我現在想把CSDN我的博客下面的頁碼爬出來,出了點問題,求解,多謝了。
import requests
from lxml import etree
HEADERS={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'
}
URL='https://blog.csdn.net/weixin_45949073/article/list/'
#response = requests.get(url=URL,headers=HEADERS).text
response = requests.get(url=URL,headers=HEADERS).content.decode('utf-8')
html = etree.HTML(response)
detail_ur = html.xpath("//div[@class='pagination-box']//div[@class='ui-paging-container']//ul//li/@data-page")#明明是可以提取出來的,如下圖,但是輸出確實空串列
print(detail_ur)
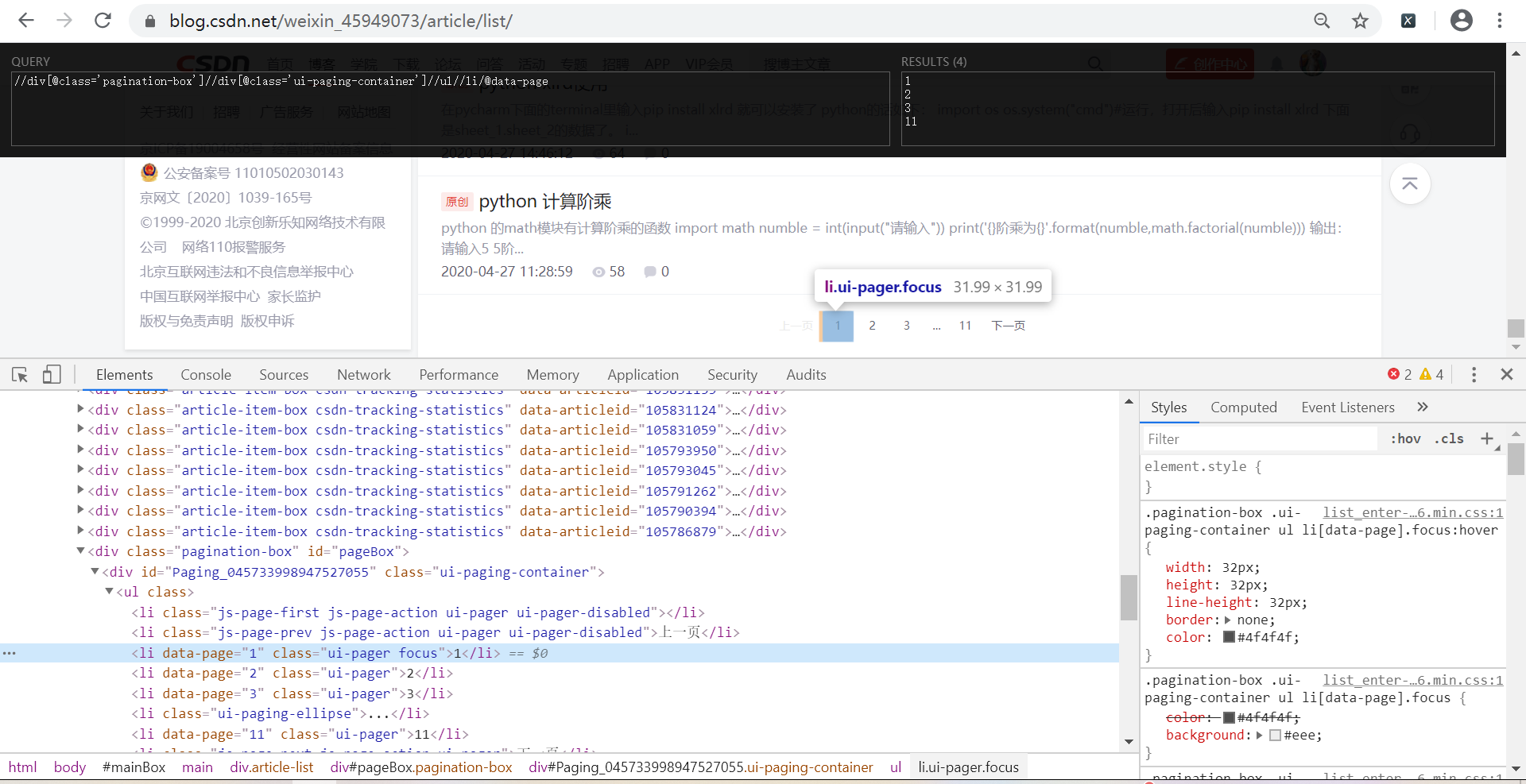
uj5u.com熱心網友回復:
如圖所示//div[@class='pagination-box']//div[@class='ui-paging-container']//ul//li/@data-page")放在XPath插件中是可以檢索出來的,但是代碼卻什么都沒輸出,唉,好蒙啊。uj5u.com熱心網友回復:
這個頁碼應該是動態加載出來的吧!根本不在原始碼當中,你看一下源代碼就知道
uj5u.com熱心網友回復:
OK,謝謝大哥。轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/46685.html