??大家好,我是不溫卜火,是一名計算機學院大資料專業大二的學生,昵稱來源于成語—
不溫不火,本意是希望自己性情溫和,作為一名互聯網行業的小白,博主寫博客一方面是為了記錄自己的學習程序,另一方面是總結自己所犯的錯誤希望能夠幫助到很多和自己一樣處于起步階段的萌新,但由于水平有限,博客中難免會有一些錯誤出現,有紕漏之處懇請各位大佬不吝賜教!暫時只有csdn這一個平臺,博客主頁:https://buwenbuhuo.blog.csdn.net/
??本片博文為大家帶來的是Spark 出現的問題及其解決方案,

目錄
- 1. 控制reduce端緩沖大小以避免OOM
- 2. JVM GC導致的shuffle檔案拉取失敗
- 3. 解決各種序列化導致的報錯
- 4. 解決算子函式回傳NULL導致的問題
- 5. 解決YARN-CLIENT模式導致的網卡流量激增問題
- 6. 解決YARN-CLUSTER模式的 JVM堆疊 記憶體溢位無法執行問題
- 7. 解決 SparkSQL 導致的 JVM 堆疊記憶體溢位
- 8. 持久化與checkpoint的使用

1. 控制reduce端緩沖大小以避免OOM
在Shuffle程序,reduce端task并不是等到map端task將其資料全部寫入磁盤后再去拉取,而是map端寫一點資料,reduce端task就會拉取一小部分資料,然后立即進行后面的聚合、算子函式的使用等操作,
reduce端task能夠拉取多少資料,由reduce拉取資料的緩沖區buffer來決定,因為拉取過來的資料都是先放在buffer中,然后再進行后續的處理,buffer的默認大小為48MB,
reduce端task會一邊拉取一邊計算,不一定每次都會拉滿48MB的資料,可能大多數時候拉取一部分資料就處理掉了,
雖然說增大reduce端緩沖區大小可以減少拉取次數,提升Shuffle性能,但是有時map端的資料量非常大,寫出的速度非常快,此時reduce端的所有task在拉取的時候,有可能全部達到自己緩沖的最大極限值,即48MB,此時,再加上reduce端執行的聚合函式的代碼,可能會創建大量的物件,這可難會導致記憶體溢位,即OOM,
如果一旦出現reduce端記憶體溢位的問題,我們可以考慮減小reduce端拉取資料緩沖區的大小,例如減少為12MB,
在實際生產環境中是出現過這種問題的,這是典型的以性能換執行的原理,reduce端拉取資料的緩沖區減小,不容易導致OOM,但是相應的,reudce端的拉取次數增加,造成更多的網路傳輸開銷,造成性能的下降,
注意,要保證任務能夠運行,再考慮性能的優化,
2. JVM GC導致的shuffle檔案拉取失敗
在Spark作業中,有時會出現shuffle file not found的錯誤,這是非常常見的一個報錯,有時出現這種錯誤以后,選擇重新執行一遍,就不再報出這種錯誤,
出現上述問題可能的原因是Shuffle操作中,后面stage的task想要去上一個stage的task``所在的Executor拉取資料,結果對方正在執行GC,執行GC會導致Executor內所有的作業現場全部停止,比如BlockManager、基于netty的網路通信等,這就會導致后面的task拉取資料拉取了半天都沒有拉取到,就會報出shuffle file not found的錯誤,而第二次再次執行就不會再出現這種錯誤,
可以通過調整reduce端拉取資料重試次數和reduce端拉取資料時間間隔這兩個引數來對Shuffle性能進行調整,增大引數值,使得reduce端拉取資料的重試次數增加,并且每次失敗后等待的時間間隔加長,
val conf = new SparkConf()
.set("spark.shuffle.io.maxRetries", "60")
.set("spark.shuffle.io.retryWait", "60s")
3. 解決各種序列化導致的報錯
當 Spark 作業在運行程序中報錯,而且報錯資訊中含有Serializable等類似詞匯,那么可能是序列化問題導致的報錯,
序列化問題要注意以下三點:
- 作為RDD的元素型別的自定義類,必須是可以序列化的;
- 算子函式里可以使用的外部的自定義變數,必須是可以序列化的;
- 不可以在RDD的元素型別、算子函式里使用第三方的不支持序列化的型別,例如Connection,
4. 解決算子函式回傳NULL導致的問題
在一些算子函式里,需要我們有一個回傳值,但是在一些情況下我們不希望有回傳值,此時我們如果直接回傳NULL,會報錯,例如Scala.Math(NULL)例外,
如果你遇到某些情況,不希望有回傳值,那么可以通過下述方式解決:
- 回傳特殊值,不回傳NULL,例如“-1”;
- 在通過算子獲取到了一個RDD之后,可以對這個RDD執行filter``操作,進行資料過濾,將數值為-1的資料給過濾掉;
- 在使用完filter算子后,繼續呼叫coalesce算子進行優化,
5. 解決YARN-CLIENT模式導致的網卡流量激增問題
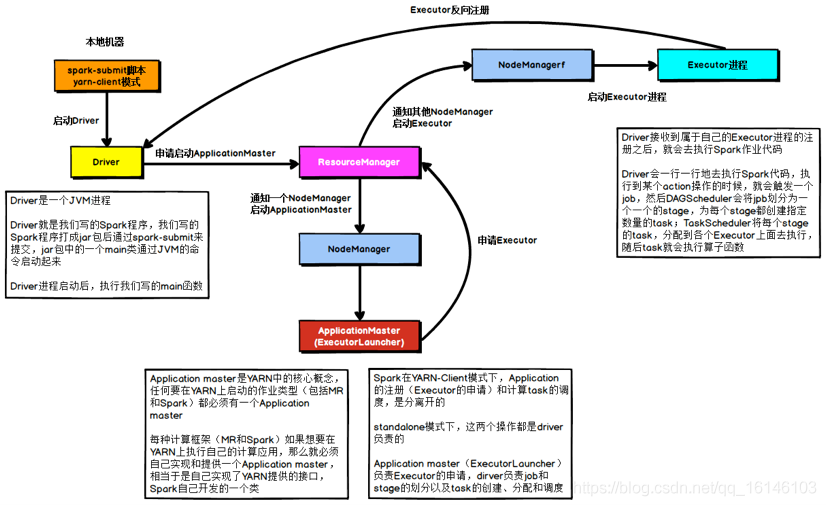
在 YARN-client 模式下,Driver 啟動在本地機器上,而 Driver 負責所有的任務調度,需要與 YARN 集群上的多個 Executor 進行頻繁的通信,
假設有100個Executor, 1000個task,那么每個Executor分配到10個task,之后,Driver要頻繁地跟Executor上運行的1000個task進行通信,通信資料非常多,并且通信品類特別高,這就導致有可能在Spark任務運行程序中,由于頻繁大量的網路通訊,本地機器的網卡流量會激增,
注意,YARN-client模式只會在測驗環境中使用,而之所以使用YARN-client模式,是由于可以看到詳細全面的log資訊,通過查看log,可以鎖定程式中存在的問題,避免在生產環境下發生故障,
在生產環境下,使用的一定是YARN-cluster模式,在YARN-cluster模式下,就不會造成本地機器網卡流量激增問題,如果YARN-cluster模式下存在網路通信的問題,需要運維團隊進行解決,
6. 解決YARN-CLUSTER模式的 JVM堆疊 記憶體溢位無法執行問題
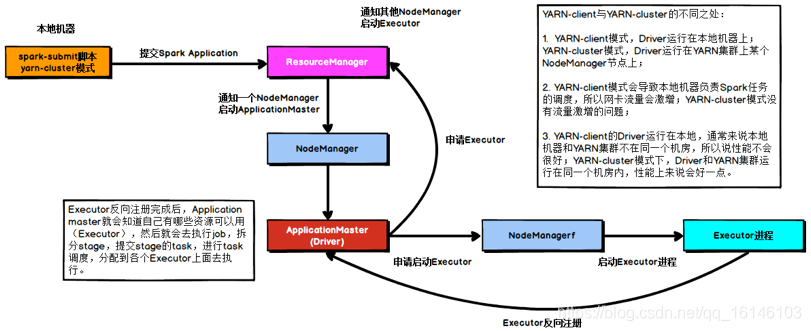
當 Spark 作業中包含 SparkSQL 的內容時,可能會碰到YARN-client模式下可以運行,但是YARN-cluster模式下無法提交運行(報出OOM錯誤)的情況,
YARN-client 模式下,Driver 是運行在本地機器上的,Spark 使用的 JVM 的 PermGen 的配置,是本地機器上的spark-class檔案,JVM 永久代的大小是128MB,這個是沒有問題的,但是在 YARN-cluster 模式下,Driver運行在YARN集群的某個節點上,使用的是沒有經過配置的默認設定,PermGen永久代大小為82MB,
SparkSQL的內部要進行很復雜的SQL的語意決議、語法樹轉換等等,非常復雜,如果sql陳述句本身就非常復雜,那么很有可能會導致性能的損耗和記憶體的占用,特別是對PermGen的占用會比較大,
所以,此時如果PermGen的占用好過了82MB,但是又小于128MB,就會出現YARN-client模式下可以運行,YARN-cluster模式下無法運行的情況,
解決上述問題的方法時增加PermGen的容量,需要在spark-submit腳本中對相關引數進行設定,
--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -XX:MaxPermSize=256M"
通過上述方法就設定了Driver永久代的大小,默認為128MB,最大256MB,這樣就可以避免上面所說的問題,
7. 解決 SparkSQL 導致的 JVM 堆疊記憶體溢位
當SparkSQL的sql陳述句有成百上千的or關鍵字時,就可能會出現Driver端的JVM堆疊記憶體溢位,
JVM堆疊記憶體溢位基本上就是由于呼叫的方法層級過多,產生了大量的,非常深的,超出了 JVM 堆疊深度限制的遞回,(我們猜測SparkSQL有大量or陳述句的時候,在決議SQL時,例如轉換為語法樹或者進行執行計劃的生成的時候,對于or的處理是遞回,or非常多時,會發生大量的遞回)
此時,建議將一條sql陳述句拆分為多條sql陳述句來執行,每條sql陳述句盡量保證100個以內的子句,根據實際的生產環境試驗,一條sql陳述句的or關鍵字控制在100個以內,通常不會導致JVM堆疊記憶體溢位
8. 持久化與checkpoint的使用
Spark持久化在大部分情況下是沒有問題的,但是有時資料可能會丟失,如果資料一旦丟失,就需要對丟失的資料重新進行計算,計算完后再快取和使用,為了避免資料的丟失,可以選擇對這個RDD進行checkpoint,也就是將資料持久化一份到容錯的檔案系統上(比如HDFS),
一個RDD快取并checkpoint后,如果一旦發現快取丟失,就會優先查看checkpoint資料存不存在,如果有,就會使用checkpoint資料,而不用重新計算,也即是說,checkpoint可以視為cache的保障機制,如果cache失敗,就使用checkpoint的資料,
使用checkpoint的優點在于提高了Spark作業的可靠性,一旦快取出現問題,不需要重新計算資料,缺點在于,checkpoint時需要將資料寫入HDFS等檔案系統,對性能的消耗較大,
??本次的分享就到這里了,

??好書不厭讀百回,熟讀課思子自知,而我想要成為全場最靚的仔,就必須堅持通過學習來獲取更多知識,用知識改變命運,用博客見證成長,用行動證明我在努力,
??如果我的博客對你有幫助、如果你喜歡我的博客內容,請“點贊” “評論”“收藏”一鍵三連哦!聽說點贊的人運氣不會太差,每一天都會元氣滿滿呦!如果實在要白嫖的話,那祝你開心每一天,歡迎常來我博客看看,
??碼字不易,大家的支持就是我堅持下去的動力,點贊后不要忘了關注我哦!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/49103.html
標籤:其他
下一篇:一納米可以影響全球?!