客戶端的頁面通過 XML 來實作 UI 的布局,頁面的 UI 布局作為一個樹形結構,而樹葉被定義為節點,這里的節點也就對應了我們要定位的元素,節點的上級節點,定義了元素的布局結構,在 XML 布局中可以使用 XPath 進行節點的定位,
App的布局結構
從上面這張圖中可以看到最左側是應用的頁面的展示,中間部分展示了這個頁面的樹形結構的 XML 代碼,
其中包含的內容為:
- 節點 node
- 節點屬性:包括 clickable(是否可點擊)、content-desc(內容)、resource-id(元素 id)、text(文本)、bounds(坐標)等,
通過ID定位
在 Android 系統元素的 ID 稱為 resource-id,使用頁面分析工具比如 Appium Inspector 能夠獲取元素的唯一標識是 ID 屬性,可以使用 ID 進行元素定位,方便快捷,
示例代碼如下:
driver.find_element(By.ID, \
"android:id/text1").click()
注意 resource-id 對應的屬性(包名:id/id 值),在使用這個屬性的時候要把它當作一個整體,
當分析工具能抓取到的 content-desc 的屬性值是唯一時,可以采用 Accessibility 的定位方式,示例代碼:
driver.find_element_by_accessibility_id("Accessibility")
與 Selenium 類似,可以使用 XPath 的定位方式完成頁面的元素定位,XPath 分為絕對路徑定位與相對路徑定位兩種形式,下面介紹的都是相對定位的形式,
XPath:resource-id 屬性定位
元素可以通過 resource-id 定位,
格式://*[@resource-id=‘resource-id屬性’]
示例代碼:
driver.find_element(By.XPATH, \
'//*[@resource-id="rl_login_phone"]')
XPath:text 屬性定位
元素可以通過 text 文本屬性定位,
格式:
//*[@text=’text文本屬性’]
示例代碼:
driver.find_element(By.XPATH,'//*[@text="我的"]')
XPath:class 屬性定位
元素可以通過 class 定位,
格式:
//*[@class=’class 屬性’]
示例代碼:
driver.find_element(By.XPATH,\
'//*[@]')
XPath:content-desc 屬性定位
元素可以通過 content-desc 定位,
格式:
//*[@content-desc=‘content-desc 屬性’]
示例代碼:
driver.find_element((By.XPATH,\
'//*[@content-desc="搜索"]')
使用 Android SDK(sdk/tools/uiautomatorviewer)路徑下自帶的 uiautomatorviewer 工具也可以抓取當前頁面的元素,
提前配置 sdk/tools/路徑到環境變數 $PATH 中,直接在命令列輸入下面的命令:
uiautomatorviewer
可以打開下面這樣一個頁面,點擊頁面左上角第二個圖示(Android 手機圖示),就可以獲取下面的 uiautomatorviewer 快照圖:
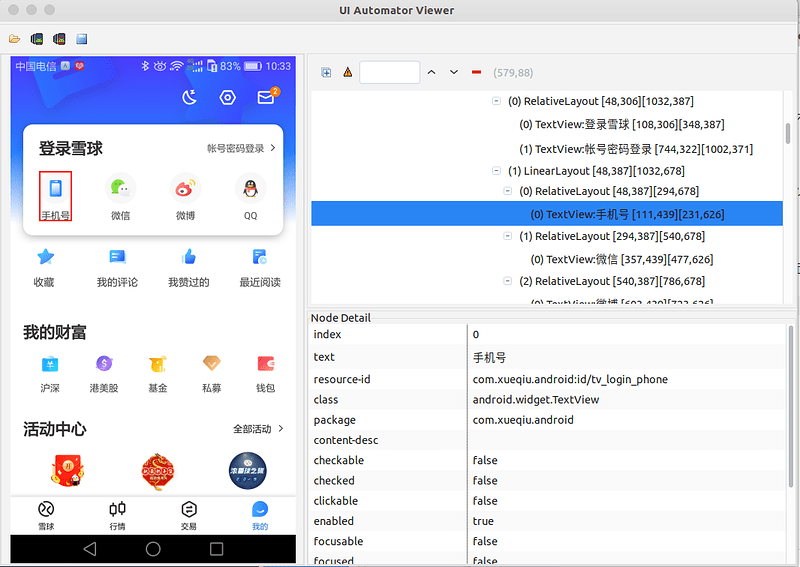
uiautomatorviewer 抓取快照展示出來的元素屬性是經過決議的,我們要查看 XML DOM 的真實結構可以列印 pagesource ,得到的內容如下,紅色框起來的部分為上圖的定位的 XML DOM 中的一個節點:
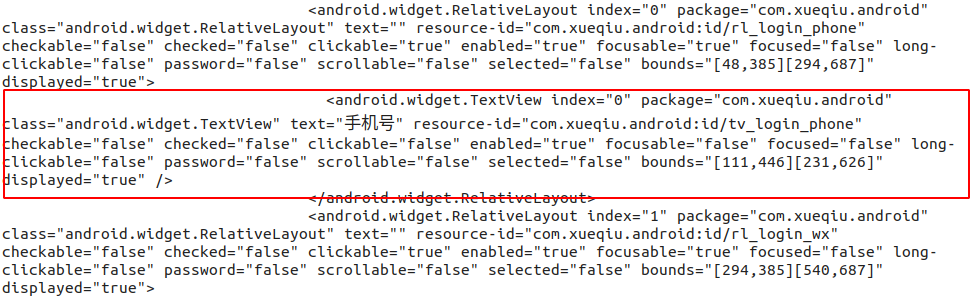
通過圖片分析,android.widget.TextView 是文本型別的節點,其中包含的屬性資訊都在上面的 uiautomatorviewer 快照圖中有展示,如果只想定位 Android 系統的頁面元素,可以直接使用 uiautomatorviewer,速度快并且不需要配置任何引數,直接點擊獲取頁面的圖示就可以將客戶端頁面抓取出來,
uiautomatorviewer 只能抓取 android8 以下的版本,如果要抓取 android8 以上的版本的頁面資訊,可以使用 Appium Inspector 或 WEditor哦~
喜歡軟體測驗的小伙伴們,如果我的博客對你有幫助、如果你喜歡我的博客內容,請 “點贊” “評論” “收藏” 一鍵三連哦,更多技術文章
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/489783.html
標籤:其他