筆記轉載于GitHub專案:https://github.com/NLP-LOVE/Introduction-NLP
9. 資訊抽取
資訊抽取是一個寬泛的概念,指的是從非結構化文本中提取結構化資訊的一類技術,這類技術依然分為基于規則的正則匹配、有監督學習和無監督學習等各種實作方法,我們將使用一些簡單實用的無監督學習方法,由于不需要標注語料庫,所以可以利用海量的非結構化文本,
本章按照顆粒度從小到大的順序,介紹抽取新詞、關鍵詞、關鍵短語和關鍵句的無監督學習方法,
9.1 新詞提取
-
概述
新詞是一個相對的概念,每個人的標準都不一樣,所以我們這里定義: 詞典之外的詞語(OOV)稱作新詞,
新詞的提取對中文分詞而言具有重要的意義,因為語料庫的標注成本很高,那么如何修訂領域詞典呢,此時,無監督的新詞提取演算法就體現了現實意義,
-
基本原理
- 提取出大量文本(生語料)中的詞語,無論新舊,
- 用詞典過濾掉已有的詞語,于是得到新詞,
步驟 2 很容易,關鍵是步驟 1,如何無監督的提取出文本中的單詞,給定一段文本,隨機取一個片段,如果這個片段左右的搭配很豐富,并且片段內部成分搭配很固定,則可以認為這是一個詞,將這樣的片段篩選出來,按照頻次由高到低排序,排在前面的有很高概率是詞,
如果文本足夠大,再用通用的詞典過濾掉“舊詞”,就可以得到“新詞”,
片段外部左右搭配的豐富程度,可以用資訊熵來衡量,而片段內部搭配的固定程度可以用子序列的互資訊來衡量,
-
資訊熵
在資訊論中,資訊熵( entropy )指的是某條訊息所含的資訊量,它反映的是聽說某個訊息之后,關于該事件的不確定性的減少量,比如拋硬幣之前,我們不知道“硬幣正反”這個事件的結果,但是一旦有人告訴我們“硬幣是正面”這條訊息,我們對該次拋硬幣事件的不確定性立即降為零,這種不確定性的減小量就是資訊熵,公式如下:
\[H(X)=-\sum_{x} p(x) \log p(x) \]
給定字串 S 作為詞語備選,X 定義為該字串左邊可能出現的字符(左鄰字),則稱 H(X) 為 S 的左資訊熵,類似的,定義右資訊熵 H(Y),例如下列句子:
兩只蝴蝶飛啊飛
這些蝴蝶飛走了
那么對于字串蝴蝶,它的左資訊熵為1,而右資訊熵為0,因為生語料庫中蝴蝶的右鄰字一定是飛,假如我們再收集一些句子,比如“蝴蝶效應”“蝴蝶蛻變”之類,就會觀察到右資訊熵會增大不少,
左右資訊熵越大,說明字串可能的搭配就越豐富,該字串就是一個詞的可能性就越大,
光考慮左右資訊熵是不夠的,比如“吃了一頓”“看了一遍”“睡了一晚”“去了一趟”中的了一的左右搭配也很豐富,為了更好的效果,我們還必須考慮詞語內部片段的凝聚程度,這種凝聚程度由互資訊衡量,
-
互資訊
互資訊指的是兩個離散型隨機變數 X 與 Y 相關程度的度量,定義如下:
\[\begin{aligned} I(X ; Y) &=\sum_{x, y} p(x, y) \log \frac{p(x, y)}{p(x) p(y)} \\ &=E_{p(x, y)} \log \frac{p(x, y)}{p(x) p(y)} \end{aligned} \]
互資訊的定義可以用韋恩圖直觀表達:
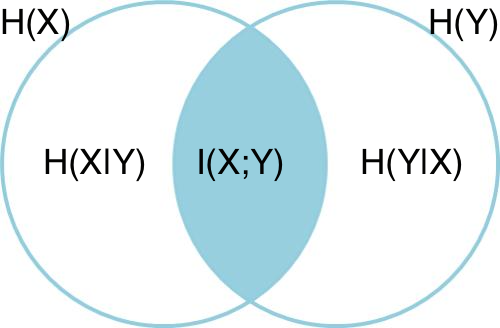
其中,左圓圈表示H(X),右圓圈表示H(Y),它們的并集是聯合分布的資訊熵H(X,Y),差集有多件嫡,交集就是互資訊,可見互資訊越大,兩個隨機變數的關聯就越密切,或者說同時發生的可能性越大,
片段可能有多種組合方式,計算上可以選取所有組合方式中互資訊最小的那一種為代表,有了左右資訊熵和互資訊之后,將兩個指標低于一定閾值的片段過濾掉,剩下的片段按頻次降序排序,截取最高頻次的 N 個片段即完成了詞語提取流程,
-
實作
我們用四大名著來提起100個高頻詞,
代碼請見(語料庫自動下載): extract_word.py
https://github.com/NLP-LOVE/Introduction-NLP/tree/master/code/ch09/extract_word.py
運行結果如下:

雖然我們沒有在古典文學語料庫上進行訓練,但新詞識別模塊成功的識別出了麝月、高太尉等生僻詞語,該模塊也適用于微博等社交媒體的不規范文本,
9.2 關鍵詞提取
詞語顆粒度的資訊抽取還存在另一個需求,即提取文章中重要的單詞,稱為關鍵詞提起,關鍵詞也是一個沒有定量的標準,無法統一語料庫,所以就可以利用無監督學習來完成,
分別介紹詞頻、TF-IDF和TextRank演算法,單檔案提起可以用詞頻和TextRank,多檔案可以使用TF-IDF來提取關鍵詞,
-
詞頻統計
關鍵詞通常在文章中反復出現,為了解釋關鍵詞,作者通常會反復提及它們,通過統計文章中每種詞語的詞頻并排序,可以初步獲取部分關鍵詞,
不過文章中反復出現的詞語卻不一定是關鍵詞,例如“的”,所以在統計詞頻之前需要去掉停用詞,
詞頻統計的流程一般是分詞、停用詞過濾、按詞頻取前 n 個,其中,求 m 個元素中前 n (n<=m) 大元素的問題通常通過最大堆解決,復雜度為 O(mlogn),HanLP代碼如下:
from pyhanlp import * TermFrequency = JClass('com.hankcs.hanlp.corpus.occurrence.TermFrequency') TermFrequencyCounter = JClass('com.hankcs.hanlp.mining.word.TermFrequencyCounter') if __name__ == '__main__': counter = TermFrequencyCounter() counter.add("加油加油中國隊!") # 第一個檔案 counter.add("中國觀眾高呼加油中國") # 第二個檔案 for termFrequency in counter: # 遍歷每個詞與詞頻 print("%s=%d" % (termFrequency.getTerm(), termFrequency.getFrequency())) print(counter.top(2)) # 取 top N # 根據詞頻提取關鍵詞 print('') print(TermFrequencyCounter.getKeywordList("女排奪冠,觀眾歡呼女排女排女排!", 3))運行結果如下:
中國=2 中國隊=1 加油=3 觀眾=1 高呼=1 [加油=3, 中國=2] [女排, 觀眾, 歡呼]用詞頻來提取關鍵詞有一個缺陷,那就是高頻詞并不等價于關鍵詞,比如在一個體育網站中,所有文章都是奧運會報道,導致“奧運會”詞頻最高,用戶希望通過關鍵詞看到每篇文章的特色,此時,TF-IDF 就派上用場了,
-
TF-IDF
TF-IDF (Term Frequency-lnverse Document Frequency,詞頻-倒排檔案頻次)是資訊檢索中衡量一個詞語重要程度的統計指標,被廣泛用于Lucene、Solr、Elasticsearch 等搜索引擎,
相較于詞頻,TF-IDF 還綜合考慮詞語的稀有程度,在TF-IDF計算方法中,一個詞語的重要程度不光正比于它在檔案中的頻次,還反比于有多少檔案包含它,包含該詞語的檔案趣多,就說明它越寬泛, 越不能體現檔案的特色, 正是因為需要考慮整個語料庫或檔案集合,所以TF-IDF在關鍵詞提取時屬于多檔案方法,
計算公式如下:
\[\begin{aligned} \mathrm { TF } - \operatorname { IDF } ( t , d ) & = \frac { \mathrm { TF } ( t , d ) } { \mathrm { DF } ( t ) } \\ & = \mathrm { TF } ( t , d ) \cdot \mathrm { IDF } ( t ) \end{aligned} \]
其中,t 代表單詞,d 代表檔案,TF(t,d) 代表 t 在 d 中出現頻次,DF(t) 代表有多少篇檔案包含 t,DF 的導數稱為IDF,這也是 TF-IDF 得名的由來,
當然,實際應用時做一些擴展,比如加一平滑、IDF取對數以防止浮點數下溢位,HanLP的示例如下:
from pyhanlp import * TfIdfCounter = JClass('com.hankcs.hanlp.mining.word.TfIdfCounter') if __name__ == '__main__': counter = TfIdfCounter() counter.add("《女排奪冠》", "女排北京奧運會奪冠") # 輸入多篇檔案 counter.add("《羽毛球男單》", "北京奧運會的羽毛球男單決賽") counter.add("《女排》", "中國隊女排奪北京奧運會金牌重返巔峰,觀眾歡呼女排女排女排!") counter.compute() # 輸入完畢 for id in counter.documents(): print(id + " : " + counter.getKeywordsOf(id, 3).toString()) # 根據每篇檔案的TF-IDF提取關鍵詞 # 根據語料庫已有的IDF資訊為語料庫之外的新檔案提取關鍵詞 print('') print(counter.getKeywords("奧運會反興奮劑", 2))運行后如下:
《女排》 : [女排=5.150728289807123, 重返=1.6931471805599454, 巔峰=1.6931471805599454] 《女排奪冠》 : [奪冠=1.6931471805599454, 女排=1.2876820724517808, 奧運會=1.0] 《羽毛球男單》 : [決賽=1.6931471805599454, 羽毛球=1.6931471805599454, 男單=1.6931471805599454] [反, 興奮劑]觀察輸出結果,可以看出 TF-IDF 有效的避免了給予“奧運會”這個寬泛的詞語過高的權重,
TF-IDF在大型語料庫上的統計類似于一種學習程序,假如我們沒有這么大型的語料庫或者存盤IDF的記憶體,同時又想改善詞頻統計的效果該怎么辦呢?此時可以使用TextRank演算法,
-
TextRank
TextRank 是 PageRank 在文本中的應用,PageRank是一種用于排序網頁的隨機演算法,它的作業原理是將互聯網看作有向圖,互聯網上的網頁視作節點,節點 Vi 到節點 Vj 的超鏈接視作有向邊,初始化時每個節點的權重 S(Vi) 都是1,以迭代的方式更新每個節點的權重,每次迭代權重的更新運算式如下:
\[S \left( V _ { i } \right) = ( 1 - d ) + d \times \sum _ { V _ { j \in I n \left( V _ { i } \right) } } \frac { 1 } { \left| O u t \left( V _ { j } \right) \right| } S \left( V _ { j } \right) \]
其中 d 是一個介于 (0,1) 之間的常數因子,在PagRank中模擬用戶點擊鏈接從而跳出當前網站的概率,In(Vi) 表示鏈接到 Vi 的節點集合,Out(Vj) 表示從 Vj 出發鏈接到的節點集合,可見,開不是外鏈越多,網站的PageRank就越高,網站給別的網站做外鏈越多,每條外鏈的權重就越低,如果一個網站的外鏈都是這種權重很低的外鏈,那么PageRank也會下降,造成不良反應,正所謂物以類聚,垃圾網站推薦的鏈接往往也是垃圾網站,因此PageRank能夠比較公正的反映網站的排名,
將 PageRank 應用到關鍵詞提取,無非是將單詞視作節點而已,另外,每個單詞的外鏈來自自身前后固定大小的視窗內的所有單詞,
HanLP實作的代碼如下:
from pyhanlp import * """ 關鍵詞提取""" content = ( "程式員(英文Programmer)是從事程式開發、維護的專業人員," "一般將程式員分為程式設計人員和程式編碼人員," "但兩者的界限并不非常清楚,特別是在中國," "軟體從業人員分為初級程式員、高級程式員、系統" "分析員和專案經理四大類,") TextRankKeyword = JClass("com.hankcs.hanlp.summary.TextRankKeyword") keyword_list = HanLP.extractKeyword(content, 5) print(keyword_list)運行結果如下:
[程式員, 程式, 分為, 人員, 軟體]
9.3 短語提取
在資訊抽取領域,另一項重要的任務就是提取中文短語,也即固定多字詞表達串的識別,短語提取經常用于搜索引擎的自動推薦,檔案的簡介生成等,
利用互資訊和左右資訊熵,我們可以輕松地將新詞提取演算法拓展到短語提取,只需將新詞提取時的字符替換為單詞, 字串替換為單詞串列即可,為了得到單詞,我們依然需要進行中文分詞, 大多數時候, 停用詞對短語含義表達幫助不大,所以通常在分詞后過濾掉,
代碼如下:
from pyhanlp import *
""" 短語提取"""
text = '''
演算法工程師
演算法(Algorithm)是一系列解決問題的清晰指令,也就是說,能夠對一定規范的輸入,在有限時間內獲得所要求的輸出,
如果一個演算法有缺陷,或不適合于某個問題,執行這個演算法將不會解決這個問題,不同的演算法可能用不同的時間、
空間或效率來完成同樣的任務,一個演算法的優劣可以用空間復雜度與時間復雜度來衡量,演算法工程師就是利用演算法處理事物的人,
1職位簡介
演算法工程師是一個非常高端的職位;
專業要求:計算機、電子、通信、數學等相關專業;
學歷要求:本科及其以上的學歷,大多數是碩士學歷及其以上;
語言要求:英語要求是熟練,基本上能閱讀國外專業書刊;
必須掌握計算機相關知識,熟練使用仿真工具MATLAB等,必須會一門編程語言,
2研究方向
視頻演算法工程師、影像處理演算法工程師、音頻演算法工程師 通信基帶演算法工程師
3目前國內外狀況
目前國內從事演算法研究的工程師不少,但是高級演算法工程師卻很少,是一個非常緊缺的專業工程師,
演算法工程師根據研究領域來分主要有音頻/視頻演算法處理、影像技術方面的二維資訊演算法處理和通信物理層、
雷達信號處理、生物醫學信號處理等領域的一維資訊演算法處理,
在計算機音視頻和圖形影像技術等二維資訊演算法處理方面目前比較先進的視頻處理演算法:機器視覺成為此類演算法研究的核心;
另外還有2D轉3D演算法(2D-to-3D conversion),去隔行演算法(de-interlacing),運動估計運動補償演算法
(Motion estimation/Motion Compensation),去噪演算法(Noise Reduction),縮放演算法(scaling),
銳化處理演算法(Sharpness),超解析度演算法(Super Resolution) 手勢識別(gesture recognition) 人臉識別(face recognition),
在通信物理層等一維資訊領域目前常用的演算法:無線領域的RRM、RTT,傳送領域的調制解調、信道均衡、信號檢測、網路優化、信號分解等,
另外資料挖掘、互聯網搜索演算法也成為當今的熱門方向,
演算法工程師逐漸往人工智能方向發展,'''
phrase_list = HanLP.extractPhrase(text, 5)
print(phrase_list)
運行結果如下:
[演算法工程師, 演算法處理, 一維資訊, 演算法研究, 信號處理]
目前該模塊只支持提取二元語法短語,在另一些場合,關鍵詞或關鍵短語依然顯得碎片化,不足以表達完整的主題,這時通常提取中心句子作為文章的簡短摘要,而關鍵句的提取依然是基于 PageRank 的拓展,
9.4 關鍵句提取
由于一篇文章中幾乎不可能出現相同的兩個句子,所以樸素的 PageRank 在句子顆粒度上行不通,為了將 PageRank 利用到句子顆粒度上去,我們引人 BM25 演算法衡量句子的相似度,改進鏈接的權重計算,這樣視窗的中心句與相鄰的句子間的鏈接變得有強有弱,相似的句子將得到更高的投票,而文章的中心句往往與其他解釋說明的句子存在較高的相似性,這恰好為演算法提供了落腳點,本節將先介紹BM25演算法,后介紹TextRank在關鍵句提取中的應用,
-
BM25
在資訊檢索領域中,BM25 是TF-IDF的一種改進變種,TF-IDF衡量的是單個詞語在檔案中的重要程度,而在搜索引擎中,查詢串(query)往往是由多個詞語構成的,如何衡量多個詞語與檔案的關聯程度,就是BM25所解決的問題,
形式化的定義 Q 為查詢陳述句,由關鍵字 q1 到 qn 組成,D 為一個被檢索的檔案,BM25度量如下:
\[\operatorname { BM } 25 ( D , Q ) = \sum _ { i = 1 } ^ { n } \operatorname { IDF } \left( q _ { i } \right) \cdot \frac { \operatorname { TF } \left( q _ { i } , D \right) \cdot \left( k _ { 1 } + 1 \right) } { \operatorname { TF } \left( q _ { i } , D \right) + k _ { 1 } \cdot \left( 1 - b + b \cdot \frac { | D | } { \operatorname { avg } D L } \right) } \]
-
TextRank
有了BM25演算法之后,將一個句子視作查詢陳述句,相鄰的句子視作待查詢的檔案,就能得到它們之間的相似度,以此相似度作為 PageRank 中的鏈接的權重,于是得到一種改進演算法,稱為TextRank,它的形式化計算方法如下:
\[\mathrm{WS}\left(V_{i}\right)=(1-d)+d \times \sum_{V_{j} \in \ln \left(V_{i}\right)} \frac{\mathrm{BM} 25\left(V_{i}, V_{j}\right)}{\sum_{V_{k} \in O u t\left(V_{j}\right)} \operatorname{Bu} 2 \mathrm{s}\left(V_{k}, V_{j}\right)} \mathrm{WS}\left(V_{j}\right) \]
其中,WS(Vi) 就是檔案中第 i 個句子的得分,重復迭代該運算式若干次之后得到最終的分值,排序后輸出前 N 個即得到關鍵句,代碼如下:
from pyhanlp import * """自動摘要""" document = '''水利部水資源司司長陳明忠9月29日在國務院新聞辦舉行的新聞發布會上透露, 根據剛剛完成了水資源管理制度的考核,有部分省接近了紅線的指標, 有部分省超過紅線的指標,對一些超過紅線的地方,陳明忠表示,對一些取用水專案進行區域的限批, 嚴格地進行水資源論證和取水許可的批準,''' TextRankSentence = JClass("com.hankcs.hanlp.summary.TextRankSentence") sentence_list = HanLP.extractSummary(document, 3) print(sentence_list)結果如下:
[嚴格地進行水資源論證和取水許可的批準, 水利部水資源司司長陳明忠9月29日在國務院新聞辦舉行的新聞發布會上透露, 有部分省超過紅線的指標]
9.5 總結
我們看到,新詞提取與短語提取,關鍵詞與關鍵句的提取,在原理上都是同一種演算法在不同文本顆粒度上的應用,值得一提的是, 這些演算法都不需要標注語料的參與,滿足了人們“不勞而獲”的欲望,然而必須指出的是,這些演算法的效果非常有限,對于同一個任務,監督學習方法的效果通常遠遠領先于無監督學習方法,
9.6 GitHub
HanLP何晗--《自然語言處理入門》筆記:
https://github.com/NLP-LOVE/Introduction-NLP
專案持續更新中......
目錄
| 章節 |
|---|
| 第 1 章:新手上路 |
| 第 2 章:詞典分詞 |
| 第 3 章:二元語法與中文分詞 |
| 第 4 章:隱馬爾可夫模型與序列標注 |
| 第 5 章:感知機分類與序列標注 |
| 第 6 章:條件隨機場與序列標注 |
| 第 7 章:詞性標注 |
| 第 8 章:命名物體識別 |
| 第 9 章:資訊抽取 |
| 第 10 章:文本聚類 |
| 第 11 章:文本分類 |
| 第 12 章:依存句法分析 |
| 第 13 章:深度學習與自然語言處理 |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/49863.html
標籤:其他
上一篇:html兩個界面互相傳輸資訊
下一篇:機器學習演算法總覽