
導讀: 本次講座從圖資料庫中的核心查詢算子——子圖匹配入題,介紹了圖資料庫的基本概念、子圖匹配的演算法,以及在圖資料庫環境下的子圖匹配查詢優化等內容,具體包括下面三個方面:
-
什么是圖資料庫
-
子圖匹配查詢及其優化方法
-
我們的作業
--
01 什么是圖資料庫
1. 資料庫
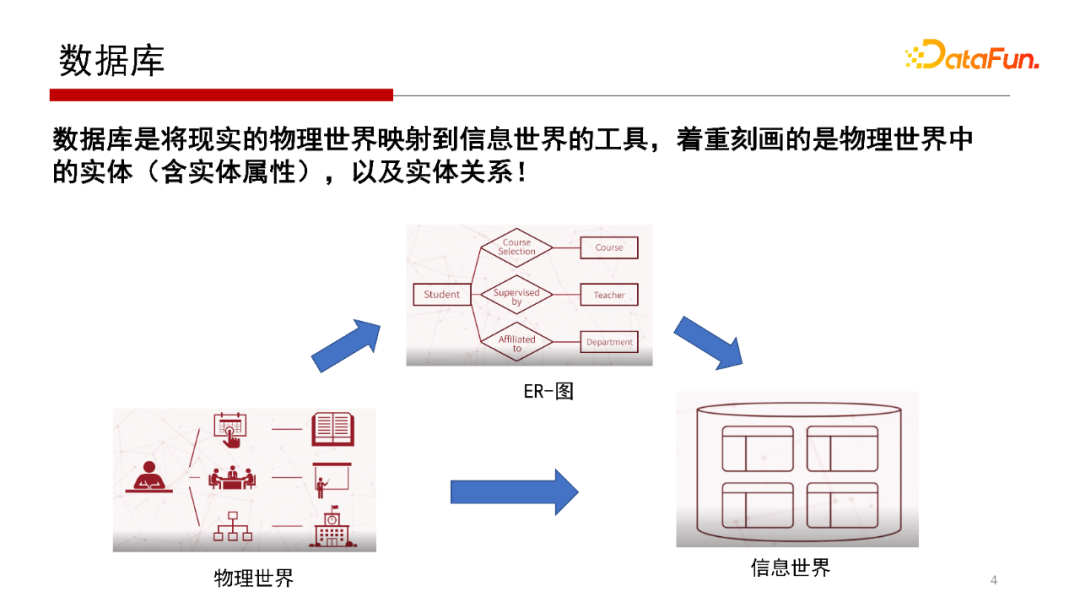
資料庫研究的核心就是將物理世界映射到資訊世界,在資料庫學習課程中會學到一個概念模型E-R圖,E-R圖表示物體與物體之間的關系,也會將物體的屬性包含在內,
2. 回顧-關系型資料庫(RDBMS)
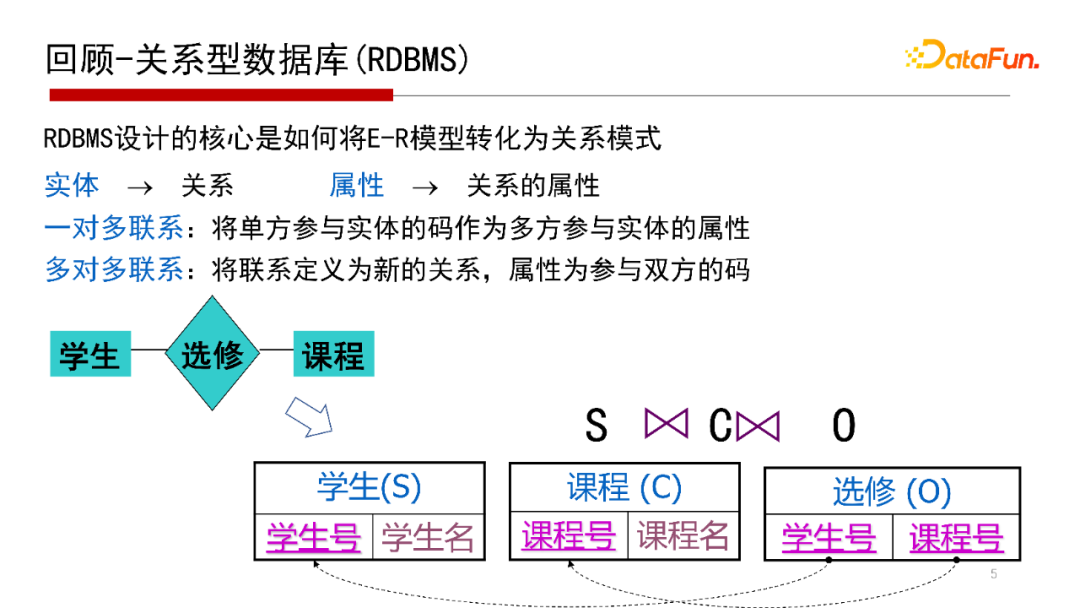
我們再回顧一下關系型資料庫是怎么實作E-R關系映射的,E-R圖是一個概念模型,是在對資訊世界、物理世界建模的時候需要一個概念模型(Conceptual Model),那么,如何將一個概念模型進行一個物理實作呢?如果底層用的是關系資料庫,需要將E-R圖結構映射到一個二維的關系表中,如“學生選修課程”的E-R圖,映射到學生表、課程表和選修表這樣的二維關系表中,這是關系資料庫設計的基本思路,
3. 圖資料庫-Game Changer
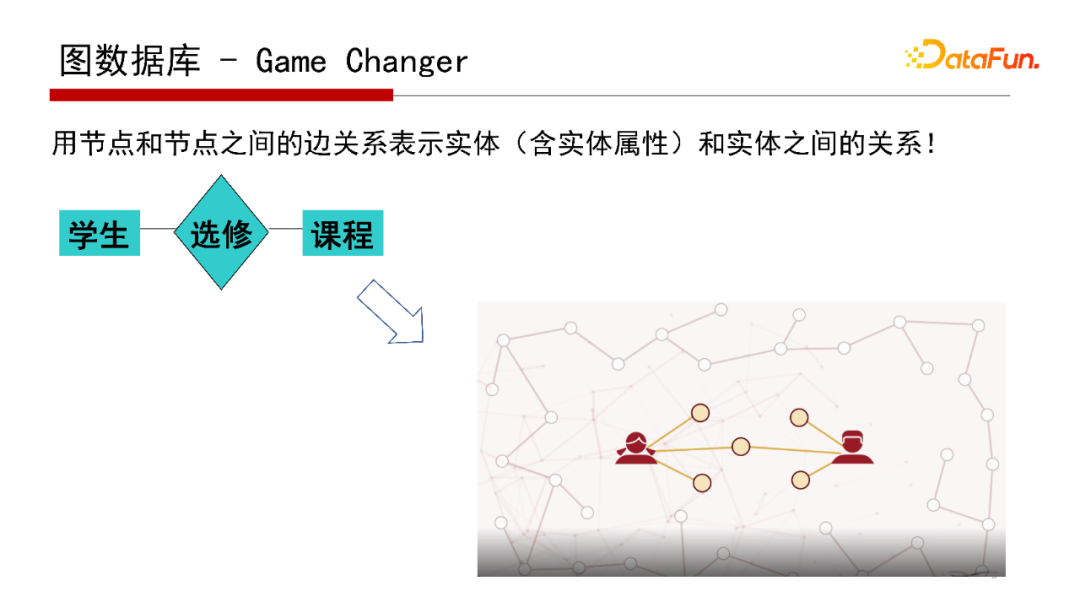
如果采用圖資料庫作為底層的物理實習,就是把E-R圖表示的概念模型映射成圖資料庫中的節點和邊,因為E-R圖和圖資料庫均采用“圖”的形式進行表達,因此這樣的映射更加直接,那么,E-R圖與圖資料庫的模型有什么區別呢?
首先,兩類模型定位不一樣,E-R圖是概念模型,更像類(class)圖,定義的是類之間的邏輯關系,不是資料的實體(Instance)之間的關聯;而圖資料庫的模型是物理實作的資料模型,圖資料庫中的每個點和邊表示實體(也稱為物體)的屬性與實體之間的關聯,
其次,兩類模型作用不同,作為概念模型,E-R圖用于幫助用戶和資料庫開發者對于應用需求和所涉及到的資料的含義進行正確理解的工具;而圖資料庫中的圖模型是資料庫系統的物理實作模型,
關系資料庫需要完成從E-R圖到關系表結構,以及關系表之間主外鍵的映射,圖資料庫則需要把E-R圖(Conceptual Model)映射成用點和邊表示物體與物體之間關系的資料模型,
4. 關系資料庫 VS 圖資料庫
關系資料庫與圖資料庫兩者之間有什么區別呢?
首先,我想強調的是兩者不是替代關系,至少就目前的技術和研究的發展狀態而言;但是兩者確實有很多區別,因此造成了在使用場景和內核系統設計中的巨大區別,
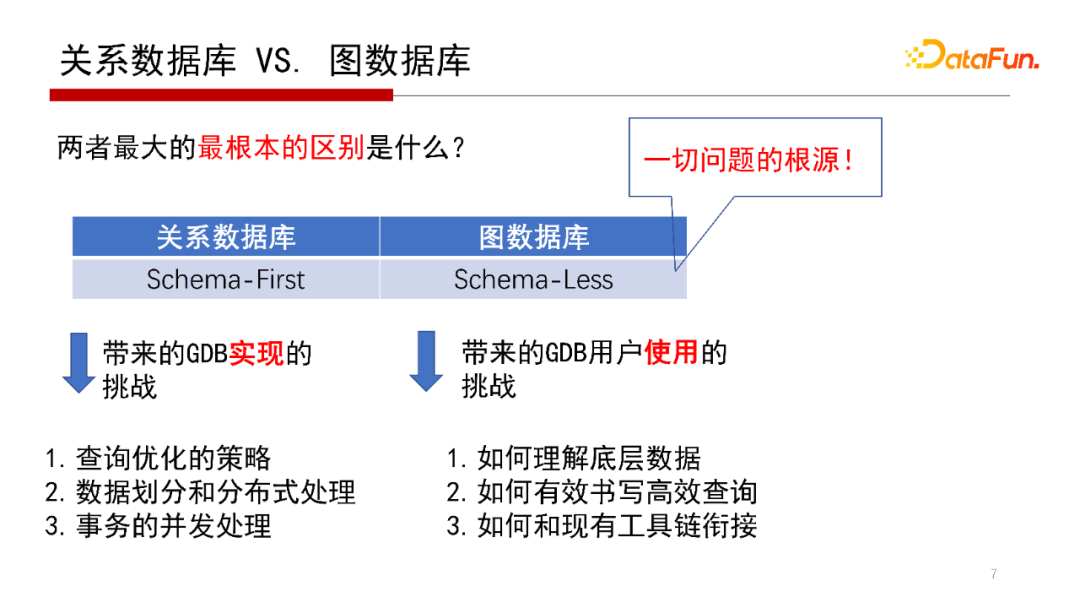
這里認為最核心的區別是,關系資料庫是Schema-First(模式優先),圖資料庫是Schema-Less(少模式),使用關系資料庫第一步是先建表結構以及定義表之間主外鍵關系,這個表結構和表之間主外鍵關系稱為Schema,關系資料庫特點是Schema-First,意思是先有表結構才有資料;圖資料庫有時候稱為Schema-Less,甚至有人認為是Non-Schema,是Schema-Less的資料,意思是匯入的資料并不是完全與預先設計的Schema完全符合,
例如,假設描述人物資訊時,有些人有10個屬性,另外一些人只有5個屬性,如果在關系資料庫中只能取兩者屬性的合集才能定義表結構;在圖資料庫當中每個人按需(on-demand)分配屬性值就可以,以及邊表示的關系也可以是不一樣,
關系資料庫是Schema-First,也就是首先要有表結構,才能灌入資料;而圖資料庫跟NoSQL有點兒相似,只要有資料來,哪怕資料并不符合前置定義的Schema,資料仍然可以灌入,
兩者的區別帶來了在實作和使用上的兩個大的區別:
在實作方面,即DBMS(資料庫管理系統)內核實作層面,傳統關系資料庫RDBMS的很多查詢優化策略(即查詢引擎的執行策略)、資料劃分和分布式的處理,以及事務的并發處理都是定義在表結構上的,因此關系資料庫的很多技術是依賴于Schema的;而在圖資料庫中,因為沒有像關系資料庫一樣的Schema,相關的技術都需要重新考慮,這是從實作角度帶來的資料庫系統DBMS本身帶來的技術挑戰,
在使用方面,即用戶如何使用DBMS系統層面,對于使用者來說,使用關系資料庫到使用圖資料庫最重要的是概念和思維方式的轉變,關系資料庫是用表結構理解資料,圖資料庫則是以圖的思路來理解資料和資料質量管理,另外,兩者查詢陳述句也不一樣,和現有工具鏈也存在銜接的問題,因為兩者定位不同,所以不能說圖資料庫和關系資料庫是一個替代關系,但從工具鏈角度、生態來說圖資料庫是一個新的變化,
5. 圖資料庫
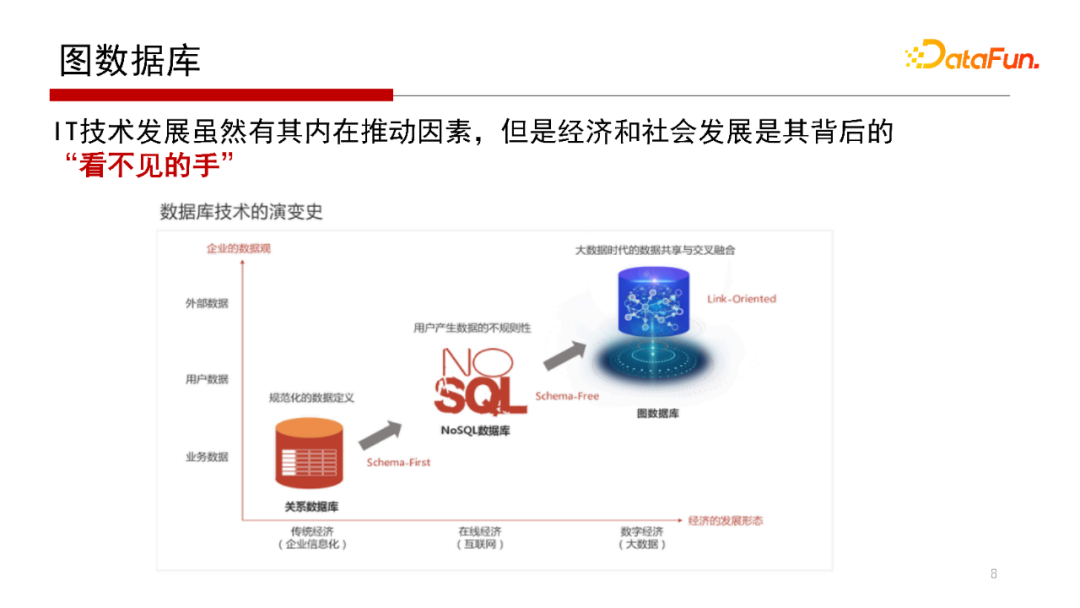
隨著研究與實踐應用的進行,我們越來越發現,雖然IT技術發展有內在的推動因素,但是經濟和社會發展也是“無形的手”,這里我們不去詳細討論從資料管理系統(DBMS)早期從層次、網狀資料庫到關系資料庫轉變的程序,其實這個早期程序的核心解決的是如何將資料庫系統的應用程式開發人員與資料庫系統的內核開發人員進行有效隔離,以提高生產效率的問題,這是一個軟體系統演化的程序:完成了從最原始的檔案系統管理資料,到構建起一個獨立的資料庫系統軟體來管理資料,
這里,我們重點觀察一下從關系資料庫到近些年NoSQL再到Graph Database,這一步一步轉變,并不是說完全替代,只是隨著經濟和社會發展出現了NoSQL、出現了Graph Database,這里我們也不從軟體系統演化的技術邏輯去做分析,而是從市場主體的企業的資料觀角度去試圖理解這點變化,前面已經提到關系資料庫是Schema-First,其特點是需要有一個表結構,表結構來自E-R圖,E-R圖從需求來,需求來自企業本身對這個任務有一個很清晰的業務邏輯,它適合傳統經濟場景,解決的是傳統企業的資訊化問題,傳統企業只有把問題資訊化才有業務邏輯,才有需求,才能明確地畫出E-R圖,有了E-R圖后才可以映射成表和表結構,通常情況下這個表結構不會做太大變化,因為關系資料庫表結構或Schema做變化是一個非常耗時的任務,
在互聯網經濟時代,資料不僅僅是企業內部業務系統產生的,有很多資料的產生也不滿足提前預設的Schema,這類資料通常稱為Users Generate Content(UGC),這樣的資料存盤需求催生了 Key-Value為代表的NoSQL資料庫系統,以解決在線經濟中互聯網情景下用戶產生的資料不規則、不滿足預設Schema的資料存盤問題,
前面提到的NoSQL關注的是用戶及相關資料,傳統關系資料庫關注的是企業的內部業務資料;而圖資料庫關注的是外部資料,在大資料、資料經濟時代講究的是資料之間融合和關聯,因為一個企業在做業務執行、決策判定的時候,需要大量的外部資料,在企業經營時,需要跟其他單位做一些資料的交換,獲取一些外部資料,而外部資料獲得與企業本身掌握的資料之間要完成資料的關聯,而這種資料關聯以“圖”的形式表示是最為合適的;圖的點和邊之間的關聯,是能夠表達資料之間深層次的語意相關性的,因此認為圖資料庫是數字經濟和大資料時代的一種重要的資料模型,
從上面的分析可以看出,技術的發展通常是有著經濟和社會發展作為背后的推動和選擇因素,
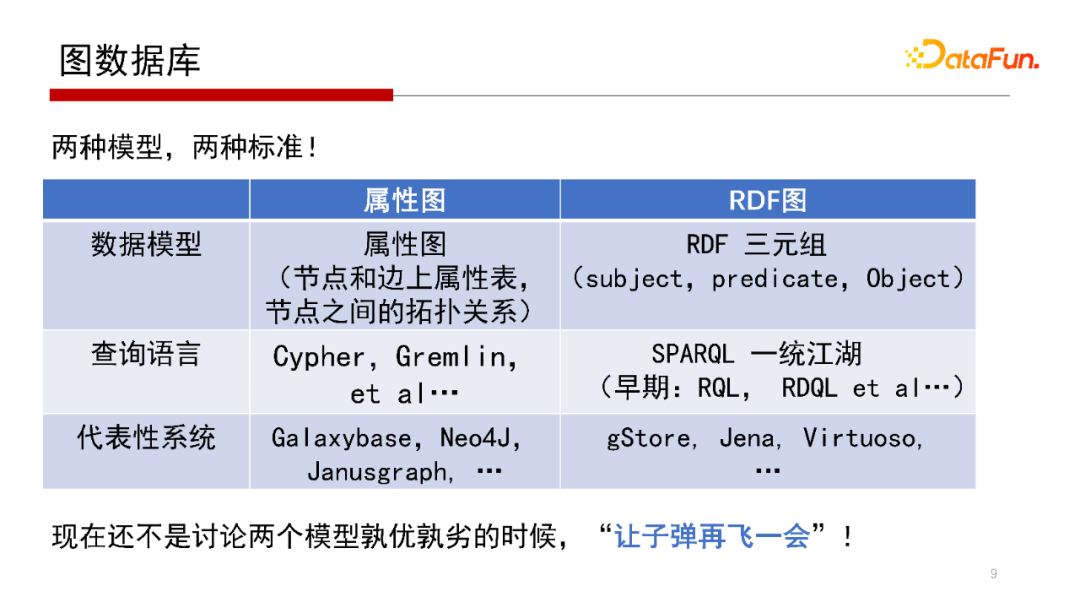
目前看,圖資料庫通常有兩大類,一種是屬性圖,另一種是RDF圖,
其中,屬性圖在節點和邊上有屬性表,從某種角度上講,它仍帶有關系資料庫的基本特性,類似表結構的形式,實際是采用Key-Value形式來存盤的,針對屬性圖的節點和邊上的屬性表的定義,各個廠商的差別也比較大,例如有些模型中不允許同一個節點分屬不同的類別,因各個廠商有自己的查詢語言,其中查詢語言使用比較多,用戶規模比較大、有一定影響力的查詢語言包括Cypher、Apache開源專案的Gremlin等,
RDF圖全稱是Resource-Description-Framework,是從語意網演變來的,借用了很多語意網的協議標準,具體就是語意網框架下的資料語言與查詢語言的標準,包括RDF三元組和SPARQL,RDF三元組表示其圖結構是用主謂賓的形式來表達的,查詢語言是SPARQL,當然早期語言還有RQL、RDQL等,這類圖資料庫系統最大的好處是協議統一,從資料模型到查詢語言的模型都有一套嚴格的規范標注,代表性的系統包括我們北京大學資料管理實驗室(PKUMOD)的gStore系統、Apache開源專案Jena等,
這兩個模型孰優孰劣,現在還不是很好討論,因為兩個模型各有各的優劣,例如,語意網特點是比較容易支持后期的推理,而且其標準化做得比較好,而目前圖資料庫也正在做標準化的事情,評判兩個模型的優劣也不應該僅從技術角度做評判,因此認為還不是評判的時候,下面我們簡單介紹一下相關模型,
6. RDF圖資料模型

RDF圖的特點是主、謂、賓表示方式,無論是表示物體、屬性還是物體與物體的關系,都用主謂賓的表示,
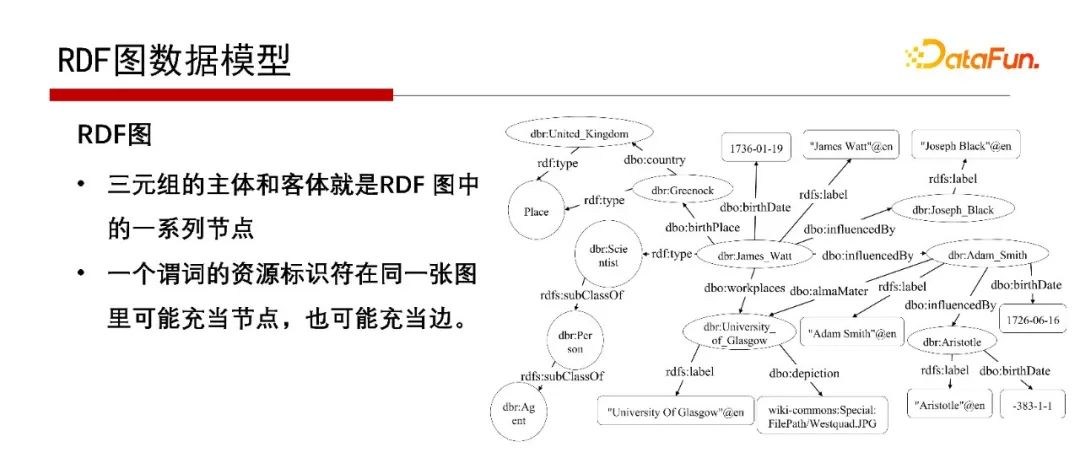
那為什么是圖的形式呢?因為主語和賓語就是兩個點,它們之間的關系就是一條邊,因此是RDF Graph;不是把RDF資料看成Graph圖,而是它本身就是Graph圖,只是它不僅可以表示成三串列的形式,也可以表示成Graph圖的形式,
7. SPARQL查詢語言

查詢語言SPARQL與SQL很像,也是一種描述性語言,具體如何執行依賴資料庫引擎,
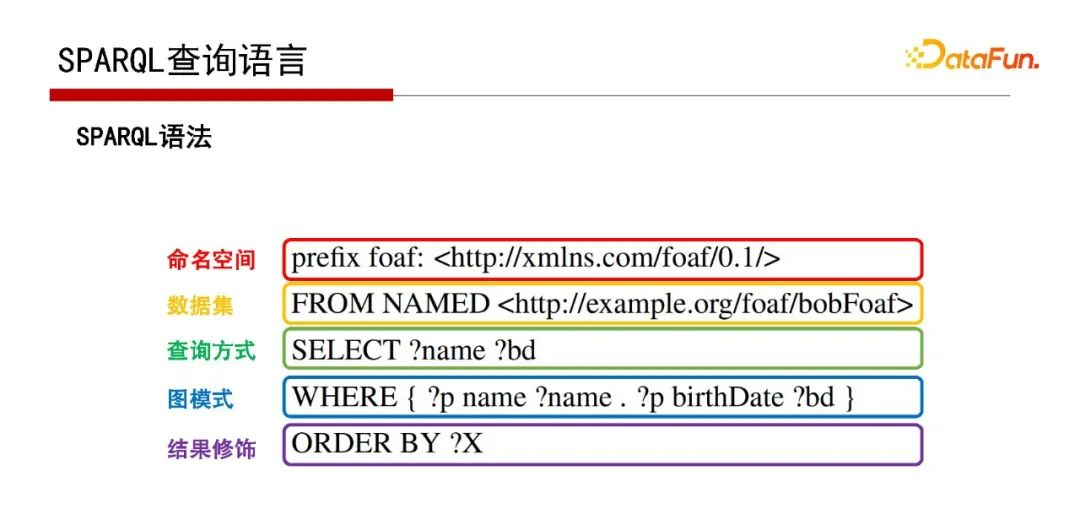
此為SPARQL查詢語言的語法示例,

除基本的圖模式外,還有復雜的圖模式,如帶有OPTIONAL、UNION等的陳述句,見以上示例,這里不再贅述,
8. 屬性圖模型
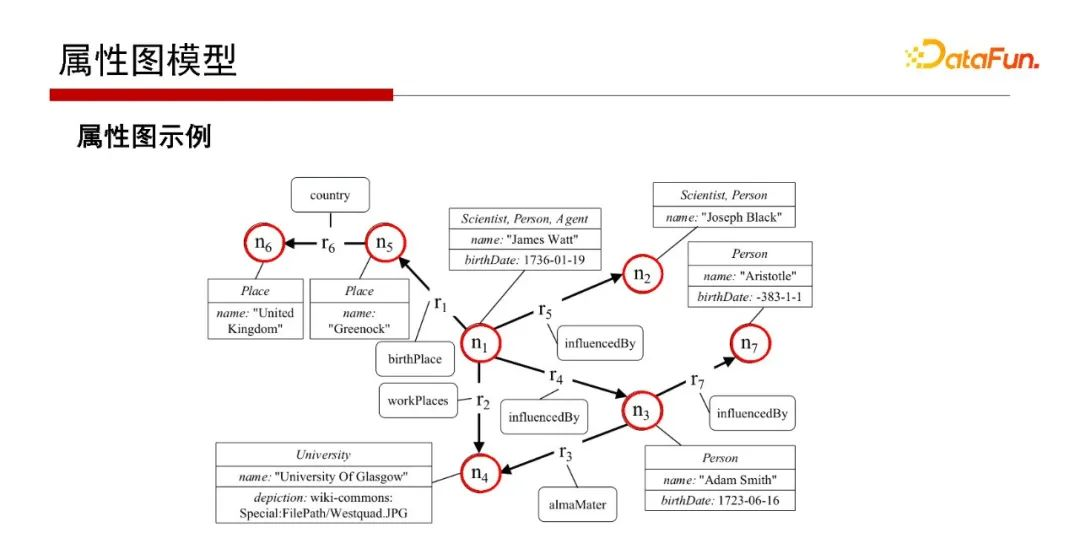
屬性圖如之前所講,其點和邊都是有屬性表的,如Person,Person的名字name、Person的birthDate;如邊r7上目前只畫了標簽influencedBy,但實際也可以是屬性表的,這是屬性圖的一個非常好的優勢,
9. Cypher查詢語言

屬性圖的查詢語言Cypher,如示例簡單解釋一下Cypher查詢語言的含義,找到屬性圖中任務的出生地點以及受多少人影響,這個查詢語言是:
MATCH(r:Person),首先是找一個人,型別是Person,將所有的Person復制到一張中間表中,中間表的名字為r;
OPTIONAL MATCH(r)-[:birthPlace]->(pl:Person),r表中的每個記錄是否有birthPlace,左連接方式,如果有birthPlace,則找出;
MATCH(r)-[:influencedBy]->(p:Person),再看這些人受哪些人影響,因為帶,則把直接影響或多跳即間接影響的人都找到,

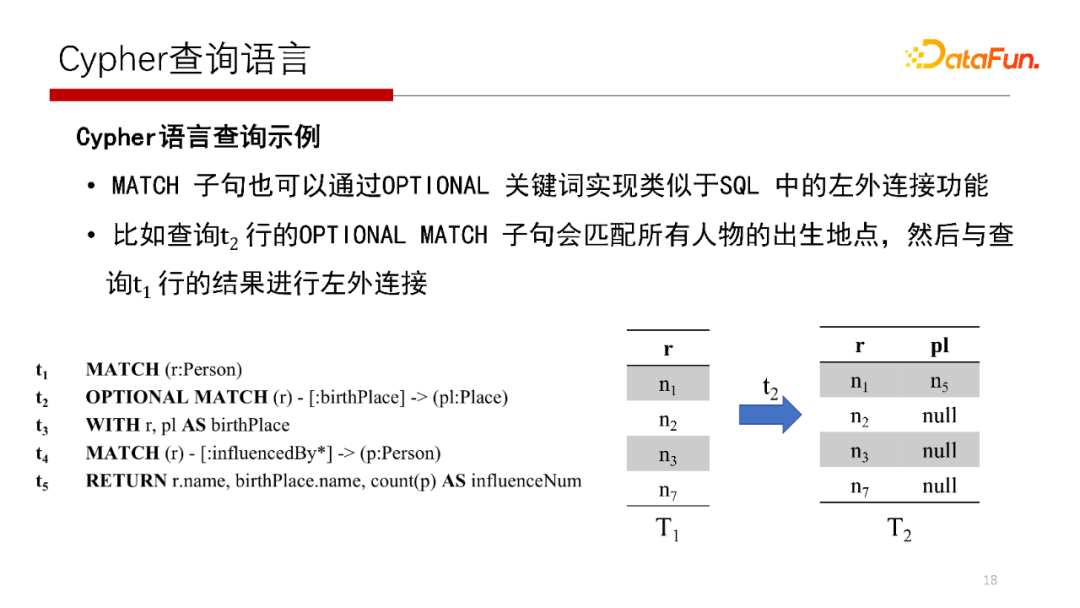

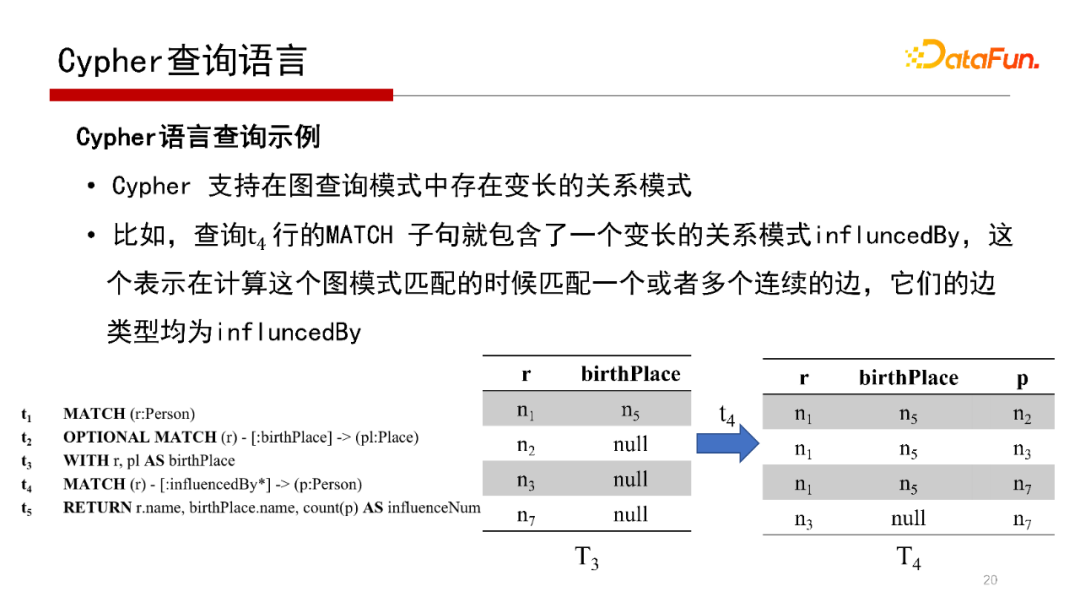
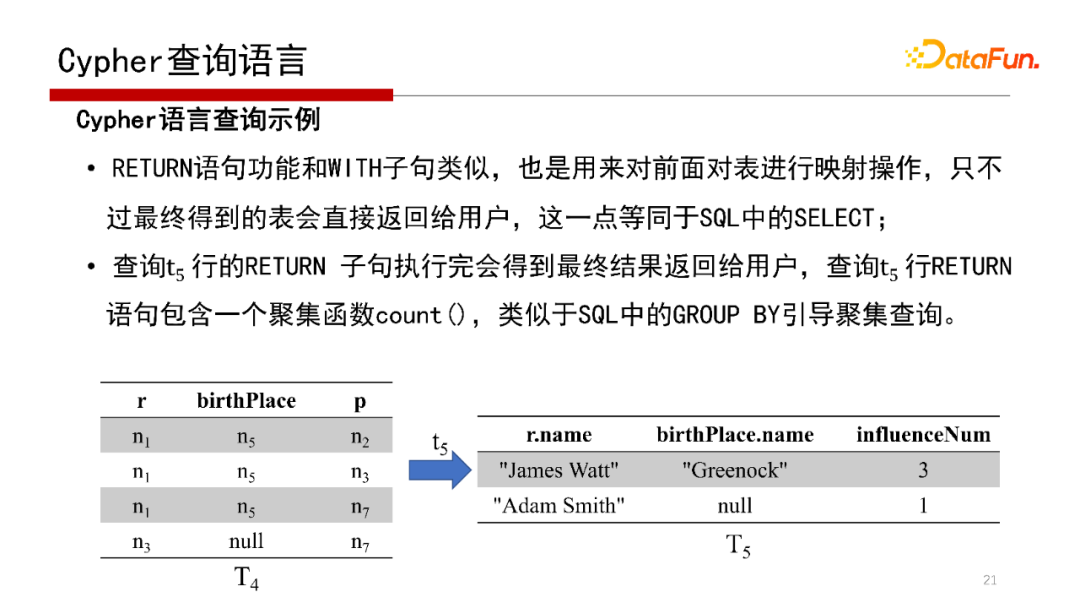
Cypher查詢語言的執行見上圖,這里不再贅述,
--
02 子圖匹配查詢及其優化方法
前面講了資料模型、資料模型的查詢語言,那與本期主題“子圖匹配”有什么關系呢?
1. 子圖匹配
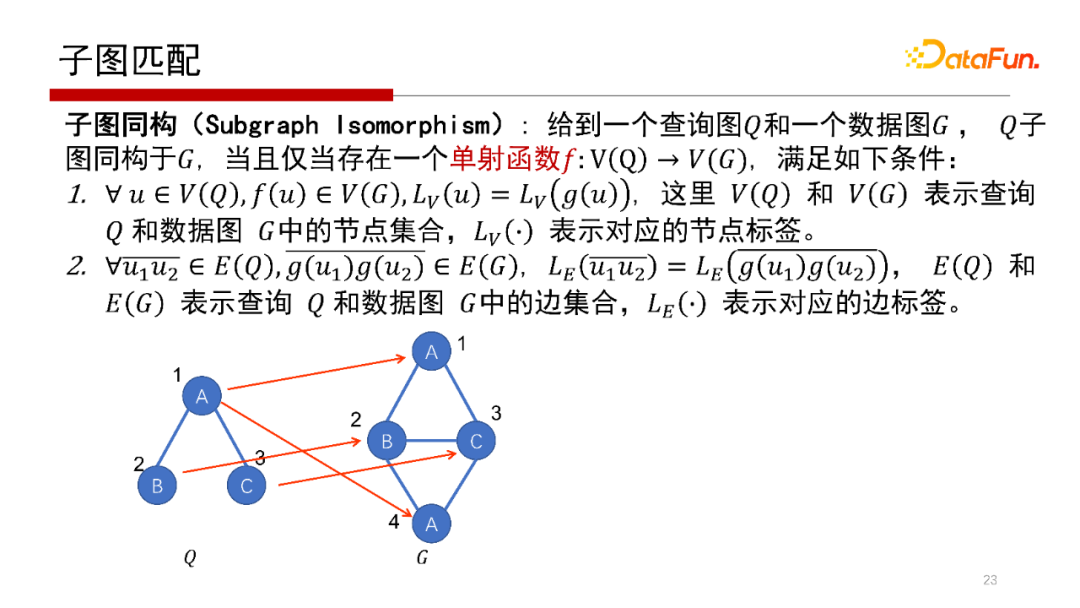
子圖匹配核心概念是給到一個查詢圖Q和一個資料圖G,Q里的每一個點通過一個單射函式映射到G當中去,即單射函式f:V(Q)→V(G),Q中的每一個點在單射函式Function(f)作用下唯一映射到G的每個點上去,如上圖中Q的1、2、3在G的中的第一個子圖匹配是(1、2、3),第二個子圖匹配是(2、3、4),子圖匹配的本質就是給一個Q,找到Q在G中的所有匹配,如示例中找到所有的二叉結構,
2. 問題的復雜性

從計算復雜性來講,子圖匹配是一個非常復雜的問題,如果對查詢圖Q不加限制,子圖匹配的判定是NP-Complete的;列舉所有的子圖匹配出現的位置是NP-Hard,雖然匹配演算法本身是指數的,但在實踐中,可以采用大量的過濾策略來檢索搜索空間,從而提高查詢的性能,
3. 子圖匹配與圖資料庫
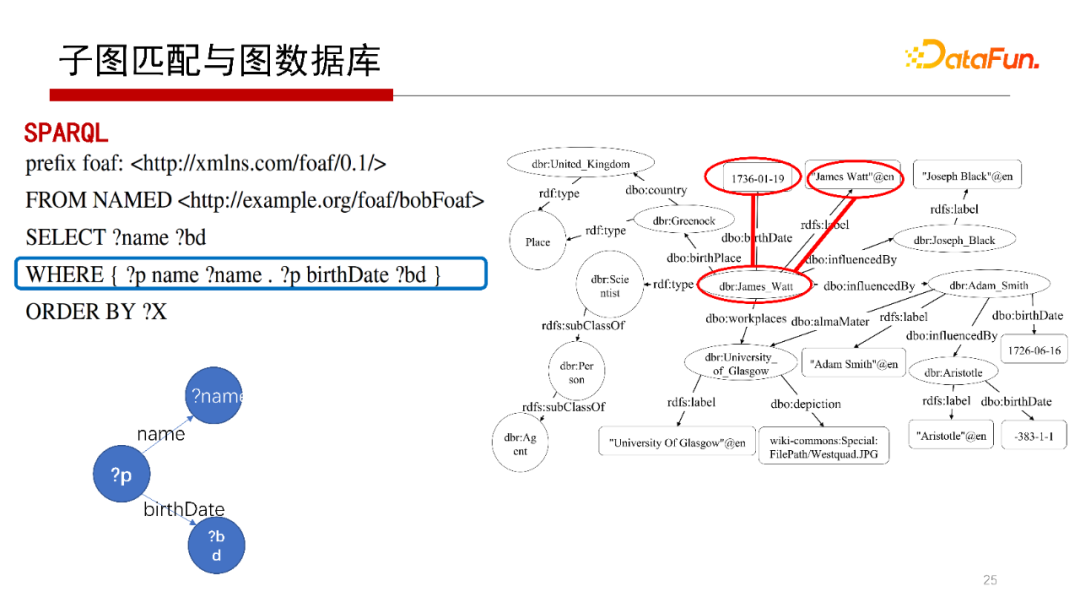
子圖匹配與圖資料庫有什么關系?
上面的SPARQL查詢的WHERE子句部分,可以表達為一個查詢圖,如這頁中的左下圖,其中帶有“?”的“?p”表示變數的含義,我們在這個例子中可以找到圖G中的子圖匹配,如紅色表示的部分,執行上述SPARQL陳述句,本質上就是Q到G的子圖匹配問題,其中,Q可能會更復雜,它不僅僅是Basic Graph Pattern(基礎圖模式),這個后面有機會再闡述,
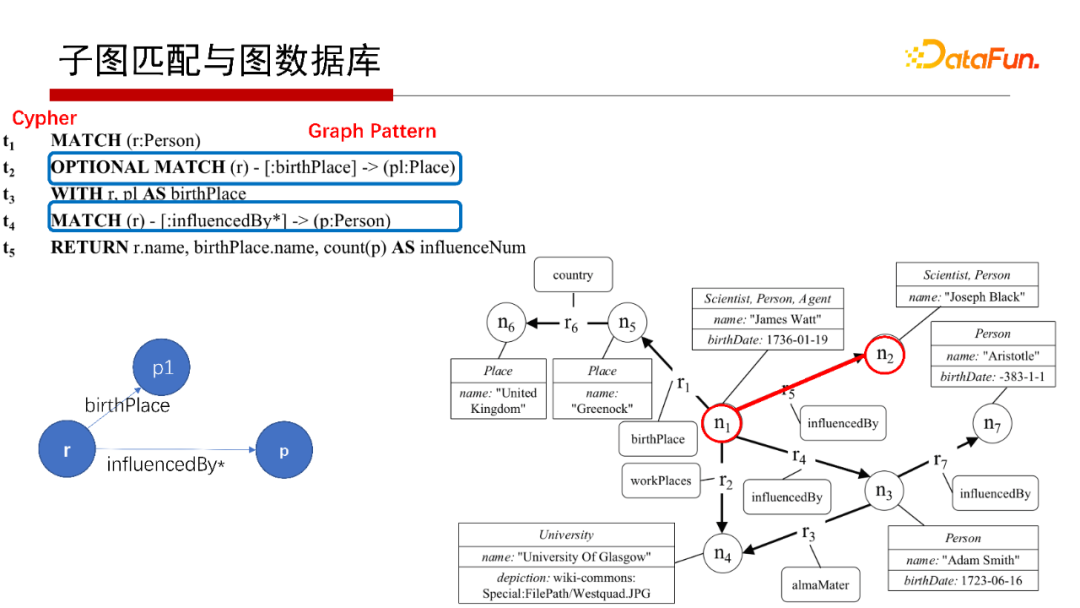
對于Cypher查詢語言也是一個子圖匹配,如上圖中OPTIONAL MATCH和MATCH陳述句,其可以表現為上圖中左下角的Q,在匹配右側G時,“birthPlace”是匹配到節點的屬性值上去了,僅此而已,其實也是一個子圖匹配的程序,
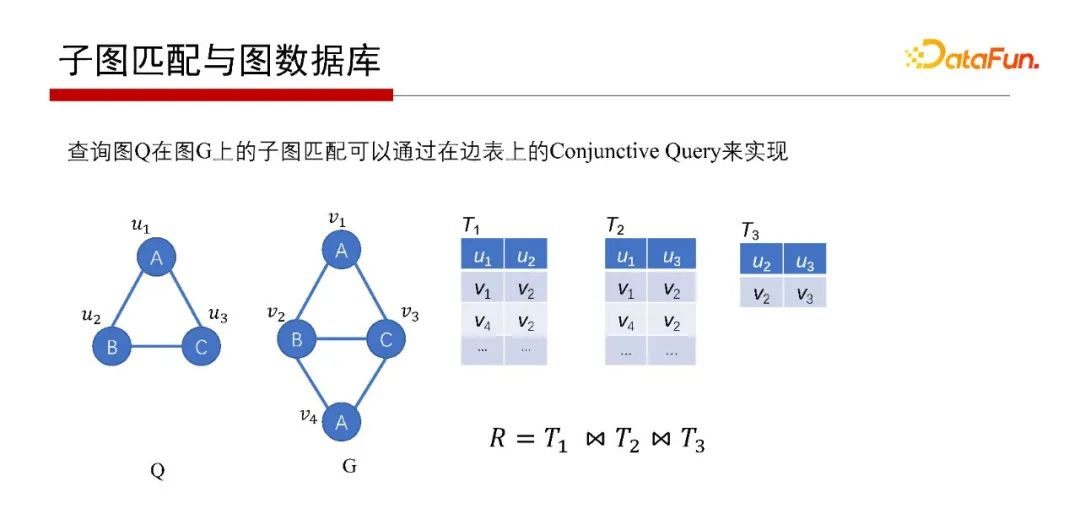
那子圖匹配如何解呢?子圖匹配問題用關系資料庫也可以解,如上圖G存在邊表里,表示邊的起點和終點,回答Q在G中的子圖匹配查詢,則分別先找到匹配查詢圖Q中的AB邊的是T1表、匹配AC邊的是T2表和匹配BC邊的是T3表,然后T1、T2、T3做自然連接(Join)操作,如果結構非空,就找到Q的子圖匹配了,所以,如果用關系代數來解決子圖匹配的問題,則等同于關系資料庫的Conjunctive Query,
4. 子圖匹配的演算法
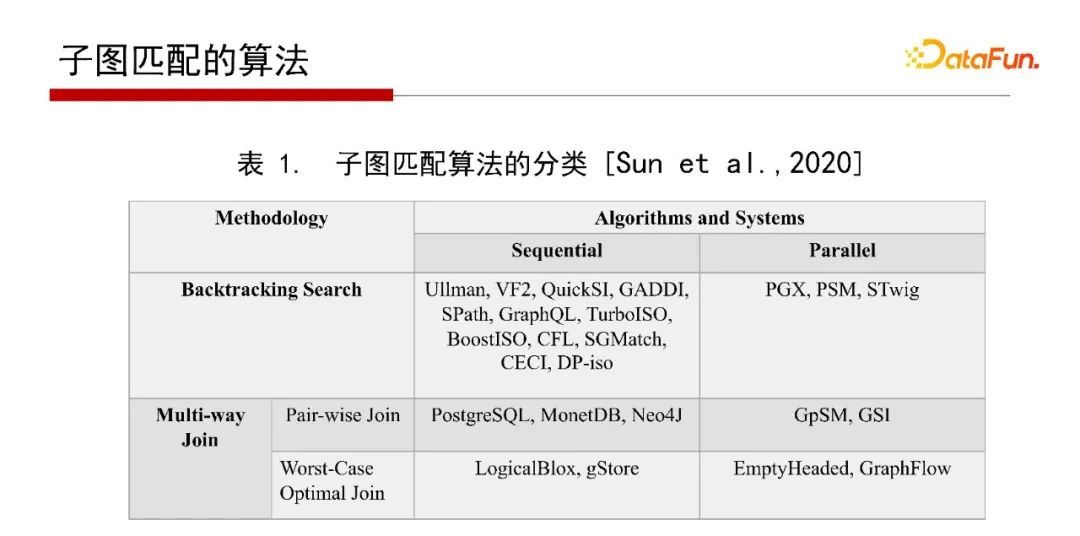
在一篇SIGMOD 2020實驗論文中指出,做子圖匹配可以有兩類演算法,一類為基于深度搜索加回溯的方式(Backtracking Search),一類為基于廣度優先的Multi-way Join方法,
5. 子圖匹配的搜索空間
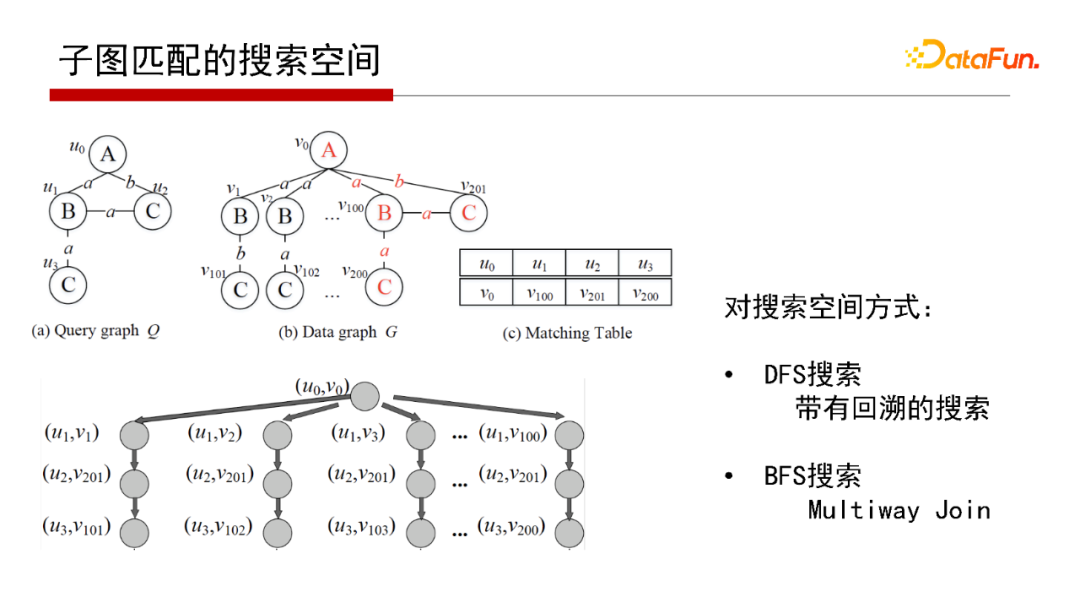
這里對子圖匹配的兩類演算法形象化解釋一下,假設有個Q和一個G,找到Q在G的子圖匹配,實際就是在搜索空間查找,這里把搜索空間定義成一個搜索樹(如上圖左下角的屬性圖),Backtracking Search搜索的策略是深度優先(DFS搜索),再回溯回來;Multi-way Join搜索的策略則是寬度優先(BFS搜索),即在搜索樹上一層一層去找,
6. 帶有回溯的搜索演算法(Backtracking Search)
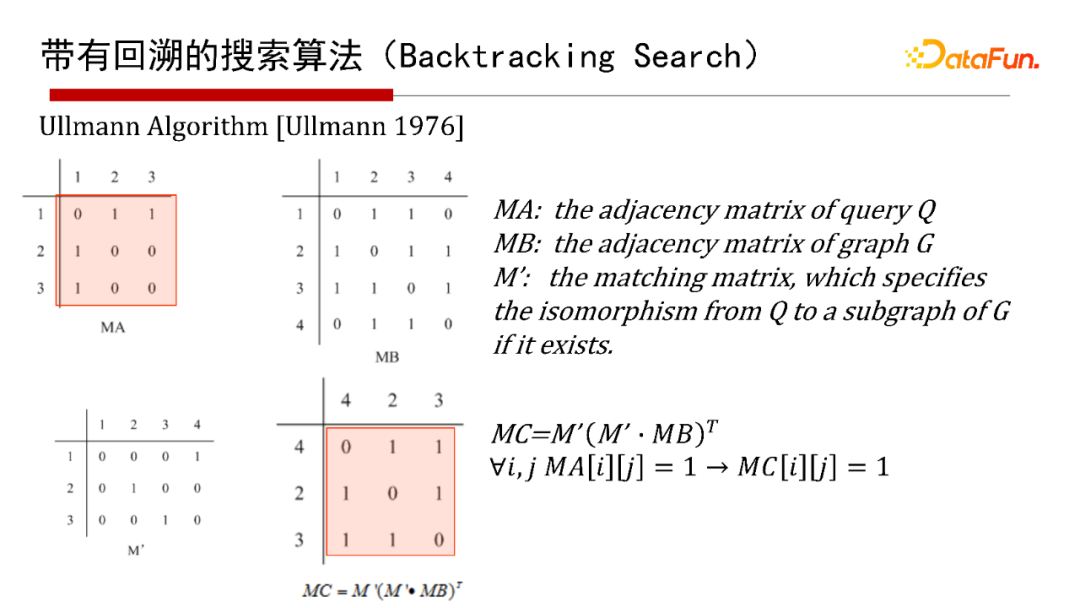

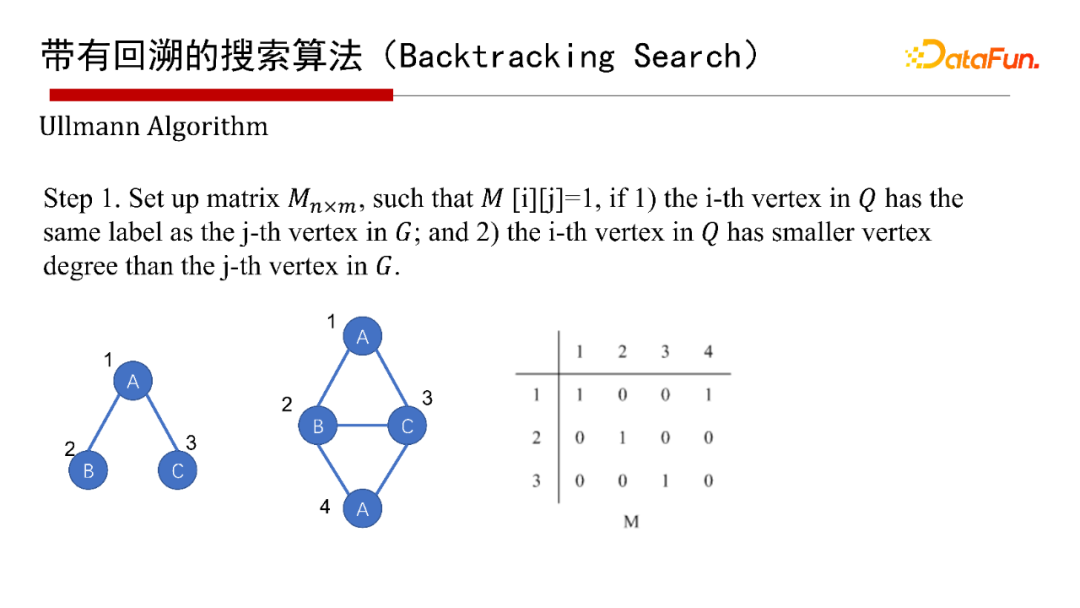

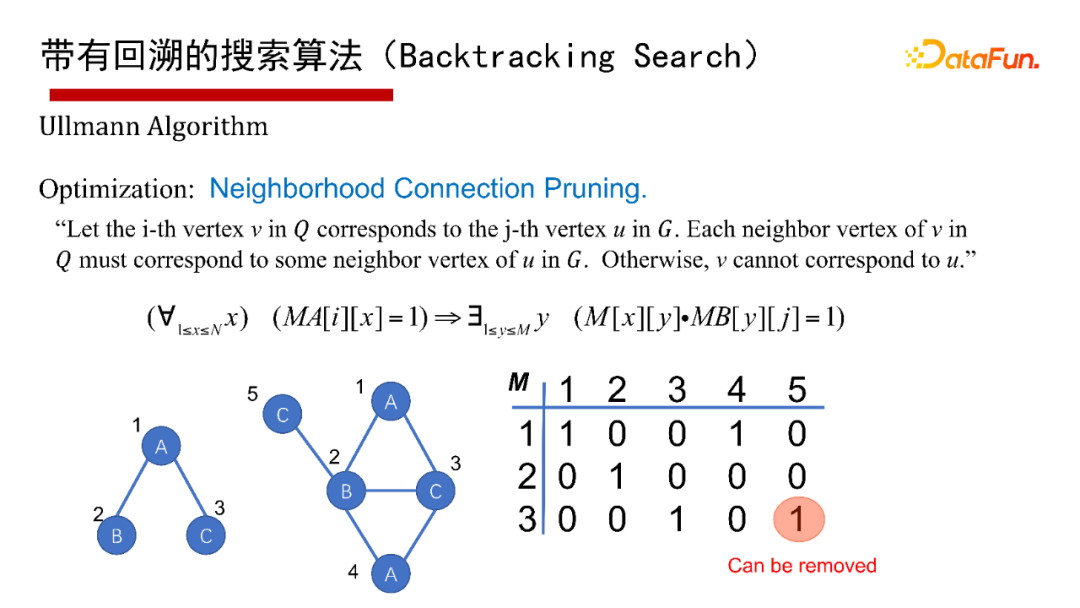
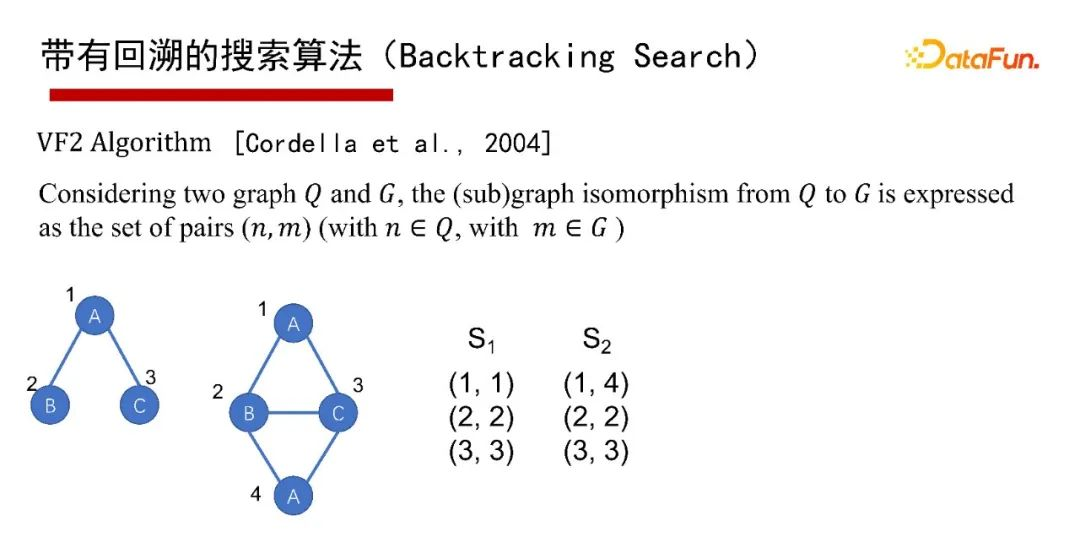
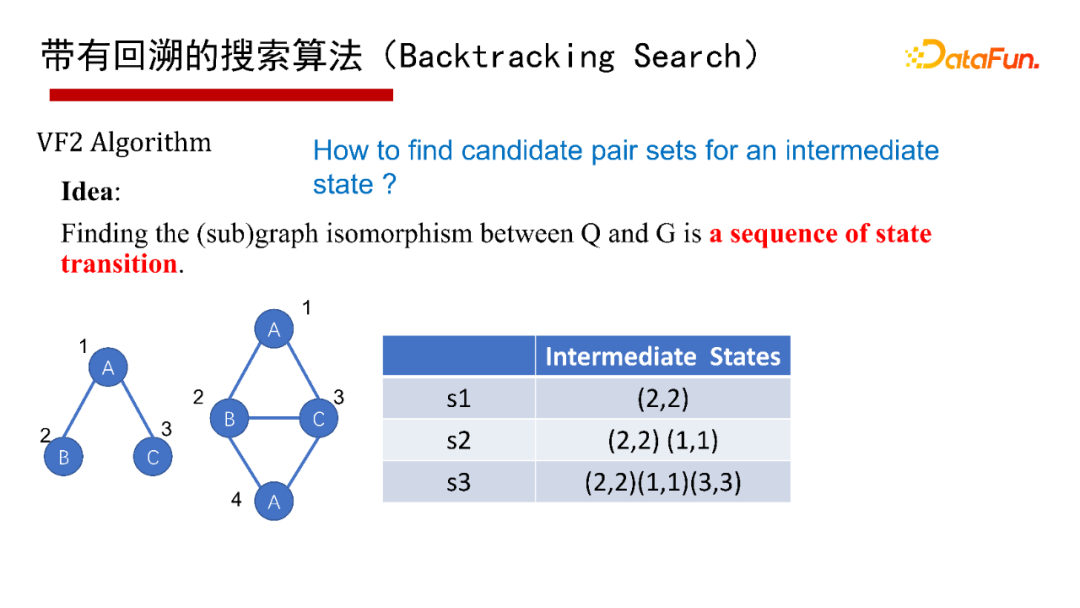
帶有回溯的搜索演算法(Backtracking Search),有1976年最早開始的Ullmann演算法,2000年的Ullmann Algorithm演算法,2004年的VF2 Algorithm演算法等,這里就不再具體介紹演算法本身了,有興趣的同學們可以參考給出的參考文獻,

這里采用通用的演算法框架(Common Framework)來講講帶有回溯的搜索演算法,給一個查詢圖Q,首先定義一個節點被匹配的順序,即最先匹配哪個點,然后是哪個點(generate a matching order),然后每次試圖按節點匹配順序進行一個點一個點的匹配;如果當前狀態匹配不了,則回溯;如果要找全部的解集,也得做回溯,其優點是可避免產生大量的中間結果,因采用深度優先,僅有遞回呼叫堆疊的空間,沒有什么中間結果,其缺點是難以并行執行,會有大量的遞回開銷,因此適合做LIMIT K和TOP-K的子圖匹配查詢,即只回傳K個或TOP K個結果(K很小的情況下),
7. 基于多路連接的演算法 (Multiway Join)
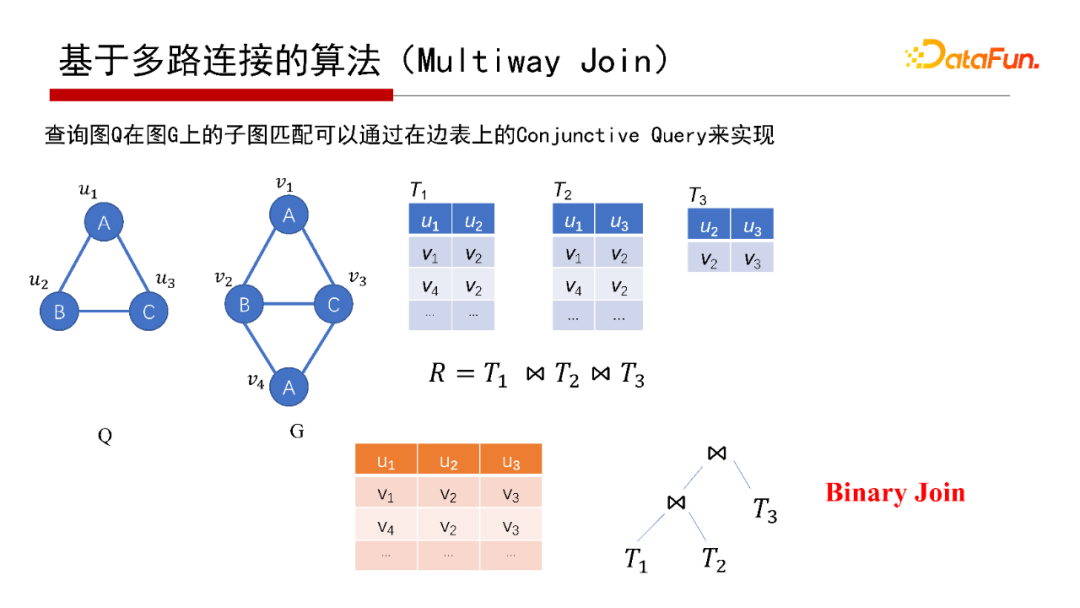
對于寬度優先的演算法,實際關系資料庫每次的Join就是寬度優先,子圖匹配從邏輯來說是T1、T2、T3的Join操作,Join怎么執行呢?從Join執行角度來說,有兩種不同的執行方案,一種是Binary Join,即第一張表T1和第二張表T2作Join,結果再與第三張表T3作一次Join,是以邊為中心,
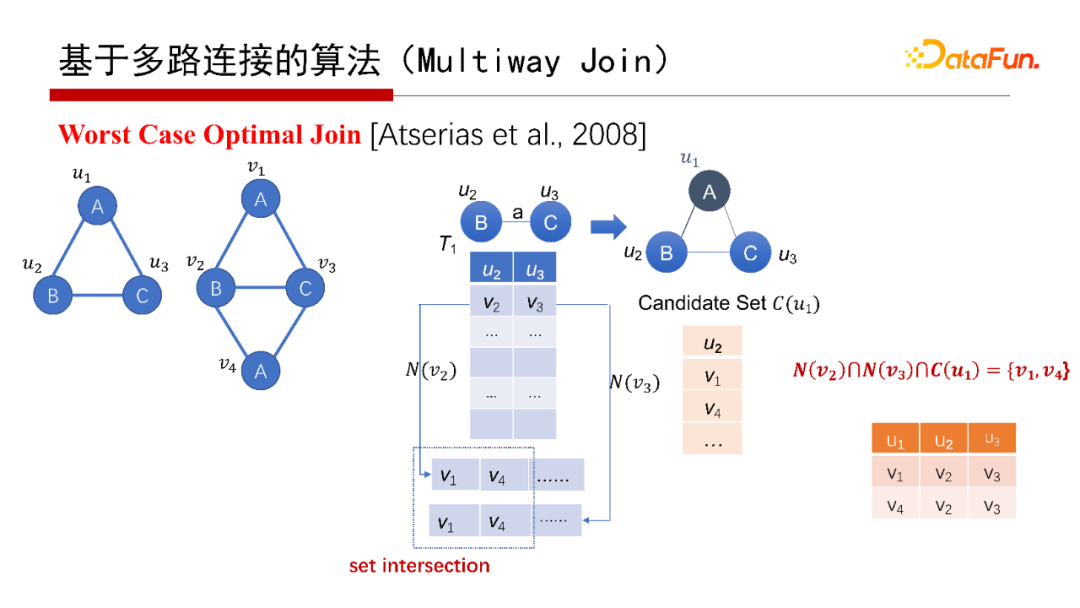
還有一種是Worst Case Optimal Join(具體可以查看給出的參考文獻),例如,假設已經匹配了BC這條邊,即G中的v2和v3匹配了Q中的u2和u3,那么要找查詢圖Q的ABC的匹配,則查找G中是否有一個三角形恰好能夠匹配Q的ABC,并且三角形包含v2和v3,例如考慮中間結果表的第一行,把v2和v3的鄰居N(v2)和N(v3)找出來,然后兩個集合做一個交集set intersection,再和A點的候選集合C(u1)做個交集,N(v2)、N(v3)、C(u1)三個集合的交集不為空,在這個例子中交集為{ v1, v4};將其分別串聯到v2和v3后面,得到v1、v2、v3和v4、v2、v3這兩個匹配,在上面的例子中,可以對每一行都執行該操作,因此該演算法很容易做并行,

請注意上面給出的WOJ演算法中,有一個很重要的操作,就是集合求交,

之所以稱之為Worst Case Optimal Join,是針對Binary Join而言,其復雜性是和它在worst case情況下的輸出結果數量相匹配的,以ABC三角形查詢圖為例,其最多有N1.5個三角形,N是邊的數目,如果用Binary Join,有可能會產生N2的中間結果,如果采用Worst Case Optimal Join演算法,則永遠不可能產生超過N1.5的中間結果,其運行時間的復雜性也是N1.5,對于其他的查詢圖,Worst Case Optimal Join也表現出該種特點,
8. Binary Join + Worst Case Optimal Join

但并不意味著Worst Case Optimal Join演算法一定比Binary Join演算法好,Worst Case Optimal Join演算法只是保證在最差情況下比Binary Join演算法好,
滑鐵盧大學做的圖資料庫系統GraphFlow,就提出把Worst Case Optimal Join和Binary Join相結合,在子圖匹配的執行選擇中既考慮Binary Join,又考慮Worst Case Optimal Join,

啟發式地講,Worst Case Optimal Join和Binary Join各有好處,Binary Join比較適合沒有環或者是樹形或者環比較稀少的查詢圖,Worst Case Optimal Join比較適合密集環形的查詢圖,因此,比較好的Join方法是依賴于查詢圖的圖結構,
--
03 我們的作業
1. RDF圖資料庫
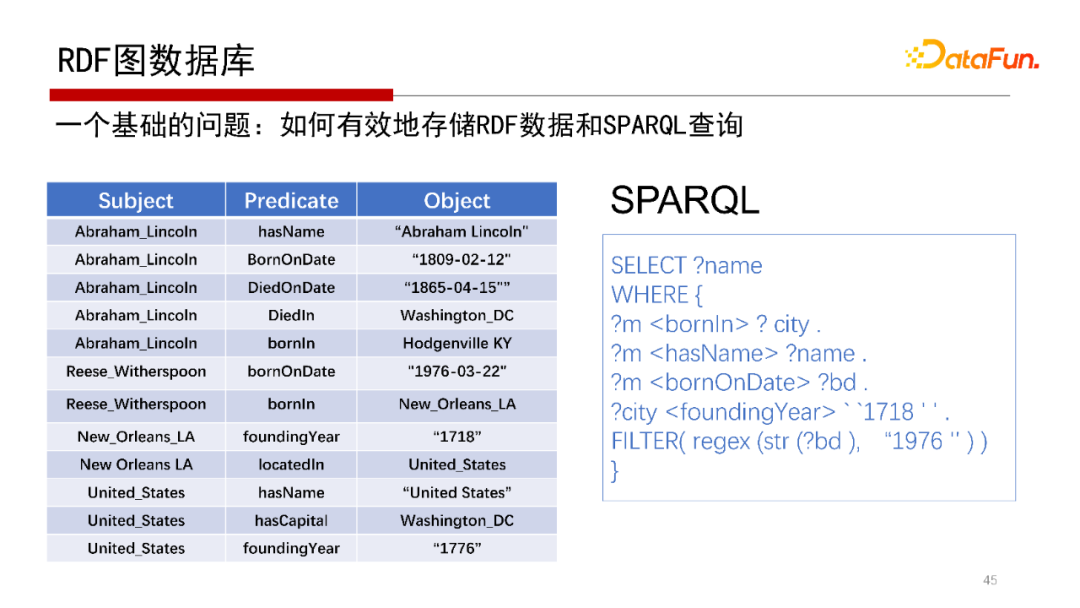
RDF圖資料庫,查詢語言是SPARQL,
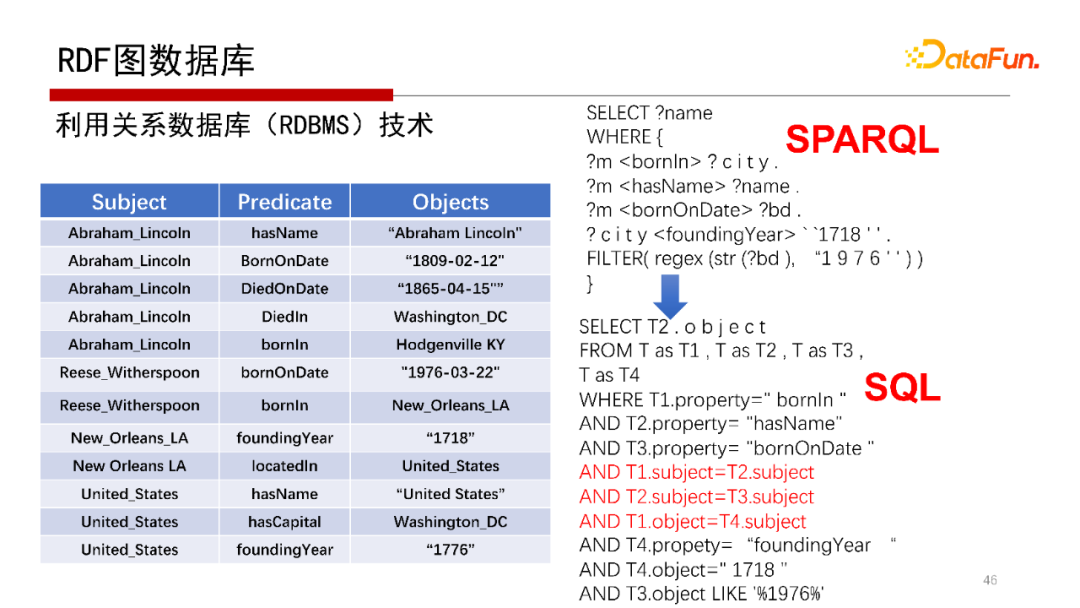
SPARQL陳述句也可以用關系資料庫來解,可以將SPARQL轉化為SQL陳述句,

然后用SQL陳述句去執行,或者可以把一張大表的表結構劃分成不同的表,仍然采用轉化成SQL陳述句,類似關系資料庫一樣去查詢,如Oracle、DB2最新的版本支持RDF,就是用這種方法去做的,但該方法的Join會很多,性能會非常低,
2. gStore[Zou et al.,2011]
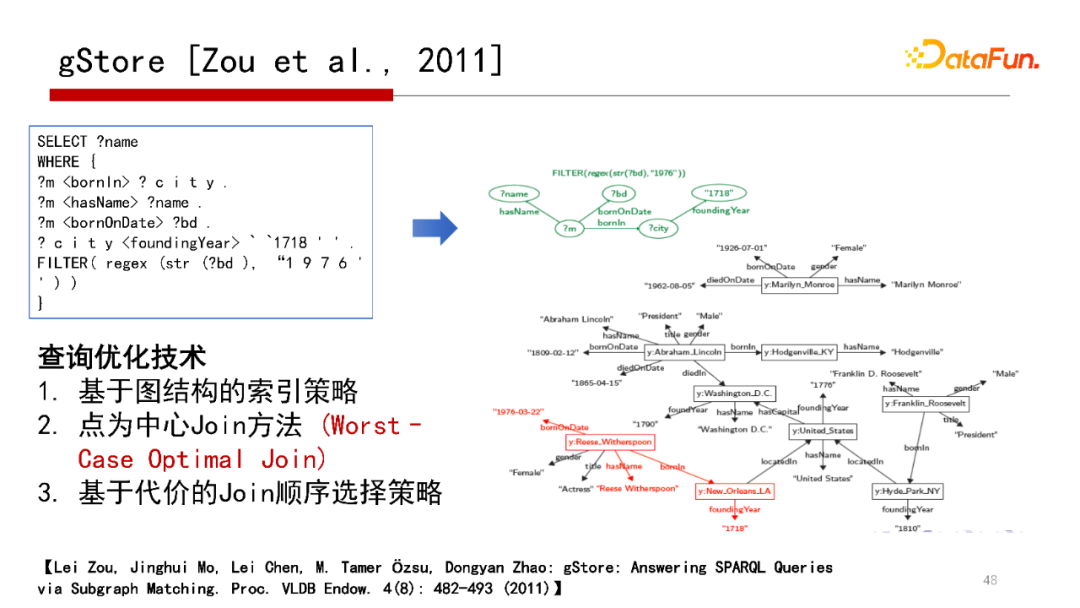
給一個SPARQL,把它Match到一個查詢圖Q,那么回答SPARQL就是在Data Graph中找到查詢圖Q的匹配,如果能找到,那么就能很快回答SPARQL,這是gStore系統最核心的思路,
gStore系統思路從技術層面,在索引的方式、Join的策略和Join順序的選擇提出了三種查詢優化方式,在原來的系統版本中,采用的是以點為中心的策略,類似Worst Case Optimal Join,沒有用Worst Case Optimal Join和Binary Join合在一起的,但在即將發布的1.0版本,則考慮了Worst Case Optimal Join 加 Binary Join合在一起的策略,
gStore的開源專案官網里有詳細的使用檔案,在gitHub和gitee(碼云在線)上面都有gStore的原始碼,
- 分布式gStore[Pengu et al.,2016]
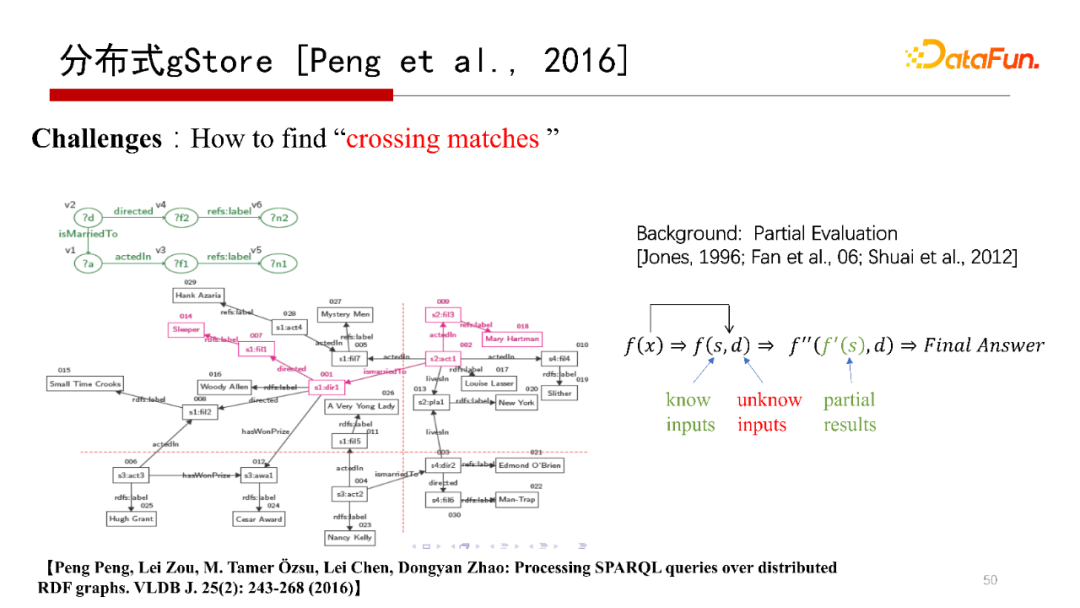
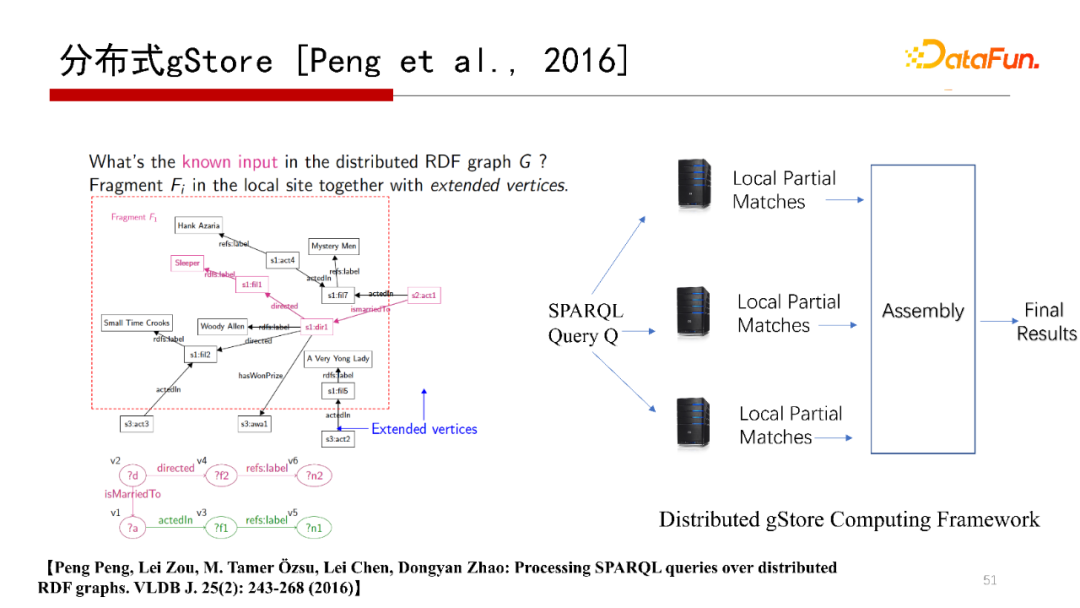
下面提到的是分布式gStore系統,解決的是單機存盤不下一個大的RDF圖,需要分布式存盤在多個機器上,而查詢結果跨在多臺機器上的問題,
4. 優化原子操作-Set Intersection

前面提到在做 Worst Case Optimal Join 時最重要的是集合求交操作,集合求交是子圖匹配中很重要的算子操作,那么集合求交怎么加速呢?

我們提出了一種利用 CPU 的 SIMD(單指令多資料流)向量計算方法,通過設計一種精巧的資料布局(Data Layout)策略,可以降低對集合求交中CPU運行的Cycles的數目,
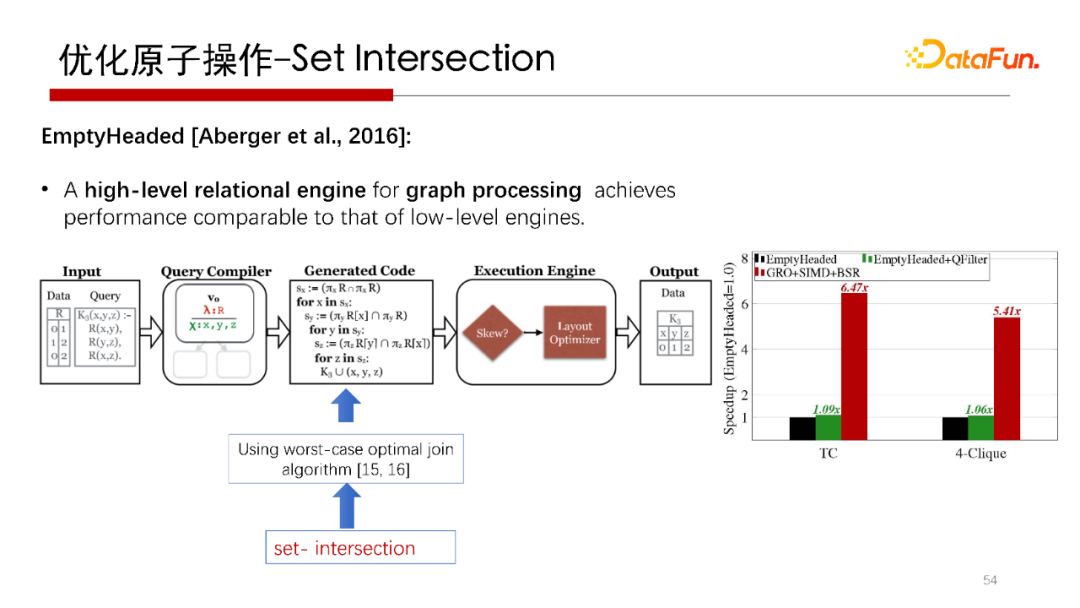
Stanford做的開源的圖處理引擎(graph processing)系統,也是用Worst Case Optimal Join做的,在其系統中,將我們研究的集合求交優化演算法替換之后,發現性能有比較明顯的提升,
5. 硬體加速
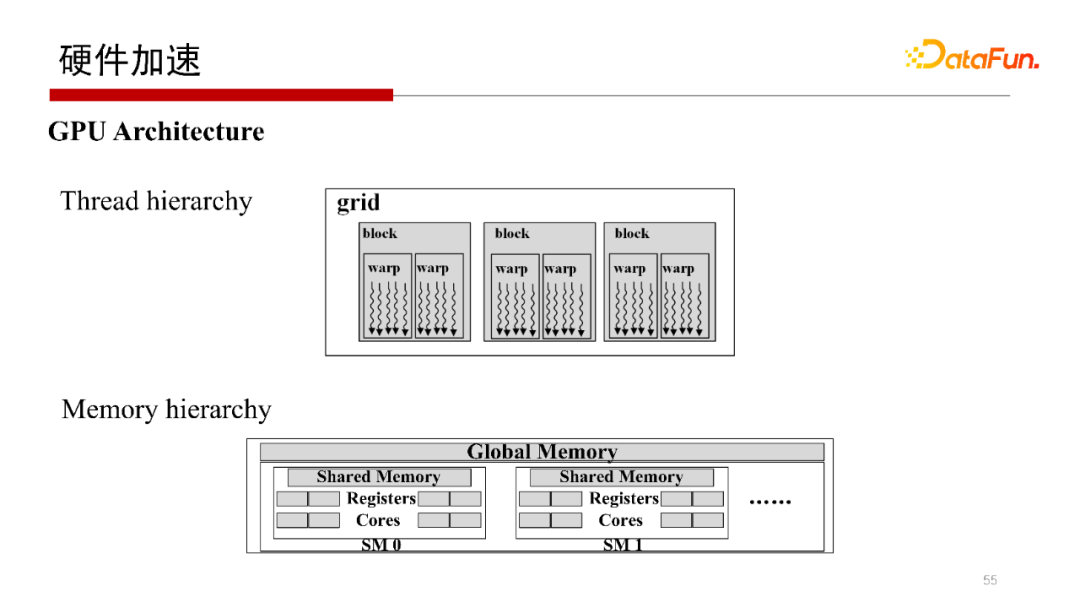

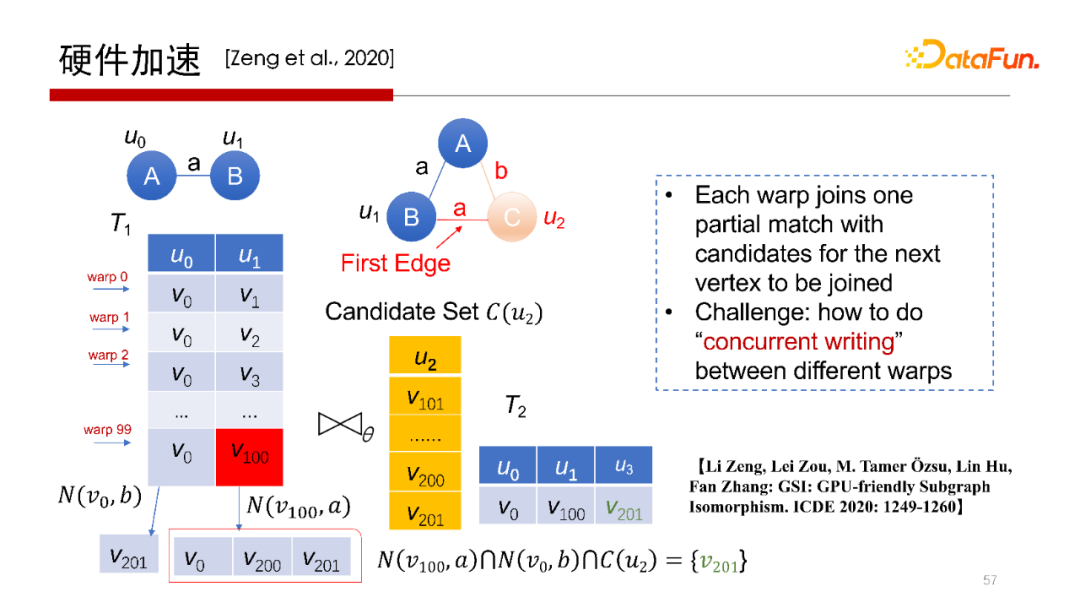
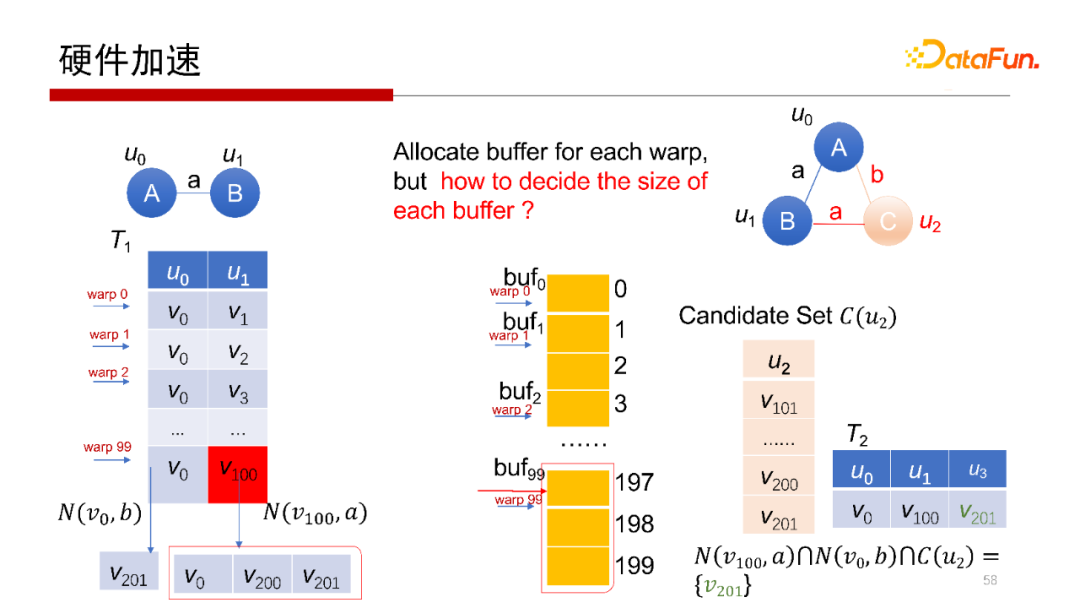
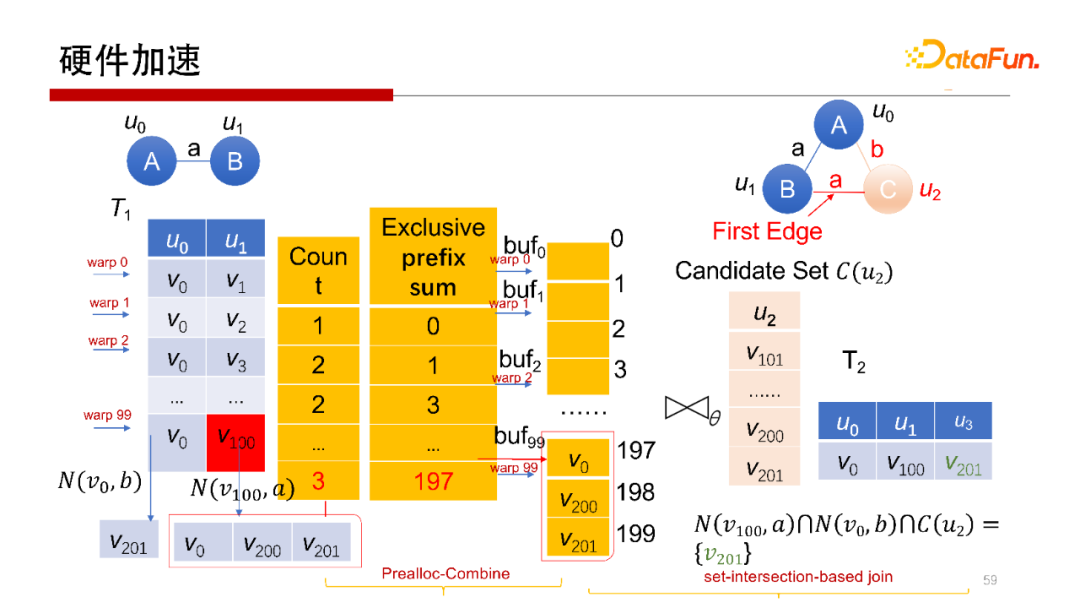
剛才提到,Worst Case Optimal Join演算法,每一行是完全獨立的查詢操作,非常容易做并行,所以會想到使用在GPU上運行操作,但在GPU上執行操作,其每個執行緒或每個wrap做計算沒有問題,但中間結果如何寫回去,如何避免寫沖突是需要考慮的,我們提出一種方案使得每一個wrap獨立地去執行,并且可以獨立地去寫,在不需要加鎖的方式下不會產生寫沖突,


以上是一些參考文獻,
今天的分享就到這里,謝謝大家,
閱讀更多技術干貨文章,請關注微信公眾號“DataFunTalk”
關于我們:
DataFun:專注于大資料、人工智能技術應用的分享與交流,發起于2017年,在北京、上海、深圳、杭州等城市舉辦超過100+線下和100+線上沙龍、論壇及峰會,已邀請近1000位專家和學者參與分享,其公眾號 DataFunTalk 累計生產原創文章500+,百萬+閱讀,13萬+精準粉絲,
注:歡迎轉載,轉載請留言或私信,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/458545.html
標籤:其他