BP神經網路的綜述
1.1神經網路的定義
神經網路(neural network) 是由具有適應性的簡單單元組成的廣泛并行互連的網路,它的組織能夠模擬生物神經系統對真實世界物體所做出的互動反應,
神經網路中最基本的成分是神經元 (neuron) 模型,即上述定義中的簡單單元,在生物神經網路中,每個神經元與其他神經元相連,當它興奮時,就會向相連的神經元發送化學物質,從而改變這些神經元內的電位,如果某神經元的電位超過了一個閾值 (threshold),那么它就會被激活,即興奮起來,向其他神經元發送化學物質,
1.2感知機與多層網路
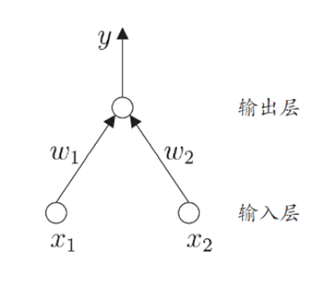
感知機 (perceptron) 由兩層神經元組成,輸入層接收外界輸入信號后傳遞給輸出層,輸出層是 M-P 神 經元,亦稱閾值邏輯單元(threshold logic unit),
感知機能容易地實作邏輯與、或、非運算,
需注意的是,感知機只有輸出層神經元進行激活函式處理,即只擁有一層功能神經元 (functional neuron),其學習能力非常有限,
要解決非線性可分問題,需考慮使用多層功能神經元,更一般的,常見的神經網路是下圖所示的層級結構,每層神經元與下一層神經元全互連,神經元之間不存在同層互連,也不存在跨層連接,這樣的神經網路結構通常稱為多層前饋神經網路 (multi-layer feedforward neural networks),其中輸入層神經元接收外界輸入,隱層與輸出層神經元對信號進行加工,最終結果由輸出層神經元輸出,換言之,輸入層神經元僅是接受輸入,不進行函式處理,隱層與輸出層包含功能神經元,
1.3 BP神經網路與BP演算法
多層網路的學習能力比單層感知機強得多,訓練多層網路,
的簡單感知機學習規則就不夠用了,這就需要更強大的學習演算法,

誤差逆傳播(error BackPropagation, BP)演算法就是其中最杰出的代表,它是迄今最成功的神經網路演算法,現實任務中使用神經網路時,大多是在使用 BP 演算法進行訓練,值得指出的是,BP演算法不僅可用于多層前饋神經網路,還可用于其他型別的神經網路,但通常說 BP 網路時,一般是指用 BP 演算法訓練的多層前饋神經網路,
BP 網路及演算法中的符號:
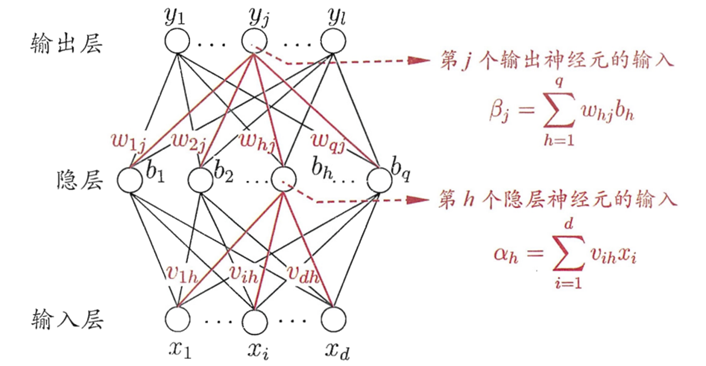
給定訓練集 , 即輸入示例由 d 個屬性描述,輸出 l 維實值向量, 下圖給出了一個擁有 d 個輸入神經元、l 個輸出神經元、q 個隱層神經元的多層前饋網路結構.
BP演算法的作業流程:
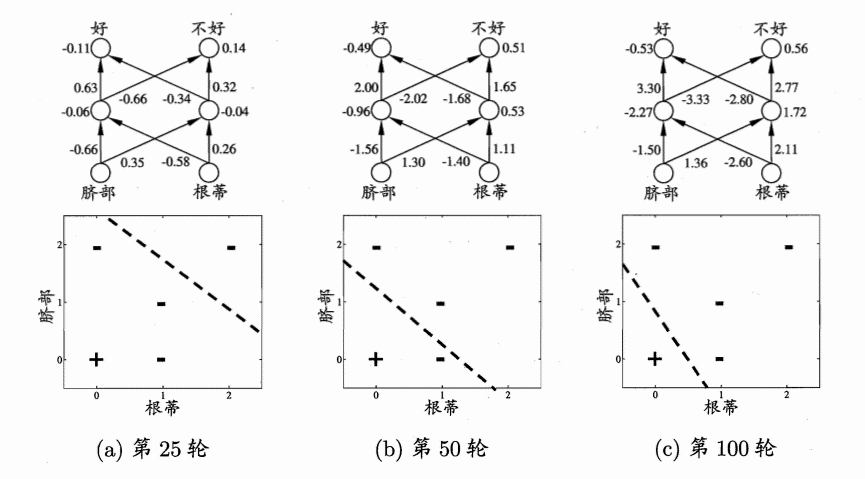
對每個訓練樣例, BP演算法執行以下操作:先將輸入示例提供給輸入層神經元,然后逐層將信號前傳,直到產生輸出層的結果;然后計算輸出層的誤差(第4-5行),再將誤差逆向傳播至隱層神經元(第6行),最后根據隱層神經元的誤差來對連接權和閾值進行調整(第7行).該迭代程序回圈進行,直到達到某些停止條件為止,例如訓練誤差已達到一個很小的值.圖1.4給出了在2個屬性、5個樣本的西瓜資料上,隨著訓練輪數的增加,網路引數和分類邊界的變化情況.

需注意的是,BP 演算法的目標是要最小化訓練集 D 上的累積誤差,
但上面介紹的標準 BP 演算法 每次僅針對一個訓練樣例更新連接權和 閾值,即更新規則是基于單個的 推導而得的,如果類似地推匯出基于累積誤差最小化的更新規則,就得到了累積 誤差逆傳播(accumulated error backpropagation) 演算法,累積 BP 演算法與標準 BP 演算法都很常用,
標準 BP 演算法與累積 BP 演算法的比較:
標準 BP 演算法每次更新只針對單個樣例,引數更新得非常頻繁,而 且對不同樣本進行更新的效果可能會出現抵消現象,因此,為了達到同樣的累積誤差極小點,標準BP演算法往往要進行 更多次的迭代,累積 BP 演算法直接針對累積誤差最小化,它在讀取整個訓練集 D 一遍后才對引數進行更新,其引數更新的頻率低得多,在很多任務中,累積誤差下降到一定程度后,進一步下降會非常緩慢,這時標準 BP 往往會更快獲得較好的解,尤其是在訓練集 D 非常大時更明顯,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/498608.html
標籤:其他