我有一個字串pdf_text(下)
pdf_text = """ Account History Report
IMAGE All Notes
Date Created:18/04/2022
Number of Pages: 4
Client Code - 110203 Client Name - AWS PTE. LTD.
Our Ref :2118881115 Name: Sky Blue Ref 1 :12-34-56789-2021/2 Ref 2:F2021004444
Amount: $100.11 Total Paid:$0.00 Balance: $100.11 Date of A/C: 01/08/2021 Date Received: 10/12/2021
Last Paid: Amt Last Paid: A/C Status: CLOSED Collector : Sunny Jane
Date Notes
04/03/2022 Letter Dated 04 Mar 2022.
Our Ref :2112221119 Name: Green Field Ref 1 :98-76-54321-2021/1 Ref 2:F2021001111
Amount: $233.88 Total Paid:$0.00 Balance: $233.88 Date of A/C: 01/08/2021 Date Received: 10/12/2021
Last Paid: Amt Last Paid: A/C Status: CURRENT Collector : Sam Jason
Date Notes
11/03/2022 Email for payment
11/03/2022 Case Status
08/03/2022 to send a Letter
08/03/2022 845***Ringing, No reply
21/02/2022 Letter printed - LET: LETTER 2
18/02/2022 Letter sent - LET: LETTER 2
18/02/2022 845***Line busy
"""
我需要拆分線上的字串Our Ref :Value Name: Value Ref 1 :Value Ref 2:Value 。這是下面每個資料物體的開始(在矩形中)
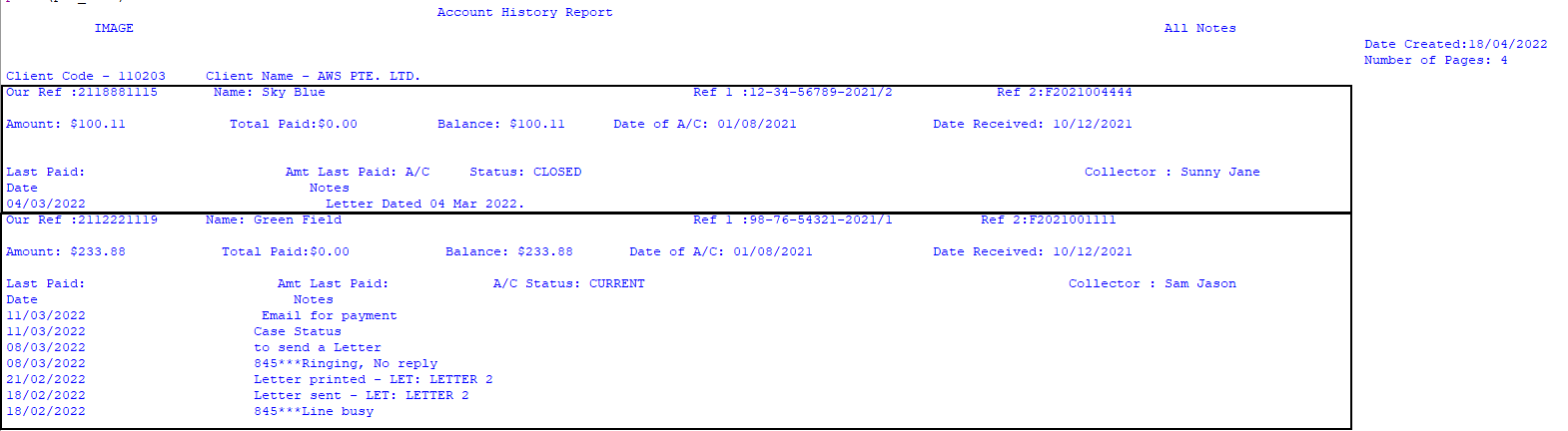
這樣我就可以在不同的字串中獲得平方物體(在上圖中)。
我使用了正則運算式模式
data_entity_sep_pattern = r'(Our Ref.*?Name.*?Ref 1.*?Ref 2.*?)'
但我沒有看到分隔線與分割線一起保留。
split_on_data_entity = re.split(data_entity_sep_pattern, pdf_text.strip())
這給了我

這顯然不是預期的。預期 split_on_data_entity[1] 和 split_on_data_entity[2] 在一個字串中,而 split_on_data_entity[3] 和 split_on_data_entity[4] 在一個字串中。
我指的是這個答案https://stackoverflow.com/a/2136580/10216112這解釋了括號保留字串
uj5u.com熱心網友回復:
預計 split_on_data_entity[1] 和 split_on_data_entity[2] 在一個字串中
括號保留字串,但在單獨的塊中。
如果您想保留字串,但將其作為下一個塊的一部分,請使用前瞻(?= )
其他一些評論:
您可能還希望要求“Our ref”作為一行中的第一組字母出現。當你在它的時候,你可以洗掉這樣的換行符,然后是可選的空格。
無需
.*?在模式的最后匹配由于文本來自 PDF,您可能不想對單詞之間的空格數過于嚴格。你可以使用
\s.
data_entity_sep_pattern = r'\n\s*(?=Our\s Ref.*?Name.*?Ref\s 1.*?Ref\s 2)'
split_on_data_entity = re.split(data_entity_sep_pattern, pdf_text)
for section in split_on_data_entity:
print(section)
print("--------------------------")
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/492580.html
標籤:Python python-3.x 正则表达式 细绳 分裂
上一篇:為什么str.lower()modify修改字串comp
下一篇:用r中的列中的字符分隔字串