我正在使用用 Python 開發的 FEM 軟體 (Code_Aster),但它的檔案擴展名為.comm. 但是,可以將 Python 片段插入.comm檔案中。
我有一個函式,它以下面的形式回傳一個很長string的包含nodes, elements, elements group, 等等:
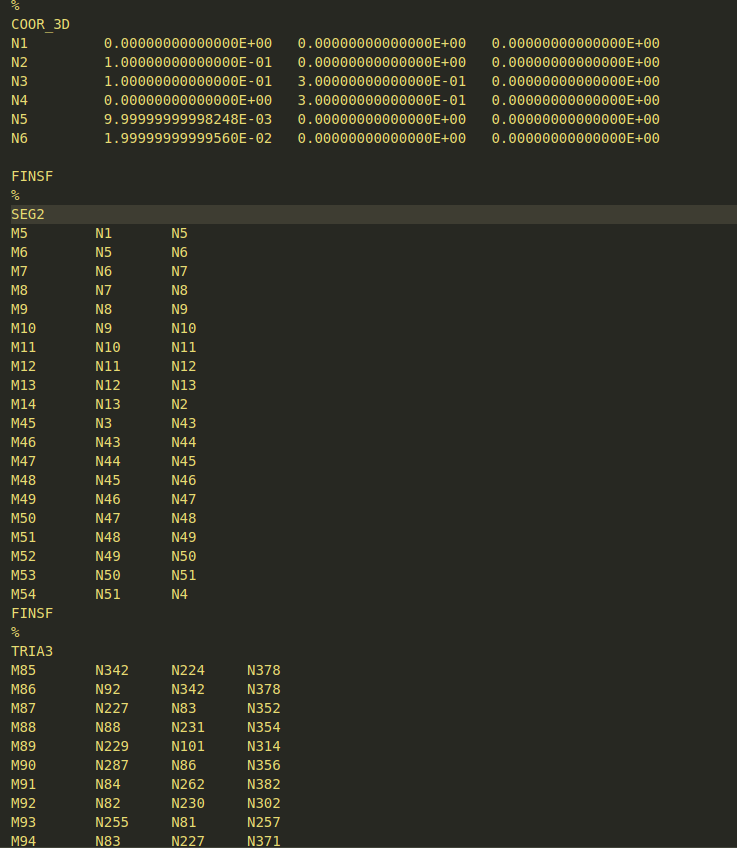
我的目標是將每一行及其關聯坐標或節點添加到串列/字典中。例如:
dct_nodes = {
'N5': [
9.99999999998248E-03,
0.00000000000000E 00,
0.00000000000000E 00
]
}
dct_elems = {
'M5': ['N1', 'N5'],
'M85': ['N342', 'N224', 'N378']
}
我用,嘗試了正則運算式re.split,但我似乎無法得到我需要的東西。這是我到目前為止所做的。re.searchre.findall
node_list = list()
for item in ttt.split("\n"):
if len(item) != 0: # there are some lines with zero len
if item[0] == 'N':
node_list.append(re.sub("\s ", ",", item.strip()))
Returns ,而我想要一個嵌套串列,所以我可以抓取type(node_list[0])并進行資料操作。如何拆分此字串,以便可以訪問例如坐標。我希望任何人都可以提供幫助。stringnode_list[0][0]node_list[0][1],
uj5u.com熱心網友回復:
如果沒有以Nor開頭的其他行M,則以下腳本可以完美地完成這項作業。
import re
ttt="""
%
COOR_3D
N1 0 0 0
N2 1 5 9
N3 2 6 10
N4 3 7 11
N5 4 8 12
FINSF
%
SEG2
M1 N1 N2
M2 N3 N4
FINSF
%
TRIA3
M3 N5 N6 N7
M4 N8 N9 N11
M5 N12 N13 N14"""
def finder(var,string):
temp_dic = dict()
for item in string.split("\n"):
if len(item) != 0: # there are some lines with zero len
temp = re.sub("\s ", ",", item.strip()).split(',')
if item[0] == var:
temp_dic[temp[0]] = [e for e in temp[1:]]
return temp_dic
nodes = finder('N',ttt)
elems = finder('M',ttt)
另請注意,如果您需要對節點的坐標進行算術操作,則必須將它們強制轉換為,float因為它們還string沒有。您可能可以使用三級運算子來決定是否e應該強制轉換為 afloat或保持 a string。我希望你覺得這個答案有用。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/467485.html