一、各自背景
1. ASCII
ASCII 只有127個字符,表示英文字母的大小寫、數字和一些符號,但由于其他語言用ASCII編碼表示位元組不夠,例如:常用中文需要兩個位元組,且不能和ASCII沖突,中國定制了GB2312編碼格式,相同的,其他國家的語言也有屬于自己的編碼格式,這導致了在多語言混合的文本中,顯示出來會有亂碼,
2. Unicode
由于每個國家的語言都有屬于自己的編碼格式,在多語言編輯文本中會出現亂碼,這樣Unicode應運而生,Unicode就是將這些語言統一到一套編碼格式中,Unicode通常兩個位元組表示一個字符,而ASCII是一個位元組表示一個字符,這樣如果你編譯的文本是全英文的,用Unicode編碼比ASCII編碼需要多一倍的存盤空間,在存盤和傳輸上就十分不劃算,
3. Utf-8
為了解決上述問題,又出現了把Unicode編碼轉化為“可變長編碼”UTF-8編碼,UTF-8編碼將Unicode字符按數字大小編碼為1-6個位元組,英文字母被編碼成一個位元組,常用漢字被編碼成三個位元組,如果你編譯的文本是純英文的,那么用UTF-8就會非常節省空間,并且ASCII碼也是UTF-8的一部分,
二、三者關系
搞清楚了ASCII、Unicode和UTF-8的背景,我們就可以總結一下現在計算機系統通用的字符編碼作業方式:
(1) 在計算機記憶體中,統一使用Unicode編碼,當需要保存到硬碟或者需要傳輸的時候,就轉換為UTF-8編碼,
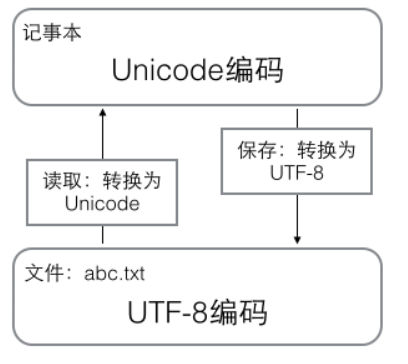
(2) 用記事本編輯的時候,從檔案讀取的UTF-8字符被轉換為Unicode字符到記憶體里,編輯完成后,保存的時候再把Unicode轉換為UTF-8保存到檔案,
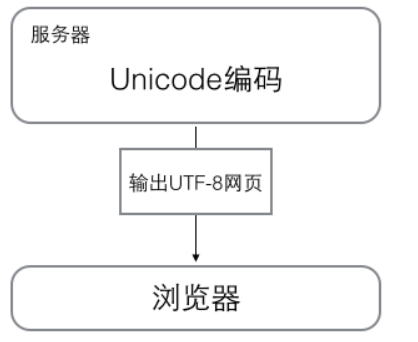
(3)瀏覽網頁的時候,服務器會把動態生成的Unicode內容轉換為UTF-8再傳輸到瀏覽器:
三、總結
utf-8變長編碼意味著要判定長度時需要計算,在編輯時用會耗費額外的計算成本,為了提高運行速度可以使用Unicode,而存盤為了節省空間,使用utf-8. 也就是說編輯時用Unicode減少判定時間,保存時用utf-8節省存盤空間,
作者:陳景中出處:https://www.cnblogs.com/blog-cjz/-------------------------------------------如果覺得這篇文章對你有小小的幫助的話,可以在右下角點個“推薦”,分享給其他人轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/458675.html
標籤:其他
上一篇:k8s入門之pod(四)