我有一個這樣的字典串列,想將它加載到物件中幾個鍵的資料框中。
我想要的資料框看起來像
ID -- retweet_count -- favorite_count
tweet_list = ['{"created_at": "Tue Aug 01 00:17:27 0000 2017", "id": 892177421306343426, "id_str": "892177421306343426", "full_text": "This is Tilly. She\'s just checking pup on you.", "truncated": false, "display_text_range": [0, 138], "contributors": null, "is_quote_status": false, "retweet_count": 6514, "favorite_count": 33819, "favorited": false, "retweeted": false, "possibly_sensitive": false, "possibly_sensitive_appealable": false, "lang": "en"}',
'{"created_at": "Sun Jul 30 15:58:51 0000 2017", "id": 891689557279858688, "id_str": "891689557279858688", "full_text": "This is Darla. She commenced a snooze mid meal.", "truncated": false, "display_text_range": [0, 79], "entities": {"hashtags": [], "symbols": [], "following": true, "follow_request_sent": false, "notifications": false, "translator_type": "none"}, "geo": null, "coordinates": null, "place": null, "contributors": null, "is_quote_status": false, "retweet_count": 8964, "favorite_count": 42908, "favorited": false, "retweeted": false, "possibly_sensitive": false, "possibly_sensitive_appealable": false, "lang": "en"}']
uj5u.com熱心網友回復:
您首先需要有一個可重現的資料:
new_list = [
{"created_at": "Tue Aug 01 00:17:27 0000 2017",
"id": 892177421306343426,
"id_str": "892177421306343426",
"full_text": "This is Tilly. She\'s just checking pup on you.",
"truncated": False,
"display_text_range": [0, 138],
"contributors": None,
"is_quote_status": False,
"retweet_count": 6514,
"favorite_count": 33819,
"favorited": False,
"retweeted": False,
"possibly_sensitive": False,
"possibly_sensitive_appealable": False,
"lang": "en"},
{"created_at": "Sun Jul 30 15:58:51 0000 2017",
"id": 891689557279858688,
"id_str": "891689557279858688",
"full_text": "This is Darla. She commenced a snooze mid meal.",
"truncated": False,
"display_text_range": [0, 79],
"entities": {"hashtags": [], "symbols": [], "following": True,
"follow_request_sent": False, "notifications": False,
"translator_type": "none"},
"geo": None, "coordinates": None,
"place": None,
"contributors": None,
"is_quote_status": False,
"retweet_count": 8964,
"favorite_count": 42908,
"favorited": False,
"retweeted": False,
"possibly_sensitive": False,
"possibly_sensitive_appealable": False,
"lang": "en"}]
要清潔它,您可以使用:
import json
new_list=[]
for i in range(len(tweet_list)):
new_list.append(json.loads(tweet_list[i]))
然后你可以使用:
import pandas as pd
df = pd. DataFrame. from_dict(new_list)
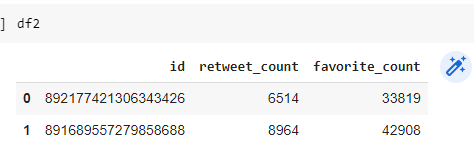
df2=pd.DataFrame(data=df[['id','retweet_count','favorite_count']])

uj5u.com熱心網友回復:
您實際上有strs 串列,它們是通過使用JSON序列化 s 創建的(不是而不是和而不是)。應用它們然后創建 DataFrame,考慮以下簡單示例dictfalseFalsenullNonejson.loads
import json
import pandas as pd
data = ['{"A":1,"B":null}','{"A":null,"B":2}','{"A":null,"B":null}']
df = pd.DataFrame(map(json.loads,data))
print(df)
給出輸出
A B
0 1.0 NaN
1 NaN 2.0
2 NaN NaN
說明:我使用map內置函式應用于json.loads每個元素,list然后pandas.DataFrame從它們創建。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/494882.html
上一篇:在R中查找跨行的值變化