字串匹配演算法
樸素思想(暴力)
任何一種問題,我們都習慣先寫出暴力做法,然后再去想如何優化,對于字串匹配也是如此,話不多說,直接上代碼,暴力遍歷比較,
for (int i = 0; i < n; i ++ )
{
bool flag = true;
for (int j = 0; j < n-m+1; j ++ )
{
if (text[i + j ] != pattern[j])
{
flag=false;
break;
}
}
if(flag)
return i;
}
雖然說暴力做法一直是效率低下的代言詞,但對于平常使用來說,這種做法就已經夠用了,因為在實際開發中,大部分情況下的主串和模式串的長度都不會太長,并且它思路清晰簡單,出問題也好修復,實際上一般 string 的查找函式就是這種做法,
但是也不能就會這一招就阿尼陀佛,萬事大吉了,總有需要優化的時候,計算機之所以在現代社會有著舉足輕重的地位,就在于人在不斷思考,并優化它的執行方式,缺少了人的思考,它只是一坨笨的不能再笨的鐵而已,
KMP
樸素做法雖然簡單,但主串與模式串的指標都要來回移動,我們去書上找東西一般都是一眼掃過去,有沒有什么辦法可以讓主串的指標不往回走,降低比較的趟數?

在上面這個例子中,很明顯更快的做法是在第一次匹配失敗之后,跳過第二次匹配,進行第三次匹配,也就是說,應該向后移動兩格而不是一格,KMP的思想就在于利用已知資訊,不把"搜索位置"移回已經比較過的位置,繼續向后移,

我們可以利用模式串自身的特點,利用已經匹配過的結果來減少列舉程序,跳過不可能成功的比較,加速匹配程序,畫個抽象點的圖:
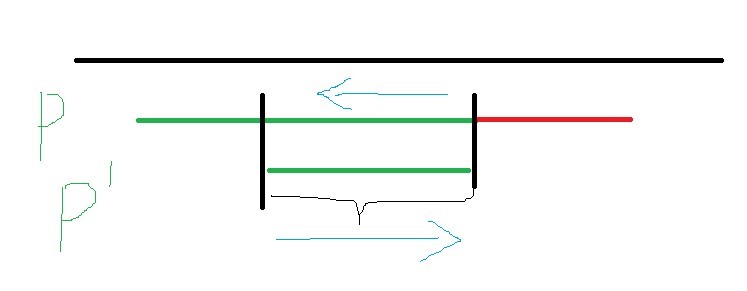
在主串指標不往后退的前提下, 我們的模式串指標最多回退到哪里就可以繼續進行匹配呢?
如上圖,回退之后的字串肯定是要能與主串匹配成功的,也就是說它與之前的模式串有著交集,從圖中可以看到,P串的后綴與P'的前綴相同,那個這個問題:在已有N個匹配成功的結果下,第N+1個字符匹配失敗時,模式串應該退回到第?個匹配成功的結果下?也就轉換成了:模式串的各個字串中,能使前后綴相等的最大長度是多少?
我們用next陣列來存盤回退到的下標

雖然說1那里應該等于0,但其實這時候已經退無可退了,所以應該退出回圈,讓主串指標向前走一位,開始新一輪比較,
利用這個next陣列,比如我們比較到下標3的時候發現不匹配,沒關系,我們退一步,退一步之后就到了下標1(回退看的next應該是已經匹配成功的那個,也就是看下標2存的是幾),如果這時候還不匹配,那我們就會退回到-1,也就是說,這輪匹配失敗了,主串可以往前走了,
看看代碼就清楚了
int strStr(string haystack, string needle)
{
if (!needle.size()) return 0;
if (!haystack.size()) return -1;
vector<int> next(needle.size());
next[0] = -1;
//求next陣列
for (int i = 1, j = -1; i < needle.size(); i++)
{
while (j >= 0 && needle[i]!=needle[j+1])
{
//不匹配就退一步看看
j = next[j];
}
if (needle[i] == needle[j + 1])
{
//匹配成功就繼續往后走
//看看還能不能匹配成功
j++;
}
next[i] = j;
}
//開始匹配
for (int i = 0, j = -1; i < haystack.size(); i++)
{
while (j != -1 && haystack[i] != needle[j+1])
{
//不匹配咱就回退
j = next[j];
}
if (haystack[i] == needle[j+1])
{
j++;
}
if (j == needle.size() - 1)
{
return i-j;
}
}
return -1;
}
BM
雖然KMP比較出名,但其實只是因為它比較難懂而已,在效率上有很多的演算法都比它要好,現在介紹的BM演算法,其效率就要比KMP好上3到4倍,
BM演算法包含兩部分:壞字符規則和好后綴規則
壞字符規則
BM演算法與我們平常接觸的字串比較方法不同,它是按模式串從大到小的順序,倒著比的,這樣做也是有好處的,起碼直觀上是這樣感覺的,就像做算數選擇題,出卷老師為了讓你花的時間久一點,故意把正確答案放到C跟D上,所以聰明點的做法應該是先算C跟D,這跟這個比較方法有點類似,
考慮下面這張圖:
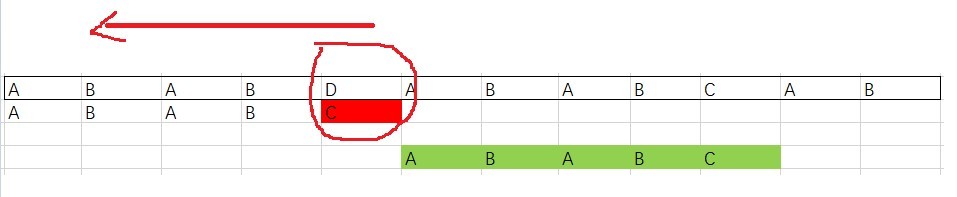
別忘了我們是從模式串最大的開始往后匹配,所以這里先比較了C和D,這個時候,有意思的來了,這個 D 在模式串中就沒有出現過,是一個壞字符,有它在的字串可能不匹配,
惹不起還躲不起嗎?溜之大吉,模式串直接移動五位,重新匹配,一下移動這么多,是不是特別的爽?
但你千萬不要以為只有沒在模式串中出現過的才叫壞字符,實際上這個只是從后往前第一個不匹配的字符,一旦發生不匹配,壞字符規則的做法是模式串指標繼續往回走,找到第一個與其匹配的字符停止,然后再繼續新一輪的匹配,
也就是說,移動的距離等于:當前模式串的下標(Si) - 往回走找到的第一個與當前不匹配字符匹配的下標(Xi),如果沒有找到,則減數為-1,
這么一想,好像用壞字符規則就萬事大吉了,但因為實際代碼中,我們不會每次不匹配都會往前找,那樣太耗費時間,取而代之的是使用散串列紀錄不同字符在模式串中“最后出現的位置”,并不是 Si 的位置往前查找的第一個位置,所以可能會出現 Xi 大于 Si 的情況,比如上圖的例子,主串"ABABDABABCAB",模式串"ABABC"當從左開始數的一個B不匹配時,找到的A的下標是最后一次在模式串中出現的下標(也就是最后一個a的位置,比A大),這時候,模式串非但不往前滑動,還回退了,為了解決這個問題,我們需要好后綴來幫忙,(實際上,兩個規則都可以獨立使用,如果壞字符你是往回遍歷而不是保存在散串列里面的話)
好后綴規則
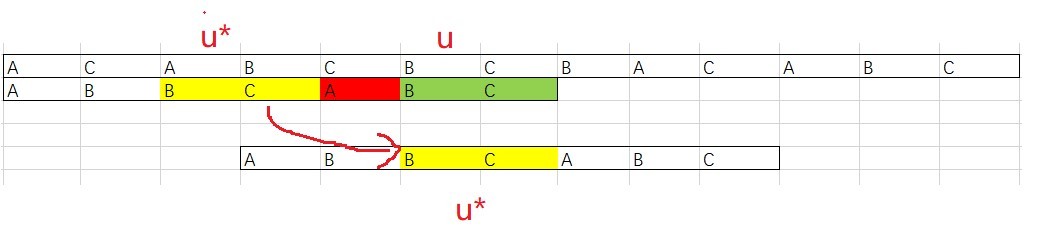
當遇到上圖的情況時,我們依然可以用壞字符規則來移動,但這次讓我們來看看好后綴是如何作業的?
我們把在主串中已經匹配成功的字串用 u標記,現在要做的是找到模式串中與其匹配的u*如果找到了,那模式串就滑動到使得u*與u對齊的位置,如果不匹配,那么溜之大吉,直接移動一個模式串長度的位置,雖然一次移動那么多是很爽,但這樣做有可能錯過可以匹配的情況,
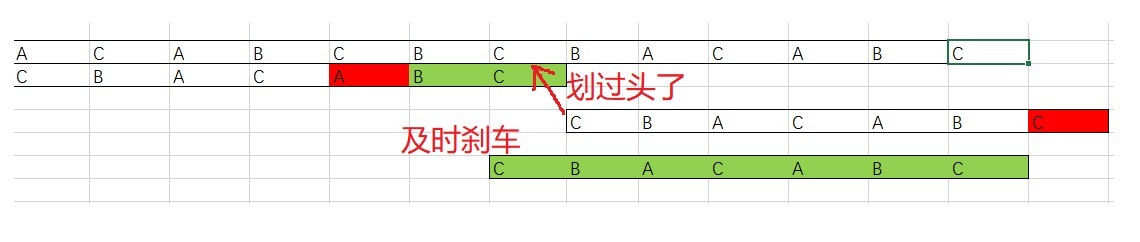
實際上這里應該跟KMP一樣,如果模式串中前綴與好后綴的后綴相同,那么就移動相應位置使其匹配,
雙劍合璧
兩個規則你都知道了,并且他們都可以獨立使用,那么到底該選哪一個呢?

可以參考的建議
- 如果處理的是字符集很大的字串匹配問題,那么壞字符規則對記憶體的消耗會比較多,因為兩個規則是獨立的,所以可以考慮僅使用好后綴
- 如果同時使用兩個規則,滑動的大小應該是兩個規則中最大的那一個,這樣可以避免負數的產生
代碼實作
如前面所說,壞字符如果每次都在模式串中遍歷的話,會對性能造成影響,那么有沒有什么高效的辦法代替遍歷呢?
我們可以將模式串中的每個字符及其下標都存到散串列中,這樣就能快速的找到壞字符在模式串的對應下標了,
先打好壞字符規則
private:
static const int SIZE = 256;
//求bc
vector<int> getBC(string pattern)
{
vector<int> bc(SIZE,-1);
for (int i = 0; i < pattern.size(); i++)
{
int ascii = (int)pattern[i];
bc[ascii] = i;
}
return bc;
}
int strStr(string haystack, string needle)
{
if (needle.size() == 0) return 0;
vector<int> bc(SIZE);
bc = getBC(needle);
int i = 0;
while (i <= haystack.size() - needle.size())
{
int j;
//別忘了,BM是從后往前匹配哦
for (j = needle.size() - 1; j >= 0; j--)
{
//不等于咱就要去找滑動位置了
if (haystack[i + j] != needle[j])
break;
}
if (j < 0)
{
//這是匹配成功!我們是從后往前的!!!
return i;
}
//找到模式串中最近的壞字符
i = i + j - bc[(int)haystack[i + j]];
}
return -1;
}
好后綴稍微麻煩一點,與KMP類似,我們用一個int陣列suffix來保存,其下標表示后綴子串的長度,讓我們來明確一下要干的事:在好后綴的后綴子串中,查找最長的、能跟模式串前綴子串匹配的后綴子串,所以存盤的應該是在模式串中跟好后綴u相匹配的子串u*的起始下標值,
等等!我們好像漏了什么?在模式串中查找跟好后綴匹配的另一個子串,并且在好后綴的后綴子串中,查找最長能跟模式串前綴子串匹配的后綴子串,
suffix陣列只能完成前半段話,那前綴子串的問題該如何解決呢?我們只能是再開一個bool陣列prefix 來做這件事了,
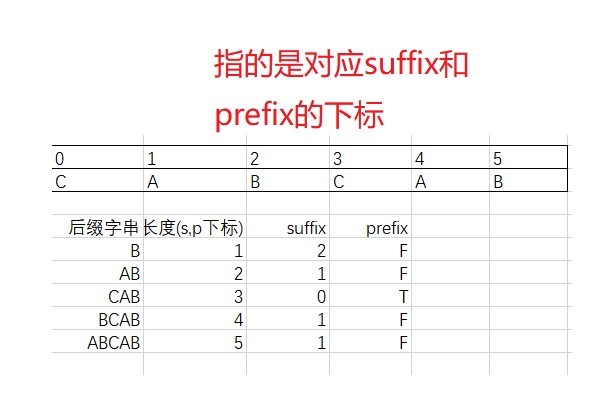
求這兩個陣列的方法也十分討巧,紀錄公共后綴子串u*的起始下標為j,如果j==0,說明是前綴字串(因為已經走到盡頭了),prefix為true,代碼實作是下面這樣:
//好后綴
void genGS(string pattern)
{
int len = pattern.size();
for (int i = 0; i < len; i++)
{
suffix.push_back(-1);
prefix.push_back(false);
}
for (int i = 0; i < len - 1; i++)
{
int j = i;
//公共后綴u*的長度
int k = 0;
while (j >= 0 && pattern[j] == pattern[len - 1 - k])
{
j--;
k++;
//保存的是在pattern中的起始下標
suffix[k] = j + 1;
}
if (j == -1)
prefix[k] = true;
}
}
現在讓我們來把兩個規則一起用在字串匹配上
private:
static const int SIZE = 256;
vector<int> bc;
vector<int> suffix;
vector<bool> prefix;
//壞字符
void getBC(string pattern)
{
for (int i = 0; i < SIZE; i++)
{
bc.push_back(-1);
}
for (int i = 0; i < pattern.size(); i++)
{
int ascii = (int)pattern[i];
bc[ascii] = i;
}
}
//好后綴
void genGS(string pattern)
{
int len = pattern.size();
for (int i = 0; i < len; i++)
{
suffix.push_back(-1);
prefix.push_back(false);
}
for (int i = 0; i < len - 1; i++)
{
int j = i;
//公共后綴u*的長度
int k = 0;
while (j >= 0 && pattern[j] == pattern[len - 1 - k])
{
j--;
k++;
//保存的是在pattern中的起始下標
suffix[k] = j + 1;
}
if (j == -1)
prefix[k] = true;
}
}
int moveByGS(int j, int len)
{
//好后綴長度
int k = len - 1 - j;
if (suffix[k] != -1)
return j - suffix[k] + 1;
for (int i = j + 2; i < len; i++)
{
if (prefix[len = i])
return i;
}
return len;
}
int strStr(string haystack, string needle)
{
if (needle.size() == 0) return 0;
getBC(needle);
genGS(needle);
int i = 0;
while (i <= haystack.size() - needle.size())
{
int j;
//別忘了,BM是從后往前匹配哦
for (j = needle.size() - 1; j >= 0; j--)
{
//不等于咱就要去找滑動位置了
if (haystack[i + j] != needle[j])
break;
}
if (j < 0)
{
//這是匹配成功!我們是從后往前的!!!
return i;
}
//找到模式串中最近的壞字符
int x = j - bc[(int)haystack[i + j]];
int y = 0;
//如果有好后綴
if (j < needle.size() - 1)
{
y = moveByGS(j,needle.size());
}
i = i + max(x, y);
}
return -1;
}
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/47561.html
標籤:其他