@目錄
- 第二章 2.3章末小結
- 1
- 分類模型
- 回歸模型
- 無監督學習
- 資料聚類
- 資料降維
- 1
第二章 2.3章末小結
1
機器學習模型按照使用的資料型別,可分為監督學習和無監督學習兩大類,
- 監督學習主要包括分類和回歸的模型,
- 分類:線性分類,支持向量機(SVM),樸素貝葉斯,k近鄰,決策樹,集成模型(隨機森林(多個決策樹)等),
- 回歸:線性回歸,支持向量機(SVM),k近鄰,回歸樹,集成模型(隨機森林(多個決策樹)等),
- 無監督學習主要包括:資料聚類(k-means)和資料降維(主成分分析)等等,
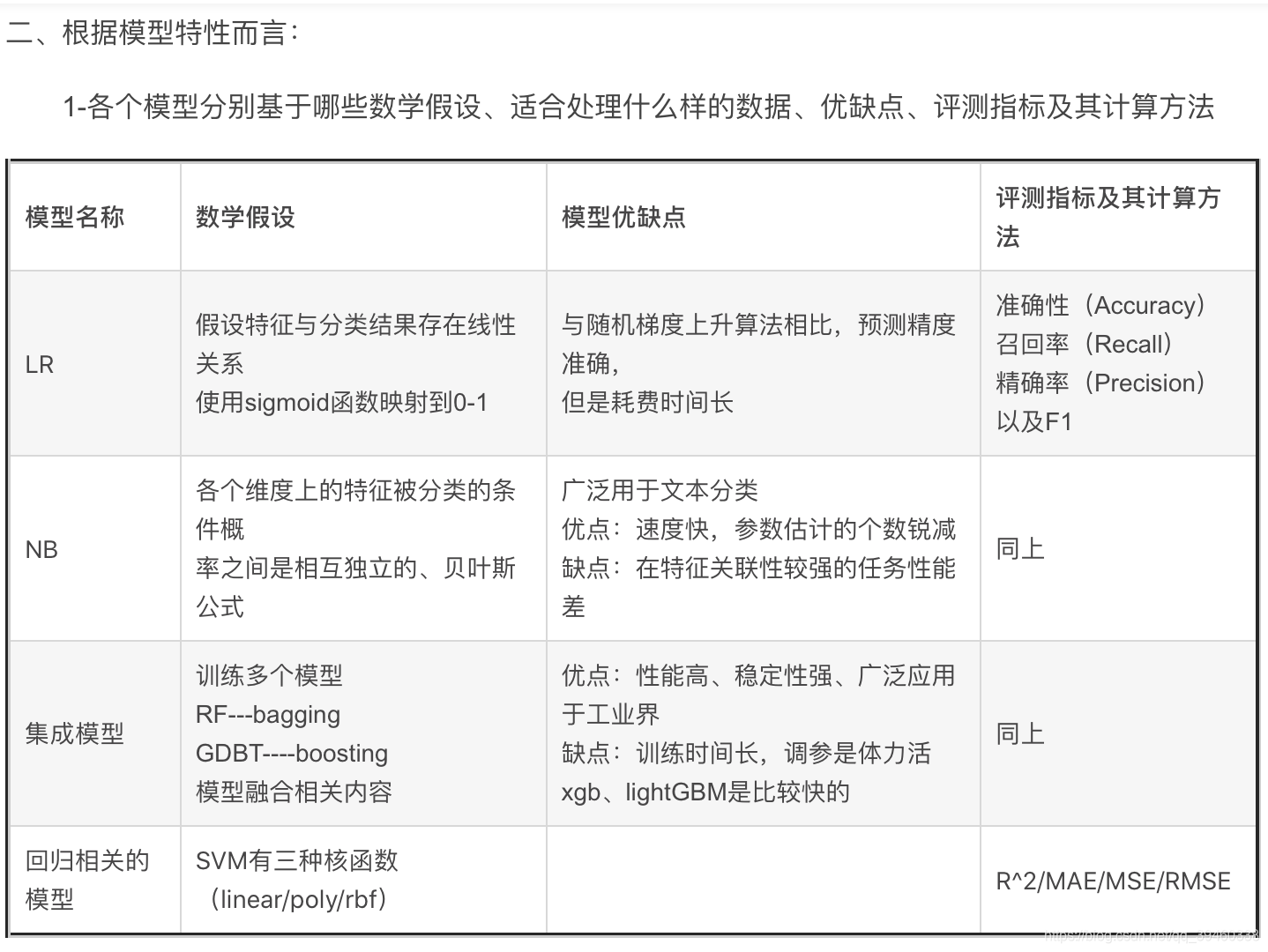
分類模型
線性:假設特征與分類結果存在線性關系,使用sigmoid函式映射到0~1,適合處理具有線性關系的資料,
在科學研究與工程實踐中可把線性分類器的表現作為基準,lr使用精確決議,SGD使用隨機梯度上升估計模型引數,耗時短,準確率略低
- 評價指標:準確性,召回率,精準率,和后二者混合的F1指標
支持向量機:精妙的模型假設,線性假設,只用考慮兩個空間間隔最小的兩個不同類別的資料點,可以在高維資料中選擇最為有效的少數訓練樣本,這樣不僅節省了模型學習所需要的記憶體,而且也提高了模型的預測性能,但付出了計算資源和時間的代價,
- 評價指標:同上,在回歸中有R^2^,MS(平方)E,MA(絕對)E,
樸素貝葉斯 (naive bayes )基于貝葉斯理論,前提:各個維度上的特征被分類的條件概率之間互相獨立,
- 缺點:由于模型的強假設,需要估計的引數規模從冪指數量級到線性數量級減少,極大節約了記憶體消耗和計算時間,但是對特征關聯性較強的任務上表現不佳,
- 評價指標:同線性
k近鄰:不需要引數訓練,其屬于無引數模型,非常高的計算復雜度(平方級)和記憶體消耗,
決策樹:推斷邏輯直觀,有清晰的可解釋性,也方便模型的可視化,易描述非線性關系,模型在學習的時候,需要考慮特征節點的選取順序,
常用的度量方式包括資訊熵和基尼不純性,并不懂,,
集成模型: 有代表性的隨機森林,同時搭建多個決策樹模型,開始投票,
決策樹可以隨機選取特征構建節點(隨機森林),或者按次序搭建分類模型(梯度提升決策樹GTB)
特點:訓練耗費時間,但是往往有更好的表現性能和穩定性,
我看分類這邊都在用線性的度量指標,
回歸模型
只是評估指標變了,在回歸中有R^2^,MS(平方)E 均方誤差,MA(絕對)E平方絕對誤差,
R^2^用來衡量模型回歸結果的波動可被真實值驗證的百分比,也暗示了模型在數值回歸方面的能力,
無監督學習
資料聚類
主流的k-means采用的迭代演算法,直觀易懂并非常實用,
- 容易收斂到區域最優解
- 需要預先設定簇的數量
可使用“肘部”觀察法粗略地預估相對合理的類簇個數,
資料降維
主成分分析(PCA principal component analysis)
相較于損失的少部分模型性能,維度壓縮能夠節省大量模型訓練時間,
明天開始進階篇
隱隱約約感覺不太對,這個沒啥 基礎啊 全是呼叫
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/49854.html
標籤:其他
上一篇:Openstack從入門到放棄