
導讀:為什么要使用機器來理解音頻內容呢?一個重要的出發點就是在大量資料存在的情況下,由人來完成音頻內容的理解是一件較為困難的事情,在圖片和文本處理方面,快速理解尚有一定實作的可能,古代有一個形容人記憶力很好的成語叫做走馬觀碑,描述一個人騎著快馬路過一個石碑,看到石碑上密密麻麻的小字一瞬間就能夠全部記下來,但是對于音頻與視頻這種內容,即使在加速的情況下也需要一定的時間來聽完、看完音頻和視頻內容才能夠進一步理解它,如果采取人力處理這些問題會遇到困難,我們就可以借助于機器輔助人來進行處理,
機器在理解音頻的程序中需要理解哪些內容呢?就需要我們來分析場景問題,
--

01 內容安全
在18年的時候,紅極一時的一名主播因為在直播程序中發表一些不當的言論而遭到封殺,同樣的案例還有因主播在直播程序中發表涉政相關的言論而被封殺,今年是建國70周年,很多境外的反動組織為了擴散他們的言論在某些直播平臺或者社交平臺散播宣傳音頻或者視頻,他們通常用錄音機等播放設備將提前錄制好的音頻和視頻連續不斷地進行播放,這是一個典型的社交問題,
此外,直播中還存在較多的色情問題,包括視頻、影像方面的色情,也包括音頻方面的色情,有時也會有廣告導流行為,所謂廣告導流就是在某一個直播平臺上,大家在音視頻交流程序中有人發類似于我們私下加個微信聊吧,這樣這個平臺的流量就會被導走,我們的作業就是要在音頻中識別出這些行為,為這些行為打上標簽,讓運營平臺知道這些音頻中存在這樣或者那樣的問題,以上所分析的問題完全屬于截流問題,
02 內容運營
內容理解的優勢在于可以進行內容推薦,一個典型的例子就是在交友的社交平臺上,如果通過聲音識別出是一位大叔,就可以給他推薦一位蘿莉,如果聲音識別是一位御姐,就可以推薦給她一個正太,這樣就有希望延長他們之間的交流時間,
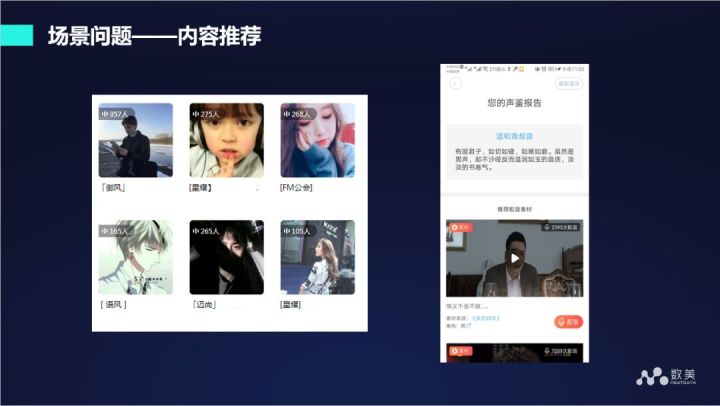
內容理解核心的解釋就是將非結構化的內容結構化,其中重要的途徑是標簽,通過各種手段為音頻或者視頻打上各種標簽,方便后面去做各種處理,比如攔截和推薦,
--
03 解決方案
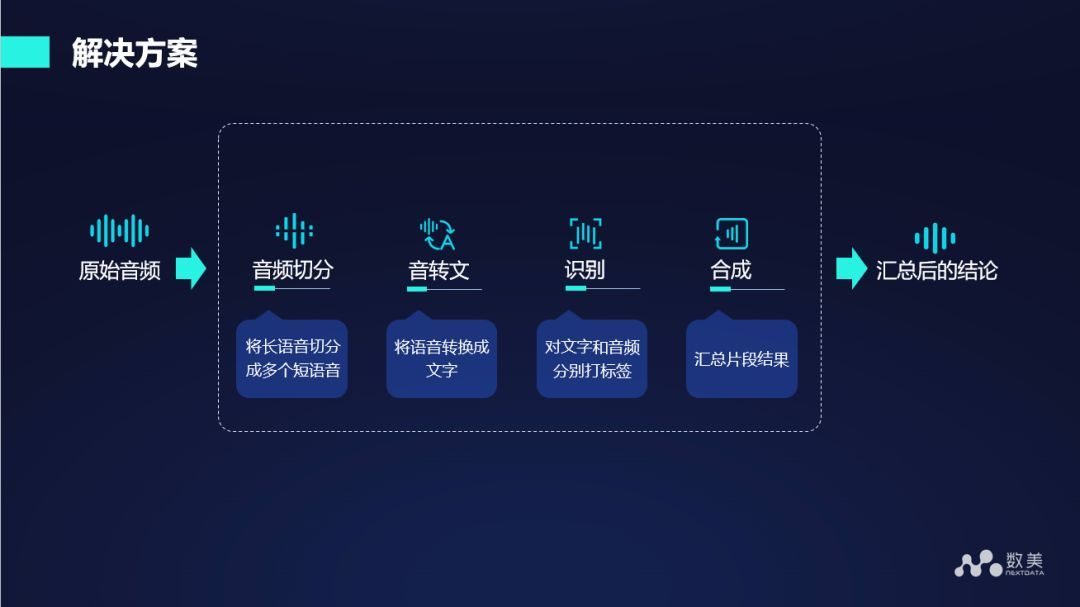
對于上述問題,我們的解決方案主要包括四個步驟:
- 音頻切分:在得到原始音頻之后首先對音頻進行切分,將長語音切分為多個短語音
- 音轉文:將語音轉換成文字
- 識別:對文字和音頻分別打標簽
- 合成:匯總片段結果,并給出最終的整條陳述句或者整個視頻,
內容理解的程序中存在一定的困難,比如遠場識別,對于直播來說識別程序中最大的困難是混響和噪聲,主播在直播程序中為了吸引更多的人觀看通常會唱歌,唱歌一般都會加混響來使歌聲聽起來有繞梁三日的感覺,但是這種情況就會對語音識別產生較大的影響,此外,我們在使用語音搜索和語音輸入法的程序中為了獲得更加正確的結果會故意放慢說話速度,表達相對更加清晰,而直播程序中為了獲得良好的互動,說話都會比較隨意,唱歌也是一個比較難解決的問題,在語音識別建模的程序中,很多情況下都是使用帶音調的音素來進行建模,但是在唱歌的程序中語音的聲調會發生變化,這樣也會引起識別不準確的問題,目前已經有很多有效的方法來解決這些問題,

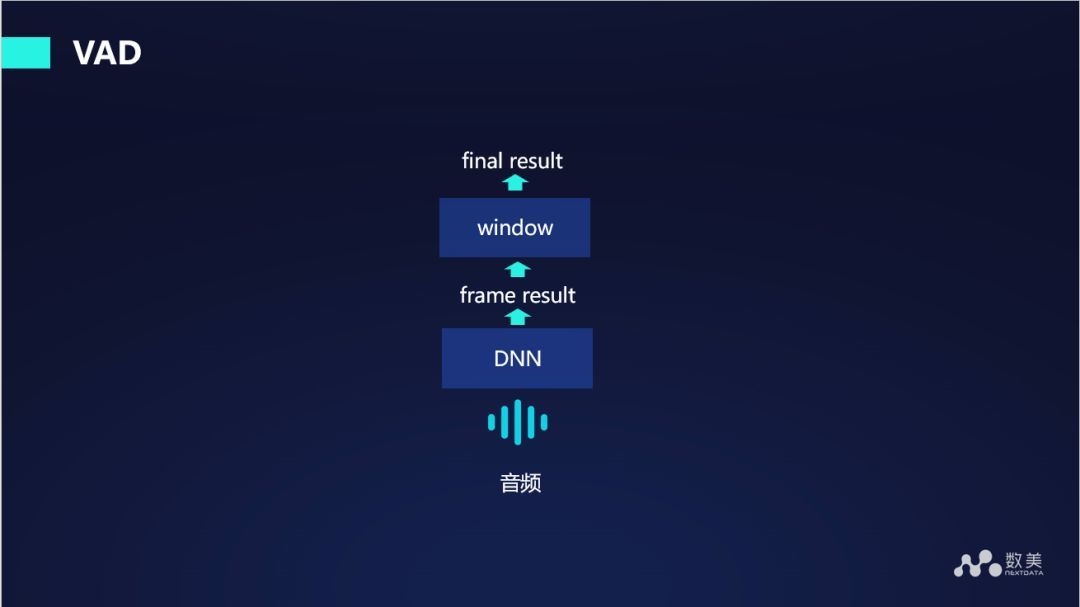
下面介紹下解決上述問題的相關作業,首先是音頻切割(VAD),這種技術是比較主流的一種方法,先通過深度學習 DNN 來預測出一段音頻是靜音還是非靜音,然后通過加窗得到最終的結果,
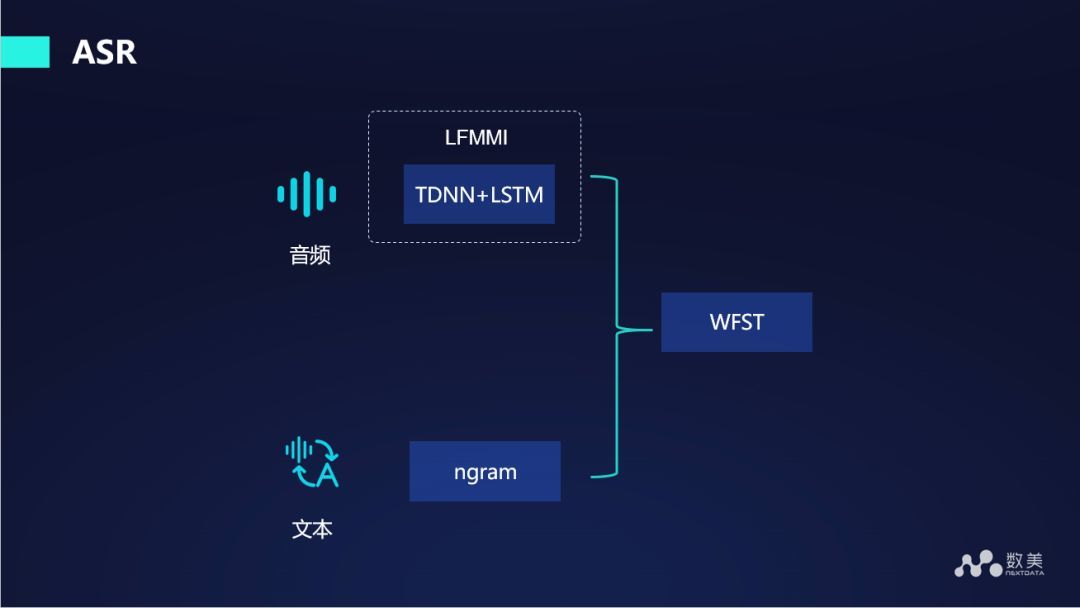
在語音轉寫文字的程序中,采用 DNN+LSTM,然后使用 lattice-free MMI 方法訓練現有模型,我們使用的語言模型是 ngram 方式,這是一個相對比較主流的框架,目前 ASR 主要解決的是把音頻中的文字提取出來,
前面我們提到還有一部分語音識別不能通過轉文字獲得,比如是否有音樂,播放音樂的名稱,是否存在色情聲音等等,我們采用聲音分類的框架來解決這個問題,首先需要對音頻進行資料增強,因為在音頻分類條件下資料的 label 并不均衡,特別是存在一些小眾的聲音,非常稀少,所以需要對這些資料進行增強,我們使用 TDNN+bi-GRU+Attention 框架,

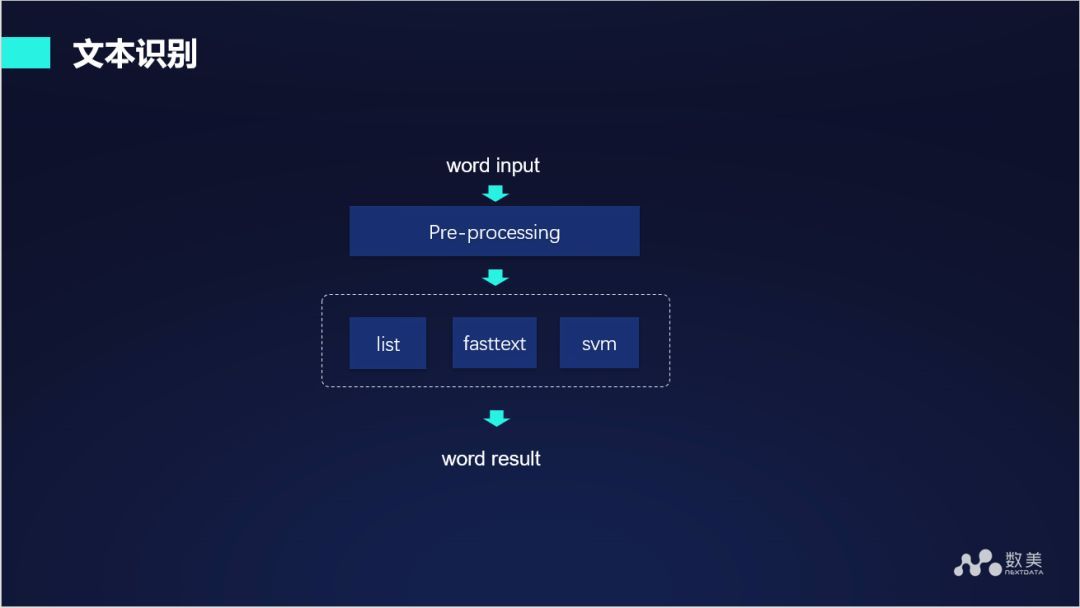
上述第一步將音頻轉換成文字,第二步將分類資訊標簽集,第三步需要對轉換出來的文字進行文字識別,文字識別主要包括文字的分類:基于一段文字判斷它所屬的類別,比如這段文字是不是屬于色情話題或者是帶有辱罵性等,模型不能完全解決這方面的問題,還需要有關鍵詞類比,我們給出的框架通過 fasttext 模型或者一些傳統的機器學習演算法來進行模型分類,同時聯合關鍵詞資訊進行處理,在使用模型訓練之前首先對文本進行預處理,比如分詞、歸一化等,
最后一步是行為識別,例如境外反動組織要去散播反動言論會在平臺上開很多賬號,對于每個賬號不會雇傭不同的人去宣傳言論,而是使用錄制好的音頻來播放相同的言論內容,這樣他的行為就會有一定的聚集性,在這種設備或者 IP 上的具體行為可以通過一個邏輯回歸模型來打分,通過分數判斷這個行為是不是存在問題,行為識別也可以檢測出一些有問題的內容,

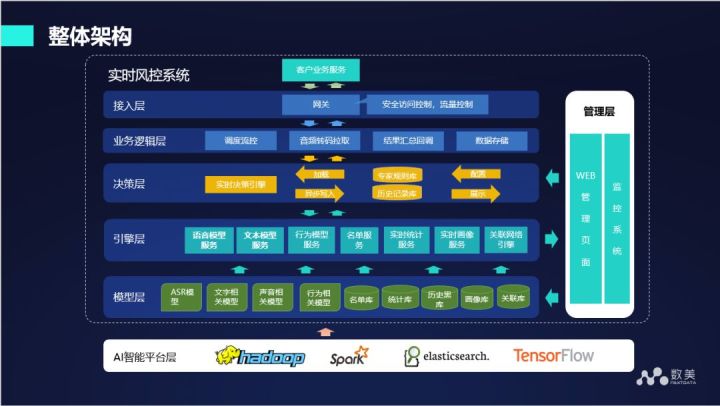
下圖是我們整個框架的架構圖,將上述我們分析的各個模塊整合在一起,在模型層面包括 ASR 模型、文字相關模型、聲音相關模型、行為相關模型、名單庫等,通過引擎層輸出各種各樣的分數,最后我們有一套規則,規則引擎會對所有模型層面和畫像層面輸出的結果進行匯總,最終得到結論,
下面是我們真實的一個價值體現,某直播平臺同時采用用戶舉報、人工抽審、數美智能審核三種方案監測平臺直播內容,用戶舉報平均每天抓出1個違規音頻,人工抽審平均每天抓出20個違規音頻(審核團隊30人),數美智能審核系統平均每天抓出160個違規音頻,同時數美智能審核系統反饋音頻轉文字結果、自動記錄違規音頻位置、發生時間等資訊,

今天的分享就到這里,謝謝大家,
本文首發于微信公眾號“DataFunTalk”
注:歡迎轉載,轉載請留言或私信,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/459553.html
標籤:其他
下一篇:力扣77. 組合