我有以下資料框,我想在讀取每個相鄰特征的不同值時著色。例如,對于“max”,CRIM raw=88.98 和 CRIM wisorized=41.53 應該是紅色,而對于 AGE,它們應該保持黑色。
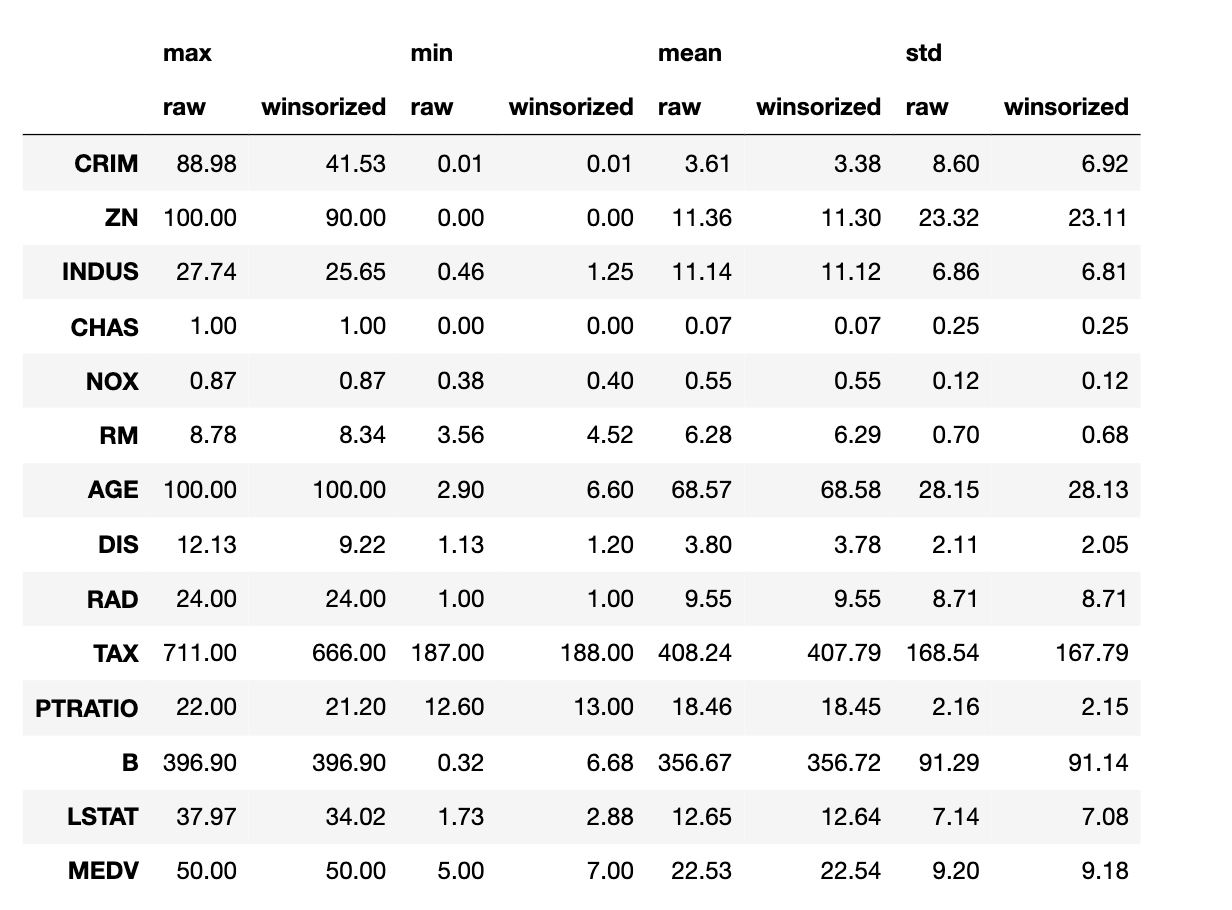
我怎樣才能做到這一點?附件是 CSV 檔案。
,25%,25%,50%,50%,75%,75%,count,count,max,max,mean,mean,min,min,std,std
,raw,winsorized,raw,winsorized,raw,winsorized,raw,winsorized,raw,winsorized,raw,winsorized,raw,winsorized,raw,winsorized
CRIM,0.08,0.08,0.26,0.26,3.68,3.68,506.0,506.0,88.98,41.53,3.61,3.38,0.01,0.01,8.6,6.92
ZN,0.0,0.0,0.0,0.0,12.5,12.5,506.0,506.0,100.0,90.0,11.36,11.3,0.0,0.0,23.32,23.11
INDUS,5.19,5.19,9.69,9.69,18.1,18.1,506.0,506.0,27.74,25.65,11.14,11.12,0.46,1.25,6.86,6.81
CHAS,0.0,0.0,0.0,0.0,0.0,0.0,506.0,506.0,1.0,1.0,0.07,0.07,0.0,0.0,0.25,0.25
NOX,0.45,0.45,0.54,0.54,0.62,0.62,506.0,506.0,0.87,0.87,0.55,0.55,0.38,0.4,0.12,0.12
RM,5.89,5.89,6.21,6.21,6.62,6.62,506.0,506.0,8.78,8.34,6.28,6.29,3.56,4.52,0.7,0.68
AGE,45.02,45.02,77.5,77.5,94.07,94.07,506.0,506.0,100.0,100.0,68.57,68.58,2.9,6.6,28.15,28.13
DIS,2.1,2.1,3.21,3.21,5.19,5.19,506.0,506.0,12.13,9.22,3.8,3.78,1.13,1.2,2.11,2.05
RAD,4.0,4.0,5.0,5.0,24.0,24.0,506.0,506.0,24.0,24.0,9.55,9.55,1.0,1.0,8.71,8.71
TAX,279.0,279.0,330.0,330.0,666.0,666.0,506.0,506.0,711.0,666.0,408.24,407.79,187.0,188.0,168.54,167.79
PTRATIO,17.4,17.4,19.05,19.05,20.2,20.2,506.0,506.0,22.0,21.2,18.46,18.45,12.6,13.0,2.16,2.15
B,375.38,375.38,391.44,391.44,396.22,396.22,506.0,506.0,396.9,396.9,356.67,356.72,0.32,6.68,91.29,91.14
LSTAT,6.95,6.95,11.36,11.36,16.96,16.96,506.0,506.0,37.97,34.02,12.65,12.64,1.73,2.88,7.14,7.08
MEDV,17.02,17.02,21.2,21.2,25.0,25.0,506.0,506.0,50.0,50.0,22.53,22.54,5.0,7.0,9.2,9.18
uj5u.com熱心網友回復:
僅此而已,僅此而已:)
def highlight_cols(s):
# input: s is a pd.Series with an attribute name
# s.name --> ('25%', 'raw')
# ('25%', 'winsorized')
# ...
#
# 1) Take the parent level of s.name (first value of the tuple) E.g. 25%
# 2) Select the subset from df, given step 1
# --> this will give you the df: 25% - raw | 25% - winsorized back
# 3) check if the amount of unique values (for each row) > 1
# If so: return a red text
# if not: return an empty string
#
# Output: a list with the desired style for serie x
return ['background-color: red' if x else '' for x in df[s.name[0]].nunique(axis=1) > 1]
df.style.apply(highlight_cols)
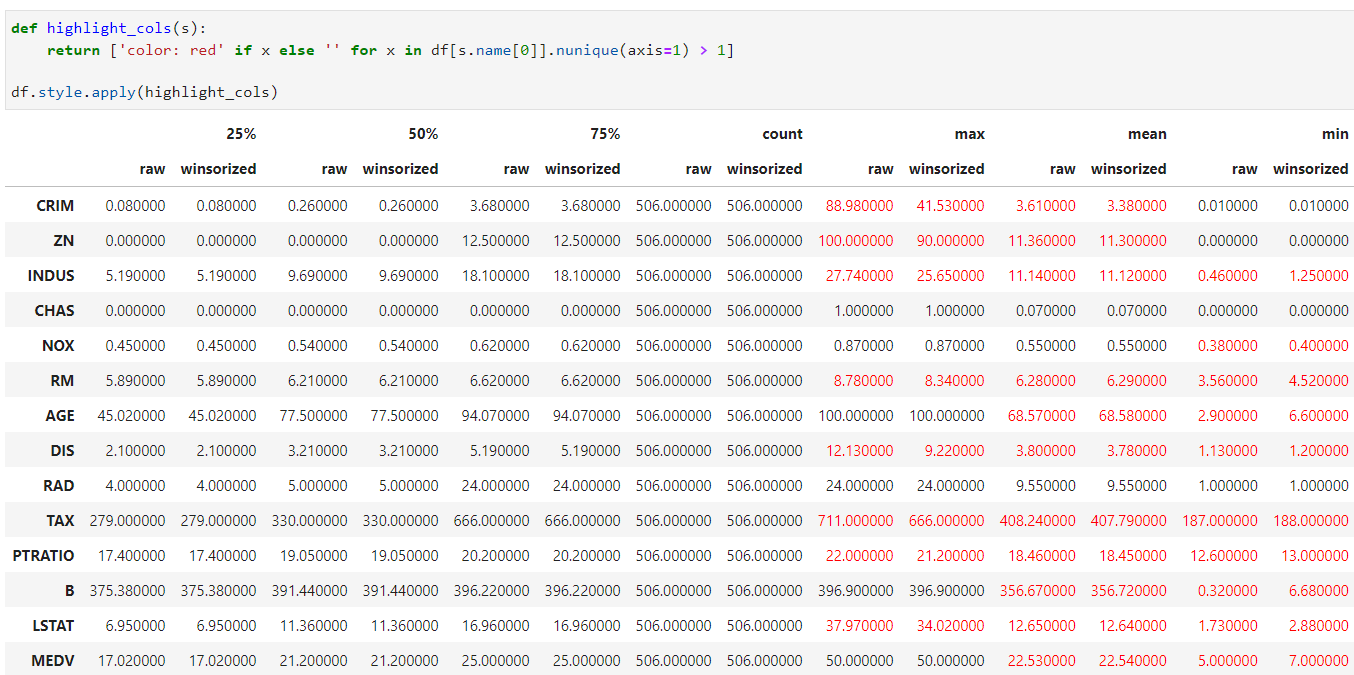
uj5u.com熱心網友回復:
您可以使用 groupby 在列之間進行此比較。這是一個例子:
import pandas as pd
import io
s = """,25%,25%,50%,50%,75%,75%,count,count,max,max,mean,mean,min,min,std,std
,raw,winsorized,raw,winsorized,raw,winsorized,raw,winsorized,raw,winsorized,raw,winsorized,raw,winsorized,raw,winsorized
CRIM,0.08,0.08,0.26,0.26,3.68,3.68,506.0,506.0,88.98,41.53,3.61,3.38,0.01,0.01,8.6,6.92
ZN,0.0,0.0,0.0,0.0,12.5,12.5,506.0,506.0,100.0,90.0,11.36,11.3,0.0,0.0,23.32,23.11
INDUS,5.19,5.19,9.69,9.69,18.1,18.1,506.0,506.0,27.74,25.65,11.14,11.12,0.46,1.25,6.86,6.81
CHAS,0.0,0.0,0.0,0.0,0.0,0.0,506.0,506.0,1.0,1.0,0.07,0.07,0.0,0.0,0.25,0.25
NOX,0.45,0.45,0.54,0.54,0.62,0.62,506.0,506.0,0.87,0.87,0.55,0.55,0.38,0.4,0.12,0.12
RM,5.89,5.89,6.21,6.21,6.62,6.62,506.0,506.0,8.78,8.34,6.28,6.29,3.56,4.52,0.7,0.68
AGE,45.02,45.02,77.5,77.5,94.07,94.07,506.0,506.0,100.0,100.0,68.57,68.58,2.9,6.6,28.15,28.13
DIS,2.1,2.1,3.21,3.21,5.19,5.19,506.0,506.0,12.13,9.22,3.8,3.78,1.13,1.2,2.11,2.05
RAD,4.0,4.0,5.0,5.0,24.0,24.0,506.0,506.0,24.0,24.0,9.55,9.55,1.0,1.0,8.71,8.71
TAX,279.0,279.0,330.0,330.0,666.0,666.0,506.0,506.0,711.0,666.0,408.24,407.79,187.0,188.0,168.54,167.79
PTRATIO,17.4,17.4,19.05,19.05,20.2,20.2,506.0,506.0,22.0,21.2,18.46,18.45,12.6,13.0,2.16,2.15
B,375.38,375.38,391.44,391.44,396.22,396.22,506.0,506.0,396.9,396.9,356.67,356.72,0.32,6.68,91.29,91.14
LSTAT,6.95,6.95,11.36,11.36,16.96,16.96,506.0,506.0,37.97,34.02,12.65,12.64,1.73,2.88,7.14,7.08
MEDV,17.02,17.02,21.2,21.2,25.0,25.0,506.0,506.0,50.0,50.0,22.53,22.54,5.0,7.0,9.2,9.18"""
df = pd.read_csv(io.StringIO(s), header=[0,1])
df = df.set_index(df.columns[0])
df.index.name = ''
def get_styles_inner(col):
first_level_name = col.columns[0][0]
# compare raw and windsorized
match = col[(first_level_name, 'raw')] == col[(first_level_name, 'winsorized')]
# color both the raw and windsorized red if they don't match
col[(first_level_name, 'raw')] = match
col[(first_level_name, 'winsorized')] = match
return col
def get_styles(df):
# Grouping on the first level of the index of the columns, pass each
# group to get_styles_inner.
match_df = df.groupby(level=0, axis=1).apply(get_styles_inner)
# Replace True with no style, and False with red
style_df = match_df.applymap(lambda x: None if x else 'color:red;')
return style_df
df.style.apply(get_styles, axis=None)
(前 24 行只是加載到您的資料集中。如果您已經擁有資料集,則可以忽略它們。)
這是輸出:
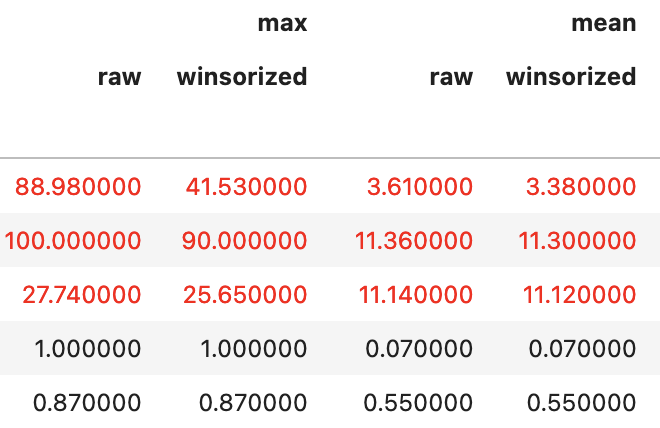
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/469358.html