摘要:本文詳細介紹如何利用MATLAB實作手寫數字的識別,其中特征提取程序采用方向梯度直方圖(HOG)特征,分類程序采用性能優異的支持向量機(SVM)演算法,訓練測驗資料集為學術及工程上常用的MNIST手寫數字資料集,博主為SVM設定了合適的核函式,最終的測驗準確率達99%的較高水平,根據訓練得到的模型,利用MATLAB GUI工具設計了可以手寫輸入或讀取圖片進行識別的系統界面,同時可視化圖片處理程序及識別結果,本套代碼集成了眾多機器學習的基礎技術,適用性極強(用戶可修改圖片檔案夾實作自定義資料集訓練),相信會是一個非常好的學習Demo,本博文目錄如下:
目錄- 前言
- 1. 效果演示
- 2. MNIST資料集
- 3. HOG特征提取
- 3. 訓練和評估SVM分類器
- 下載鏈接
- 結束語
?點擊跳轉至文末所有涉及的完整代碼檔案下載頁?
完整資源下載鏈接:https://mianbaoduo.com/o/bread/YZeUkplu
代碼介紹及演示視頻鏈接:https://www.bilibili.com/video/BV1km4y1R7qf/(正在更新中,歡迎關注博主B站視頻)
前言
機器學習中支持向量機(SVM)演算法可謂是個超級經典,也許很多人傾向于使用深度神經網路解決問題,但在博主看來選擇何種演算法應該取決于具體的機器學習任務,對于復雜程度不高、資料量較少的任務,也許經典的機器學習演算法能夠更好地解決問題,手寫數字識別這一任務要求正確分類出0-9的手寫數字圖片,最常用的資料集是MNIST,該資料集也是眾多論文中經常用來測驗對比演算法的物件,博主想說的是其實SVM也可以很好地解決這一問題,本文介紹的代碼就可以實作99%的測驗準確率,所以想借此為大家提供一個學習的Demo共同交流,
博主之前也曾寫過兩篇利用SVM進行分類的博文:基于支持向量機的影像分類(上篇)和基于支持向量機的影像分類(下篇:MATLAB實作),詳細介紹了特征提取的基本技術和支持向量機的原理,亦可供大家參考,本文給出了MATLAB實作的完整代碼供大家參考,有基礎的讀者可按照文中的介紹復現出完整程式;對于想獲取全部資料集及程式檔案的朋友,可以點擊提供的下載鏈接獲取可直接運行的代碼,原創不易,還請多多支持了,如本文對您有所幫助,敬請點贊、收藏、關注!
1. 效果演示
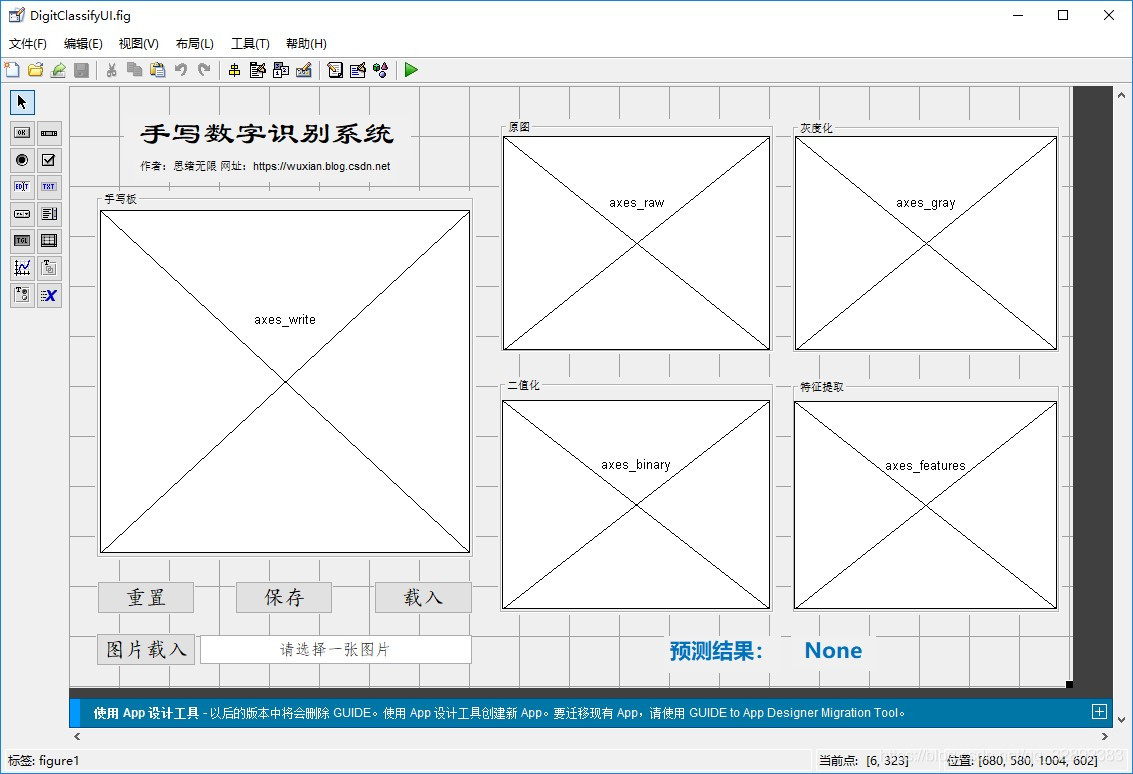
找資料的大伙時間寶貴,為了方便大家了解專案,我們老規矩先上效果演示,GUI界面有幾個主要功能:通過手寫板寫入數字進行識別;利用檔案瀏覽器選取一張手寫數字的圖片進行識別;同步可視化處理程序中的影像,顯示最終識別結果,GUI界面如下:
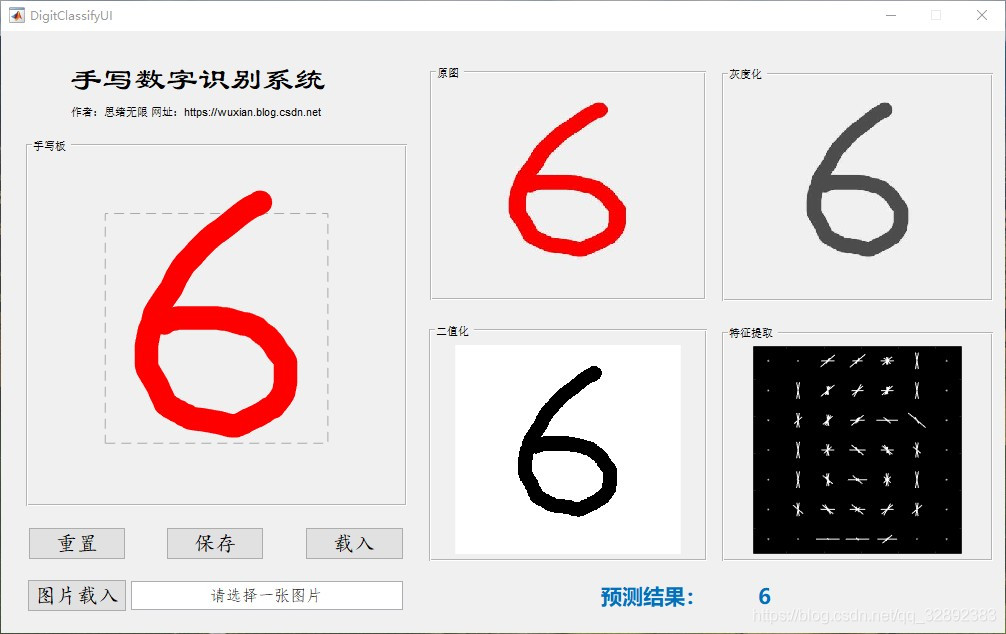
在手寫板中寫入數字后可點擊下方保存按鈕保存為圖片檔案,手寫輸入及讀圖輸入及保存功能的演示動圖如下圖所示,右側為影像原圖、灰度化處理、二值化處理及特征提取后的影像,方便了解識別的處理程序:
本專案所有功能均已在MATLAB R2020b中測驗通過,更多演示細節敬請前往博主B站觀看演示視頻,視頻具體演示程式運行效果并介紹如何使用代碼,歡迎關注!
2. MNIST資料集
MNIST資料集來自美國國家標準與技術研究所(National Institute of Standards and Technology, NIST),訓練集 (Training Set) 由來自250個不同人手寫的數字構成,其中50%是高中學生,50%來自人口普查局的作業人員;測驗集(Test Set) 也是同樣比例的手寫數字資料,
MNIST資料集可在 http://yann.lecun.com/exdb/mnist/獲取,但由于訪問外網下載速度很慢,博主已將該資料集打包上傳至百度網盤,大家可以通過博主前面發布的博文:深度學習常用資料集介紹與下載(附網盤鏈接)進行下載,MNIST資料集包含了四個部分:
- Training set images:train-images-idx3-ubyte.gz (9.9MB,解壓后47MB,包含60000個樣本)
- Training set labels:train-labels-idx1-ubyte.gz(29KB,解壓后60KB,包含60000個標簽)
- Test set images:t10k-images-idx3-ubyte.gz (1.6MB,解壓后7.8MB,包含10000個樣本)
- Test set labels: t10k-labels-idx1-ubyte.gz(5KB,解壓后10KB,包含10000個標簽)
將下載后的資料集檔案放在一個檔案夾下,用于后續處理,MNIST資料集檔案如下圖所示:
由于MNIST的原始檔案并非常見的圖片格式,因此為了方便后續處理,我們先將這幾個檔案轉化為mat檔案,然后逐個讀取轉換為影像矩陣并保存為圖片檔案,值得注意的是,我們需按照每條樣本資料的標簽將其分別放置在不同的檔案夾中,如下方式在train檔案夾中創建0-9的檔案夾用來存放要寫入的對應標簽的圖片:
這里寫一個小腳本將資料集圖片按標簽存入對應檔案夾中,其中的mat檔案為讀取原始資料并轉存后的資料集,MNIST每張圖片的尺寸均為28×28,所以可以先通過reshape恢復資料尺寸,然后利用imwrite函式寫入檔案中(路徑為對應標簽的子檔案夾),該部分代碼如下:
clear
clc
% P = loadMNISTImages('mnist/train-images.idx3-ubyte');
% T = loadMNISTLabels('mnist/train-labels.idx1-ubyte');
load('test_data.mat', 'test_X')
load('test_label.mat', 'test_Y')
load('train_data.mat', 'train_X')
load('train_label.mat', 'train_Y')
load('validation_data.mat', 'validation_X')
load('validation_label.mat', 'validation_Y')
% 遍歷每張圖片
disp('現在將訓練資料保存為圖片檔案格式')
for i = 1:length(train_X)
img = reshape(train_X(i, :), 28, 28); % 轉換成28*28的圖片
img = img';
imwrite(img, ['./mnist/train/', int2str(train_Y(i)), '/', int2str(i), '.jpg']);
disp(i);
end
% 遍歷每張圖片
disp('現在將測驗資料保存為圖片檔案格式')
for i = 1:length(test_X)
img = reshape(test_X(i, :), 28, 28); % 轉換成28*28的圖片
img = img';
imwrite(img, ['./mnist/test/', int2str(test_Y(i)), '/', int2str(i), '.jpg']);
disp(i);
end
處理后的子檔案夾中將存放對應的圖片檔案,其中兩個子檔案夾的截圖如下圖所示:
資料集準備完畢,現在可以通過檔案夾讀取圖片了,在MATLAB中可使用imageDatastore函式方便地批量讀取圖片集,它通過遞回掃描檔案夾目錄,將每個檔案夾名稱自動作為影像的標簽,該部分代碼如下:
% 給出訓練和測驗資料路徑,利用imageDatastore載入資料集
syntheticDir = fullfile('data','mnist', 'train');
handwrittenDir = fullfile('data','mnist', 'test');
% imageDatastore遞回掃描目錄,將每個檔案夾名稱自動作為影像的標簽
trainSet = imageDatastore(syntheticDir, 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
testSet = imageDatastore(handwrittenDir, 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
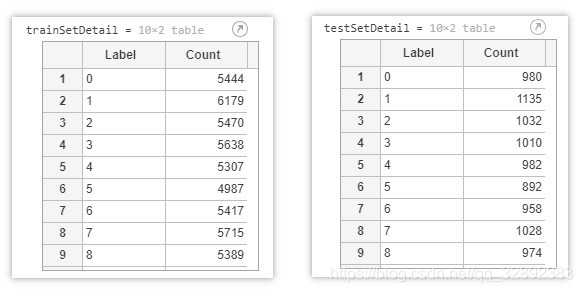
至此訓練和測驗資料集分別被存放在trainSet、testSet變數中,可以簡單查看訓練和測驗集每類標簽的樣本個數,顯示代碼如下:
trainSetDetail = countEachLabel(trainSet) % 訓練資料
testSetDetail = countEachLabel(testSet) % 測驗資料
執行以上代碼運行結果如下:
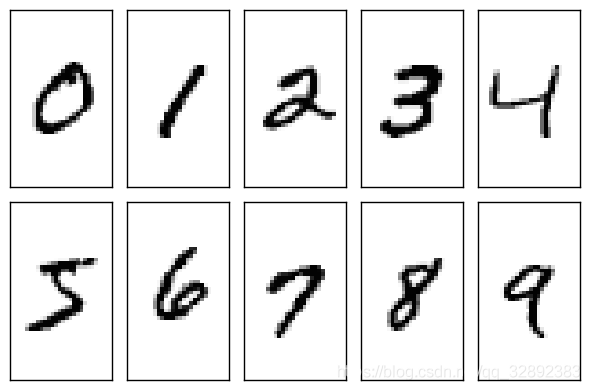
下面讀取幾張訓練和測驗集的圖片,顯示原始圖片幫助我們清楚該資料集的實際情況,按照兩行顯示:第一行為訓練圖片,第二行為測驗圖片,該部分代碼如下:
figure;
% 顯示訓練、測驗圖片(第一行是訓練圖片、第二行是測驗圖片)
subplot(2,5,1);imshow(trainSet.Files{4417});
subplot(2,5,2);imshow(trainSet.Files{23696});
subplot(2,5,3);imshow(trainSet.Files{31739});
subplot(2,5,4);imshow(trainSet.Files{46740});
subplot(2,5,5);imshow(trainSet.Files{54784});
subplot(2,5,6);imshow(testSet.Files{53});
subplot(2,5,7);imshow(testSet.Files{4572});
subplot(2,5,8);imshow(testSet.Files{5163});
subplot(2,5,9);imshow(testSet.Files{8381});
subplot(2,5,10);imshow(testSet.Files{9549});
執行該代碼可以看到如下的運行結果:

在提取特征前我們對圖片進行一些必要的預處理操作,首先讀取圖片后進行灰度化,然后進行二值化處理,以方便后續的特征提取,這里我們將原始圖片和二值化后的影像顯示在一個視窗中,其代碼如下:
exampleImage = readimage(trainSet, 31739);
if numel(size(exampleImage))==3
exampleImage = rgb2gray(exampleImage); % 灰度化圖片
end
processedImage = imbinarize(exampleImage);
figure;
subplot(1,2,1)
imshow(exampleImage)
title('原始影像')
subplot(1,2,2)
imshow(processedImage)
title('二值化后影像')
執行該代碼可以看到如下的原始影像與二值化后的對比結果:

3. HOG特征提取
真正用于訓練分類器的資料并不是原始圖片資料,而是先經過特征提取后得到的特征向量,這里使用的特征型別是HOG,也就是方向梯度直方圖,所以這里重要的一點是正確提取出HOG特征,extractHOGFeatures是MATLAB自帶的HOG特征提取函式,該函式不僅可以有效提取特征,還可以回傳特征的可視化結果以方便展示,這里通過調整每個細胞單元的尺寸大小實作不同尺寸的特征提取,可以通過可視化的結果看到細胞單元的尺寸對影像的形狀資訊量的影響:
img = readimage(trainSet, 31739);
% 提取HOG特征,并進行HOG可視化
[hog_2x2, vis2x2] = extractHOGFeatures(img,'CellSize',[2 2]);
[hog_4x4, vis4x4] = extractHOGFeatures(img,'CellSize',[4 4]);
[hog_8x8, vis8x8] = extractHOGFeatures(img,'CellSize',[8 8]);
% 顯示原始圖片
figure;
subplot(2,3,1:3); imshow(img);
title('原始圖片');
% 可視化HOG特征
subplot(2,3,4);
plot(vis2x2);
title({'CellSize = [2 2]'; ['Length = ' num2str(length(hog_2x2))]});
subplot(2,3,5);
plot(vis4x4);
title({'CellSize = [4 4]'; ['Length = ' num2str(length(hog_4x4))]});
subplot(2,3,6);
plot(vis8x8);
title({'CellSize = [8 8]'; ['Length = ' num2str(length(hog_8x8))]});
通過以上代碼我們分別提取了2×2、4×4、8×8三種尺寸的HOG特征,其運行的可視化結果如下:

從以上結果可以看出2×2的細胞尺寸會編碼更多的形狀資訊,這會顯著增加HOG特征向量的維數,相反8×8的細胞尺寸得到的特征量最少,這其實是一個需要除錯的引數,一方面應該對足夠的空間資訊進行編碼,另一方面需要減少HOG特征向量的維數,為此可以選擇4×4的細胞大小,當然讀者還可以通過反復根據分類器訓練和測驗的效果來調整HOG特征的相關引數,以實作最佳引數設定,
3. 訓練和評估SVM分類器
下面我們使用以上提取的HOG特征訓練支持向量機,以上的代碼只是提取了一張圖片的特征,訓練前我們對整個訓練資料集提取HOG特征并組合,為了方便后面的性能評估,這里對測驗資料集也進行特征提取:
cellSize = [4 4];
hogFeatureSize = length(hog_4x4);
% 提取HOG特征
tStart = tic;
[trainFeatures, trainLabels] = extractHogFromImageSet(trainSet, hogFeatureSize, cellSize); % 訓練集特征提取
[testFeatures, testLabels] = extractHogFromImageSet(testSet, hogFeatureSize, cellSize); % 測驗集特征提取
tEnd = toc(tStart);
fprintf('提取特征所用時間:%.2f秒\n', tEnd);
由于圖片數量眾多,提取特征程序尚需一定時間,這里對訓練集、測驗集提取程序進行計時,因計算機算力不同,執行時間可能會不一致,以下代碼中extractHogFromImageSet函式為自定義函式,封裝了前面所提到的影像灰度化、二值化和HOG特征提取的代碼,可以方便我們復用代碼,使得程式更加簡潔,
cellSize = [4 4];
hogFeatureSize = length(hog_4x4);
% 提取HOG特征
tStart = tic;
[trainFeatures, trainLabels] = extractHogFromImageSet(trainSet, hogFeatureSize, cellSize); % 訓練集特征提取
[testFeatures, testLabels] = extractHogFromImageSet(testSet, hogFeatureSize, cellSize); % 測驗集特征提取
tEnd = toc(tStart);
fprintf('提取特征所用時間:%.2f秒\n', tEnd);
運行以上代碼結果如下:
提取特征所用時間:181.59秒
構建支持向量機模型,利用提取的訓練集特征進行訓練,首先利用templateSVM函式構建支持向量機模板引數,選擇polynomial核函式,執行標準化處理資料,顯示訓練程序;利用fitcecoc函式執行訓練程序,其代碼如下:
% 訓練支持向量機
t = templateSVM('SaveSupportVectors',true, 'Standardize', true, 'KernelFunction','polynomial', ...
'KernelScale', 'auto','Verbose', 1); % 利用polynomial核函式, 標準化處理資料,顯示訓練程序(verbose取0時取消顯示)
tStart = tic; % 計時開始
classifier = fitcecoc(trainFeatures, trainLabels, 'Learner', t); % 訓練SVM模型
tEnd = toc(tStart);
fprintf('訓練模型所用時間:%.2f秒\n', tEnd);
以上代碼開啟了訓練程序資訊顯示,訓練程序中顯示資訊如下:
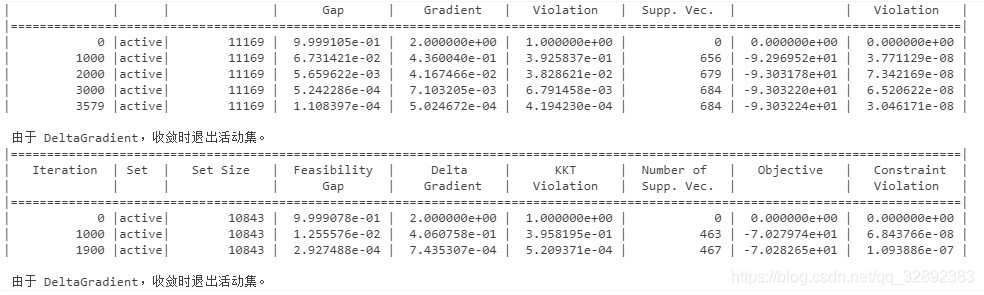
訓練模型所用時間:104.96秒
等待訓練完成,我們可以使用訓練好的分類器進行預測,這里先利用測驗集評估模型并計算分類評價指標,對測驗集進行預測的代碼如下:
tStart = tic;
% 對測驗資料集進行預測
predictedLabels = predict(classifier, testFeatures);
tEnd = toc(tStart);
fprintf('模型對測驗集進行預測所用時間:%.2f秒\n', tEnd);
運行結果如下:
模型對測驗集進行預測所用時間:5.18秒
得到了預測結果,可以使用混淆矩陣評估結果,以下代碼首先計算混淆矩陣結果,然后將結果列印出來:
% 使用混淆矩陣評估結果
confMat = confusionmat(testLabels, predictedLabels);
dispConfusionMatrix(confMat); % 顯示混淆矩陣
運行結果如下:
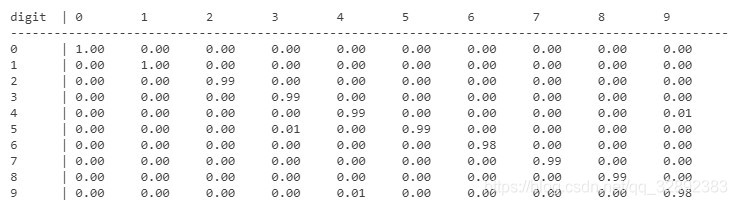
以上代碼顯示了混淆矩陣的結果,但可能還不夠直觀,下面繪制混淆矩陣圖幫助更好了解模型性能:
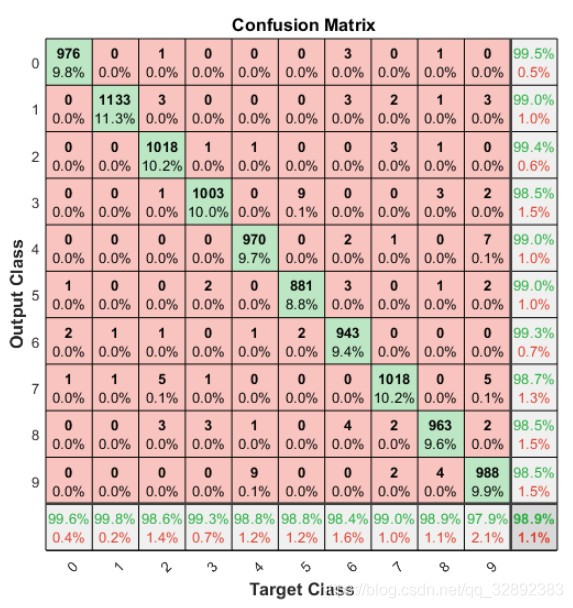
% 繪制混淆矩陣圖
plotconfusion(testLabels, predictedLabels);
運行代碼后顯示混淆矩陣圖如下圖所示,每行對角線上的網格(綠色網格)處顯示了某類樣本預測正確的數目及其占比,右下角網格表示分類的準確率,可以看出該分類器具有98.9%的總體分類準確率,
分類準確率還可以通過以下代碼進行計算:
accuracy = sum(predictedLabels == testLabels) / numel(testLabels);
fprintf('模型在測驗集上的準確率:%.0f%%\n', accuracy*100);
同樣可以計算出預測的準確率,這里四舍五入取整可得以下結果:
模型在測驗集上的準確率:99%
通過測驗集評估結果,可以看出采用核函式的支持向量機準確率為99%,其性能已逼近深度卷積神經網路,得到了一個性能優良的分類器,接下來便可以利用模型設計一些有意思的東西了,為此我將該模型用于實際的手寫數字識別中,以下是在MATLAB GUI工具中設計的界面,如若讀者反響熱烈,后期將很快更GUI的設計介紹,還請關注了!
下載鏈接
若您想獲得博文中涉及的實作完整全部程式檔案(包括資料集,m, UI檔案等,如下圖),這里已打包上傳至博主的面包多平臺和CSDN下載資源,本資源已上傳至面包多網站和CSDN下載資源頻道,可以點擊以下鏈接獲取,已將所有涉及的檔案同時打包到里面,點擊即可運行,完整檔案截圖如下:
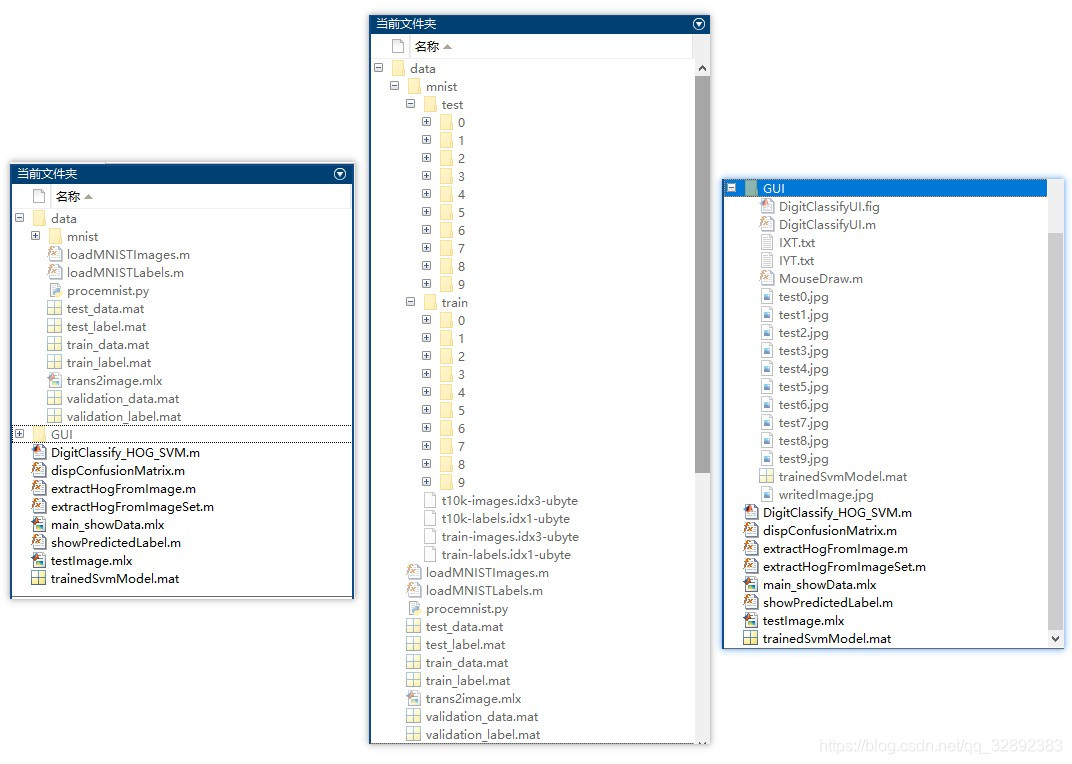
注意:本資源已經過除錯通過,下載后可通過MATLAB R2020b運行;訓練主程式為main_showData.mlx或DigitClassify_HOG_SVM.m檔案,測驗程式可運行testImage.mlx,要使用GUI界面請運行DigitClassifyUI.m檔案(腳本檔案可直接運行);其它程式檔案大部分為函式而非可直接運行的腳本,使用時請勿直接點擊運行!???
完整資源下載鏈接1:博主在面包多網站上的完整資源下載頁
完整資源下載鏈接2:https://mianbaoduo.com/o/bread/YZeUkplu
注:以上兩個鏈接為面包多平臺下載鏈接,CSDN下載資源頻道下載鏈接稍后上傳,
代碼使用介紹及演示視頻鏈接:https://space.bilibili.com/456667721/(尚在更新中,歡迎關注博主B站視頻)
結束語
由于博主能力有限,博文中提及的方法即使經過試驗,也難免會有疏漏之處,希望您能熱心指出其中的錯誤,以便下次修改時能以一個更完美更嚴謹的樣子,呈現在大家面前,同時如果有更好的實作方法也請您不吝賜教,如果本博文反響較好,其界面部分也將在下篇博文中介紹,所有涉及的GUI界面程式也會作細致講解,敬請期待!
用心整理知識,只出精品博文轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/458663.html
標籤:其他
上一篇:redis資料結構
下一篇:創建鏈表并且遍歷鏈表