PyTorch快速入門
Tensors
Tensors貫穿PyTorch始終
和多維陣列很相似,一個特點是可以硬體加速
Tensors的初始化
有很多方式
-
直接給值
data = https://www.cnblogs.com/ghostcai/p/[[1,2],[3,4]] x_data = torch.tensor(data) -
從NumPy陣列轉來
np_arr = np.array(data) x_np = torch.from_numpy(np_array) -
從另一個Tensor
x_ones = torch.ones_like(x_data) -
賦01或隨機值
shape = (2,3,) rand_tensor = torch.rand(shape) ones_tensor = torch.ones(shape) zeros_tensor = torch.zeros(shape)
Tensors的屬性
tensor = torch.rand(3,4)
print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
print(f"Device tensor is stored on: {tensor.device}")
shape維度,dtype元素型別,device運行設備(cpu/gpu)
Tensors的操作
使用GPU的方法
if torch.cuda_is_available():
tensor = tensor.to("cuda")
各種操作
-
索引和切片
tensor = torch.ones(4,4) print(tensor[0]) #第一行(0開始) print(tensor[;,0]) #第一列(0開始) print(tensor[...,-1]) #最后一列 -
連接
t1 = torch.cat([tensor,tensor],dim=1) #沿著第一維的方向拼接 -
矩陣乘法
三種辦法,類似于運算子多載、成員函式和非成員函式
y1 = tensor @ tensor y2 = tensor.matmul(tensor.T) y3 = torch.rand_like(tensor) torch.matmul(tensor,tensor.T,out=y3) -
點乘
類似,也是三種辦法
z1 = tensor * tensor z2 = tensor.mul(tensor) z3 = torch.rand_like(tensor) torch.mul(tensor,tensor,out=z3) -
單元素tensor求值
agg = tensor.sum() agg_item = agg.item() print(agg_item,type(agg_item)) -
In-place 操作
就是會改變成員內容的成員函式,以下劃線結尾
tensor.add_(5) #每個元素都+5節約記憶體,但是會丟失計算前的值,不推薦使用,
和NumPy的聯系
-
Tensor轉NumPy陣列
t = torch.ones(5) n = t.numpy()注意,這個寫法類似參考,沒有新建記憶體,二者修改同步
-
NumPy陣列轉tensor
n = np.ones(5) t = torch.from_numpy(n)同樣是參考,一個的修改會對另一個有影響
資料集和資料加載器
處理資料的代碼通常很雜亂,難以維護,我們希望這部分代碼和主代碼分離,
加載資料集
以FasnionMNIST為例,我們需要四個引數
-
root是路徑
-
Train區分訓練集還是測驗集
-
download表示如果root找不到,就從網上下載
-
transform表明資料的轉換方式
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
training_data = https://www.cnblogs.com/ghostcai/p/datasets.FansionMNIST(
root ="data",
train = True,
download = True,
transform = ToTensor()
)
test_data = https://www.cnblogs.com/ghostcai/p/datasets.FansionMNIST(
root ="data",
train = False,
download = True,
transform = ToTensor()
)
標號和可視化
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item()
img, label = training_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
自己創建資料集類
必須實作三個函式__init__,__len__,__getitem__
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
__init__類似于建構式
__len__求資料個數
__getitem__按下標找資料和標簽,類似多載[]
用DataLoaders準備資料用于訓練
DataLoaders主要做3件事,將資料劃分為小batches,隨機打亂資料,和多核處理,
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data,batch_size = 64,shuffle=True)
test_dataloader = DataLoader(test_data,batch_size = 64,shuffle=True)
用DataLoader進行迭代訓練
# 展示影像和標簽
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
Transforms
讓資料變形成需要的形式
transform指定feature的變形
target_transform指定標簽的變形
比如,需要資料從PIL Image變成Tensors,標簽從整數變成one-hot encoded tensors
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
ds = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=https://www.cnblogs.com/ghostcai/p/1))
)
這里用了兩個技術,ToTensor()和Lambda運算式
ToTensor()將PIL images或者NumPy陣列轉化成FloatTensor,每個像素的灰度轉化到[0,1]范圍內
Lambda類似C++里的Lambda運算式,我們需要將整數轉化為 one-hot encoded tensor,就先創建一個長度為資料標簽型別的全0的Tensor,然后用scatter_()把第y個值改為1,注意到,scatter的index接受的引數也是Tensor,可見Tensor的廣泛使用,
神經網路
神經網路是一些層或者模塊,對資料進行處理,
torch.nn提供了諸多構造神經網路的模塊,模塊化的結構方便了管理復雜結構,
接下來以在FashionMNIST上構造一個影像分類器為例,
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
準備訓練設備
有GPU用GPU,沒有用CPU
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
定義網路的類
我們的網路從nn.Module繼承來
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
然后創建一個實體(物件),把它放到device上
model = NeuralNetwork().to(device)
print(model)
跑一下的結果
Using cpu device
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
結果是回傳值的softmax,這是個10維的概率,找最大的就是預測結果
X = torch.rand(1, 28, 28, device=device)
logits = model(X)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")
模型的layers
以3張28x28的影像為例,分析它在network里的狀態
input_image = torch.rand(3,28,28)
print(input_image.size())
'''
torch.Size([3,28,28])
'''
nn.Flatten
Flatten顧名思義,扁平化,用于將2維tensor轉為1維的
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flag_image.size())
'''
torch.Size([3,784])
'''
nn.Linear
Linear,做線性變換的
layer1 = nn.Linear(in_features=28*28,out_features=20)
hidden1 = layer1(flag_image)
print(hidden1.size())
'''
torch.Size([3,20])
'''
nn.ReLU
非線性激活函式,在Linear層后,增加非線性,讓神經網路學到更多的資訊
hidden1 = nn.ReLU()(hidden1)
nn.Sequential
Sequential,序列的,類似于把layers一層一層擺著
seq_modules = nn.Sequential(
flatten,
layer1,
nn.ReLU(),
nn.Linear(20, 10)
)
input_image = torch.rand(3,28,28)
logits = seq_modules(input_image)
nn.Softmax
最后一層的結果回傳一個在[-inf,inf]的值logits,通過softmax層后,映射到[0,1]
這樣[0,1]的值可以作為概率輸出,dim指定和為1的維度
softmax = nn.Softmax(dim=1)
pred_probab = softmax(logits)
模型的引數
這些layers是引數化的,就是說在訓練中weights和biases不斷被優化
以下的代碼輸出這個模型里的所有引數值
for name, param in model.named_parameters():
print(name,param.size(),param[:2])
自動求導
訓練神經網路的時候,最常用的是反向傳播,模型引數根據loss functoin的梯度進行調整,
為了求梯度,也就是求導,我們使用torch.autograd,
考慮就一個layer的網路,輸入x,引數w和b,以及一個loss function,也就是
import torch
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
Tensors, Functions and Computational Graph
考慮這個程序的Computational Graph,如下
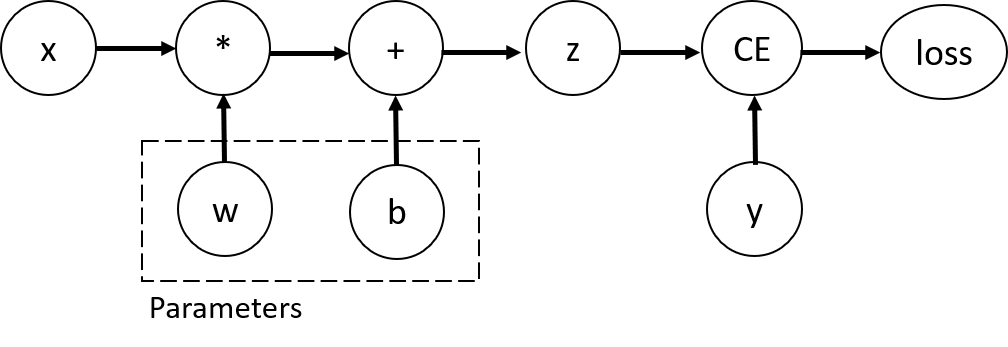
這個一定是DAG(有向無環圖)
為了計算loss在w和b方向上的梯度,我們給他們設定requires_grad
w.requires_grad_(True)
b.requires_grad_(True)
Functions實際上是物件,有計算正向值和反向導數的成員,
print(z.grad_fn)
print(loss.grad_fn)
計算梯度
我們要計算Loss對w和b的偏導,只需要使用
loss.backward()
然后就得到了
print(w.grad)
print(b.grad)
注意:
- 我們只能計算圖里葉子的梯度,內部的點不能算
- 一張圖只能計算一次梯度,要保留節點的話,backward要傳
retain_graph=True
import torch
x = torch.randn((1,4),dtype=torch.float32,requires_grad=True)
y = x ** 2
z = y * 4
print(x)
print(y)
print(z)
loss1 = z.mean()
loss2 = z.sum()
print(loss1,loss2)
loss1.backward() # 這個代碼執行正常,但是執行完中間變數都free了,所以下一個出現了問題
print(loss1,loss2)
loss2.backward() # 這時會引發錯誤
所以要把loss1的那行改成
loss1.backward(retain_graph=True)
不計算梯度
有些時候我們不需要計算梯度,比如模型已經訓好了,只需要正向用
這個時候算梯度就很拖累時間,所以要禁用梯度
z = torch.matmul(x, w)+b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x, w)+b
print(z.requires_grad)
'''
True
False
'''
另一個辦法是用.detach()
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad)
'''
False
'''
tensor輸出和雅克比積
如果函式的輸出是tensor,就不能簡單算梯度了
結果是一個矩陣(其實就是依次遍歷x和y的分量,求偏導)
\[J=\left(\begin{array}{ccc}\frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}}\end{array}\right) \]PyTorch不計算J的原始值,而是給一個\(v\),計算\(v^T\cdot J\),輸出介面是統一的
具體來說,把v當引數傳進去
inp = torch.eye(5, requires_grad=True)
out = (inp+1).pow(2)
out.backward(torch.ones_like(inp), retain_graph=True)
優化模型引數
有了模型,接下來要進行訓練、驗證和測驗,
前置代碼
首先要加載資料,建立模型
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
training_data = https://www.cnblogs.com/ghostcai/p/datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = https://www.cnblogs.com/ghostcai/p/datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
超引數
定義三個超引數
- Epochs數:資料集迭代次數
- Batch size:單次訓練樣本數
- Learning Rate:學習速度
優化回圈
接下來,我們進行多輪的優化,每輪叫一個epoch
每個epoch包含兩部分,訓練loop和驗證/測驗loop
Loss Function
PyTorch提供常見的Loss Functions
- nn.MSELoss (Mean Square Error)
- nn.NLLLoss (Negative Log Likelihood)
- nn.CrossEntropyLoss (交叉熵)
我們使用交叉熵,把原始結果logits放進去
loss_fn = nn.CrossEntropyLoss()
Optimizer
初始化優化器,給它需要優化的引數,和超引數Learning Rate
optimizer = torch.optim.SGC(model.parameters(),lr = learning_rate)
優化器在每個epoch里做三件事
optimizer.zero_grad()將梯度清零loss.backward()進行反向傳播optimizer.step()根據梯度調整引數
完整實作
在train_loop里訓練,test_loop里測驗
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
training_data = https://www.cnblogs.com/ghostcai/p/datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = https://www.cnblogs.com/ghostcai/p/datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
learning_rate = 1e-3
batch_size = 64
epochs = 5
# Initialize the loss function
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
# Compute prediction and loss
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 10
for t in range(epochs):
print(f"Epoch {t + 1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done!")
保存和加載模型
如何保存和加載訓好的模型?
import torch
import torchvision.models as models
保存和加載模型權重
通過torch.save方法,可以將模型保存到state_dict型別的字典里,
model = models.vgg16(pretrained=True)
torch.save(model.state_dict(), 'model_weights.pth')
而要加載的話,需要先構造相同型別的模型,然后把引數加載進去
model = models.vgg16() # we do not specify pretrained=True, i.e. do not load default weights
model.load_state_dict(torch.load('model_weights.pth'))
model.eval()
注意,一定要調一下model.eval(),防止后續出錯
保存和加載模型
上一種方法里,需要先實體化模型,再匯入權值
有沒有辦法直接保存和加載整個模型呢?
我們用不傳mode.state_dict()引數,改為model
保存方式:
torch.save(model,'model.pth')
加載方式:
model = torch.load('model.pth')
本文來自博客園,作者:GhostCai,轉載請注明原文鏈接:https://www.cnblogs.com/ghostcai/p/16209766.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/468758.html
標籤:其他
上一篇:C++基礎-3-函式