- 高斯噪音(Gaussian noise)
a kind of signal noise that has a probability density function (pdf) equal to that of the normal distribution (which is also known as the Gaussian distribution).
the values that the noise can take are Gaussian-distributed.
(from wiki)
- 降維(Dimensionality Reduction)
【原】Coursera—Andrew Ng機器學習—課程筆記 Lecture 14—Dimensionality Reduction 降維 - 馬小豆包 - 博客園 (cnblogs.com)
【機器學習】資料降維(Dimensionality Reduction) - 知乎 (zhihu.com)
各類降維方法總結 - 簡書 (jianshu.com)
- (資料壓縮)Data compression
data compression, source coding, or bit-rate reduction is the process of encoding information using fewer bits than the original representation.
-Lossless compression reduces bits by identifying and eliminating statistical redundancy. No information is lost in lossless compression.
-Lossy compression reduces bits by removing unnecessary or less important information.
Compression is useful because it reduces the resources required to store and transmit data.
(from wiki)
- argmax
(from
argmax - Overfitting的文章 - 知乎 https://zhuanlan.zhihu.com/p/79383099)
- 線性代數筆記5——平面方程與矩陣 - 我是8位的 - 博客園 (cnblogs
矩陣論(七):投影矩陣_exp(i)的博客-CSDN博客_投影矩陣(目前還看不懂
線性空間里的線性映射_Uncertainty!!的博客-CSDN博客_線性映射
- 奇異值分解(SVD) - 知乎 (zhihu.com)
評論補充:這個先算U V,再算中間矩陣的方法是錯的
(應該先算u或v再求中間矩陣推出v或u,按這種演算法特征向量正負都無法確定)
真正的U和V一定是AAT和ATA的特征向量組,但是直接求ATA和AAT的特征向量組不一定是U和V,
A必須為實對稱矩陣,實對稱矩陣才有正交基讓其對角化,一般的n * n矩陣,比如Jordan block是沒法對角化的
求出矩陣A的特征值和特征向量,就可以把矩陣A特征分解
A=WΣW^(-1)
W: n個特征向量張成的n*n維矩陣
Σ: n個特征值為主對角線的n*n維矩陣(其他的為零)
!!!把W的n個特征向量標準化→每個w,滿足(w^T)·w=1 or ||w||^2=1后
n個特征向量是標準正交基,滿足(W^T)·W=I or W^T=W^(-1),W是酉矩陣
此時特征分解:A=WΣW^(-T)
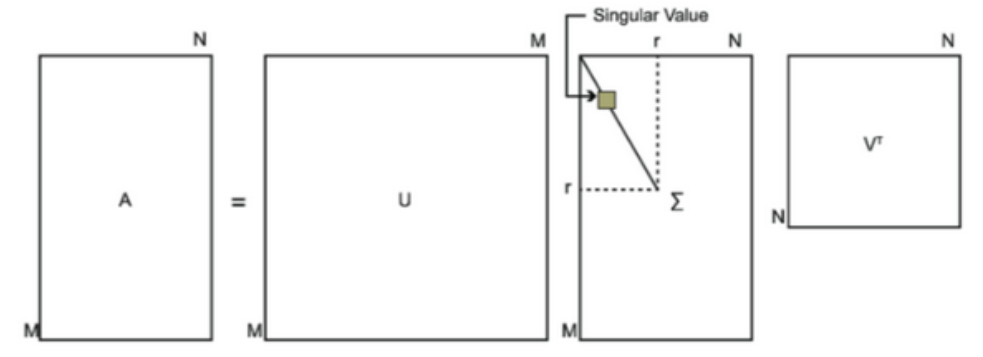
【上面是方陣的情況】
【下面是SVD,不要求方陣】
A(m*n)的SVD
U: m*m
Σ: m*n,除主對角線元素(奇異值)全為零
V: n*n
U和V是酉矩陣(滿足(W^T)·W=I )
goal:求SVD分解后的U,Σ,V這三個矩陣
step1: 進行特征分解,得到的特征值和特征向量滿足下式:
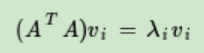
(A^T)·A(n*n)的所有特征向量張成一個n×n的矩陣V=SVD公式里的V矩陣
V中的每個特征向量叫做A的右奇異向量
step2:
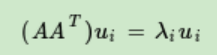
A·(A^T)(m*m)的所有特征向量張成一個m×m的矩陣V=SVD公式里的U矩陣
U中的每個特征向量叫做A的左奇異向量
step3:
∵Σ除了對角線上是奇異值其他位置都是0
∴只需要求出每個奇異值σ
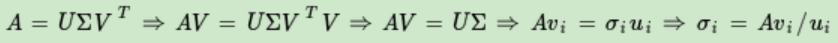
the reason of step1:
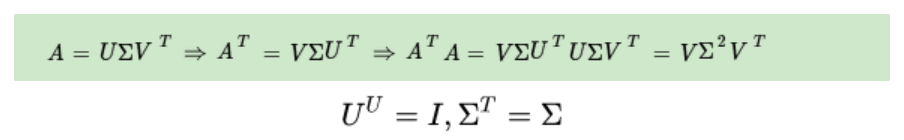
特征值和奇異值滿足:
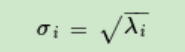
求奇異值的新方法get
SVD計算舉例
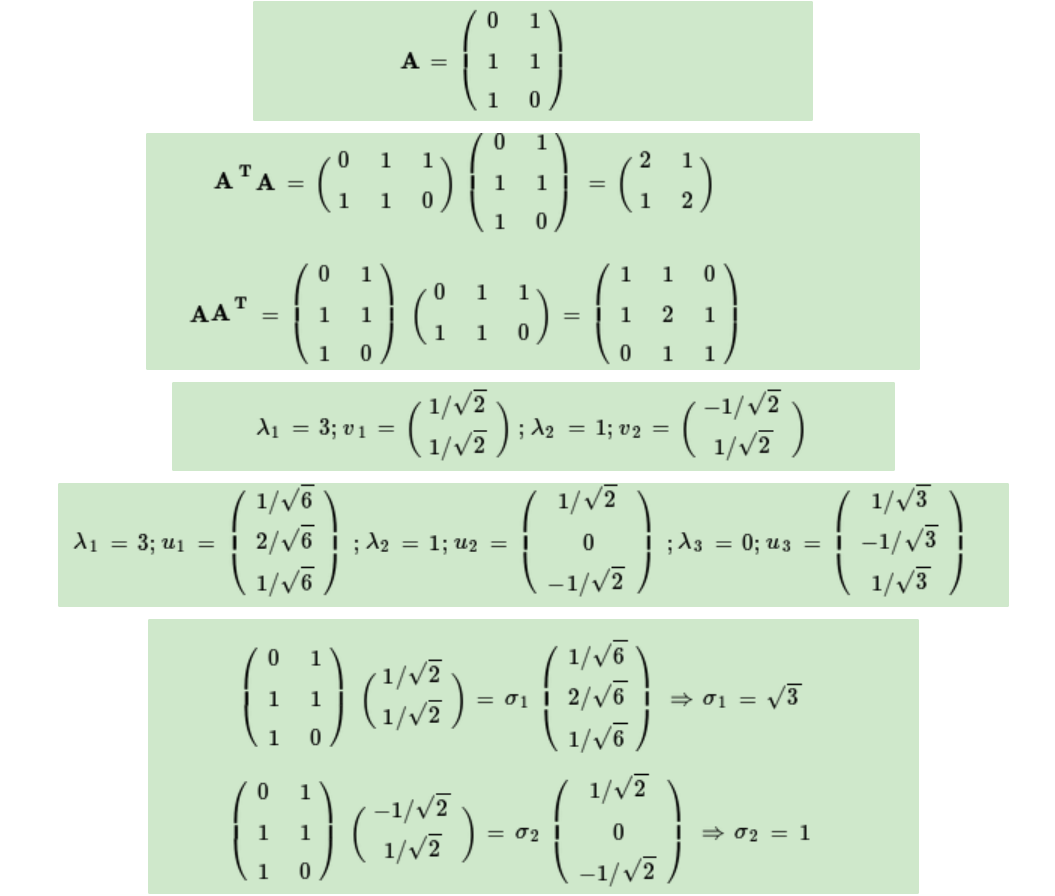

PCA降維,需要找到樣本協方差矩陣 (X^T)·X的最大的d個特征向量
然后用這最大的d個特征向量張成的矩陣來做低維投影降維
有一些SVD的實作演算法可以不求先求出協方差矩陣 ,也能求出右奇異矩陣V
PCA演算法可以不用做特征分解,而是做SVD來完成
實際上,scikit-learn的PCA演算法的背后真正的實作就是用的SVD
PCA僅僅使用了我們SVD的右奇異矩陣,即用于列數即特征維度的壓縮,也就是我們的PCA降維
左奇異矩陣可以用于行數的壓縮
讀評論:SVD是對資料進行有效特征整理的程序
對于一個m×n矩陣A,我們可以理解為其有m個資料,n個特征,(想象成一個n個特征組成的坐標系中的m個點),然而一般情況下,這n個特征并不是正交的,也就是說這n個特征并不能歸納這個資料集的特征,
SVD的作用就相當于是一個坐標系變換的程序,從一個不標準的n維坐標系,轉換為一個標準的k維坐標系,并且使這個資料集中的點,到這個新坐標系的歐式距離為最小值(也就是這些點在這個新坐標系中的投影方差最大化),其實就是一個最小二乘的程序,
如何使資料在新坐標系中的投影最大化呢,那么我們就需要讓這個新坐標系中的基盡可能的不相關,我們可以用協方差來衡量這種相關性,A^T·A中計算的便是n×n的協方差矩陣,每一個值代表著原來的n個特征之間的相關性,
當對這個協方差矩陣進行特征分解之后,我們可以得到奇異值和右奇異矩陣,而這個右奇異矩陣則是一個新的坐標系,奇異值則對應這個新坐標系中每個基對于整體資料的影響大小,我們這時便可以提取奇異值最大的k個基,作為新的坐標,這便是PCA的原理,
對于表達特征空間的資訊,用正交特征能更方便直觀的去歸納,非正交特征表達更困難,也更容易出現冗余特征,
- 希望降維多少個維度,就從最大的λ依次開始取(最大,次大,次次大……)
- 特征值大表示資訊量豐富,反之不豐富
- PCA(主成分分析)所對應的數學理論是SVD(矩陣的奇異值分解),而奇異值分解本身是完全不需要對矩陣中的元素做標準化或者去中心化的,
但是對于機器學習,我們通常會對矩陣(也就是資料)的每一列先進行標準化,
PCA通常是用于高維資料的降維,它可以將原來高維的資料投影到某個低維的空間上并使得其方差盡量大,如果資料其中某一特征(矩陣的某一列)的數值特別大,那么它在整個誤差計算的比重上就很大,那么可以想象在投影到低維空間之后,為了使低秩分解逼近原資料,整個投影會去努力逼近最大的那一個特征,而忽略數值比較小的特征,
因為在建模前我們并不知道每個特征的重要性,這很可能導致了大量的資訊缺失,為了“公平”起見,防止過分捕捉某些數值大的特征,我們會對每個特征先進行標準化處理,使得它們的大小都在相同的范圍內,然后再進行PCA,
此外,從計算的角度講,PCA前對資料標準化還有另外一個好處,因為PCA通常是數值近似分解,而非求特征值、奇異值得到決議解,所以當我們使用梯度下降等演算法進行PCA的時候,我們最好先要對資料進行標準化,這是有利于梯度下降法的收斂,
(from 主成分分析PCA演算法:為什么要對資料矩陣進行均值化? - Bruce的回答 - 知乎 https://www.zhihu.com/question/40956812/answer/1188542265)
- 白化whitening
原文地址:http://blog.csdn.net/hjimce/article/details/50864602
**作者:**hjimce
一、相關理論
白化是一個比PCA稍微高級一點的演算法
目的是去除輸入資料的冗余資訊,假設訓練資料是影像,由于影像中相鄰像素之間具有很強的相關性,所以用于訓練時輸入是冗余的;白化的目的就是降低輸入的冗余性,
輸入資料集X,經過白化處理后,新的資料X'滿足兩個性質:
(1)特征之間相關性較低;(2)所有特征具有相同的方差,
PCA如果不降維,而是僅僅使用PCA求出特征向量,然后把資料X映射到新的特征空間,這樣的一個映射程序,其實就是滿足了我們白化的第一個性質:除去特征之間的相關性,因此白化演算法的實作程序,第一步操作就是PCA,求出新特征空間中X的新坐標,然后再對新的坐標進行方差歸一化操作,
二、演算法概述
白化分為PCA白化、ZCA白化
1、PCA預處理
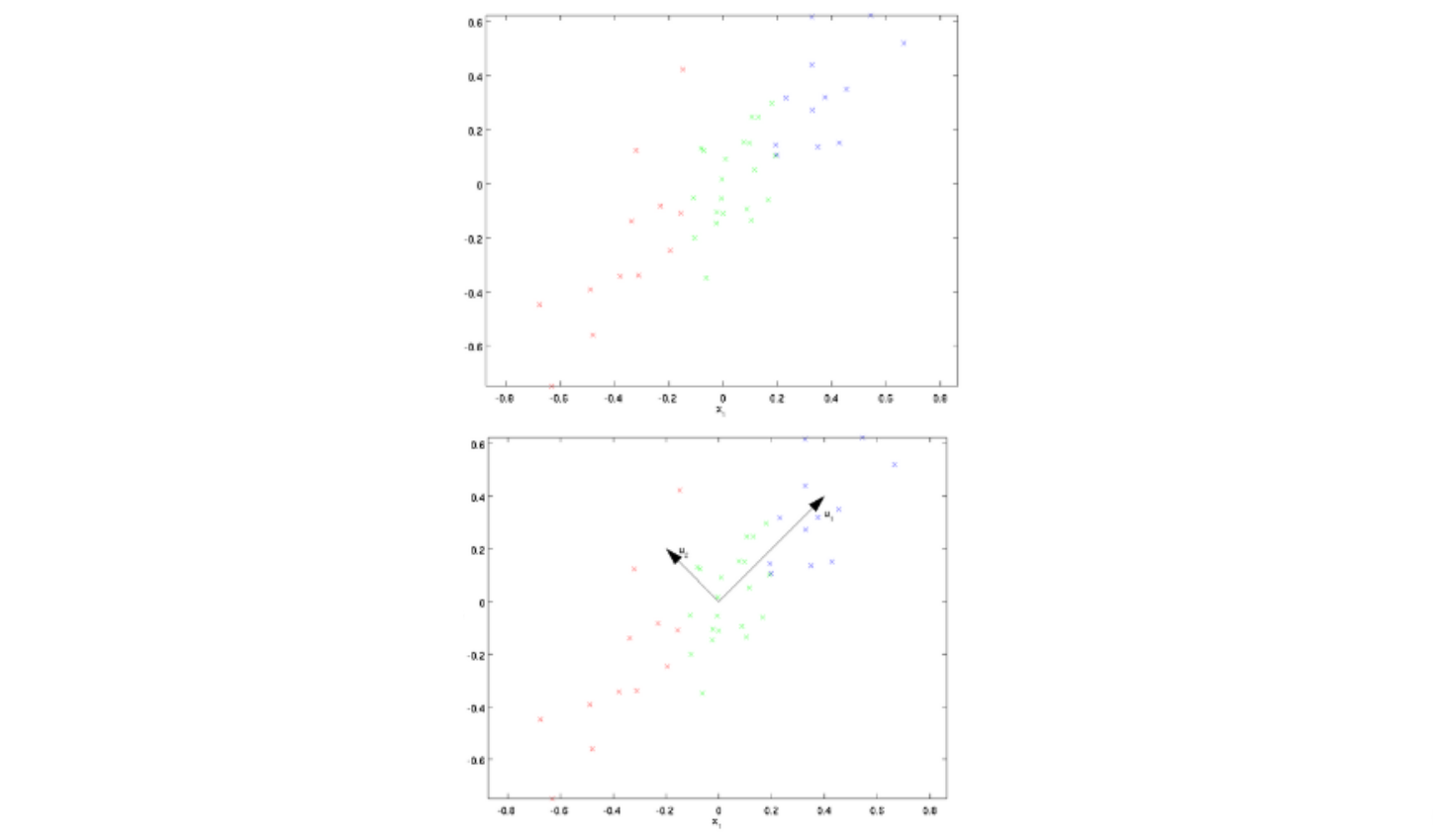
上面圖片,左圖表示原始資料X
然后我們通過協方差矩陣可以求得特征向量u1、u2,
然后把每個資料點,投影到這兩個新的特征向量,得到進行坐標如下:
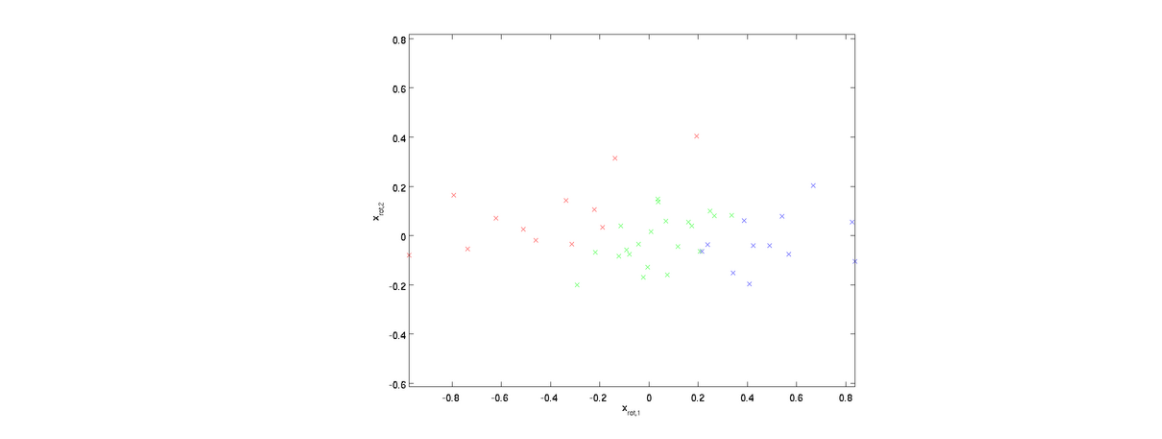
2、PCA白化
對上面的pca的新坐標X’,每一維的特征做一個標準差歸一化處理,
X'為經過PCA處理的新PCA坐標空間,然后λi就是第i維特征對應的特征值(前面pca得到的特征值),ε是為了避免除數為0,
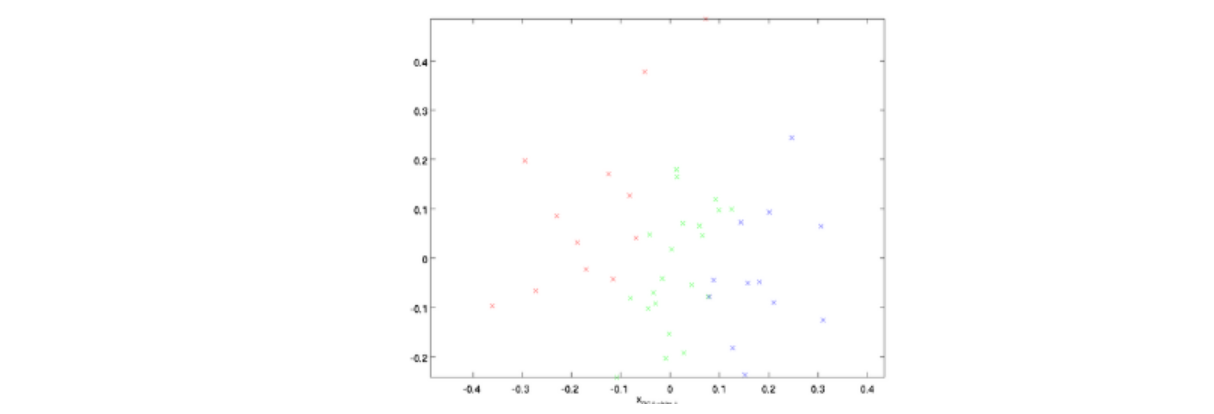
3、ZCA白化
ZCA白化是在PCA白化的基礎上,又進行處理的一個操作,具體的實作是把上面PCA白化的結果,又變換到原來坐標系下的坐標:
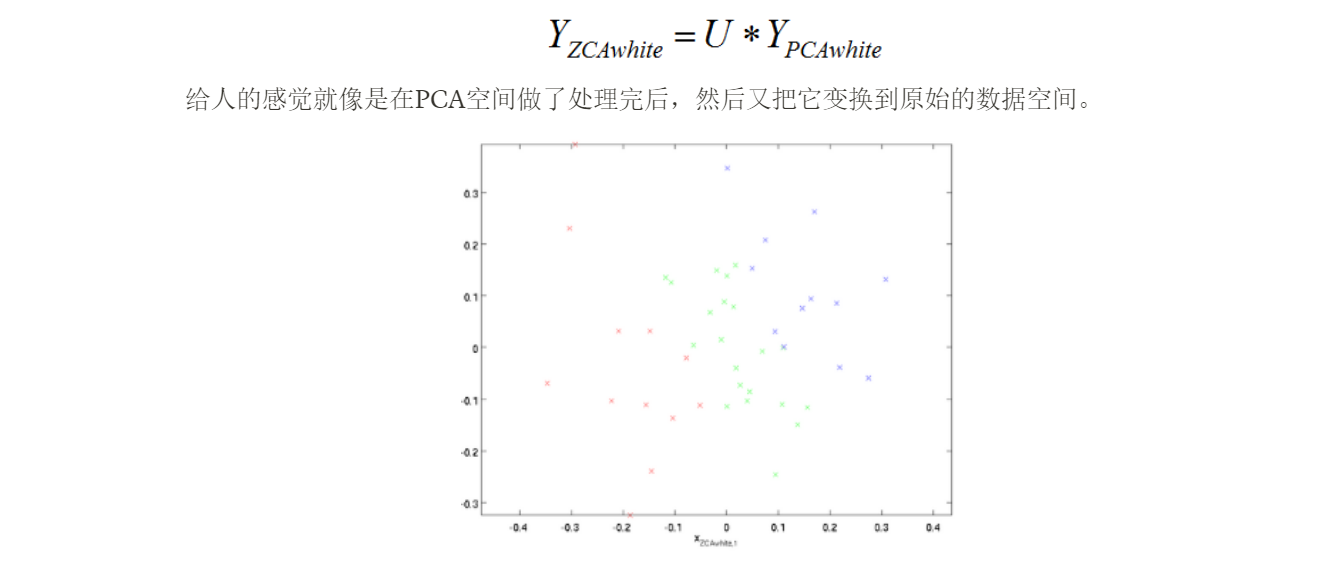
(from 機器學習(七)白化whitening_hjimce的博客-CSDN博客_特征白化)
- 機器學習中一個重要的思想:不是找到曲折的分界線,而是找到在高維(或低維)的投影,并在新維度中找到合適的線性分界面
- feature mapping 把資料升維!
- 核化投影內積,而不投影樣本本身,運算式相對來說更簡單
- https://www.bilibili.com/video/BV1hW411C7ny?from=search&seid=13237820143070831043&vd_source=0645a76390602d5640c372c2f44d99e1
-
-
把所有樣本類似協方差的核函式按一定規律寫出來組成核矩陣,如果該核矩陣滿足半正定,說明里面的小k可以作為核函式
-
不同核函式的分界面不同(?)
-
資料降維: 核主成分分析(Kernel PCA) https://zhuanlan.zhihu.com/p/59775730
主成分分析(Principal Components Analysis, PCA)適用于資料的線性降維,
而核主成分分析(Kernel PCA, KPCA)可實作資料的非線性降維,用于處理線性不可分的資料集,
KPCA的大致思路是:對于輸入空間(Input space)中的矩陣X ,我們先用一個非線性映射把X 中的所有樣本映射到一個高維甚至是無窮維的空間(稱為特征空間,Feature space),(使其線性可分),然后在這個高維空間進行PCA降維,
(知乎原文并不能看得太懂……可能是還有一些知識點不夠熟悉)
- 矩陣的模
https://blog.csdn.net/familyshizhouna/article/details/108456164

- Linear Discriminant Analysis
solve more than two-class classification problems.
It is also known as Normal Discriminant Analysis (NDA) or Discriminant Function Analysis (DFA).
This can be used to project the features of higher dimensional space into lower-dimensional space in order to reduce resources and dimensional costs.
one of the most popular dimensionality reduction techniques used for supervised classification problems.
It is also considered a pre-processing step for modeling differences in ML and applications of pattern classification.
- Medical
In the medical field, LDA has a great application in classifying the patient disease on the basis of various parameters of patient health and the medical treatment which is going on. On such parameters, it classifies disease as mild, moderate, or severe. This classification helps the doctors in either increasing or decreasing the pace of the treatment.
-
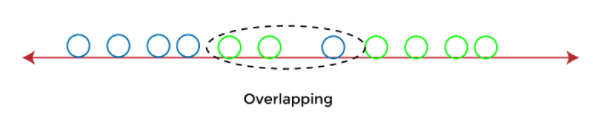
To overcome the overlapping issue in the classification process, we must increase the number of features regularly.
LDA enables us to draw a straight line that can completely separate the two classes of the data points. Here, LDA uses an X-Y axis to create a new axis by separating them using a straight line and projecting data onto a new axis.
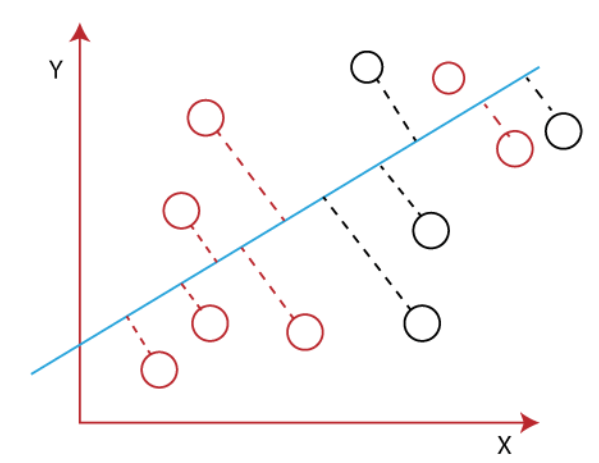
To create a new axis, Linear Discriminant Analysis uses the following criteria:
- It maximizes the distance between means of two classes.
- It minimizes the variance within the individual class.
Conclusion: the new axis will increase the separation between the data points of the two classes and plot them onto the new axis.
[Linear Discriminant Analysis (LDA) in Machine Learning - Javatpoint](https://www.javatpoint.com/linear-discriminant-analysis-in-machine-learning#:~:text=Linear Discriminant Analysis (LDA) is,Discriminant Function Analysis (DFA).)
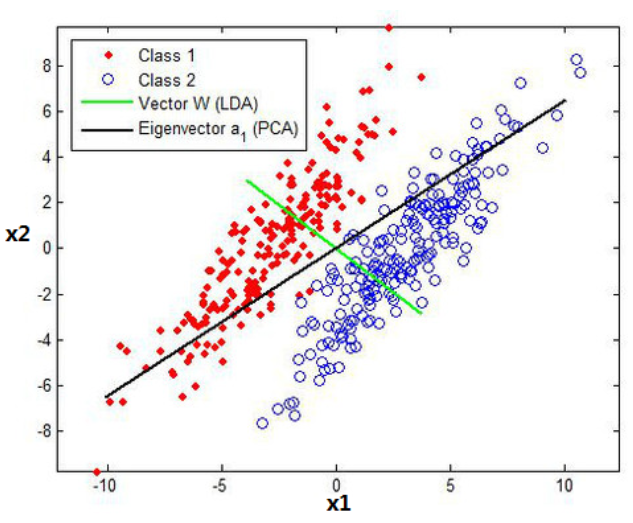
- PCA在提取樣本主要變化資訊上有效,但次要變化資訊有時也能幫助分類
- PCA方法尋找的是資料變化的主軸方向,而判別分析尋找的是用來有效分類的方向,
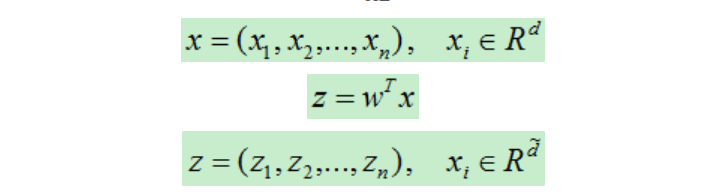
變換:使得同一類的樣本被w作用后距離更近,不同類的樣本被w作用后距離更遠,
Xi的中心點
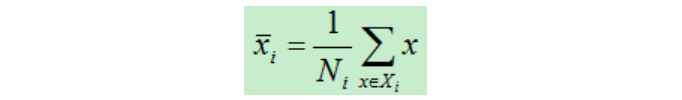
Ni為類別ci的樣本數,即Xi的數目,
中心點經過w變換后得到的中心點
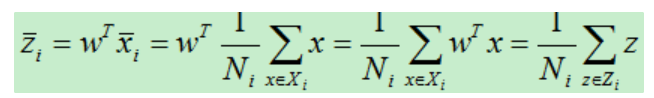
樣本集Xi的中心點的投影為Xi中各元素投影后的均值,
goal: 使得投影之后同類之間樣本距離更小,而不同類之間的樣本距離越大,
- 1)類內距離:各樣本點到該樣本點所在類別的中心點的距離和
散列度:一個類別的類內距離
投影之后類別為i的類內散列度(scatter,類似方差)為:
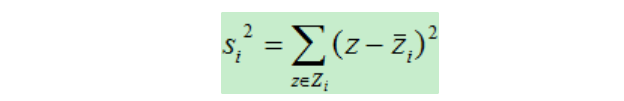
Zi:類別為i的所有樣本集合
推導見:LDA 線性判別分析 - liuwu265 - 博客園 (cnblogs.com)
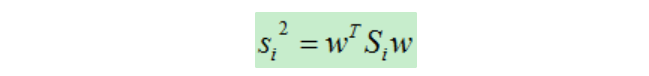
- PPCA
PPCA(Probability PCA)_我永遠熱愛計算機科學與技術的博客-CSDN博客_ppca
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/498631.html
標籤:其他
上一篇:Leetcode 2 兩數相加
下一篇:猴子吃桃(遞回)