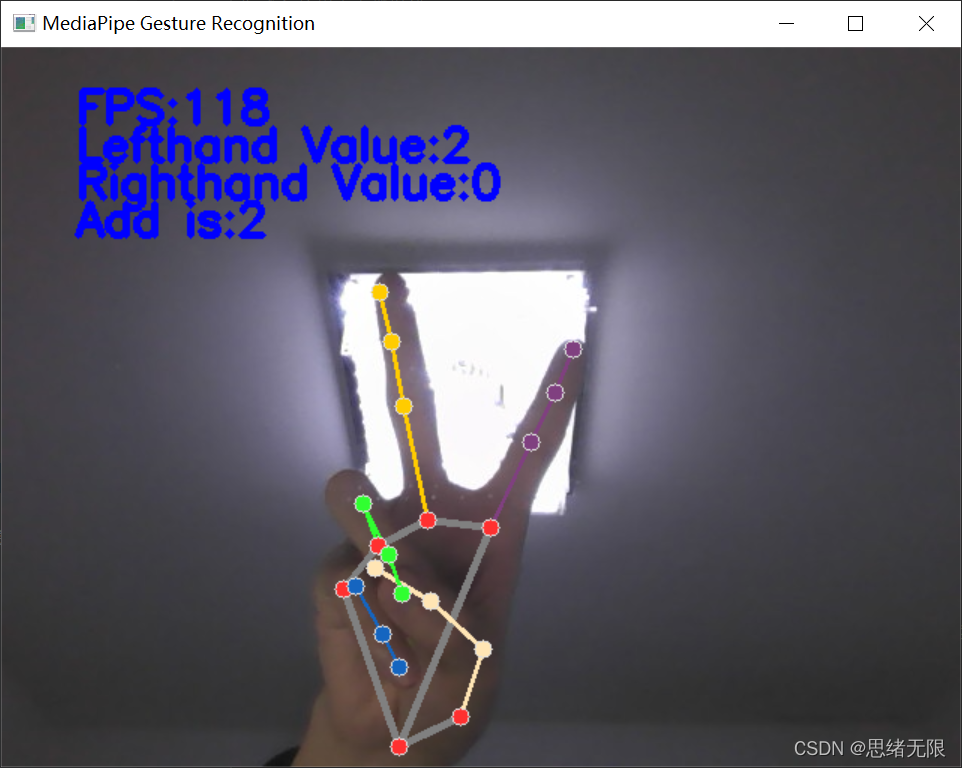
在使用了MediaPipe的手勢識別后,我發現難得不是對于手勢關鍵點的檢測,MediaPipe的手勢識別,在CPU上基本可以達到實時的標準,更難的應該是對手勢的判斷,對關鍵點的理解,這里我也觀摩了很多其他博主的文章,對于不同方法得到的準確度也不一樣,這值得我們更多的去思考,對于手勢更準的判斷,我們可以將其應用在很多的工程實體中,
打開QtDesigner軟體,拖動以下控制元件至主視窗中,調整界面樣式和控制元件放置,性別識別系統的界面設計如下圖所示:
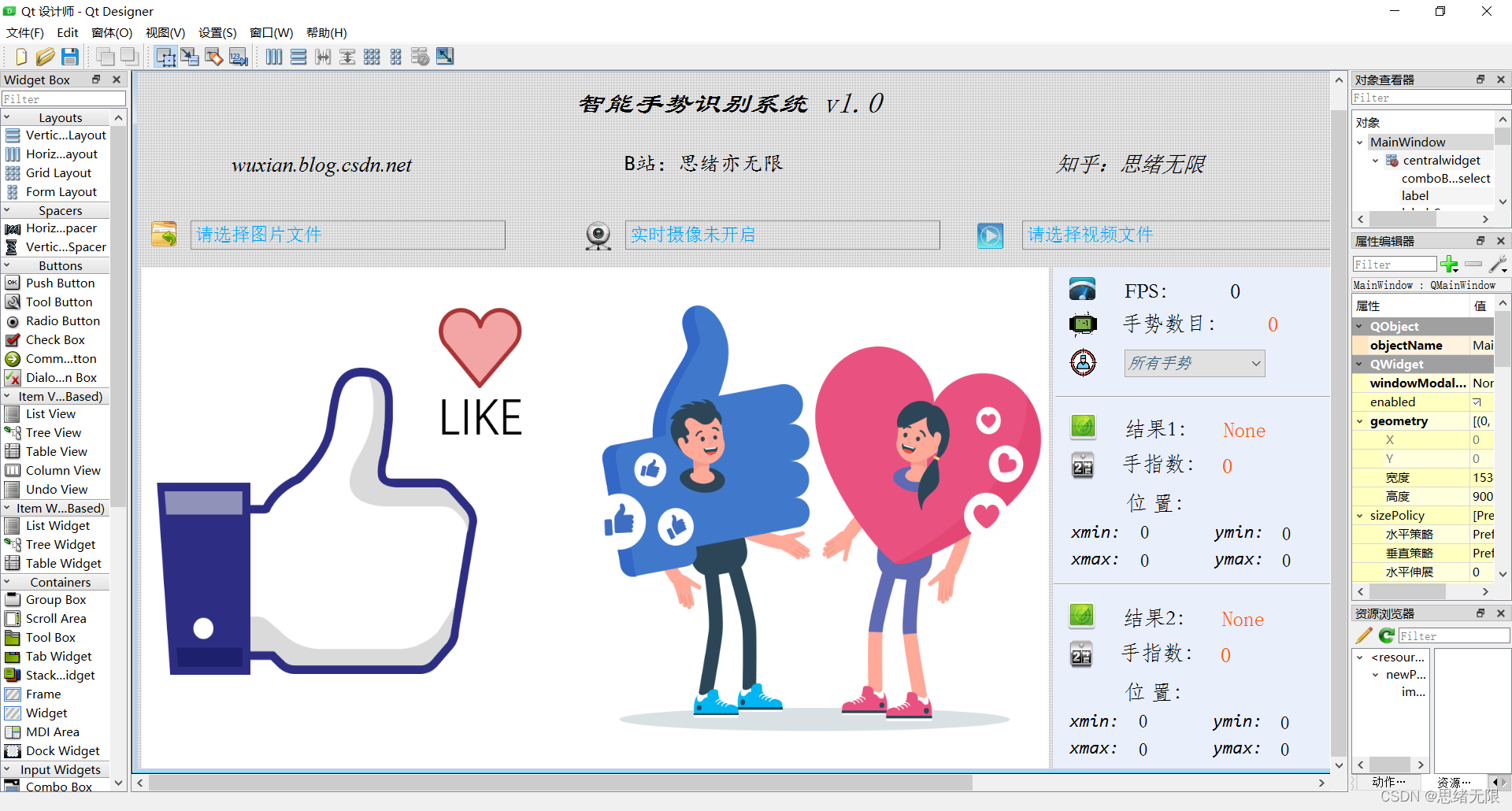
控制元件界面部分設計好,接下來利用PyUIC工具將.ui檔案轉化為.py代碼檔案,通過呼叫界面部分的代碼同時加入對應的邏輯處理代碼,博主對其中的UI功能進行了詳細測驗,最終開發出一版流暢得到清新界面,就是博文演示部分的展示,完整的UI界面、測驗圖片視頻、代碼檔案,以及Python離線依賴包(方便安裝運行,也可自行配置環境),均已打包上傳,感興趣的朋友可以通過下載鏈接獲取,
下載鏈接
若您想獲得博文中涉及的實作完整全部程式檔案(包括測驗圖片、視頻,py, UI檔案等,如下圖),這里已打包上傳至博主的面包多平臺和CSDN下載資源,本資源已上傳至面包多網站和CSDN下載資源頻道,可以點擊以下鏈接獲取,已將所有涉及的檔案同時打包到里面,點擊即可運行,完整檔案截圖如下:
在檔案夾下的資源顯示如下,其中包含了Python的離線依賴包,讀者可在正確安裝Anaconda和Pycharm軟體后,點擊bat檔案進行安裝,詳細演示也可見本人B站視頻,
注意:本資源已經過除錯通過,下載后可通過Pycharm運行;運行界面的主程式為runMain.py,測驗圖片可運行JPGDet.py,測驗視頻檔案可運行VideoDet.py,測驗攝像頭識別可運行Cameradet.py,為確保程式順利運行,請配置Python依賴包的版本如下:???
Python版本:3.8,請勿使用其他版本,詳見requirements.txt檔案;
absl-py==1.0.0
attrs==21.4.0
certifi==2021.10.8
cvzone==1.5.6
cycler==0.11.0
fonttools==4.29.1
kiwisolver==1.3.2
matplotlib==3.5.1
mediapipe==0.8.9.1
numpy==1.22.3
opencv-contrib-python==4.5.5.62
opencv-python==4.5.5.64
packaging==21.3
Pillow==9.0.1
protobuf==3.19.4
pyparsing==3.0.7
PyQt5==5.15.6
PyQt5-Qt5==5.15.2
PyQt5-sip==12.9.1
python-dateutil==2.8.2
six==1.16.0
wincertstore==0.2
完整資源下載鏈接1:https://mianbaoduo.com/o/bread/mbd-YpmXlZ9s
完整資源下載鏈接2:博主在CSDN下載頻道的完整資源下載頁
結束語
由于博主能力有限,博文中提及的方法即使經過試驗,也難免會有疏漏之處,希望您能熱心指出其中的錯誤,以便下次修改時能以一個更完美更嚴謹的樣子,呈現在大家面前,同時如果有更好的實作方法也請您不吝賜教,
參考資料:
- https://blog.csdn.net/weixin_45930948/article/details/115444916
- https://cloud.tencent.com/developer/article/1492209
- 王如斌,竇全禮,張淇,周誠.基于MediaPipe的手勢識別用于挖掘機遙操作控制[J/OL].土木建筑工程資訊技術:1-8[2022-03-31].
解迎剛,王全. 基于視覺的動態手勢識別研究綜述[J]. 計算機工程與應用, 2021, 57(22):10. ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/458532.html
標籤:其他