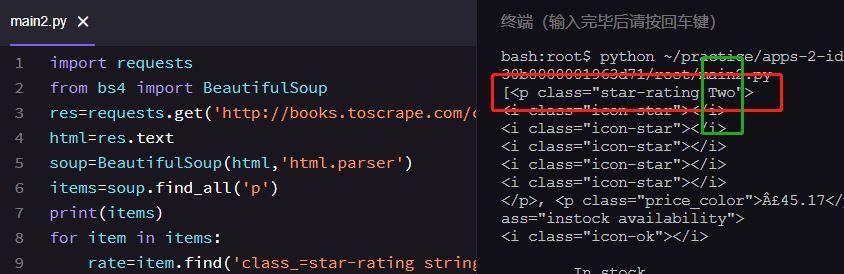
uj5u.com熱心網友回復:
我想把這個TWO提取出來 不要star-rating 求教!uj5u.com熱心網友回復:

uj5u.com熱心網友回復:
建議找出規律,然后用正則。uj5u.com熱心網友回復:
我小白一個...但還是謝謝啦
uj5u.com熱心網友回復:
獲取標簽屬性后str.split()[-1]分割
uj5u.com熱心網友回復:
沒辦法,屬性提取會一塊提取出來,你可以用切片之類的方法部分顯示uj5u.com熱心網友回復:
謝謝你!uj5u.com熱心網友回復:
謝謝??!uj5u.com熱心網友回復:
這個需求有點奇怪,可能我理解錯了uj5u.com熱心網友回復:
哈哈 這就是一個評價等級 我想把這個評價等級爬出來uj5u.com熱心網友回復:
明白了,那就是按照上面說的,先把class抽出來,再拆分
uj5u.com熱心網友回復:
那請問這個class里面有這么多...而且star-rating one two three又不是同樣的 我該用什么方法把class=star-rating ***的這中提取出來呢
uj5u.com熱心網友回復:
如果每個class都是star-rating+***,就可以用上面他們說的拆分呀.split()[-1]uj5u.com熱心網友回復:
這個分割好像是在提取出屬性后再提取屬性當中的one two three用的 不知道用什么關鍵詞能把屬性提取出來
uj5u.com熱心網友回復:
大神 還麻煩再請教一下 我該用什么關鍵詞能把class=star-rating ** 這類屬性提取出來... 他后面one two three都不一樣謝謝啦
uj5u.com熱心網友回復:
給你一個用simplified_scrapy庫的例子,需要安裝pip install simplified-scrapy
from simplified_scrapy.simplified_doc import SimplifiedDoc
doc = SimplifiedDoc()
print (doc.getElementByClass("star-rating",'<p class="star-rating Two"><li></li></p>')["class"].split()[-1])
uj5u.com熱心網友回復:
好噠 謝謝大神!
uj5u.com熱心網友回復:
還是找規律。看看不同等級(不同class)有什么規律,再決定怎么處理。
uj5u.com熱心網友回復:
規律就是class =star-rating 啥啥啥(one two three一類的) 然后就不會用find找出來這一類了
uj5u.com熱心網友回復:
上面的方法不行嗎
uj5u.com熱心網友回復:
試了一下運行出錯 book.toscrape.com 這是那個網站 你要是方便的話還請你試一試提取出來里面的書名和對應的評分...這是老師自建的一個用來練習做作業的網站.... 頭疼...
book.toscrape.com 這是那個網站 你要是方便的話還請你試一試提取出來里面的書名和對應的評分...這是老師自建的一個用來練習做作業的網站.... 頭疼...
uj5u.com熱心網友回復:
import requestsfrom bs4 import BeautifulSoup
res = requests.get('http://books.toscrape.com/catalogue/category/books/travel_2/index.html')
soup = BeautifulSoup(res.text, 'html.parser')
article = soup.find_all('article', class_='product_pod')
for item in article:
name_h3 = item.find('h3') # 找到書名所在標簽h3中
name_a = name_h3.find('a')
name = name_a['title'] # 找到每本書的全名
print(name)
score_p = item.find('p')
score_dirt = score_p.attrs # 這一步是取出p標簽的屬性名(以大字典的形式)
# print(score_dirt)
score = score_dirt['class'][1]
print(score) # 取出分
price = item.find('p', class_='price_color') # 取出價格
print(price.text[1:]+'\n') # 注意偏移量
uj5u.com熱心網友回復:
import requestsfrom bs4 import BeautifulSoup
res = requests.get('http://books.toscrape.com/')
html = res.text
soup = BeautifulSoup(html,'html.parser')
items = soup.find_all(class_='product_pod')
print(items)
for item in items:
book_name = item.find('h3')
book_grade = item.p['class'] #把p的class屬性值裝入串列
book_price = item.find(class_='price_color')
print(book_name.text,'\n',book_grade[1],'\n',book_price.text) #提取串列
uj5u.com熱心網友回復:
import requestsfrom bs4 import BeautifulSoup
res = requests.get('http://books.toscrape.com/catalogue/category/books/travel_2/index.html')
soup = BeautifulSoup(res.text, 'html.parser')
article = soup.find_all('article', class_='product_pod')
print(article)
for item in article:
book_name = item.find('h3') #h3標簽
book_grade = item.p['class'] #把p的class屬性值裝入串列
book_price = item.find(class_='price_color')
print('''{}\n\n{}\n\n{}'''.format(book_name,book_grade,book_price))
print("*"*50)
print(book_name.a['title'],'\n',book_grade[1],'\n',book_price.text[1:]) #提取串列
print(book_name.text,"\n",book_name.a['href'])
按樓上的改的,學習了
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/48392.html
下一篇:微機原理:用匯編語言寫以下程式