2.8版本以前
同步(snyc)
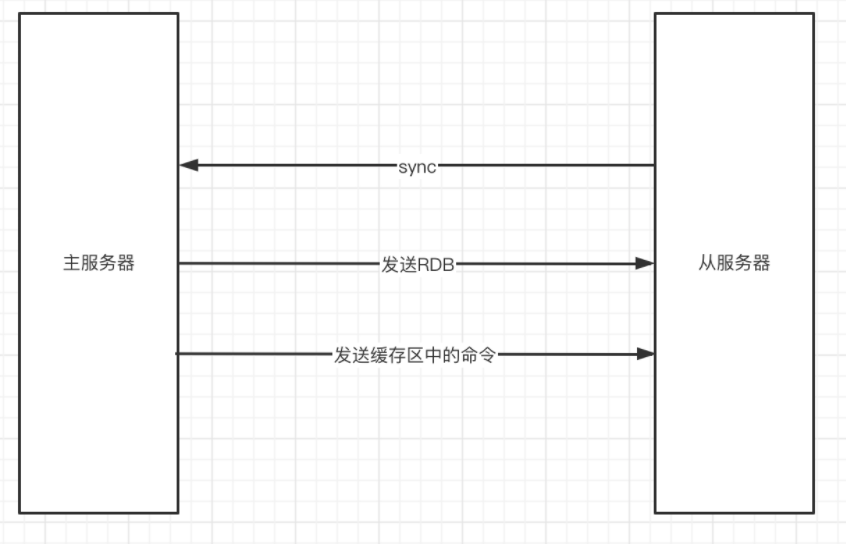
執行步驟:
- 從服務器發送
snyc給主服務器 - 主服務器收到命令后,開始執行
bgsave操作,將生成RDB檔案,將生成的RDB檔案同步給從服務,并使用一個緩沖區記錄從現在開始的寫命令 - 從服務載入接受到的RDB檔案,期間不可進行其他操作,
- 主服務將緩沖區里的命令同步給從服務器
傳播
同步完成之后,后續的命令都是通過傳播的方式發送給從服務器的,即當主服務執行完一條命令后,將該命令發送給從服務,完成資料的同步,
缺陷
場景:
- 首次復制,不存在問題,畢竟新連接上一個master服務器,則需要復制其全量的資料
- 斷開后重連復制,這是,仍是需要通過
sync進行全量的復制,這就是很耗費資源的,畢竟如果斷開時間短,如中間網路抖動,導致中間短暫性斷開,再次復制全量資料,成本太高,
關于sync命令:
- 主服務器需要執行
bgsave命令來生成RDB檔案,這個操作會耗費主服務器的大量CPU、記憶體和磁盤IO資源, - 主服務器將RDB檔案發送給從服務器,會消耗雙方的網路資源(帶寬和流量),
- 接受到RDB檔案后,從服務器需要載入RDB檔案,這個載入期間,從服務器因為阻塞而沒有辦法處理命令請求,
2.8版本以后
psnyc具備完整重同步(full resynchronization)和部分重同步(partial resynchronization),
其中,完整重同步和sync的首次同步是一致的,通過主服務器生成RDB檔案進行全量資料的同步,如果存在多個從服務器,主服務器僅會生成一份RDB檔案,分別同步給各個從服務器,部分重同步則解決了sync斷開重連的問題,當斷開重連后,主服務器在條件允許的前提下,僅會發送斷開期間的寫命令,部分重同步的主要實作由以下三部分組成:
- 主服務器的復制偏移量(replication offset)和從服務器的復制偏移量
- 主服務器的復制積壓緩沖區(replication backlogs)
- 服務器的運行ID(run ID)
復制偏移量
主服務器記錄的是自己發給從服務器的偏移量,從服務器記錄的是自己接受到的資料偏移量,比如:當前主從服務器的偏移量均為100,在有新的寫入命令后,主服務器的偏移量變成了110,而從服務器的是100,此時會有短暫的不一致,待主服務器將新寫入命令同步給從服務器后,從服務器的偏移量會變更為110,此時主從服務器又是保持一致的資料了,
復制積壓緩沖區
一個固定長度的先進先出佇列,默認1M,可通過配置repl_backlog_size調整其大小,當收到一條寫入命令,除了發給從服務器外,還會將命令寫入到復制積壓緩沖區一份,
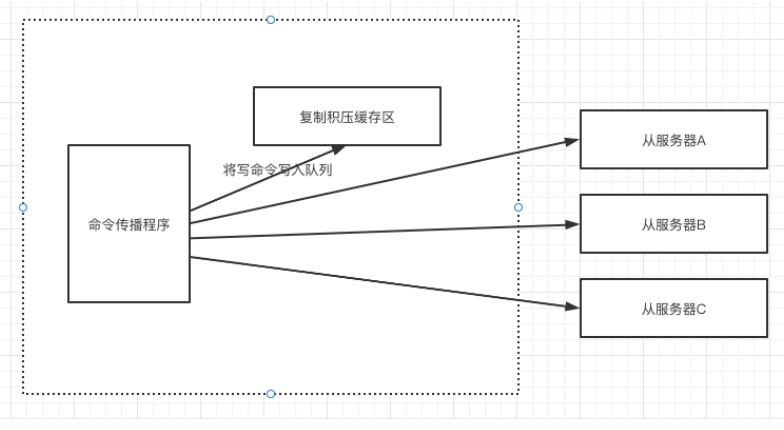
當從服務器A與主服務器斷開后,中間的寫入命令會無法同步給從服務器A,之后,重連后,從服務器會將其復制偏移量告知主服務器,如果該偏移量還在復制積壓緩沖區中,則直接將復制積壓緩沖區該偏移量后的命令發送給從服務器,
服務器的運行ID
每個redis實體在啟動時候,都會隨機生成一個長度為40的唯一字串來標識當前運行的redis節點,當從服務器對主服務器進行首次復制時,則將自己的runID發送給從服務器,從服務器會將這個ID保存起來,當從服務器與主服務器斷開后重連時,會向主服務器發送當前存盤的runID,主服務器收到后,會判斷與當前自己的runID是否一致,如果不一致,則進行全量復制;如果一致,則判斷復制偏移量是否還在復制積壓緩沖區中,如果還在,則進行部分重同步,
psync命令
psync <runId> <offset>
首次發送時為psync ? -1,之后發送的為上次master的runID和當前的復制偏移量,
缺陷
由于每次實體重啟都會重新生成runID,或者發生故障遷移后,新Master的runId必然與上一次的不一致,仍會導致完整重同步,
4.0版本以后的優化
解決了psnyc的缺陷,簡稱:psync2
第一種情況:redis重啟
第一步,在redis關閉時,通過shutdown save,都會呼叫rdbSaveInfoAuxFields函式,把當前實體的repl-id和repl-offset保存到RDB檔案中,
第二步,重啟后加載RDB檔案中的復制資訊,把其中repl_id和repl_offset加載到實體中,分別賦給master_replid和master_repl_offset兩個變數值,
當從庫開啟了AOF持久化,redis加載順序發生變化優先加載AOF檔案,但是由于aof檔案中沒有復制資訊,所以導致重啟后從實體依舊使用全量復制!
第三步:向主庫上報復制資訊,判斷是否進行部分同步,
- 從實體向主庫上報master_replid與主實體的master_replid1或replid2有一個相等,用于判斷主從未發生改變;
- 從實體上報的master_repl_offset+1位元組,還存在于主實體的復制積壓緩沖區中,用于判斷從庫丟失部分是否在復制緩沖區中;
第二種情況: 故障切換
redis從庫默認開始復制積壓緩沖區,方便從庫切換為主庫,其他從庫可以直接從master節點獲取缺失的命令,通過兩組replId實作,
第一組:master_replid和master_repl_offset:如果redis是主實體,則表示為自己的replid和復制偏移量; 如果redis是從實體,則表示為自己主實體的replid1和同步主實體的復制偏移量,
第二組:master_replid2和second_repl_offset:無論主從,都表示自己上次主實體repid1和復制偏移量;用于兄弟實體或級聯復制,主庫故障切換psync,
判斷是否使用部分復制條件:如果從庫提供的master_replid與master的replid不同,且與master的replid2不同,或同步速度快于master; 就必須進行全量復制,否則執行部分復制,
公眾號:慢行的蝸牛
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/462926.html
標籤:其他
下一篇:JVM的類加載程序